文章目录
- 一、关于 xFormers
- 特点
- 二、安装xFormers
- 三、Benchmarks
- (可选)测试安装
- 四、使用xFormers
- 1、Transformers 关键概念
- 2、Repo map
- 3、主要特点
- 4、安装故障排除
一、关于 xFormers
xFormers是一个基于PyTorch的库,其中包含灵活的Transformers 组件。
它们是可互操作和优化的构建块,可以选择组合以创建一些最先进的模型。
- github : https://github.com/facebookresearch/xformers
- 官方文档: https://facebookresearch.github.io/xformers/
特点
- 可定制的构建块:无需样板代码即可使用的独立/可定制构建块。组件与领域无关,xFormers被视觉、NLP等领域的研究人员使用。
- 首先研究:xFormers包含前沿组件,这些组件在PyTorch等主流库中尚不可用。
- 考虑效率:因为迭代速度很重要,所以组件尽可能快速和内存高效。xFormers包含自己的CUDA内核,但在相关时会分派到其他库。
二、安装xFormers
- (推荐,linux)使用conda安装最新的稳定版:需要使用conda安装PyTorch2.3.1
conda install xformers -c xformers
- (推荐,linux&win)使用pip安装最新的稳定版:需要PyTorch2.3.1
# cuda 11.8 version
pip3 install -U xformers --index-url https://download.pytorch.org/whl/cu118
# cuda 12.1 version
pip3 install -U xformers --index-url https://download.pytorch.org/whl/cu121
- 开发二进制文件:
# Use either conda or pip, same requirements as for the stable version above
conda install xformers -c xformers/label/dev
pip install --pre -U xformers
- 从源代码安装:例如,如果您想与另一个版本的PyTorch一起使用(包括夜间发布)
# (Optional) Makes the build much faster
pip install ninja
# Set TORCH_CUDA_ARCH_LIST if running and building on different GPU types
pip install -v -U git+https://github.com/facebookresearch/xformers.git@main#egg=xformers
# (this can take dozens of minutes)
三、Benchmarks
Memory-efficient MHA
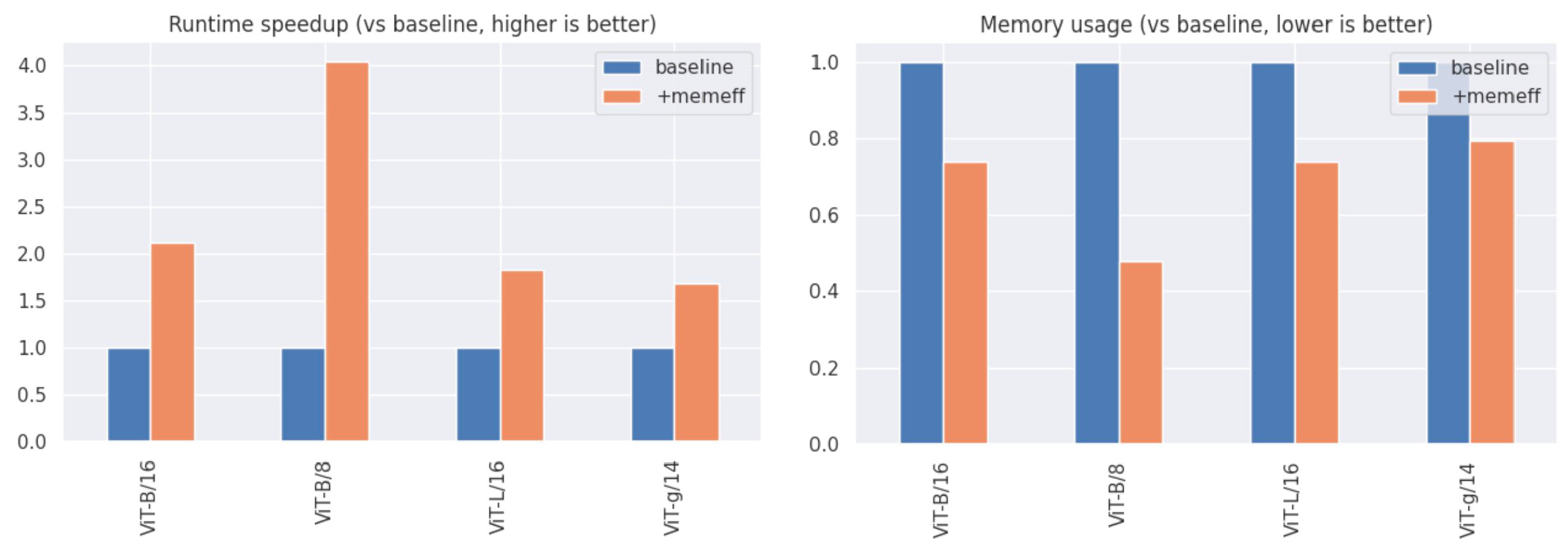
设置:f16上的A100,测量前进+后退传球的总时间
请注意,这是精确的关注,而不是近似值,只需调用xformers.ops.memory_efficient_attention
更多 benchmarks
xFormers提供了许多组件,BENCHMARKS.md中提供了更多基准测试。
(可选)测试安装
此命令将提供有关xFormers安装的信息,以及构建/可用的内核:
