【ACM】作者从聚合后节点相似性的角度重新审视异配性,并定义了新的同质性度量方法。基于聚合相似度度量这一指标,作者提出了一种新的框架,称为自适应信道混合(Adaptive Channel Mixing,ACM),它通过自适应地利用聚合、多样化和身份信道来提取更丰富的局部信息,以对应不同的节点异配性情况。
发表在2022年NeurIPS会议上,作者是McGill University的,引用量155,开源代码可以复现。
NeurIPS会议简介:全称Conference on Neural Information Processing Systems(神经信息处理系统大会),机器学习和计算神经科学领域的顶级学术会议,CCF A。
查询会议:
- 会伴:https://www.myhuiban.com/
- CCF deadline:https://ccfddl.github.io/
原文和开源代码链接:
- paper原文:https://arxiv.org/abs/2210.07606
- 开源代码:https://github.com/SitaoLuan/ACM-GNN
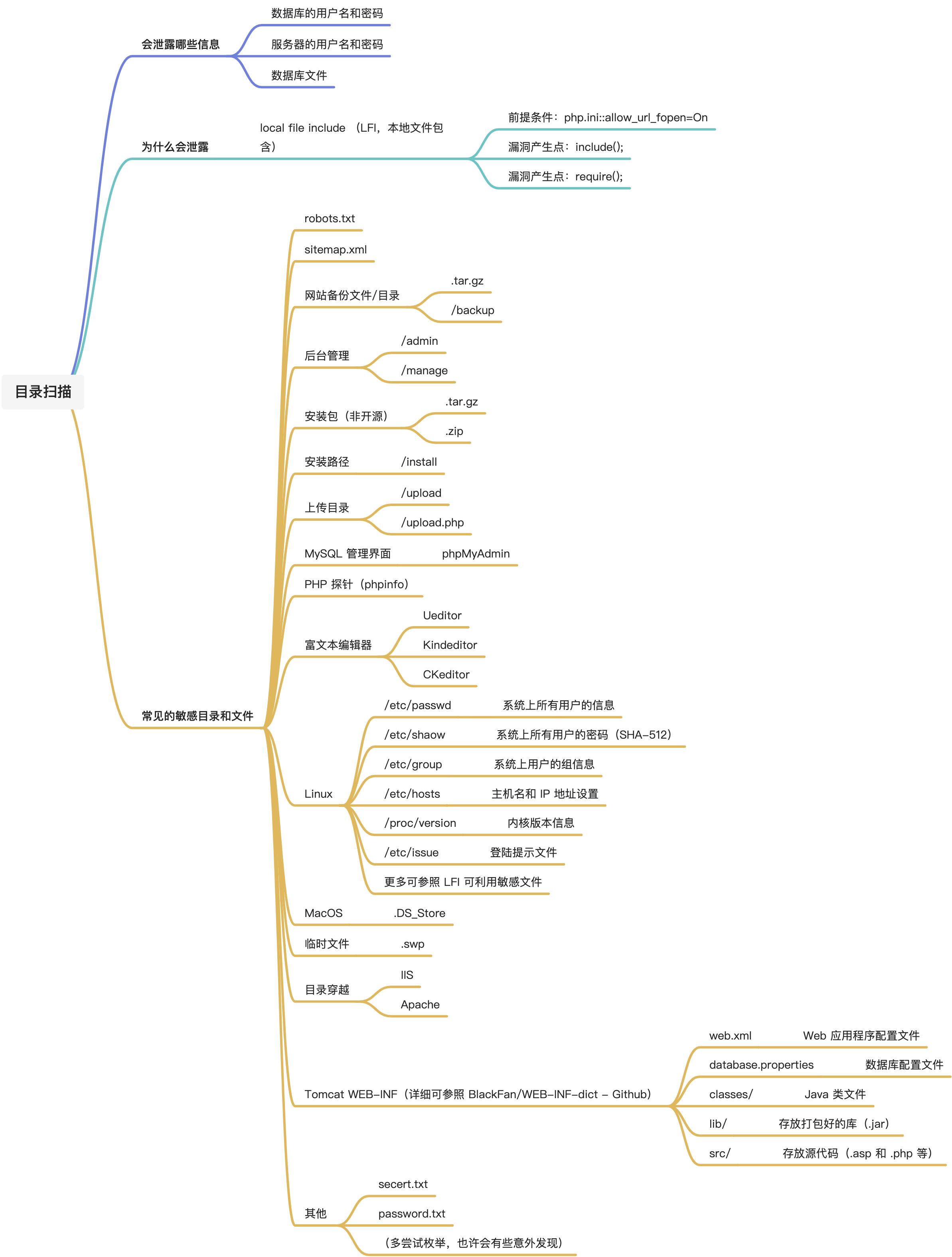
0、核心内容
背景与问题:传统的图神经网络基于同质性假设,即连接的节点倾向于具有相似的属性。然而,最近的研究发现,在某些数据集上,GNNs相对于传统的神经网络并没有表现出优势。这被认为是由于异配性问题,即同质性假设并不总是成立。
同质性度量:论文首先回顾了现有同质性度量方法,并指出了它们只考虑标签一致性的缺点。
异配性分析:作者从聚合后节点相似性的角度重新审视异配性,并定义了新的同质性度量方法。
局部多样化操作:论文证明了局部多样化操作可以有效解决一些异配性的不利情况。
自适应信道混合(ACM)框架:提出了一种新的框架,称为自适应信道混合(Adaptive Channel Mixing,ACM),它通过自适应地利用聚合、多样化和身份信道来提取更丰富的局部信息,以对应不同的节点异配性情况。
试验评估:ACM在10个基准节点分类任务上进行了评估,结果表明,ACM增强的基线模型在大多数任务上都取得了显著的性能提升,超过了现有的最先进GNN模型,同时没有带来显著的计算负担。
贡献:论文的主要贡献包括提出了从聚合后节点相似性角度分析异配性的新视角,提出了与现有方法不同的ACM框架,并通过实验验证了其有效性。
