FTTransformer,是一个BERT模型架构在结构化数据集上的迁移变体。和BERT一样,它非常能打。
它可能是少数能够在大多数结构化数据集上取得超过或者匹配LightGBM结果的深度模型。
本范例我们将应用它在来对Covertype植被覆盖数据集进行一个多分类任务。
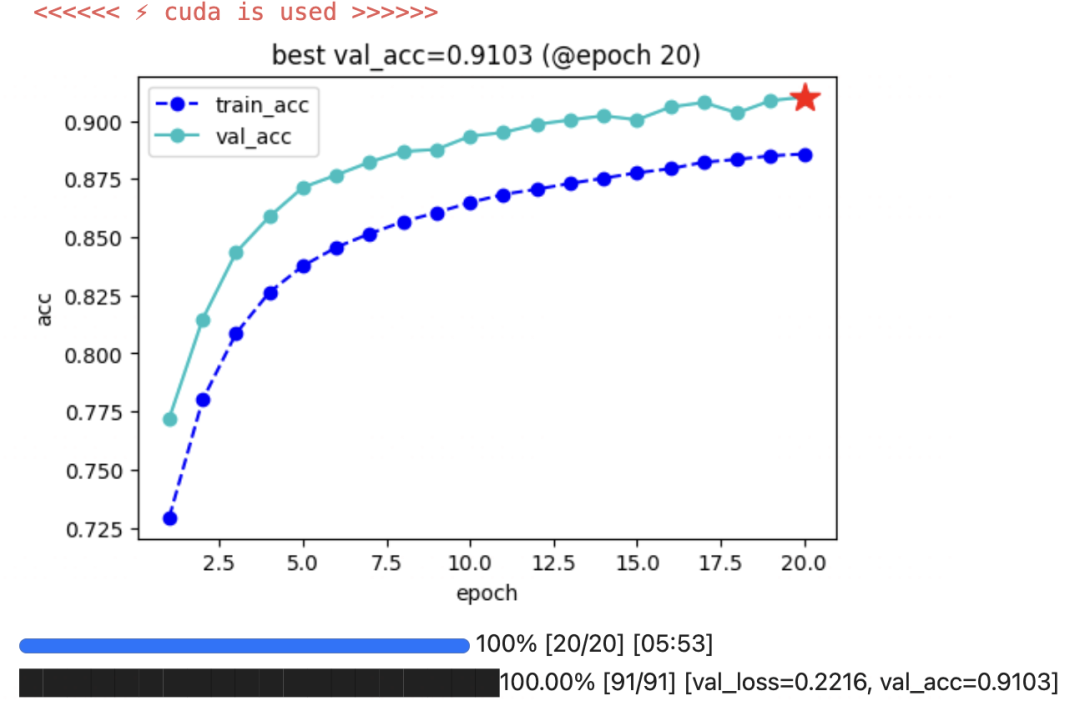
我们在测试集取得了91%的准确率,相比之下LightGBM只有83%的准确率。
公众号算法美食屋后台回复关键词:torchkeras,获取本文notebook源码和所用Covertype数据集下载链接。
〇,原理讲解
FTTransformer是一个可以用于结构化(tabular)数据的分类和回归任务的模型。
FT 即 Feature Tokenizer的意思,把结构化数据中的离散特征和连续特征都像单词一样编码成一个向量。
从而可以像对text数据那样 应用 Transformer对 Tabular数据进行特征抽取。
值得注意的是,它对Transformer作了一些微妙的改动以适应 Tabular数据。
例如:去除第一个Transformer输入的LayerNorm层,仿照BERT的设计增加了output token(CLS token) 与features token 一起进行进入Transformer参与注意力计算。
一,准备数据
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_splitfile_path = "covertype.parquet"
dfdata = pd.read_parquet(file_path)
...dftmp, dftest_raw = train_test_split(dfdata, random_state=42, test_size=0.2)
dftrain_raw, dfval_raw = train_test_split(dftmp, random_state=42, test_size=0.2)print("len(dftrain) = ",len(dftrain_raw))
print("len(dfval) = ",len(dfval_raw))
print("len(dftest) = ",len(dftest_raw))dfdata.shape = (581012, 13)
target_col = Cover_Type
cat_cols = ['Wilderness_Area', 'Soil_Type']
num_cols = ['Elevation', 'Aspect', 'Slope', '...']