python -m xformers.info
四、使用xFormers
1、Transformers 关键概念
让我们从变形金刚架构的经典概述开始(插图来自Lin et al,“A Survey of Transformers”)

在这个例子中,你会发现关键的存储库边界:转换器通常由注意力机制、编码一些位置信息的嵌入、前馈块和残差路径(通常称为前层或后层范数)的集合组成。这些边界并不适用于所有模型,但我们在实践中发现,如果有一些调整,它可以捕捉到大部分最先进的技术。
因此,模型不是在单体文件中实现的,这些文件通常很难处理和修改。上图中出现的大多数概念对应于抽象级别,当给定子块存在变体时,应该始终可以选择其中任何一个。您可以专注于给定的封装级别并根据需要进行修改。
2、Repo map
├── ops # Functional operators└ ...
├── components # Parts zoo, any of which can be used directly
│ ├── attention
│ │ └ ... # all the supported attentions
│ ├── feedforward #
│ │ └ ... # all the supported feedforwards
│ ├── positional_embedding #
│ │ └ ... # all the supported positional embeddings
│ ├── activations.py #
│ └── multi_head_dispatch.py # (optional) multihead wrap
|
├── benchmarks
│ └ ... # A lot of benchmarks that you can use to test some parts
└── triton└ ... # (optional) all the triton parts, requires triton + CUDA gpu
3、主要特点
- 许多注意力机制,可互换性
-
- 记忆效率高的精确注意力-快10倍
- 注意力稀疏
- 块稀疏注意
- 融合softmax
- 熔融线性层
- 熔合层范数
- 融合辍学(激活(x+偏差))
- 熔融旋转
-
- 微观基准
- Transformers 组基准
- 上帝抵抗军,在SLURM的支持下
-
- 与分层变形金刚兼容,如Swin或元变形金刚
-
- 不使用单片CUDA内核、可组合构建块
- 使用Triton优化部分,显式,pythonic和用户可访问
- 对SquaredReLU(在ReLU、LeakyReLU、GeLU之上)的原生支持,可扩展激活
4、安装故障排除
- NVCC和当前CUDA运行时匹配。根据您的设置,您可以更改CUDA运行时,使用
module unload cuda; module load cuda/xx.x,也可能是nvcc - 您使用的GCC版本与当前的NVCC功能匹配
- 将
TORCH_CUDA_ARCH_LISTenv变量设置为您想要支持的体系结构。建议的设置(构建缓慢但全面)是export TORCH_CUDA_ARCH_LIST="6.0;6.1;6.2;7.0;7.2;7.5;8.0;8.6" - 如果从源OOMs构建,则可以减少忍者与
MAX_JOBS的并行性(例如MAX_JOBS=2) - 如果您在使用conda安装时遇到
UnsatisfiableError,请确保您在conda环境中安装了PyTorch,并且您的设置(PyTorch版本、cuda版本、python版本、操作系统)匹配xFormers的现有二进制文件
2024-07-17(三)