文章目录
- 1、简介
- 1.1、基本概念
- 1.2、索引类型
- 1.3、数据准备
- 1.4、技术摘要⭐
- 2、简单行、列索引
- 3、列表索引
- 4、范围索引
- 5、布尔索引
- 6、多维索引
🍃作者介绍:双非本科大三网络工程专业在读,阿里云专家博主,专注于Java领域学习,擅长web应用开发、数据结构和算法,初步涉猎人工智能和前端开发。
🦅个人主页:@逐梦苍穹
📕所属专栏:人工智能
🌻gitee地址:xzl的人工智能代码仓库
✈ 您的一键三连,是我创作的最大动力🌹
1、简介
我们在操作张量时,经常需要去进行获取或者修改操作,掌握张量的花式索引操作是必须的一项能力。
张量索引是指从多维数组(即张量)中访问特定元素、子张量或切片的过程。理解张量索引是操作和处理张量数据的基础。下面是一些关于张量索引的理论知识:
1.1、基本概念
- 张量:张量是多维数组的泛化,可以是标量、向量、矩阵或更高维度的数组。例如,标量是0维张量,向量是1维张量,矩阵是2维张量,三维及更高维度的数组也是张量。
- 维度(Dimension):张量的维度数,表示数组在每个方向上的大小。
- 形状(Shape):描述张量在每个维度上的大小。例如,形状为(2, 3, 4)的张量表示它有3个维度,每个维度分别有2、3、4个元素。
1.2、索引类型
张量索引主要有以下几种类型:
- 整型索引(Integer Indexing):
- 使用一个或多个整型值来访问张量中的特定元素或子张量。
- 例如,对于一个形状为(3, 4)的二维张量
A,A[1, 2]访问的是第二行第三列的元素(索引从0开始)。
- 切片索引(Slicing):
- 使用冒号
:表示范围,来访问张量的子集。 - 例如,对于一个形状为(3, 4)的二维张量
A,A[1:3, :]访问的是第二行和第三行的所有列。
- 使用冒号
- 高级索引(Advanced Indexing):
- 使用数组或张量作为索引,以访问特定模式的元素。
- 例如,对于一个形状为(3, 4)的二维张量
A,A[[0, 2], [1, 3]]访问的是(0,1)和(2,3)位置的元素。
- 布尔索引(Boolean Indexing):
- 使用布尔数组或张量来筛选符合条件的元素。
- 例如,对于一个形状为(3, 4)的二维张量
A,A[A > 5]访问的是所有大于5的元素。
1.3、数据准备
下面在进行代码演示之前,先准备一份数据:
import torch
data = torch.randint(0, 10, [4, 5])
print(data)
print('-' * 50)
1.4、技术摘要⭐
| 索引类型 | 描述 | 代码方法 |
|---|---|---|
| 整型索引 | 使用一个或多个整型值来访问张量中的特定元素或子张量 | tensor[index] 访问张量 tensor 的特定元素或子张量, |
例如 tensor[1, 2] 访问二维张量的第二行第三列元素 | ||
| 切片索引 | 使用冒号 : 表示范围,访问张量的子集 | tensor[start:stop:step] 访问 tensor 的子集, |
例如 tensor[1:3, :] 访问二维张量的第二行和第三行的所有列 | ||
| 高级索引 | 使用数组或张量作为索引,以访问特定模式的元素 | tensor[indices] 访问 tensor 的特定模式元素, |
例如 tensor[[1, 2], [2, 3]] 访问特定位置的元素 | ||
| 布尔索引 | 使用布尔数组作为掩码,访问满足条件的元素 | tensor[mask] 访问 tensor 中满足 mask 条件的元素, |
例如 tensor[tensor > 0] 访问所有大于0的元素 |
2、简单行、列索引
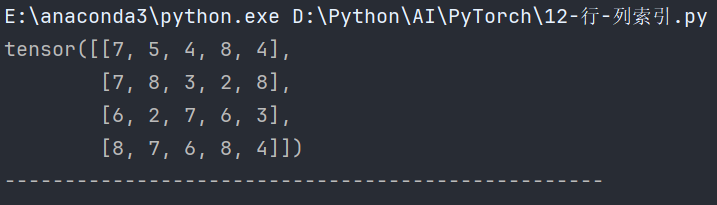
data[0]获取并打印张量的第一行。
data[:, 0]获取并打印张量的第一列。
def test01():print(data[0])print(data[:, 0])print('-' * 50)
3、列表索引
在PyTorch和其他基于NumPy的库中,列表索引是一种高级索引方式,允许使用列表或数组中的索引来选择张量中的特定元素。
这种索引方式可以比传统的切片更灵活、更强大。
基本概念:
- 列表索引:使用一个或多个列表来索引张量,提取出特定的元素。
- 广播机制:当列表索引的形状不匹配时,会自动
扩展(广播)这些索引,使得它们可以一起使用。