相关工作:论文讨论了其他研究者在处理GNNs中异配性问题时的工作,包括MixHop、Geom-GCN、H2GCN、CPGNN、FAGCN和GPRGNN等。
结论与局限性:论文总结了研究成果,并指出了当前方法的局限性,例如在处理某些有害异配性情况时的不足。
1、本文贡献
① 第一个从聚合后节点相似性的角度分析异配性;
② 提出ACM框架,与具有多通道的自适应滤波器库和现有GNN有很大不同:
传统的自适应滤波器通道为每一个滤波器使用一个标量权值,这个权值由所有节点共享;相比之下,ACM提供了一种机制,使不同的节点可以学习不同的权重,利用来自不同通道的信息来解释不同的局部异配性。
与现有的利用高频信号的高阶滤波器和全局特性而需要更多的计算资源不同,ACM通过自适应地考虑节点局部信息成功解决了异配性问题。
③ 与现有的试图促进高表达能力的学习过滤器不同,ACM的目标是,当给定具有一定表达能力的滤波器时,我们可以以某种方式从额外的通道中提取更丰富的信息来解决异配性。这使ACM更灵活,也更容易实现。
2、先验知识
① 什么是图-标签一致性(graph-label consistency)?
图-标签一致性是指在图数据结构中,节点的连接模式与节点标签(或类别)之间的一致性。在图神经网络的研究和应用中,这个概念尤为重要,因为它关系到图上的信息传播和节点分类任务的性能。
具体来说,如果一个图具有较高的图-标签一致性,那么意味着图中相同类别的节点更有可能彼此相连,而不同类别的节点则较少相连。这种情况下,图中的社区结构或群组比较明显,同质性现象突出。同质性是指节点倾向于与具有相似特征或标签的节点建立连接。
在论文中提到的现有同质性度量方法,如边同质性、节点同质性和类同质性,都是基于图-标签一致性来定义的,用以量化图中节点连接模式与节点标签一致的程度。这些度量通常在0到1的范围内,值越接近1表示图的同质性越强,即图中的连接更多地发生在相同标签的节点之间。
然而,论文指出仅考虑图-标签一致性的现有同质性度量方法存在局限性,因为它们不能充分描述异配性对基于聚合的GNNs的影响。异配性是指图中不同类别的节点之间存在连接,这可能会导致信息在不同类别的节点间错误传播,影响GNNs的性能。为了解决这个问题,论文提出了从聚合后节点相似性的角度来分析异配性,并定义了新的同质性度量方法。
② GCN损失函数定义
重归一化的亲和矩阵(the renormalized affinity matrix)本质上是为图中的每个节点添加了一个自循环,并在GCN中广泛应用如下:

GCN可以通过最小化以下交叉熵损失来训练:

其中:
L s y m + A s y m = I , A s y m = D − 1 / 2 A D − 1 / 2 L r w + A r w = I , A r w = D − 1 A L_{sym} + A_{sym} = I,\ A_{sym} = D^{-1/2}AD^{-1/2}\\ L_{rw} + A_{rw} = I,\ A_{rw} = D^{-1}A\\ Lsym+Asym=I, Asym=D−1/2AD−1/2Lrw+Arw=I, Arw=D−1A
- 对称归一化拉普拉斯算子: L s y m L_{sym} Lsym
- 对称归一化亲和矩阵: A s y m A_{sym} Asym
- 随机游走归一化拉普拉斯算子: L r w L_{rw} Lrw
- 随机游走归一化亲和矩阵: A r w A_{rw} Arw
- 重归一化后: A ^ = A + I , D ^ = D + I \hat{A} = A+I,\hat{D} = D+I A^=A+I,D^=D+I 。
③ 什么是gram matrix?
在机器学习和数学中,Gram矩阵(也称为Gramian矩阵)是一个矩阵 G G G,其元素由两个向量集合的內积构成。具体来说,如果有向量集合 { x 1 , x 2 , … … , x n } \{x_1,x_2,……,x_n\} {x1,x2,……,xn},那么Gram矩阵G定义为:
G i j = x i ⋅ x j G_{ij}=x_i·x_j Gij=xi⋅xj
其中, G i j G_{ij} Gij是矩阵 G G G中第 i i i行和第 j j j列的元素, x i x_i xi和 x j x_j xj是集合中的向量,而 · 表示向量的点积(內积)。
在不同的上下文中,Gram矩阵可能有不同的含义:
- 在优化和数值分析中,Gram矩阵可以用来表示二次型的矩阵,特别是在半正定规划和谱方法中。
- 在机器学习中,特别是在核方法(如支持向量机)中,Gram矩阵是核函数在训练样本上的应用结果,可以反映样本之间的相似性或距离。
- 在GNN中,如本文提到的,Gram矩阵可以由图上的信号处理得到,用于衡量节点特征在经过某种聚合操作后的相似性。例如, S ( A ^ , X ) S(\hat{A},X) S(A^,X)就是一个基于图的聚合操作 A ^ \hat{A} A^和特征矩阵 X X X计算得到的Gram矩阵。
- 在信号处理中,Gram矩阵可以用来分析信号的自相关性。
Gram矩阵的一个重要特性是它是对称且半正定的。如果向量集合是正交的,那么Gram矩阵将是对角矩阵,对角线上的元素是向量的模(或能量)的平方。在实际应用中,Gram矩阵的大小和特性可以提供有关向量集合结构的重要信息。
④ 什么是亲和矩阵(affinity matrix)?
亲和矩阵是一个在图机器学习和图信号处理中常用的概念,用于表示图中节点间的相似性或连接关系。在图的上下文中,亲和矩阵可以捕捉节点间的局部结构和邻域信息,通常用于GCNs和其他图学习方法中。
定义:亲和矩阵A是一个N×N的矩阵,其中N是图中节点的数量。矩阵中的每个元素 A i j A_{ij} Aij表示节点 i i i和节点 j j j之间的相似性或连接强度。
和邻接矩阵的关系:亲和矩阵通常从图的邻接矩阵派生而来,邻接矩阵是一个二值矩阵,其元素表示节点间是否存在边。亲和矩阵可以是对邻接矩阵的加权版本,权重可以根据边的类型或其他属性来定义。
归一化:在某些应用中,亲和矩阵会被归一化,以确保每行的和为1,这样它就可以被用作概率分布,表示节点通过随机游走到达其他节点的概率。
图卷积:在图卷积网络中,亲和矩阵用于聚合邻居节点的特征。例如,一个节点的新特征可以通过与其相邻节点的加权平均来计算,其中权重由亲和矩阵给出。
低通滤波器:在图信号处理中,亲和矩阵可以被视为低通滤波器,因为它倾向于保留图中的局部结构和平滑信号。
对称性和正定性:亲和矩阵通常是对称的,并且可以是正定的,这使得它们在数学分析和优化中具有良好的性质。
应用:亲和矩阵在图聚类、节点分类、图嵌入和图生成等任务中都有应用。通过学习或设计亲和矩阵,可以提高图学习方法的性能。
在图神经网络的背景下,亲和矩阵是实现节点间信息传递和特征聚合的关键组件,它直接影响到模型对图结构的理解和利用。
3、异配性分析
① Observation

