安装说明
kube-prometheus
- https://prometheus-operator.dev/docs/
- https://github.com/prometheus-operator/kube-prometheus
该存储库收集 Kubernetes 清单、Grafana仪表板和Prometheus 规则以及文档和脚本,以使用 Prometheus Operator 通过Prometheus提供易于操作的端到端 Kubernetes 集群监控。
该项目的内容是用jsonnet编写的。该项目既可以被描述为一个包,也可以被描述为一个库。
该软件包中包含的组件:
- The Prometheus Operator
- Highly available Prometheus
- Highly available Alertmanager
- Prometheus node-exporter
- Prometheus blackbox-exporter
- Prometheus Adapter for Kubernetes Metrics APIs
- kube-state-metrics
- Grafana
该堆栈用于集群监控,因此它被预先配置为从所有 Kubernetes 组件收集指标。除此之外,它还提供一组默认的仪表板和警报规则。许多有用的仪表板和警报都来自kubernetes-mixin 项目,与该项目类似,它提供可组合的 jsonnet 作为库,供用户根据自己的需求进行自定义。
先决条件
Prometheus Operator 的版本>=0.39.0需要 版本 的 Kubernetes 集群>=1.16.0。如果您刚刚开始使用 Prometheus Operator,强烈建议使用最新版本。
如果您运行的是旧版本的 Kubernetes 和 Prometheus Operator,我们建议先升级 Kubernetes,然后再升级 Prometheus Operator。
兼容性
以下 Kubernetes 版本受支持,并且在我们在各自分支中针对这些版本进行测试时可以正常工作。但请注意,其他版本也可能有效!
| kube-prometheus stack | Kubernetes 1.22 | Kubernetes 1.23 | Kubernetes 1.24 | Kubernetes 1.25 | Kubernetes 1.26 | Kubernetes 1.27 | Kubernetes 1.28 |
|---|---|---|---|---|---|---|---|
| release-0.10 | ✔ | ✔ | ✗ | ✗ | x | x | x |
| release-0.11 | ✗ | ✔ | ✔ | ✗ | x | x | x |
| release-0.12 | ✗ | ✗ | ✔ | ✔ | x | x | x |
| release-0.13 | ✗ | ✗ | ✗ | x | ✔ | ✔ | ✔ |
| main | ✗ | ✗ | ✗ | x | x | ✔ | ✔ |
部署 Operator
注意:对于 Kubernetes v1.21.z 之前的版本,请参考Kubernetes 兼容性矩阵以选择兼容的分支。
创建需要的命名空间和 CRDs
首先 clone 项目代码,我们这里直接使用默认的 main 分支即可:
git clone https://github.com/prometheus-operator/kube-prometheus.git
cd kube-prometheus
使用manifests目录中的配置创建监控堆栈:
# Create the namespace and CRDs, and then wait for them to be available before creating the remaining resources
# Note that due to some CRD size we are using kubectl server-side apply feature which is generally available since kubernetes 1.22.
# If you are using previous kubernetes versions this feature may not be available and you would need to use kubectl create instead.
kubectl apply --server-side -f manifests/setup
安装 Operator 控制器
当我们声明完 CRD 过后,就可以来自定义资源清单了,但是要让我们声明的自定义资源对象生效就需要安装对应的 Operator 控制器,在 manifests 目录下面就包含了 Operator 的资源清单以及各种监控对象声明,比如 Prometheus、Alertmanager 等,直接应用即可:
# 进入Operator 资源清单目录
cd kube-prometheus/manifests# 新建对应的服务目录
mkdir -p operator node-exporter alertmanager grafana kube-state-metrics blackbox_exporter prometheus prometheusRules serviceMonitor adapter service# 把对应的服务配置文件移动到相应的服务目录
mv prometheus-* prometheus/
mv prometheusOperator* operator/
mv grafana-* grafana/
mv prometheusAdapter-* adapter/
mv *-serviceMonitor* serviceMonitor/
mv kubeStateMetrics-* kube-state-metrics/
mv alertmanager-* alertmanager/
mv nodeExporter-* node-exporter/
mv blackboxExporter-* blackbox_exporter/
find . -name "*Rule.yaml" -exec mv {} ./prometheusRules/ \;# 新创建了两个目录,存放钉钉配置和其它配置
mkdir other dingtalk-hook
kubectl wait \--for condition=Established \--all CustomResourceDefinition \--namespace=monitoringkubectl apply -f operator/
这会创建一个名为 monitoring 的命名空间,以及相关的 CRD 资源对象声明,以避免部署监控组件时的竞争条件。
查看是否正常部署
$ kubectl -n monitoring get podNAME READY STATUS RESTARTS AGE
prometheus-operator-586f75fb74-hzj24 2/2 Running 0 82s
查看是否正常部署自定义资源定义(CRD)
$ kubectl get crd -n monitoringNAME CREATED AT
alertmanagers.monitoring.coreos.com 2019-04-16T06:22:20Z
prometheuses.monitoring.coreos.com 2019-04-16T06:22:20Z
prometheusrules.monitoring.coreos.com 2019-04-16T06:22:20Z
servicemonitors.monitoring.coreos.com 2019-04-16T06:22:21Z
部署服务
需要注意有一些资源的镜像来自于 k8s.gcr.io,如果不能正常拉取,则可以将镜像替换成可拉取的。
- prometheusAdapter-deployment.yaml
- kubeStateMetrics-deployment.yaml
替换Docker镜像加速地址
sed -i 's/registry.k8s.io/k8s.m.daocloud.io/g' adapter/prometheusAdapter-deployment.yaml
sed -i 's/registry.k8s.io/k8s.m.daocloud.io/g' kube-state-metrics/kubeStateMetrics-deployment.yaml
