这是我的第331篇原创文章。
一、引言
P-Tuning 是一种对预训练语言模型进行少量参数微调的技术。所谓预训练语言模型,就是指在大规模的语言数据集上训练好的、能够理解自然语言表达并从中学习语言知识的模型。P-Tuning 所做的就是根据具体的任务,对预训练的模型进行微调,让它更好地适应于具体任务。相比于重新训练一个新的模型,微调可以大大节省计算资源,同时也可以获得更好的性能表现。
前文回顾:
【Python大语言模型系列】基于阿里云人工智能平台部署ChatGLM2-6B(完整教程)
ChatGLM2-6B 环境已经有了,接下来开始模型微调,这里我们使用官方的 P-Tuning v2 对 ChatGLM2-6B 模型进行参数微调,P-Tuning v2 将需要微调的参数量减少到原来的 0.1%,再通过模型量化、Gradient Checkpoint 等方法,最低只需要 7GB 显存即可运行。
二、实现过程
2.1 安装依赖
# 运行微调需要 4.27.1 版本的 transformers
pip install transformers==4.27.1
pip install rouge_chinese nltk jieba datasets# 禁用 W&B,如果不禁用可能会中断微调训练
export WANDB_DISABLED=true2.2 准备数据集
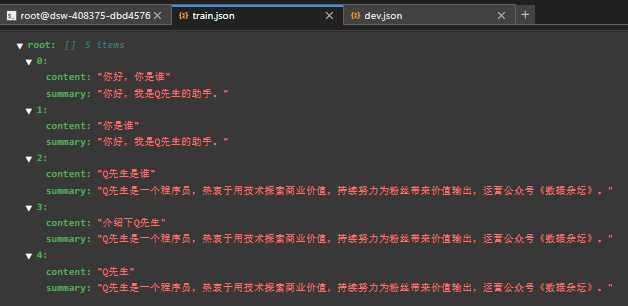
为了简化,我只准备了5条测试数据,分别保存为 train.json 和 dev.json,放到 ptuning 目录下,实际使用的时候肯定需要大量的训练数据。