异配性被广泛认为对基于消息传递的GNNs是有害的,因为直观上,不同类节点的特征会被错误地混合,导致节点是无法区分的。
然而,情况并不总是如此,例如,根据现有的同配性指标(边同配性、节点同配性和类同配性),图1所示的二部图是高度异配的,但在平均聚合后,第1类和第2类中的节点只是交换颜色,仍然可区分。
这个例子告诉我们,除了图-标签的一致性之外,我们还需要研究聚合步骤后节点之间的关系。
② Definition
为此,我们首先定义了聚合后的节点相似度矩阵(the post-aggregation node similarity matrix)如下:

其中, A ^ \hat{A} A^是一个通用的聚合算子,用于在GNN中聚合邻居节点的特征信息。 A ^ \hat{A} A^可以是随机游走归一化亲和矩阵 A ^ r w \hat{A}_{rw} A^rw或者对称归一化亲和矩阵 A ^ s y m \hat{A}_{sym} A^sym,本文用的是 A ^ r w \hat{A}_{rw} A^rw。
A ^ r w = D ^ − 1 A ^ A ^ = A + I D ^ = D + I \hat{A}_{rw}=\hat{D}^{-1}\hat{A}\\ \hat{A} = A+I\\ \hat{D} = D+I\\ A^rw=D^−1A^A^=A+ID^=D+I
S ( A ^ , X ) S(\hat{A},X) S(A^,X)本质上是度量每对聚合节点特征之间的相似性的gram matirx。
SGC:

SGC的梯度与 S ( A ^ , X ) S(\hat{A},X) S(A^,X)矩阵的关系——损失函数对 Y ′ Y' Y′求导:

其中 Z − Y Z-Y Z−Y是预测误差矩阵(prediction error matrix)。
The update direction of the prediction for node i is essentially a weighted sum of the prediction error。
节点 i i i预测的更新方向本质是预测误差的加权和。
[ S ( A ^ , X ) ] i j [S(\hat{A},X)]_{ij} [S(A^,X)]ij越大,意味着节点 i i i倾向于被更新到与节点 j j j相同的类。
举例:对于图1的二部图来说,计算 S ( A ^ , X ) = A ^ X ( A ^ X ) T S(\hat{A},X)=\hat{A}X(\hat{A}X)^T S(A^,X)=A^X(A^X)T,其中 A ^ = ( D + I ) − 1 ( A + I ) \hat{A}=(D+I)^{-1}(A+I) A^=(D+I)−1(A+I),其中 I I I为单位矩阵。
A = [ 0 0 0 1 1 1 0 0 0 1 1 1 0 0 0 1 1 1 1 1 1 0 0 0 1 1 1 0 0 0 1 1 1 0 0 0 ] X = [ 0 0 0 1 1 1 ] D = [ 3 0 0 0 0 0 0 3 0 0 0 0 0 0 3 0 0 0 0 0 0 3 0 0 0 0 0 0 3 0 0 0 0 0 0 3 ] A=\begin{bmatrix} 0 & 0 & 0 & 1 & 1 & 1 \\ 0 & 0 & 0 & 1 & 1 & 1 \\ 0 & 0 & 0 & 1 & 1 & 1 \\ 1 & 1 & 1 & 0 & 0 & 0 \\ 1 & 1 & 1 & 0 & 0 & 0 \\ 1 & 1 & 1 & 0 & 0 & 0 \\ \end{bmatrix}\ X=\begin{bmatrix} 0 \\ 0 \\ 0 \\ 1 \\ 1 \\ 1 \\ \end{bmatrix}\ D=\begin{bmatrix} 3 & 0 & 0 & 0 & 0 & 0 \\ 0 & 3 & 0 & 0 & 0 & 0 \\ 0 & 0 & 3 & 0 & 0 & 0 \\ 0 & 0 & 0 & 3 & 0 & 0 \\ 0 & 0 & 0 & 0 & 3 & 0 \\ 0 & 0 & 0 & 0 & 0 & 3 \\ \end{bmatrix} A= 000111000111000111111000111000111000 X= 000111 D= 300000030000003000000300000030000003
基于上述定义和观察,我们将**聚合相似度分数(aggregation similarity score)**定义如下:

为了使[0,1]中的度量范围与现有的度量范围一样,我们将方程7重新调整为以下修改后的聚合相似度:

为了在不考虑节点特征的情况下衡量标签和图结构之间的一致性,并与方程3中现有的同质性度量进行公平的比较,我们将**图聚合同质性(graph aggregation homophily)**及其修改后的版本定义为:

③ Empirical Evaluation and Comparison on Synthetic Graphs
为了全面比较 H a g g M ( G ) H^M_{agg}(G) HaggM(G)与现有指标阐明图结构对GNN性能影响的能力,我们对不同级别的 H e d g e M ( G ) H^M_{edge}(G) HedgeM(G)生成的合成图进行实验,以评估 H a g g M ( G ) H^M_{agg}(G) HaggM(G)的输出与现有度量进行比较。
Data Generation & Experimental Setup
我们首先为28个边同质性水平中的每一个生成10个图,从0.005到0.95,总共有280个图。在每个生成的图中,我们有5个类,每个类有400个节点。对于每个类中的节点,我们随机生成了800条类内边和[800/ H e d g e ( G ) − 800 H_{edge}(G)-800 Hedge(G)−800]条类间边。每个类中的节点特征从相应类的6个基准数据集(Cora、Citeseer、Pubmed、Chameleon、Squirrel、Film)类中的节点特征中采样。节点被随机划分为训练/验证/测试集,其比例为60%/20%/20%。我们还在合成图上训练了1跳SGC(sgc-1)和GCN。对于 H e d g e ( G ) H_{edge}(G) Hedge(G)的每个值,我们取使用该值生成的10个图的运行的平均测试精度和标准差。对于每个生成的图,我们还计算了 H n o d e ( G ) H_{node}(G) Hnode(G)、 H c l a s s ( G ) H_{class}(G) Hclass(G)和 H a g g M ( G ) H^M_{agg}(G) HaggM(G)。模型对不同同质性值的性能如图2所示。

