文章目录
- 什么是布隆过滤器
-
- 布隆过滤器的优点:
- 布隆过滤器的缺点:
- 其他问题
- 布隆过滤器适合的场景
- 布隆过滤器原理
-
- 数据结构
- 增加元素
- 查询元素
- 删除元素
- 如何使用布隆过滤器
-
- Google开源的Guava自带布隆过滤器
- Redis实现布隆过滤器
-
- Redis中配置布隆过滤器
- Redis中布隆过滤器指令使用
-
- 自定义参数
- 基本操作
- Java集成Redis使用布隆过滤器
-
- pom中引入redisson依赖:
- 编写代码测试
什么是布隆过滤器
布隆过滤器(Bloom Filter)是 1970 年由布隆提出的,是一种非常节省空间的概率数据结构,运行速度快,占用内存小,但是有一定的误判率且无法删除元素。它实际上是一个很长的二进制向量和一系列随机映射函数组成,主要用于判断一个元素是否在一个集合中。
通常我们都会遇到判断一个元素是否在某个集合中的业务场景,这个时候我们可能都是采用 HashMap的Put方法或者其他集合将数据保存起来,然后进行比较确定,但是如果元素很多的情况下,采用这种方式就会非常浪费空间,最终达到瓶颈,检索速度也会越来越慢,这时布隆过滤器(Bloom Filter)就应运而生了。
布隆过滤器的优点:
- 支持海量数据场景下高效判断元素是否存在
- 布隆过滤器存储空间小,并且节省空间,不存储数据本身,仅存储hash结果取模运算后的位标记
- 不存储数据本身,比较适合某些保密场景
布隆过滤器的缺点:
- 不存储数据本身,所以只能添加但不可删除,因为删掉元素会导致误判率增加
- 由于存在hash碰撞,匹配结果如果是“存在于过滤器中”,实际不一定存在
- 当容量快满时,hash碰撞的概率变大,插入、查询的错误率也就随之增加了
布隆过滤器中一个元素如果判断结果为存在的时候元素不一定存在,但是判断结果为不存在的时候则一定不存在。因此,布隆过滤器不适合那些对结果必须精准的应用场景。
其他问题
- 不支持计数,同一个元素可以多次插入,但效果和插入一次相同
- 由于错误率影响hash函数的数量,当hash函数越多,每次插入、查询需做的hash操作就越多
布隆过滤器适合的场景
- 区块链中使用布隆过滤器来加快钱包同步;以太坊使用布隆过滤器用于快速查询以太坊区块链的日志