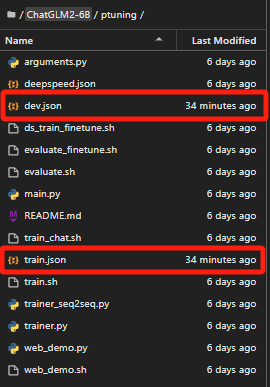
train.json 和 dev.json的内容如下:
2.3 调整脚本参数
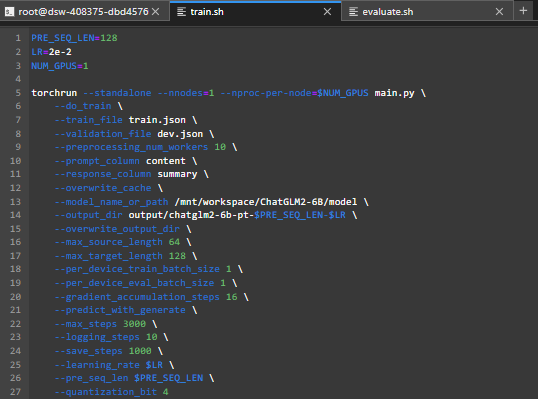
修改 train.sh 和 evaluate.sh 中的 train_file、validation_file和test_file为你自己的 JSON 格式数据集路径,并将 prompt_column 和 response_column 改为 JSON 文件中输入文本和输出文本对应的 KEY。
可能还需要增大 max_source_length 和 max_target_length 来匹配你自己的数据集中的最大输入输出长度。并将模型路径 THUDM/chatglm-6b 改为你本地的模型路径。
train.sh修改如下:
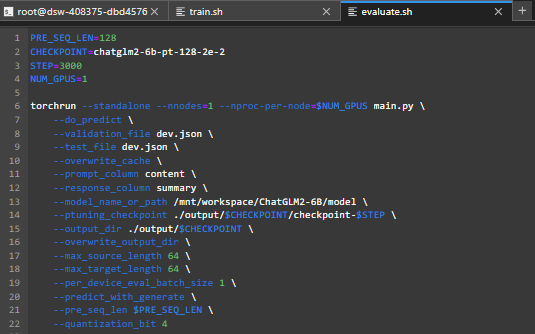
evalution.sh修改如下:
2.4 执行训练脚本
bash train.sh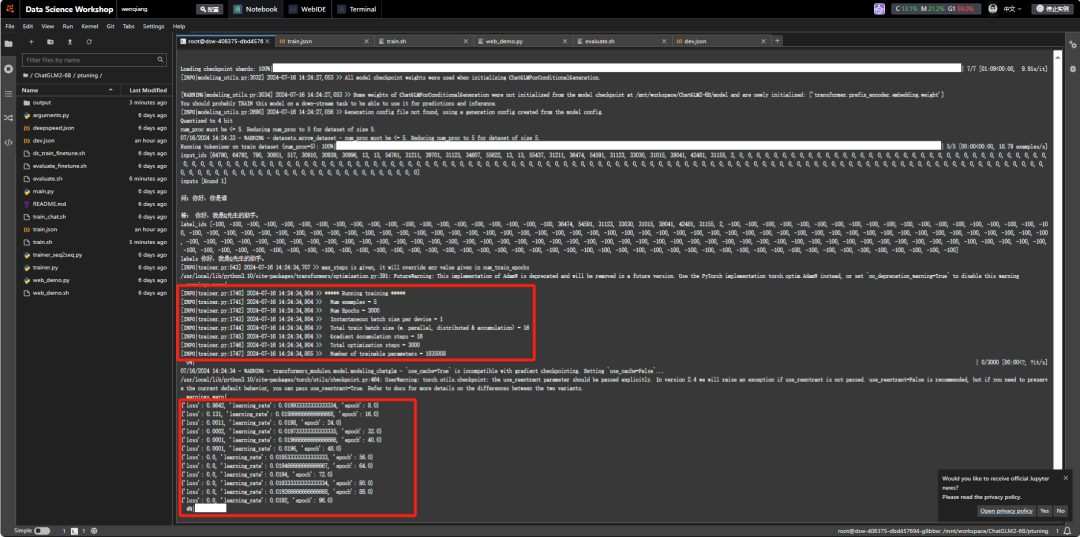
训练过程会比较慢,差不多花了一个小时,最终训练完成:
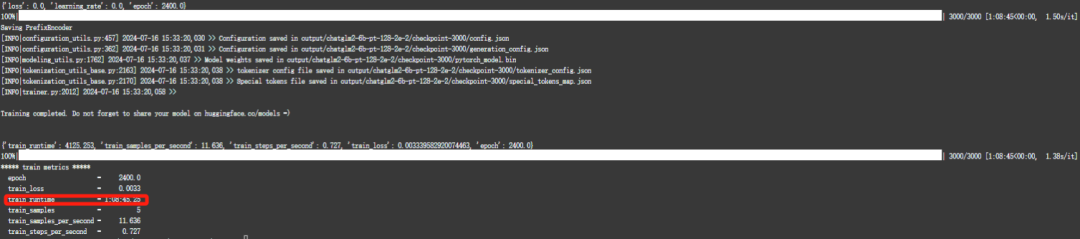
2.5 执行推理脚本
bash evalution.sh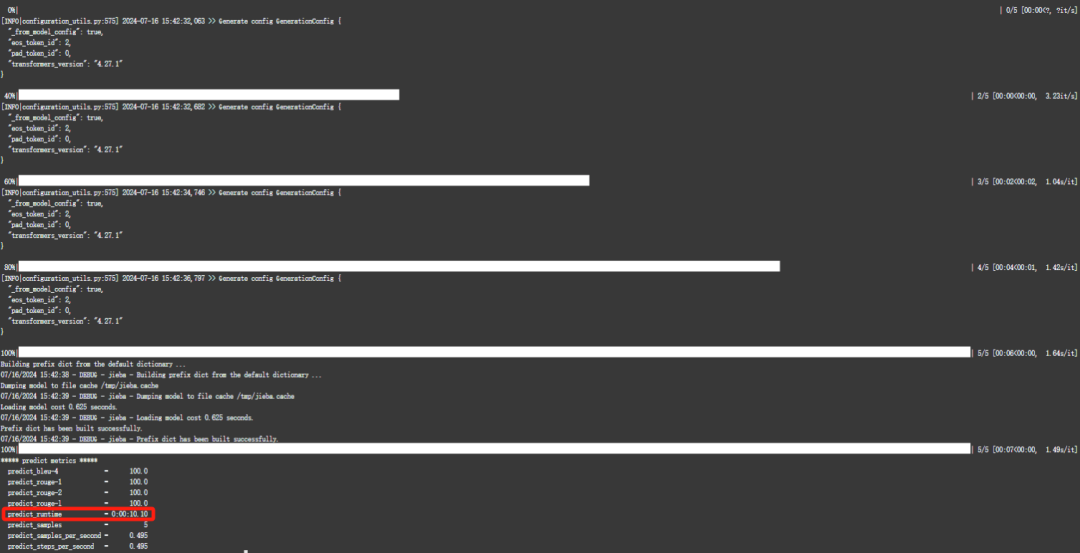