Comparison of Homophily Metrics
如果同质性度量提供信息,则SGC-1和GCN的性能将单调增加。然而,图2(a)(b)©显示了 H e d g e ( G ) H_{edge}(G) Hedge(G)、 H n o d e ( G ) H_{node}(G) Hnode(G)和 H c l a s s ( G ) H_{class}(G) Hclass(G)下的性能曲线为U型,而图2(d)显示了一个近似单调的曲线,在1附近有少量的数值扰动。这表明 H a g g M ( G ) H^M_{agg}(G) HaggM(G)比现有指标更好地指示了图结构对SGC-1和GCN性能的影响方式。
4、自适应信道混合(Adaptive Channel Mixing,ACM)
① 滤波器组
对于定义在图 G G G上的图信号 x x x,一个2通道线性分析滤波器组包括:一对滤波器 H L P H_{LP} HLP和 H H P H_{HP} HHP,它们分别保留了 x x x的低频和高频内容。
一般认为,拉普拉斯矩阵可以视为HP滤波器,亲和矩阵可以视为LP滤波器。
此外,我们扩展了滤波器组的概念,并将MLPs视为使用具有 H L P = I H_{LP}=I HLP=I和 H H P = 0 H_{HP}=0 HHP=0的身份(全通滤波器),它也满足 H L P + H H P = I + 0 = I H_{LP}+H_{HP} = I+0 = I HLP+HHP=I+0=I。

图3中的示例还显示了不同节点可能需要从不同信道中提取的本地信息。例如,节点{1, 3}需要来自
HP信道的信息,而节点2只需要来自LP信道的信息。

图4显示,节点在不同数据集上节点局部同配性 H n o d e v H_{node}^v Hnodev的分布不同。
② ACM框架
为了自适应地利用GNN中的LP、HP和身份识别信道来处理不同的局部异配性情况,我们现在将描述我们提出的自适应信道混合(ACM)框架。
我们将以GCN为例,以矩阵形式引入ACM框架,但该框架可以以类似许多不同的GNN方式进行组合。
ACM框架包括以下步骤:

我们将把在步骤中使用选项1的实例化称为ACM,把使用选项2的实例化称为ACMII。
5、相关工作
《MixHop》:承认在弱同质图上学习的困难,并提出MixHop从多跳邻域中提取特征以获得更多信息。
《Measuring and improving the use of graph information in graph neural networks》:提出了基于特征平滑度和标签平滑度的测量方法,这可能有助于指导在处理异配图时的GNN。
《Geom-GCN》:预计计算无监督节点嵌入,并使用嵌入空间中由几何关系定义的图结构来定义双层聚合过程。
《H2GCN》:结合了3种关键设计来解决异配性:自我与邻居之间的嵌入分离;高阶邻域;中间表示的组合。
《CPGNN》:通过兼容性矩阵来标记相关性,这有利于异配图,并利用兼容性矩阵将先验信念估计传播到GNN中。
《FAGCN》:学习边级聚合权值作为GAT,但允许权值为负值,这使得网络能够捕获图信号中的高频分量。
《GPRGNN》:使用可学习的权值,可以是正的和负的特征传播。这使得GPRGNN能够适应异配图,并处理图信号的高频和低频部分。
《BernNet》:设计了一种利用伯恩斯坦多项式学习任意图谱滤波器来解决异配性。
《Is homophily a necessity for graph neural networks?》:指出GNN的同质性是不必要的,并描述了GNN在异配图上表现良好的条件。
6、实验评估
消融实验结果:

可视化:

与SOTA相比:

7、引用
Derivative works:
| Title | First author | Year | Citations | Conference | PS |
|---|---|---|---|---|---|
| Graph Neural Networks for Graphs with Heterophily:A Survey | Xin Zheng | 2022 | 124 | arXiv | 2022年异配图神经网络综述 |
| Clarify Confused Nodes via Separated Learning | Jiajun Zhou | 2023 | 1 | —— | |
| Demystifying Structural Disparity in Graph Neural Networks: Can One Size Fit All? | Haitao Mao | 2023 | 17 | NeurIPS | |
| Understanding Heterophily for Graph Neural Networks | Junfu Wang | 2024 | 4 | arXiv | |
| Breaking the Entanglement of Homphily and Heterophily in Semi-supervised Node Classification | Henan Sun | 2023 | 1 | arXiv | |
| Node Classification Beyond Homophily: Towards a General Solution | Zhe Xu | 2023 | 5 | KDD | |
| Spatial Heterophily Aware Graph Neural Networks | Congxi Xiao | 2023 | 2 | KDD | |
| Clarify Confused Nodes Through Separated Learning | Sheng Gong | 2023 | 1 | arXiv | |
| AdaFGL: A New Paradigm for Federated Node Classification with Topology Heterogeneity | Xunkai Li | 2024 | 0 | arXiv | |
| Towards Learning from Graphs with Heterophily: Progress and Future | Chenghua Gong | 2024 | 2 | arXiv | 2024年异配图神经网络综述 |
Prior works:
| Title | First author | Year | Citations | Conference | PS |
|---|---|---|---|---|---|
| Simple and Deep Graph Convolutional Networks | Ming Chen | 2020 | 1111 | ICML | |
| Geom-GCN: Geometric Graph Convolutional Networks | Hongbin Pei | 2020 | 821 | ICLR | 《Geom-GCN》 |
| Simplifying Graph Convolutional Networks | Felix Wu | 2019 | 2550 | ICML | |
| Multi-scale Attributed Node Embedding | Benedek Rozemberczki | 2019 | 640 | J. Complex Networks(期刊) | |
| MixHop: Higher-Order Graph Convolutional Architectures via Sparsified Neighborhood Mixing | Sami Abu-El-Haija | 2019 | 707 | ICML | |
| Predict then Propagate: Graph Neural Networks meet Personalized PageRank | Johannes Klicpera | 2018 | 1371 | ICLR | |
| Graph Attention Networks | Petar Velickovic | 2017 | 15785 | ICLR | |
| Inductive Representation Learning on Large Graphs | William L. Hamilton | 2017 | 12072 | NeurIPS | |
| Convolutional Neural Networks on Graphs with Fast Localized Spectral Filtering | M. Defferrard | 2016 | 6801 | ICLR | |
| Semi-Supervised Classification with Graph Convolutional Networks | Thomas Kipf | 2016 | 24115 | ICLR |
该作者其他论文:
| Title | Conference | Year | Citation |
|---|---|---|---|
| Complete the Missing Half: Augmenting Aggregation Filtering with Diversification for Graph Convolutional Networks | arXiv | 2020 | 24 |
| Is Heterophily A Real Nightmare For Graph Neural Networks To Do Node Classification? | arXiv | 2021 | 85 |
| Revisiting Heterophily For Graph Neural Networks(本文) | NeurIPS | 2022 | 108 |
| When Do We Need Graph Neural Networks for Node Classification | International Workshop on Complex Networks & Their Applications | 2022 | 0 |
| When Do We Need GNN for Node Classification? | arXiv | 2022 | 14 |
| On Addressing the Limitations of Graph Neural Networks | arXiv | 2023 | 3 |
| When Do Graph Neural Networks Help with Node Classification: Investigating the Homophily Principle on Node Distinguishability | NeurIPS | 2023 | 21 |
8、参考资料
- kimi:https://kimi.moonshot.cn/
- Derivative works:https://www.connectedpapers.com/main/4becb19c87f0526d9a3a2c15497e0b1c40b576e2/Revisiting-Heterophily-For-Graph-Neural-Networks/derivative










![BUUCTF逆向wp [HDCTF2019]Maze](https://i-blog.csdnimg.cn/direct/0f892030a49c446ca68837854ac2983a.jpeg)