- 数据库防止穿库,Google Bigtable,HBase 和 Cassandra 以及 Postgresql 使用BloomFilter来减少不存在的行或列的磁盘查找。避免代价高昂的磁盘查找会大大提高数据库查询操作的性能
- 判断用户是否阅读过某一个视频或者文章,类似抖音,刷过的视频往下滑动不再刷到,可能会导致一定的误判,但不会让用户看到重复的内容
- 网页爬虫对URL去重,采用布隆过滤器来对已经爬取过的URL进行存储,这样在进行下一次爬取的时候就可以判断出这个URL是否爬取过了
- 使用布隆过滤器来做黑名单过滤,针对不同的用户是否存入白名单或者黑名单,虽然有一定的误判,但是在一定程度上还是很好的解决问题
- 缓存击穿场景,一般判断用户是否在缓存中,如果存在则直接返回结果,不存在则查询数据库,如果来一波冷数据,会导致缓存大量击穿,造成雪崩效应,这时候可以用布隆过滤器当缓存的索引,只有在布隆过滤器中,才去查询缓存,如果没查询到则穿透到数据库查询。如果不在布隆过滤器中,则直接返回,会造成一定程度的误判
- WEB拦截器,如果相同请求则拦截,防止重复被攻击。用户第一次请求,将请求参数放入布隆过滤器中,当第二次请求时,先判断请求参数是否被布隆过滤器命中。可以提高缓存命中率。Squid 网页代理缓存服务器在 cache digests 中就使用了布隆过滤器。Google Chrome浏览器使用了布隆过滤器加速安全浏览服务
- Google 著名的分布式数据库 Bigtable 使用了布隆过滤器来查找不存在的行或列,以减少磁盘查找的IO次数
- Squid 网页代理缓存服务器在 cache digests 中使用了也布隆过滤器
- Venti 文档存储系统也采用布隆过滤器来检测先前存储的数据
- SPIN 模型检测器也使用布隆过滤器在大规模验证问题时跟踪可达状态空间
- Google Chrome浏览器使用了布隆过滤器加速安全浏览服务
如果允许误判率的话,可以使用布隆过滤器,只有你想不到的,没有你做不到的。
布隆过滤器原理
数据结构
布隆过滤器是由一个固定大小的二进制向量或者位图(bitmap)和一系列映射函数组成的。
对于长度为 m 的位数组,在初始状态时,它所有位置都被置为0,如下图所示:
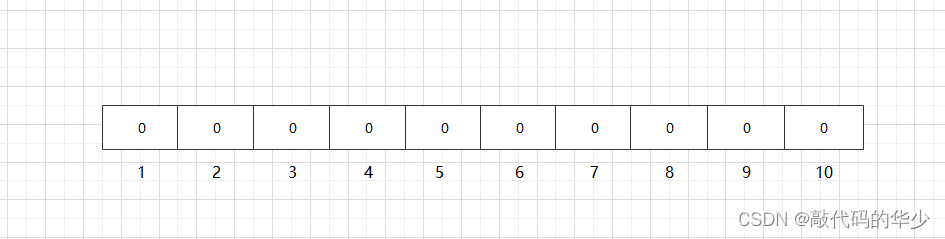