len(dftrain) = 371847
len(dfval) = 92962
len(dftest) = 116203from torchkeras.tabular import TabularPreprocessor
from sklearn.preprocessing import OrdinalEncoder#特征工程
...dftest = pipe.transform(dftest_raw.drop(target_col,axis=1))
dftest[target_col] = encoder.transform(dftest_raw[target_col].values.reshape(-1,1)).astype(np.int32)from torchkeras.tabular import TabularDataset
from torch.utils.data import Dataset,DataLoader def get_dataset(dfdata):return TabularDataset(data = dfdata,task = 'classification',target = [target_col],continuous_cols = pipe.get_numeric_features(),categorical_cols = pipe.get_embedding_features())def get_dataloader(ds,batch_size=1024,num_workers=0,shuffle=False):dl = DataLoader(ds,batch_size=batch_size,shuffle=shuffle,num_workers=num_workers,pin_memory=False,)return dl ds_train = get_dataset(dftrain)
ds_val = get_dataset(dfval)
ds_test = get_dataset(dftest)dl_train = get_dataloader(ds_train,shuffle=True)
dl_val = get_dataloader(ds_val,shuffle=False)
dl_test = get_dataloader(ds_test,shuffle=False)for batch in dl_train:break二,定义模型
from torchkeras.tabular.models import FTTransformerConfig,FTTransformerModelmodel_config = FTTransformerConfig(task="classification",num_attn_blocks=3
)config = model_config.merge_dataset_config(ds_train)
net = FTTransformerModel(config = config)#初始化参数
net.reset_weights()
net.data_aware_initialization(dl_train)print(net.backbone.output_dim)
print(net.hparams.output_dim)三,训练模型
from torchkeras import KerasModel
from torchkeras.tabular import StepRunner
KerasModel.StepRunner = StepRunnerimport torch
from torch import nn
class Accuracy(nn.Module):def __init__(self):super().__init__()self.correct = nn.Parameter(torch.tensor(0.0),requires_grad=False)self.total = nn.Parameter(torch.tensor(0.0),requires_grad=False)def forward(self, preds: torch.Tensor, targets: torch.Tensor):preds = preds.argmax(dim=-1)targets = targets.reshape(-1)m = (preds == targets).sum()n = targets.shape[0] self.correct += m self.total += nreturn m/ndef compute(self):return self.correct.float() / self.total def reset(self):self.correct -= self.correctself.total -= self.totalkeras_model = KerasModel(net,loss_fn=None,optimizer = torch.optim.AdamW(net.parameters(),lr = 1e-3),metrics_dict = {"acc":Accuracy()})keras_model.fit(train_data = dl_train,val_data= dl_val,ckpt_path='checkpoint',epochs=20,patience=10,monitor="val_acc", mode="max",plot = True,wandb = False
)
四,评估模型
keras_model.evaluate(dl_val){'val_loss': 0.22164690216164012, 'val_acc': 0.9103181958198547}keras_model.evaluate(dl_test){'val_loss': 0.22033428426897317, 'val_acc': 0.9109489321708679}五,使用模型
from tqdm import tqdm
net = net.cpu()
net.eval()
preds = []
with torch.no_grad():for batch in tqdm(dl_test):preds.append(net.predict(batch))yhat_list = [yd.argmax(dim=-1).tolist() for yd in preds]
yhat = []
for yd in yhat_list:yhat.extend(yd)
yhat = encoder.inverse_transform(np.array(yhat).reshape(-1,1))dftest_raw = dftest_raw.rename(columns = {target_col: 'y'})
dftest_raw['yhat'] = yhatfrom sklearn.metrics import classification_report