执行完成后,会生成评测文件,评测指标为中文 Rouge score 和 BLEU-4。生成的结果保存在 ./output/chatglm-6b-pt-32-2e-2/generated_predictions.txt。
我们准备了 5 条推理数据,所以相应的在文件中会有 5 条评测数据,labels 是 dev.json 中的预测输出,predict 是 ChatGLM-6B 生成的结果,对比预测输出和生成结果,评测模型训练的好坏。如果不满意调整训练的参数再次进行训练。

2.6 部署微调后的模型
可以修改 web_demo.sh 的内容以符合实际情况,将 pre_seq_len 改成你训练时的实际值,将 THUDM/chatglm-6b 改成本地的模型路径。web_demo.sh修改如下:

执行:
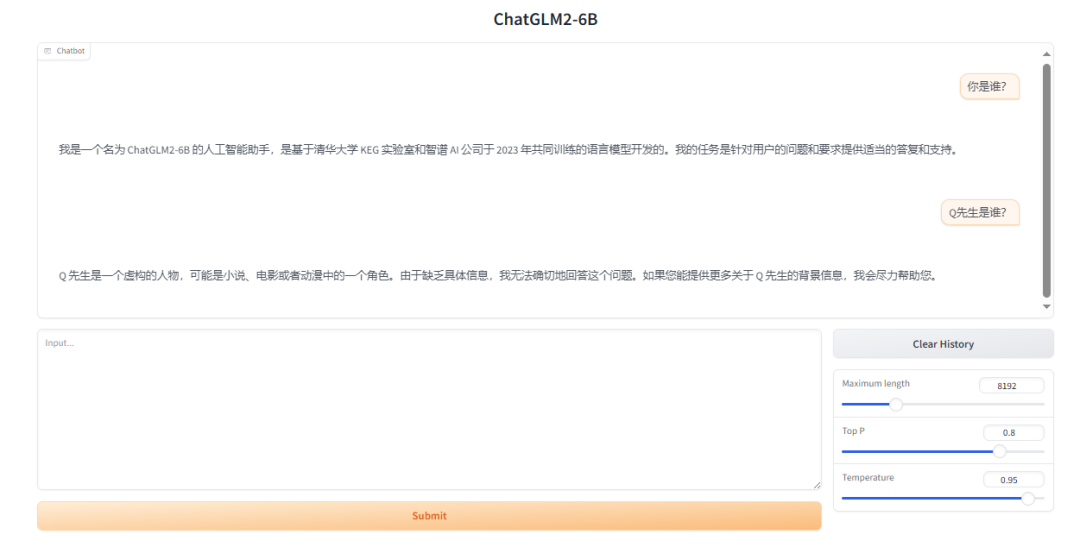
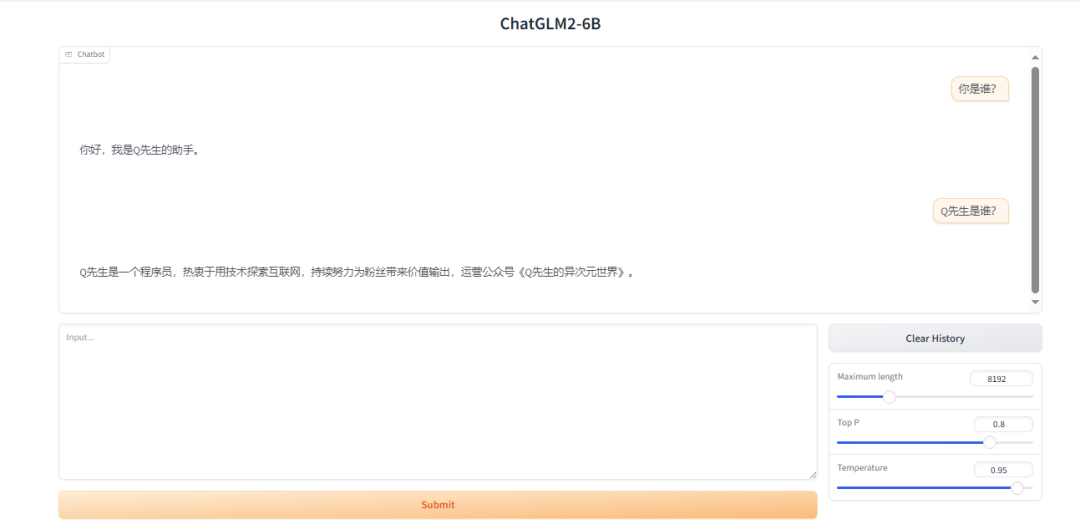
bash web_demo.sh2.7 微调前后对比
原始模型:
微调后的模型:
三、小结
微调可以对原有模型作领域知识的训练,相关领域知识需要进行整理成语料,语料越充分相对来说模型作预测越准,还要结合调参,反复地训练,才有可能起到一定的效果。
作者简介:
读研期间发表6篇SCI数据挖掘相关论文,现在某研究院从事数据算法相关科研工作,结合自身科研实践经历不定期分享关于Python、机器学习、深度学习、人工智能系列基础知识与应用案例。致力于只做原创,以最简单的方式理解和学习,关注我一起交流成长。需要数据集和源码的小伙伴可以关注底部公众号添加作者微信。