位数组中的每个元素都只占用 1 bit ,并且数组中元素只能是 0 或者 1。这样申请一个 100w 个元素的位数组只占用 1000000Bit / 8 = 125000 Byte = 125000/1024 KB ≈ 122KB 的空间。
增加元素
当一个元素加入布隆过滤器中的时候,会进行如下操作:
- 使用布隆过滤器中的哈希函数对元素值进行计算,得到哈希值(有几个哈希函数得到几个哈希值)
- 根据得到的哈希值,在位数组中把对应下标的值置为 1
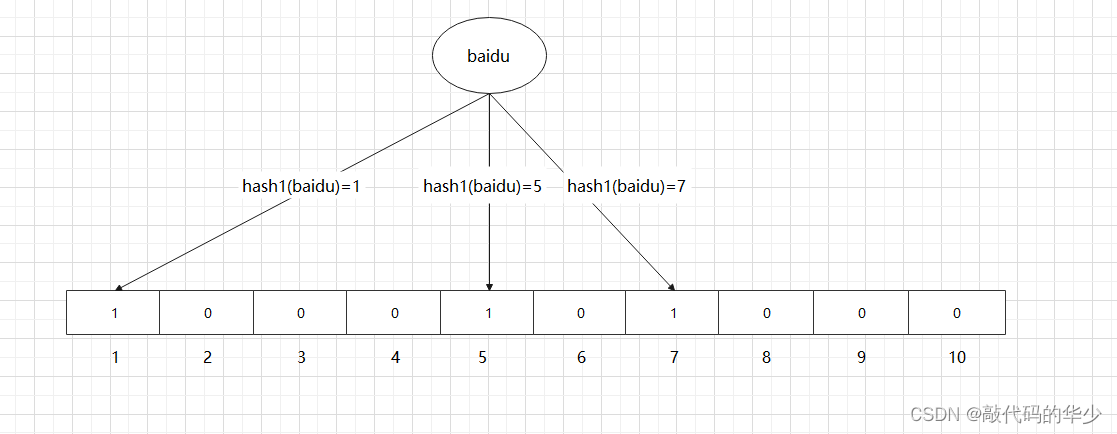
接着再添加一个值 “xinlang”,哈希函数的值是3、5、8,如下图所示:
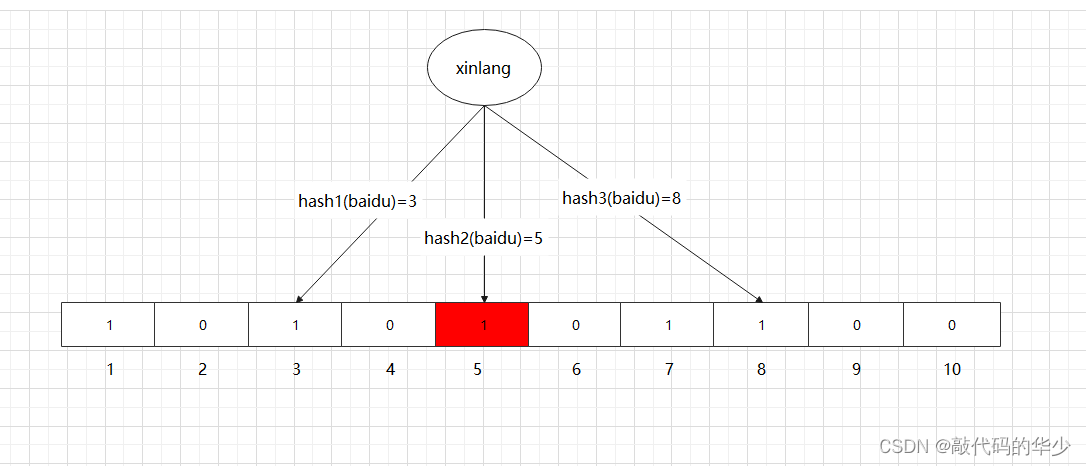
这里需要注意的是,5 这个 bit 位由于两个值的哈希函数都返回了这个 bit 位,因此被覆盖了。
查询元素
- 对给定元素再次进行相同的哈希计算
- 得到哈希值之后判断位数组中的每个元素是否都为 1,如果值都为 1,那么说明这个值存在布隆过滤器当中,如果存在一个值不为 1,说明该元素不在布隆过滤器中
如下图所示:
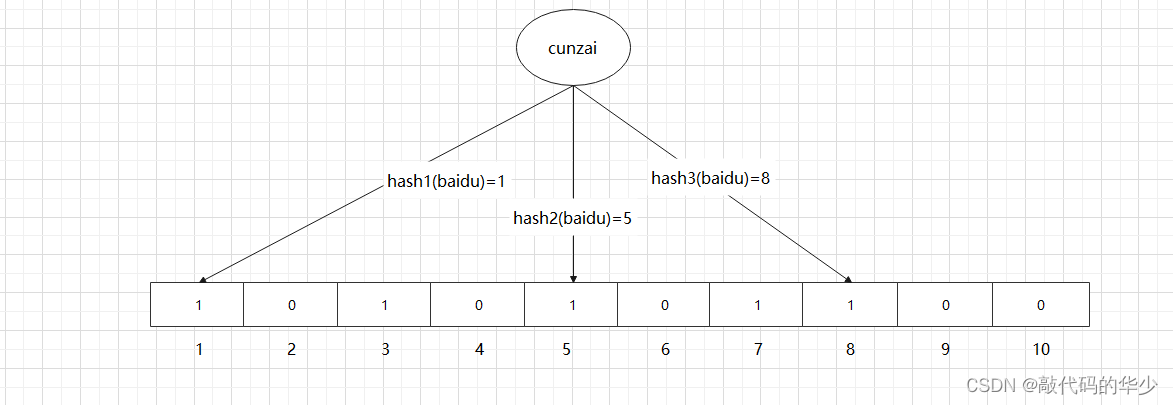
结果得到三个 1 ,说明 “cunzai” 是有可能存在的。
为什么说是可能存在,而不是一定存在呢?主要分为以下几种情况:
因为映射函数本身就是散列函数,散列函数是会有碰撞的情况发生。
- 情况1:一个字符串可能是 “chongtu” 经过相同的三个映射函数运算得到的三个点跟 “xinlang” 是一样的,这种情况下我们就说出现了误判
- 情况2: “chongtu” 经过运算得到三个点位上的 1 是两个不同的变量经过运算后得到的,这也不能证明字符串 “chongtu” 是一定存在的
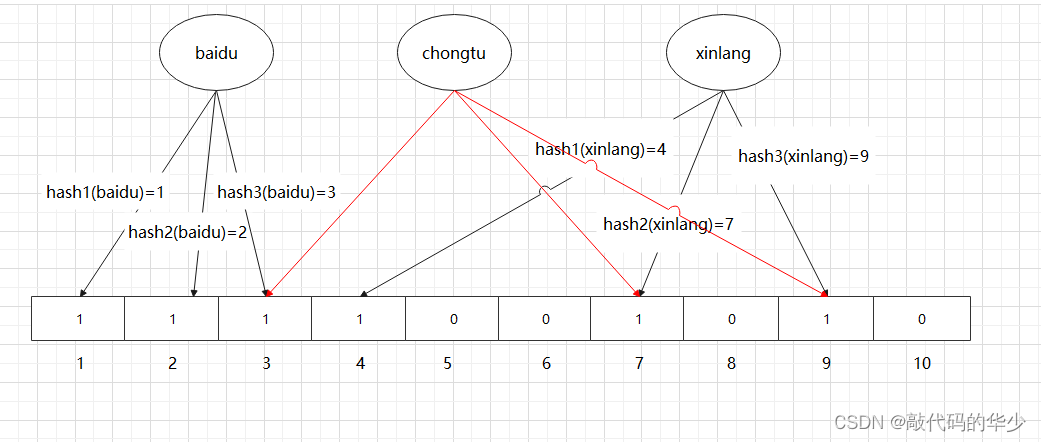
鉴于上面的情况,不同的字符串可能哈希出来的位置相同,这种情况我们可以适当增加位数组大小或者调整哈希函数。
布隆过滤器判定某个元素存在,小概率会误判;布隆过滤器判定某个元素不在,则这个元素一定不在。
删除元素
