目录
- 0.前期准备
- 1.为何IO交互要是Page?
- 2.理解单个Page
- 3.理解多个Page
- 4.页目录
- 5.单页情况
- 6.多页情况
- 7.总结复盘
- 8.InnoDB 在建立索引结构来管理数据的时候,其他数据结构为何不行?
- 9.聚簇索引 vs 非聚簇索引
0.前期准备
-
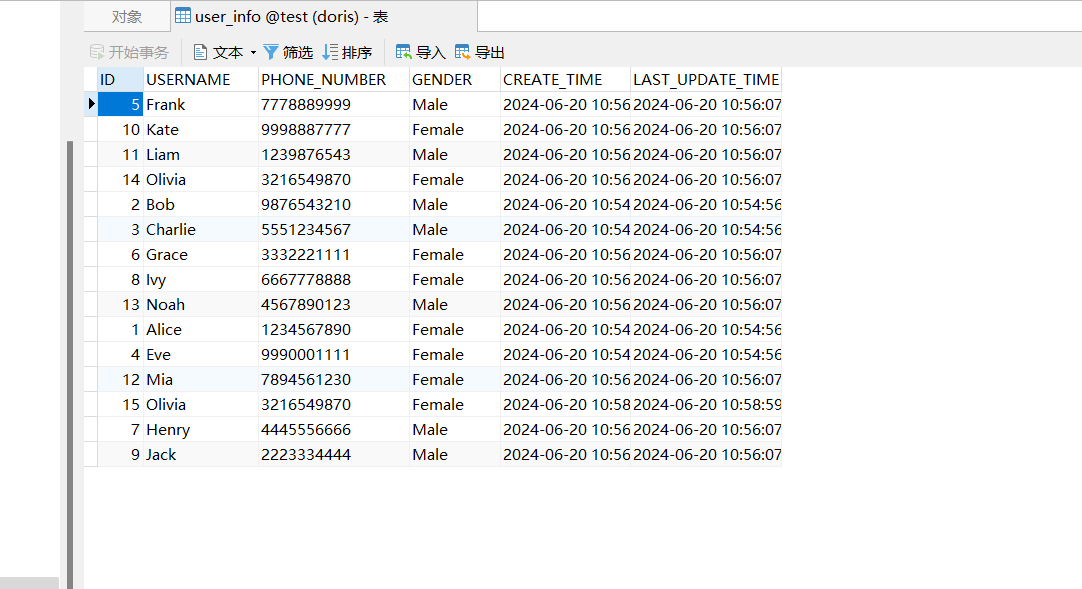
建立测试表
create table if not exists user ( id int primary key, --一定要添加主键,只有这样才会默认生成主键索引 age int not null, name varchar(16) not null );mysql> show create table user \G *************************** 1. row *************************** Table: user Create Table: CREATE TABLE `user` (`id` int(11) NOT NULL,`age` int(11) NOT NULL,`name` varchar(16) NOT NULL,PRIMARY KEY (`id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8 --默认就是InnoDB存储引擎 -
插入多条记录
- 注意:这里并没有按照主键的大小顺序插入
# 插入多条记录, insert into user (id, age, name) values(3, 18, '杨过'); insert into user (id, age, name) values(4, 16, '小龙女'); insert into user (id, age, name) values(2, 26, '黄蓉'); insert into user (id, age, name) values(5, 36, '郭靖'); insert into user (id, age, name) values(1, 56, '欧阳锋'); -
查看插入结果,发现竟然默认是有序的,是谁干的呢?排序有什么好处呢?
- mysqld自己做的
- 可以很方便地引入目录
select * from user; +----+-----+-----------+ | id | age | name | +----+-----+-----------+ | 1 | 56 | 欧阳锋 | | 2 | 26 | 黄蓉 | | 3 | 18 | 杨过 | | 4 | 16 | 小龙女 | | 5 | 36 | 郭靖 | +----+-----+-----------+
1.为何IO交互要是Page?
- 为何MySQL和磁盘进行IO交互的时候,要采用Page的方案进行交互呢?用多少,加载多少不香吗?
- 如上面的5条记录,如果MySQL要查找id=2的记录,第一次加载id=1,第二次加载id=2,一次一条记录,那么就需要2次IO。如果要找id=5,那么就需要5次IO
- 但如果这5条(或者更多)都被保存在一个Page中(16KB,能保存很多记录),那么第一次IO查找id=2的时候,整个Page会被加载到MySQL的Buffer Pool中,这里完成了一次IO。但是往后如果在查找id=1,3,4,5等,完全不需要进行IO了,而是直接在内存中进行了,所以,就在单Page里面,大大减少了IO的次数
- 怎么保证,用户一定下次找的数据,就在这个Page里面?
- 不能严格保证,但是有很大概率,因为有局部性原理
- 往往IO效率低下的最主要矛盾不是IO单次数据量的大小,而是IO的次数
2.理解单个Page
-
MySQL中要管理很多数据表文件,而要管理好这些文件,就需要 先描述,再组织
- 目前可以简单理解成一个个独立文件是由一个或者多个Page构成的
- MYSQL内部,一定需要并且会存在大量的Page,也就决定了,MYSQL必须要将多个同时存在的Page管理起来
- 要管理所有的MYSQL内的Page,需要 先描述,再组织
-
不同的Page,在MySQL中,都是16KB,使用 prev 和 next 构成双向链表
-
因为有主键的问题, MySQL会默认按照主键给数据进行排序,从下面的Page内数据记录可以看出,数据是有序且彼此关联的