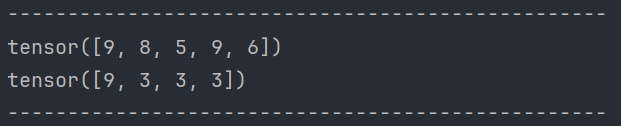
def test02():# 返回 (0, 1)、(1, 2) 两个位置的元素print(data[[0, 1], [1, 2]])print('-' * 50)# 返回 0、1 行的 1、2 列共4个元素print(data[[[0], [1]], [1, 2]])print(data[[[2], [3]], [1, 2]])print(data[[[0, 1], [1, 2]], [1, 2]])print(data[[[0, 1], [2, 3]], [1, 2]])
输出:
E:\anaconda3\python.exe D:\Python\AI\PyTorch\12-行-列索引.py
tensor([[2, 4, 2, 0, 4],[0, 8, 4, 7, 6],[8, 7, 3, 7, 3],[0, 2, 6, 2, 9]])
tensor(3)
--------------------------------------------------
tensor([4, 4])
--------------------------------------------------
tensor([[4, 2],[8, 4]])
tensor([[7, 3],[2, 6]])
tensor([[4, 4],[8, 3]])
tensor([[4, 4],[7, 6]])Process finished with exit code 0
下面我会详细介绍下面这四个数据的计算过程:
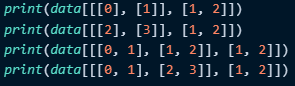
如下所示:



4、范围索引
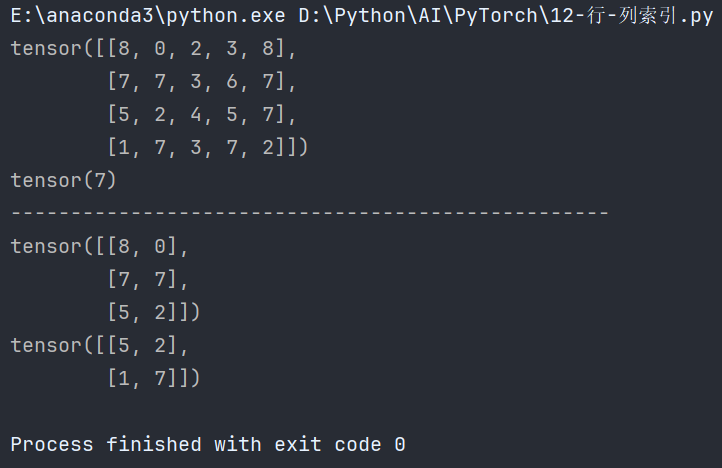
# 3. 范围索引
def test03():# 前3行的前2列数据print(data[:3, :2])# 第2行到最后的前2列数据print(data[2:, :2])
if __name__ == '__main__':test03()
5、布尔索引
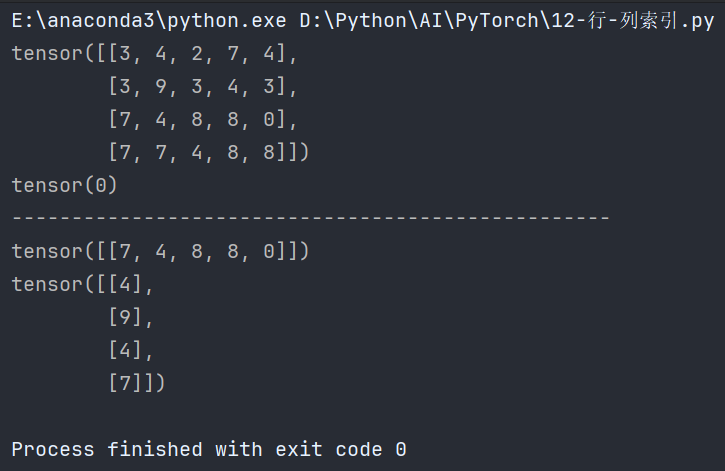
# 布尔索引
def test04():# 第三列大于5的行数据print(data[data[:, 2] > 5])# 第二行大于5的列数据print(data[:, data[1] > 5])
if __name__ == '__main__':test04()
6、多维索引
# 多维索引
def test05():data = torch.randint(0, 10, [3, 4, 5])print(data)print('-' * 50)print(data[0, :, :])print(data[:, 0, :])print(data[:, :, 0])if __name__ == '__main__':test05()
输出:
E:\anaconda3\python.exe D:\Python\AI\PyTorch\12-行-列索引.py
tensor([[[9, 2, 4, 0, 9],[3, 6, 7, 1, 9],[9, 3, 8, 3, 3],[5, 6, 8, 2, 0]],[[4, 1, 7, 8, 1],[2, 1, 3, 3, 5],[7, 2, 6, 0, 1],[7, 0, 3, 2, 4]],[[0, 1, 7, 3, 3],[1, 0, 0, 9, 9],[8, 7, 9, 9, 7],[1, 9, 1, 3, 1]]])
--------------------------------------------------
tensor([[9, 2, 4, 0, 9],[3, 6, 7, 1, 9],[9, 3, 8, 3, 3],[5, 6, 8, 2, 0]])
tensor([[9, 2, 4, 0, 9],[4, 1, 7, 8, 1],[0, 1, 7, 3, 3]])
tensor([[9, 3, 9, 5],[4, 2, 7, 7],[0, 1, 8, 1]])Process finished with exit code 0











![java基础之数组,int[]和ArrayList](https://i-blog.csdnimg.cn/direct/540aff9c491644dbb4fcc1a400bc3f35.png)