布隆过滤器对元素的删除,肯定不可以,会出现问题,比如上面添加元素的 bit 位 5 被两个变量的哈希值共同覆盖的情况下,一旦我们删除其中一个值。例如“xinlang”而将其置位 0,那么下次判断另一个值例如“baidu”是否存在的话,会直接返回 false,而实际上我们并没有删除它,这就导致了误判的问题。
如何使用布隆过滤器
Google开源的Guava自带布隆过滤器
首先引入Guava的依赖:
那么,在数据量很大的情况下,效率如何呢?
BloomFilter<Integer> bloomFilter = BloomFilter.create(Funnels.integerFunnel(), 5000000);for (int i = 0; i < 5000000; i++) {bloomFilter.put(i);}long start = System.nanoTime();if (bloomFilter.mightContain(500000)) {System.out.println("成功过滤到500000");}long end = System.nanoTime();System.out.println("布隆过滤器消耗时间"+(end - start)/1000000L+"毫秒");
成功过滤到500000
布隆过滤器消耗时间0毫秒
- 1
- 2
布隆过滤器消耗时间:0毫秒,有点不敢相信呢,匹配速度是不是很快?
那么,在数据量很大的情况下,1%的误判率结果如何?
BloomFilter<String> bloomFilter = BloomFilter.create(Funnels.stringFunnel(Charsets.UTF_8),5000000,0.01);List<String> list = new ArrayList<>(5000000);for (int i = 0; i < 5000000; i++) {String uuid = UUID.randomUUID().toString();bloomFilter.put(uuid);list.add(uuid);}int mightContainNumber1= 0;NumberFormat percentFormat =NumberFormat.getPercentInstance();percentFormat.setMaximumFractionDigits(2);
3%的误判率结果如何?