-
为什么数据库在插入数据时要对其进行排序呢?按正常顺序插入数据不是也挺好的吗?
- 插入数据时排序的目的,就是优化查询的效率
- 页内部存放数据的模块,实质上也是一个链表的结构,链表的特点也就是增删快,查询修改慢,所以优化查询的效率是必须的
- 正是因为有序,在查找的时候,从头到后都是有效查找,没有任何一个查找是浪费的,而且,如果运气好,是可以提前结束查找过程的
3.理解多个Page
- 上面页模式中,只有一个功能,就是在查询某条数据的时候直接将一整页的数据加载到内存中,以减少硬盘IO次数,从而提高性能。但是,现在的页模式内部,实际上是采用了链表的结构,前一条数据指向后一条数据,本质上还是通过数据的逐条比较来取出特定的数据
- 如果有1千万条数据,一定需要多个Page来保存1千万条数据,多个Page彼此使用双链表链接起来,而且每个Page内部的数据也是基于链表的。那么,查找特定一条记录,也一定是线性查找,这效率也太低了

4.页目录
- 在看一本书的时候,比如要看<刘姥姥进大观园>,找到该章节有两种做法
- 从头逐页的向后翻,直到找到目标内容
- 通过书提供的目录,发现其在234页(假设),那么便直接翻到234页。
- 同时,查找目录的方案,可以顺序找,不过因为目录肯定少,所以可以快速提高定位
- 本质上,书中的目录,是多花了纸张的,但是却提高了效率
- 所以,目录,是一种**“空间换时间的做法”**
5.单页情况
- 针对上面的单页Page,能否也引入目录呢?
- 当然可以
- 此时,如果要查找id=4记录,之前必须线性遍历4次,才能拿到结果。现在直接通过目录2[3],直接进行定位新的起始位置,提高了效率
- 现在可以再次正式回答上面的问题了,为何通过键值MySQL会自动排序?
- 可以很方便引入目录

- 可以很方便引入目录
6.多页情况
-
MySQL中每一页的大小只有 16KB,单个Page大小固定,所以随着数据量不断增大,16KB不可能存下所有的数据,那么必定会有多个页来存储数据
-
在单表数据不断被插入的情况下, MySQL 会在容量不足的时候,自动开辟新的Page来保存新的数据,然后通过指针的方式,将所有的Page组织起来
-
需要注意,下面的图,是理想结构,目前要保证整体有序,那么新插入的数据,不一定会在新Page上面,这里仅仅做演示
-
这样,就可以通过多个Page遍历,Page内部通过目录来快速定位数据
- 可是,貌似这样也有效率问题,在Page之间,也是需要MySQL遍历的
- 遍历意味着依旧需要进行大量的IO,将下一个Page加载到内存,进行线性检测
- 这样就显得之前的Page内部的目录,有点杯水车薪了

-
那么如何解决呢?
- 给Page也带上目录
- 使用一个目录项来指向某一页,而这个目录项存放的就是将要指向的页中存放的最小数据的键值
- 和页内目录不同的地方在于,这种目录管理的级别是页,而页内目录管理的级别是行
- 其中,每个目录项的构成是:键值+指针,图中没有画全

-
存在一个目录页来管理页目录,目录页中的数据存放的就是指向的那一页中最小的数据
- 有数据,就可通过比较,找到该访问哪个Page,进而通过指针,找到下一个Page
-
其实目录页的本质也是页,普通页中存的数据是用户数据,而目录页中存的数据是普通页的地址
-
可是,每次检索数据的时候,该从哪里开始呢?虽然顶层的目录页少了,但是还是要遍历啊?
- 不用担心,可以再加目录页
- 这种数据结构就是传说中的B+树
- 至此,已经给表user构建完了主键索引
-
索引的本质:就是数据结构B+树
-
随便找一个id=?,现在查找的Page数一定减少了,也就意味着IO次数减少了,那么效率也就提高了