print(classification_report(y_true = dftest_raw['y'],y_pred = dftest_raw['yhat']))precision recall f1-score support1 0.90 0.91 0.91 425572 0.92 0.92 0.92 565003 0.92 0.90 0.91 71214 0.85 0.82 0.83 5265 0.78 0.75 0.77 19956 0.84 0.82 0.83 34897 0.92 0.91 0.91 4015accuracy 0.91 116203macro avg 0.88 0.86 0.87 116203
weighted avg 0.91 0.91 0.91 116203import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.metrics import confusion_matrix# 计算混淆矩阵
cm = confusion_matrix(dftest_raw['y'], dftest_raw['yhat'])# 将混淆矩阵转换为DataFrame
df_cm = pd.DataFrame(cm, index=['Actual {}'.format(i) for i in range(cm.shape[0])],columns=['Predicted {}'.format(i) for i in range(cm.shape[1])])# 使用seaborn绘制混淆矩阵
plt.figure(figsize=(10,7))
sns.heatmap(df_cm, annot=True, fmt='d', cmap='Blues', cbar=False)
plt.title('Confusion Matrix')
plt.xlabel('Predicted labels')
plt.ylabel('True labels')
plt.show()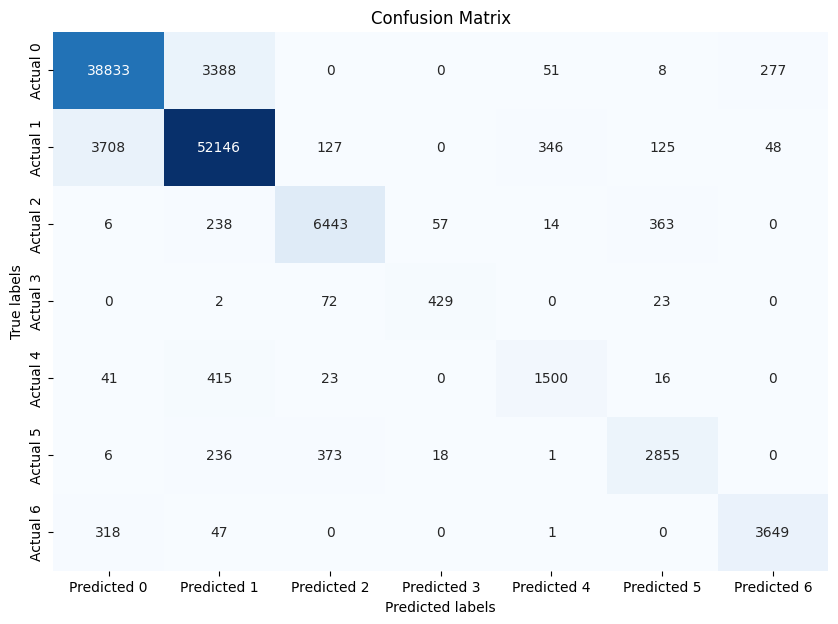
六,保存模型
最佳模型权重已经保存在ckpt_path = 'checkpoint'位置了。
net.load_state_dict(torch.load('checkpoint'))七,与LightGBM对比
import pandas as pd
import lightgbm as lgb
from sklearn.preprocessing import OrdinalEncoder
from sklearn.metrics import accuracy_score dftmp, dftest_raw = train_test_split(dfdata, random_state=42, test_size=0.2)
dftrain_raw, dfval_raw = train_test_split(dftmp, random_state=42, test_size=0.2)dftrain = dftrain_raw.copy()
dfval = dfval_raw.copy()
dftest = dftest_raw.copy()target_col = 'Cover_Type'
cat_cols = ['Wilderness_Area', 'Soil_Type']encoder = OrdinalEncoder()dftrain[target_col] = encoder.fit_transform(dftrain[target_col].values.reshape(-1,1))
dfval[target_col] = encoder.transform(dfval[target_col].values.reshape(-1,1))
dftest[target_col] = encoder.transform(dftest[target_col].values.reshape(-1,1))for col in cat_cols:dftrain[col] = dftrain[col].astype(int)dfval[col] = dfval[col].astype(int)dftest[col] = dftest[col].astype(int)ds_train = lgb.Dataset(dftrain.drop(columns=[target_col]), label=dftrain[target_col],categorical_feature=cat_cols)
ds_val = lgb.Dataset(dfval.drop(columns=[target_col]), label=dfval[target_col],categorical_feature=cat_cols)
ds_test = lgb.Dataset(dftest.drop(columns=[target_col]), label=dftest[target_col],categorical_feature=cat_cols)import lightgbm as lgbparams = {'n_estimators':500,'boosting_type': 'gbdt','objective':'multiclass','num_class': 7, # 类别数量'metric': 'multi_logloss', 'learning_rate': 0.01,'verbose': 1,'early_stopping_round':50
}
model = lgb.train(params, ds_train, valid_sets=[ds_val], valid_names=['validate'])y_pred_val = model.predict(dfval.drop(target_col,axis = 1), num_iteration=model.best_iteration)
y_pred_val = np.argmax(y_pred_val, axis=1)y_pred_test = model.predict(dftest.drop(target_col,axis = 1), num_iteration=model.best_iteration)
y_pred_test = np.argmax(y_pred_test, axis=1)val_score = accuracy_score(dfval[target_col], y_pred_val)
test_score = accuracy_score(dftest[target_col], y_pred_test) print('val_score = ',val_score)
print('test_score = ' , test_score)val_score = 0.8321464684494739
test_score = 0.8329389086340284公众号算法美食屋后台回复关键词:torchkeras,获取本文notebook源码和更多有趣范例。







![[k8s源码]5.自己写一个informer控制器](https://i-blog.csdnimg.cn/direct/b74441f7f66948b0874dedaf26d0053a.png)