创建一个最多添加 500 个整数的布隆过滤器,并且可以容忍误判率为百分之一(0.01)
public void bool(){BloomFilter<Integer> filter = BloomFilter.create(Funnels.integerFunnel(), 500, 0.01);// 判断指定元素是否存在System.out.println(filter.mightContain(1));System.out.println(filter.mightContain(2));// 将元素添加进布隆过滤器filter.put(1);filter.put(2);// 判断指定元素是否存在System.out.println(filter.mightContain(1));System.out.println(filter.mightContain(2));}
从上面的结果可以看出:
- 如果元素实际存在,那么布隆过滤器一定会判断存在
- 误判率即fpp在3%左右,随着for循环的次数越大,而且越接近3%,那么如果元素不存在,那么布隆过滤器可能会判断存在
看源码可知这个3%的fpp是Guava中默认的fpp
public static <T> BloomFilter<T> create(Funnel<? super T> funnel, long expectedInsertions) {return create(funnel, expectedInsertions, 0.03); // FYI, for 3%, we always get 5 hash functions}
- 1
- 2
- 3
如下地址是一个免费的在线布隆过滤器在线计算的网址:
点击这里
经过哈希计算次数设置为3次,这个3%的误判率和3次哈希运算需要多大空间位数组呢?
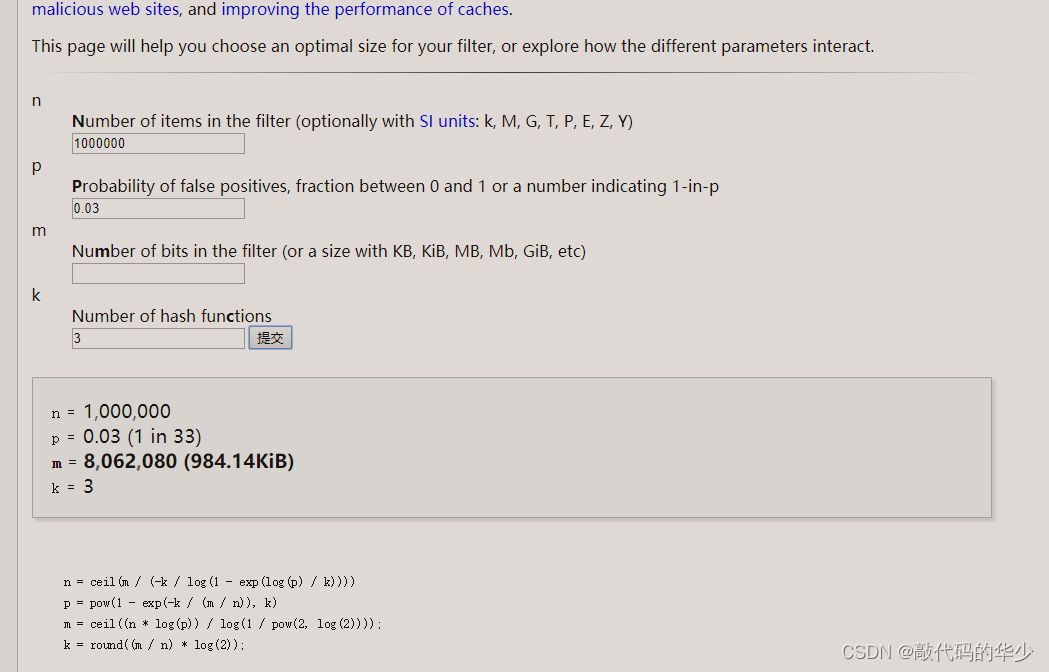
计算得到的结果是984.14KiB,100W的key才占用了0.98M,而如果是10亿呢,计算的结果是960M,这个内存空间是完全可以接受的。
Guava 提供的布隆过滤器的实现还是很不错的,但是它有一个重大的缺陷就是只能单机使用(另外,容量扩展也不容易),而现在互联网一般都是分布式的场景。为了解决这个问题就需要用到Redis中的布隆过滤器了。
Redis实现布隆过滤器
Redis中配置布隆过滤器
1、点击https://redis.io/modules 找到RedisBloom
2、点击进去下载RedisBloom-master.zip文件,上传到linux
3、解压缩刚才的RedisBloom文件
unzip RedisBloom-master.zip
cd RedisBloom-master
- 1
- 2
编译安装
make
- 1
make完生成redisbloom.so,拷贝到redis的安装目录。
cp redisbloom.so /home/www/server/redis
- 1
在redis.conf配置文件中加入如RedisBloom的redisbloom.so文件的地址,如果是集群则每个配置文件中都需要加入redisbloom.so文件的地址
loadmodule /home/www/server/redis/redisbloom.so
- 1
保存以后重启redis服务
redis-server redis.conf --loadmodule /home/www/server/redis/redisbloom.so
- 1
上面我们有提到需要重启Redis,在本地和测试环境还可以,但是正式环境能不重启就不需要重启,那这么做可以不重启Redis,使用module load命令执行。
> MODULE LOAD /home/www/server/redis/redisbloom.so
> module list
1) 1) "name"2) "bf"3) "ver"4) (integer) 999999
- 1
- 2
- 3
- 4
- 5
- 6
看到以上数据则说明redisbloom加载成功了,模块名name为"bf",模块版本号ver为999999。
Redis中布隆过滤器指令使用
使用布隆过滤器完整指令请到官网查看: 点击这里
自定义参数
- bf.reserve {key} {error_rate} {capacity}
- 使用给定的期望错误率和初始容量创建空的布隆过滤器
- 参数说明:
- key:布隆过滤器的key
- error_rate:期望的错误率(False Positive Rate),该值必须介于0和1之间。该值越小,BloomFilter的内存占用量越大,CPU使用率越高
- capacity:布隆过滤器的初始容量,即期望添加到布隆过滤器中的元素的个数。当实际添加的元素个数超过该值时,布隆过滤器将进行自动的扩容,该过程会导致性能有所下降,下降的程度是随着元素个数的指数级增长而线性下降
- 返回值:
- 成功:OK
- 其它情况返回相应的异常信息
基本操作
- bf.add {key} {item}
- 添加单个元素
- 参数说明:
- key:布隆过滤器的名字
- item:待插入过滤器的元素
- 返回值:
- 元素不存在插入成功:返回1
- 元素可能已经存在:返回0
- 其它情况返回相应的异常信息
- bf.madd {key} {item} [item...]
- 添加多个元素
- 参数说明:
- key:布隆过滤器的名字
- item:待插入过滤器的元素,可插入多个
- 返回值:
- 成功:返回一个数组,数组的每一个元素可能为1或0,当item一定不存在时数组元素值为1,当item可能已经存在时数组元素值为0
- 其它情况返回相应的异常信息
- bf.exists{key} {item}
- 判断单个元素是否存在
- 参数说明:
- key:布隆过滤器的名字
- item:待检查的元素
- 返回值:
- 元素一定不存在:0
- 元素可能存在:1
- 其它情况返回相应的异常信息
- bf.mexists{key} {item} [item...]
- 判断多个元素是否存在
- 参数说明:
- key:布隆过滤器的名字
- item:待检查的元素
- 返回值:
- 元素一定不存在:0
- 元素可能存在:1
- 其它情况返回相应的异常信息
- bf.insert{key} [CAPACITY {cap}] [ERROR {ERROR}] [NOCREATE] ITEMS {item…}
- 向key指定的Bloom中添加多个元素,添加时可以指定大小和错误率,且可以控制在Bloom不存在的时候是否自动创建
- 参数说明:
- key:布隆过滤器的名字
- CAPACITY:如果过滤器已创建,则此参数将被忽略
- ERROR:如果过滤器已创建,则此参数将被忽略
- expansion:布隆过滤器会自动创建一个子过滤器,子过滤器的大小是上一个过滤器大小乘以expansion。expansion的默认值是2,也就是说布隆过滤器扩容默认是2倍扩容。
- NOCREATE:如果设置了该参数,当布隆过滤器不存在时则不会被创建。用于严格区分过滤器的创建和元素插入场景。该参数不能与CAPACITY和ERROR同时设置。
- NONSCALING:设置此项后,当添加到布隆过滤器中的数据达到初始容量后,不会扩容过滤器,并且会抛出异常((error) ERR non scaling filter is full)。
- ITEMS:待插入过滤器的元素列表,该参数必传。
- 返回值:
- 成功:返回一个数组,数组的每一个元素可能为1或0,当item一定不存在时数组元素值为1,当item可能已经存在时数组元素值为0
- 其它情况返回相应的异常信息
127.0.0.1:6379> bf.insert name items zhangsan1 zhangsan2 zhangsan3
1) (integer) 1
2) (integer) 1
3) (integer) 1
127.0.0.1:6379> bf.insert name items zhangsan1 zhangsan2 zhangsan3
1) (integer) 0
2) (integer) 0
3) (integer) 0
127.0.0.1:6379> bf.insert name capacity 10000 error 0.00001 nocreate items zhangsan1 zhangsan2 zhangsan3
1) (integer) 0
2) (integer) 0
3) (integer) 0
127.0.0.1:6379>
127.0.0.1:6379> bf.insert name capacity 10000 error 0.00001 nocreate items zhangsan4 zhangsan5 zhangsan6
1) (integer) 1
2) (integer) 1
