转载请注明出处:小锋学长生活大爆炸[xfxuezhagn.cn]
如果本文帮助到了你,欢迎[点赞、收藏、关注]哦~
目录
函数说明
用法示例
示例 1: 获取所有边的源节点和目标节点
示例 2: 获取特定节点的出边
示例 3: 获取所有边的边ID
示例 4: 获取所有信息(源节点、目标节点和边ID)
示例 5: 对于有多种边缘类型的图形,需要在查询中指定边的类型
示例 6:对于无向图,则边是双向的
dgl.DGLGraph.out_edges — DGL 2.3 documentation
函数说明
dgl.DGLGraph.out_edges 是 DGL(Deep Graph Library)中的一个方法,用于获取图中所有边的源节点和目标节点。这个方法可以用于返回整个图的边,也可以通过传入指定的节点来获取从这些节点出发的边。
DGLGraph.out_edges(u=ALL, etype=None, form='uv')
参数
-
u(节点ID):- 可以是 单个节点ID(整数)。
- 可以是 节点ID的张量(Int Tensor),每个元素是一个节点ID。张量的设备类型和ID数据类型必须与图的相同。
- 可以是 可迭代的节点ID列表(iterable[int]),每个元素是一个节点ID。
-
form(字符串,可选):'eid': 返回1D张量,表示所有边的ID。'uv'(默认): 返回一个2元组(1D张量),分别表示所有边的源节点和目标节点。'all': 返回一个3元组(1D张量),分别表示所有边的源节点、目标节点和边ID。
-
etype(字符串或(字符串, 字符串, 字符串),可选):- 边的类型名称。格式可以是 (源节点类型, 边类型, 目标节点类型)。
- 或者是一个唯一标识三元组格式的字符串类型名称。如果图中只有一种类型的边,可以省略。
返回值
- 返回所有指定类型节点的出边。返回形式取决于
form参数的值。'eid': 返回一个1D张量,表示所有边的ID。'uv': 返回一个2元组(1D张量),分别表示所有边的源节点和目标节点。'all': 返回一个3元组(1D张量),分别表示所有边的源节点、目标节点和边ID。
用法示例
我们创建一个如图所示的简单的graph:

示例 1: 获取所有边的源节点和目标节点
import dgl
import torch# 创建一个简单的图,包含4个节点和4条边
u = torch.tensor([0, 0, 1, 2])
v = torch.tensor([1, 2, 3, 3])
graph = dgl.graph((u, v))# 获取所有边的源节点和目标节点
src, dst = graph.out_edges(graph.nodes())print("源节点:", src)
print("目标节点:", dst)# 源节点: tensor([0, 0, 1, 2])
# 目标节点: tensor([1, 2, 3, 3])
示例 2: 获取特定节点的出边
# 获取节点0和节点1的出边
nodes = torch.tensor([0, 1])
src, dst = graph.out_edges(nodes)print("源节点:", src)
print("目标节点:", dst)# 源节点: tensor([0, 0, 1])
# 目标节点: tensor([1, 2, 3])
示例 3: 获取所有边的边ID
# 获取所有边的边ID
edge_ids = graph.out_edges(graph.nodes(), form='eid')print("边ID:", edge_ids)# 边ID: tensor([0, 1, 2, 3])
示例 4: 获取所有信息(源节点、目标节点和边ID)
# 获取所有边的源节点、目标节点和边ID
src, dst, eid = graph.out_edges(graph.nodes(), form='all')print("源节点:", src)
print("目标节点:", dst)
print("边ID:", eid)# 源节点: tensor([0, 0, 1, 2])
# 目标节点: tensor([1, 2, 3, 3])
# 边ID: tensor([0, 1, 2, 3])
示例 5: 对于有多种边缘类型的图形,需要在查询中指定边的类型
hg = dgl.heterograph({('user', 'follows', 'user'): (torch.tensor([0, 1]), torch.tensor([1, 2])),('user', 'plays', 'game'): (torch.tensor([3, 4]), torch.tensor([5, 6]))
})
hg.out_edges(torch.tensor([1, 2]), etype='follows')# (tensor([1]), tensor([2]))示例 6:对于无向图,则边是双向的
注意:在dgl的图中,所有边都是有向的,如果要创建无向图,需要创建双向边。

import dgl
import torch# 创建一个无向图,包含4个节点和4条边
u = torch.tensor([0, 0, 1, 2])
v = torch.tensor([1, 2, 3, 3])# 创建双向边以模拟无向图
u_bi = torch.cat([u, v])
v_bi = torch.cat([v, u])graph = dgl.graph((u_bi, v_bi))
# 简化图
graph = dgl.to_simple(graph)# 获取节点的出边
src, dst = graph.out_edges([1, 3])print("源节点:", src)
print("目标节点:", dst)# 源节点: tensor([1, 1, 3, 3])
# 目标节点: tensor([3, 0, 1, 2])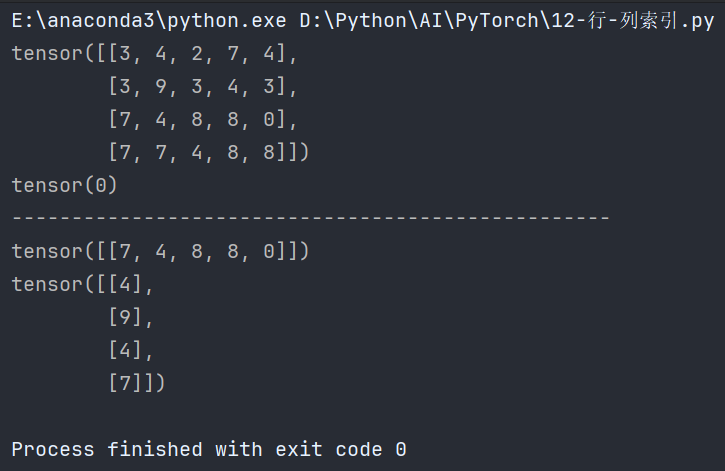











![java基础之数组,int[]和ArrayList](https://i-blog.csdnimg.cn/direct/540aff9c491644dbb4fcc1a400bc3f35.png)