7.总结复盘
- Page分为目录页和数据页,目录页只放各个下级Page的最小键值
- 查找的时候,自顶向下找,只需要加载部分目录页到内存,即可完成算法的整个查找过程,大大减少了IO次数
8.InnoDB 在建立索引结构来管理数据的时候,其他数据结构为何不行?
-
链表?
- 线性遍历
-
二叉搜索树?
- 退化问题,可能退化成为线性结构
-
AVL && 红黑树?
- 虽然是平衡或者近似平衡,但是毕竟是二叉结构,相比较多阶B+,意味着树整体过高,都是自顶向下找,层高越低,意味着系统与硬盘更少的IO Page交互
- 虽然你很秀,但是有更秀的:P
-
Hash?
- 官方的索引实现方式中, MySQL是支持HASH的,不过 InnoDB 和 MyISAM 并不支持
- Hash根据其算法特征,决定了虽然有时候也很快(O(1)),不过,在面对范围查找就明显不行

-
B树?最值得比较的是InnoDB为何不用B树作为底层索引?
- 目前这两棵树,对我们最有意义的区别是:
- B树节点,既有数据,又有Page指针,而B+,只有叶子节点有数据,其他目录页,只有键值和Page指针
- 路上节点不存储data,这样一个节点就可以存储更多的key,可以使得树更矮,所以IO操作次数更少[结构角度]
- 每一个节点,都有目录项,可以大大提高搜索效率[算法角度]
- B+叶子节点,全部相连,而B没有,这是B+的特点
- 叶子节点相连,更便于进行范围查找
- B树节点,既有数据,又有Page指针,而B+,只有叶子节点有数据,其他目录页,只有键值和Page指针
- 目前这两棵树,对我们最有意义的区别是:
-
B树

-
B+树

9.聚簇索引 vs 非聚簇索引
-
MyISAM引擎同样使用B+树作为索引结果,叶节点的data域存放的是数据记录的地址
- 下图为 MyISAM 表的主键索引,Col1 为主键

- 下图为 MyISAM 表的主键索引,Col1 为主键
-
其中,MyISAM 最大的特点是将索引Page和数据Page分离,也就是叶子节点没有数据,只有对应数据的地址
- 相较于 InnoDB 索引, InnoDB 是将索引和数据放在一起的
-
MyISAM 这种用户数据与索引数据分离的索引方案,叫做非聚簇索引
-
InnoDB 这种用户数据与索引数据在一起索引方案,叫做聚簇索引
-rw-r----- 1 mysql mysql 8586 Jun 13 13:33 mtest.frm --表结构数据 -rw-r----- 1 mysql mysql 0 Jun 13 13:33 mtest.MYD --该表对应的数据,当前没有数据,所以是0 -rw-r----- 1 mysql mysql 1024 Jun 13 13:33 mtest.MYI --该表对应的主键索引数据-rw-r----- 1 mysql mysql 8586 Jun 13 13:39 itest.frm --表结构数据 -rw-r----- 1 mysql mysql 98304 Jun 13 13:39 itest.ibd --该表对应的主键索引和用户数据/ 虽然现在一行数据没有,但是该表并不为0,因为有主键索引数据 -
当然, MySQL 除了默认会建立主键索引外,用户也有可能建立按照其他列信息建立的索引,一般这种索引可以叫做辅助(普通)索引
- 对于 MyISAM,建立辅助(普通)索引和主键索引没有差别,无非就是主键不能重复,而非主键可重复
-
下图就是基于 MyISAM 的 Col2 建立的索引,和主键索引没有差别

-
同样, InnoDB 除了主键索引,用户也会建立辅助(普通)索引,以上表中的 Col3 建立对应的辅助索引如下图

-
可以看到,InnoDB 的非主键索引中叶子节点并没有数据,而只有对应记录的key值
- 所以通过辅助(普通)索引,找到目标记录,需要两遍索引:
- 首先检索辅助索引获得主键
- 然后用主键到主索引中检索获得记录
- 这种过程,就叫做回表查询
- 所以通过辅助(普通)索引,找到目标记录,需要两遍索引:
-
为何 InnoDB 针对这种辅助(普通)索引的场景,不给叶子节点也附上数据呢?
- 原因就是太浪费空间了