3) (integer) 1
127.0.0.1:6379>

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- bf.scandump {key} {item}
- 对布隆过滤器进行增量持久化操作
- 参数说明:
- key:布隆过滤器的名字
- item:首次调用传值0,或者上次调用此命令返回的结果值
- 返回值:
- 返回连续的(iter, data)对,直到(0,NULL),表示DUMP完成
- 其它情况返回相应的异常信息
- bf.scandump {key} {item}
- 对布隆过滤器进行增量持久化操作
- 参数说明:
- key:布隆过滤器的名字
- item:首次调用传值0,或者上次调用此命令返回的结果值
- 返回值:
- 返回连续的(iter, data)对,直到(0,NULL),表示DUMP完成
- 其它情况返回相应的异常信息
- bf.info {key}
- 返回布隆过滤器的相关信息
- 参数说明:
- key:布隆过滤器的名字
- 返回值:
- Capacity:预设容量
- Size:实际占用情况,但如何计算待进一步确认
- Number of filters:过滤器层数
- Number of items inserted:已经实际插入的元素数量
- Expansion rate:子过滤器扩容系数(默认2)
- bf.debug{key}
- 查看布隆过滤器的内部详细信息
- 参数说明:
- key:布隆过滤器的名字
- 返回值:
- size:布隆过滤器中已插入的元素数量
- 每层BloomFilter的详细信息
- bytes:占用字节数量
- bits:占用bit位数量,bits = bytes * 8
- shashes:该层hash函数数量
- hashwidth:hash函数宽度
- capacity:该层容量(第一层为BloomFilter初始化时设置的容量,第2层容量 = 第一层容量 * expansion,以此类推)
- size:该层中已插入的元素数量(各层size之和等于BloomFilter中已插入的元素数量size)
- ratio:该层错误率(第一层的错误率 = BloomFilter初始化时设置的错误率 * 0.5,第二层为第一层的0.5倍,以此类推,ratio与expansion无关)
#创建一个容量为5的布隆过滤器,其key为“name”;
127.0.0.1:6379> bf.reserve name0.1 5
OK
编写代码测试
public void patchingConsum(ConsumPatchingVO vo) throws ParseException {Config config = new Config();SingleServerConfig singleServerConfig = config.useSingleServer();singleServerConfig.setAddress("redis://127.0.0.1:6379");singleServerConfig.setPassword("123456");RedissonClient redissonClient = Redisson.create(config);RBloomFilter<String> bloom = redissonClient.getBloomFilter("name");// 初始化布隆过滤器; 大小:100000,误判率:0.01bloom.tryInit(100000L, 0.01);// 新增10万条数据for(int i=0;i<100000;i++) {bloom.add("name" + i);}// 判断不存在于布隆过滤器中的元素List<String> notExistList = new ArrayList<>();for(int i=0;i<100000;i++) {String str = "name" + i;boolean notExist = bloom.contains(str);if (notExist) {notExistList.add(str);}}if ($.isNotEmpty(notExistList) && notExistList.size() > 0 ) {System.out.println("误判次数:"+notExistList.size());}