sed -i 's/quay.io/quay.m.daocloud.io/g' kube-state-metrics/kubeStateMetrics-deployment.yaml
部署整套CRD
kubectl apply -f prometheus/
kubectl apply -f grafana/
kubectl apply -f adapter/
kubectl apply -f alertmanager/
kubectl apply -f node-exporter/
kubectl apply -f kube-state-metrics/
kubectl apply -f serviceMonitor/
kubectl apply -f blackbox_exporter/
kubectl apply -f prometheusRules/
这会自动安装 prometheus-operator、node-exporter、kube-state-metrics、grafana、prometheus-adapter 以及 prometheus 和 alertmanager 等大量组件,如果没成功可以多次执行上面的安装命令。
检查是否正常部署
$ kubectl get pods -n monitoring
NAME READY STATUS RESTARTS AGE
alertmanager-main-0 2/2 Running 0 73m
alertmanager-main-1 2/2 Running 0 73m
alertmanager-main-2 2/2 Running 0 73m
blackbox-exporter-d46f55658-jjrjf 3/3 Running 0 72m
grafana-55dfb44658-gjhvw 1/1 Running 0 73m
kube-state-metrics-54b8f57bc9-wkcr2 3/3 Running 0 36m
node-exporter-267nz 2/2 Running 0 73m
node-exporter-6bfhs 2/2 Running 0 73m
node-exporter-9t4lj 2/2 Running 0 73m
node-exporter-nd5gh 2/2 Running 0 73m
prometheus-adapter-6f5fc7b689-24dph 1/1 Running 0 36m
prometheus-adapter-6f5fc7b689-ngcgn 1/1 Running 0 36m
prometheus-k8s-0 2/2 Running 0 73m
prometheus-k8s-1 2/2 Running 0 73m
prometheus-operator-586f75fb74-hzj24 2/2 Running 0 85m
$ kubectl get svc -o wide -n monitoring
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE SELECTOR
alertmanager-main ClusterIP 10.247.60.19 <none> 9093/TCP,8080/TCP 3m56s app.kubernetes.io/component=alert-router,app.kubernetes.io/instance=main,app.kubernetes.io/name=alertmanager,app.kubernetes.io/part-of=kube-prometheus
alertmanager-operated ClusterIP None <none> 9093/TCP,9094/TCP,9094/UDP 3m56s app.kubernetes.io/name=alertmanager
blackbox-exporter ClusterIP 10.247.22.106 <none> 9115/TCP,19115/TCP 3m54s app.kubernetes.io/component=exporter,app.kubernetes.io/name=blackbox-exporter,app.kubernetes.io/part-of=kube-prometheus
grafana ClusterIP 10.247.27.27 <none> 3000/TCP 3m57s app.kubernetes.io/component=grafana,app.kubernetes.io/name=grafana,app.kubernetes.io/part-of=kube-prometheus
kube-state-metrics ClusterIP None <none> 8443/TCP,9443/TCP 3m55s app.kubernetes.io/component=exporter,app.kubernetes.io/name=kube-state-metrics,app.kubernetes.io/part-of=kube-prometheus
node-exporter ClusterIP None <none> 9100/TCP 3m56s app.kubernetes.io/component=exporter,app.kubernetes.io/name=node-exporter,app.kubernetes.io/part-of=kube-prometheus
prometheus-adapter ClusterIP 10.247.207.100 <none> 443/TCP 3m57s app.kubernetes.io/component=metrics-adapter,app.kubernetes.io/name=prometheus-adapter,app.kubernetes.io/part-of=kube-prometheus
prometheus-k8s ClusterIP 10.247.87.202 <none> 9090/TCP,8080/TCP 4m1s app.kubernetes.io/component=prometheus,app.kubernetes.io/instance=k8s,app.kubernetes.io/name=prometheus,app.kubernetes.io/part-of=kube-prometheus
prometheus-operated ClusterIP None <none> 9090/TCP 4m1s app.kubernetes.io/name=prometheus
prometheus-operator ClusterIP None <none> 8443/TCP 15m app.kubernetes.io/component=controller,app.kubernetes.io/name=prometheus-operator,app.kubernetes.io/part-of=kube-prometheus
访问 prometheus UI
如果我们想要在外网访问这两个服务的话,可以通过创建对应的 Ingress 对象或者使用 NodePort 类型的 Service,我们这里为了简单,直接使用 NodePort 类型的服务即可,编辑 grafana、alertmanager-main 和 prometheus-k8s 这 3 个 Service,将服务类型更改为 NodePort:
# 将 type: ClusterIP 更改为 type: NodePort
$ kubectl edit svc grafana -n monitoring
$ kubectl edit svc alertmanager-main -n monitoring
$ kubectl edit svc prometheus-k8s -n monitoring
$ kubectl get svc -n monitoring
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
alertmanager-main NodePort 10.102.174.254 <none> 9093:32660/TCP,8080:31615/TCP 49m
grafana NodePort 10.105.33.193 <none> 3000:31837/TCP 49m
prometheus-k8s NodePort 10.109.250.233 <none> 9090:31664/TCP,8080:31756/TCP 49m
......
更改完成后,我们就可以通过上面的 NodePort 去访问对应的服务了,比如查看 prometheus 的服务发现页面:
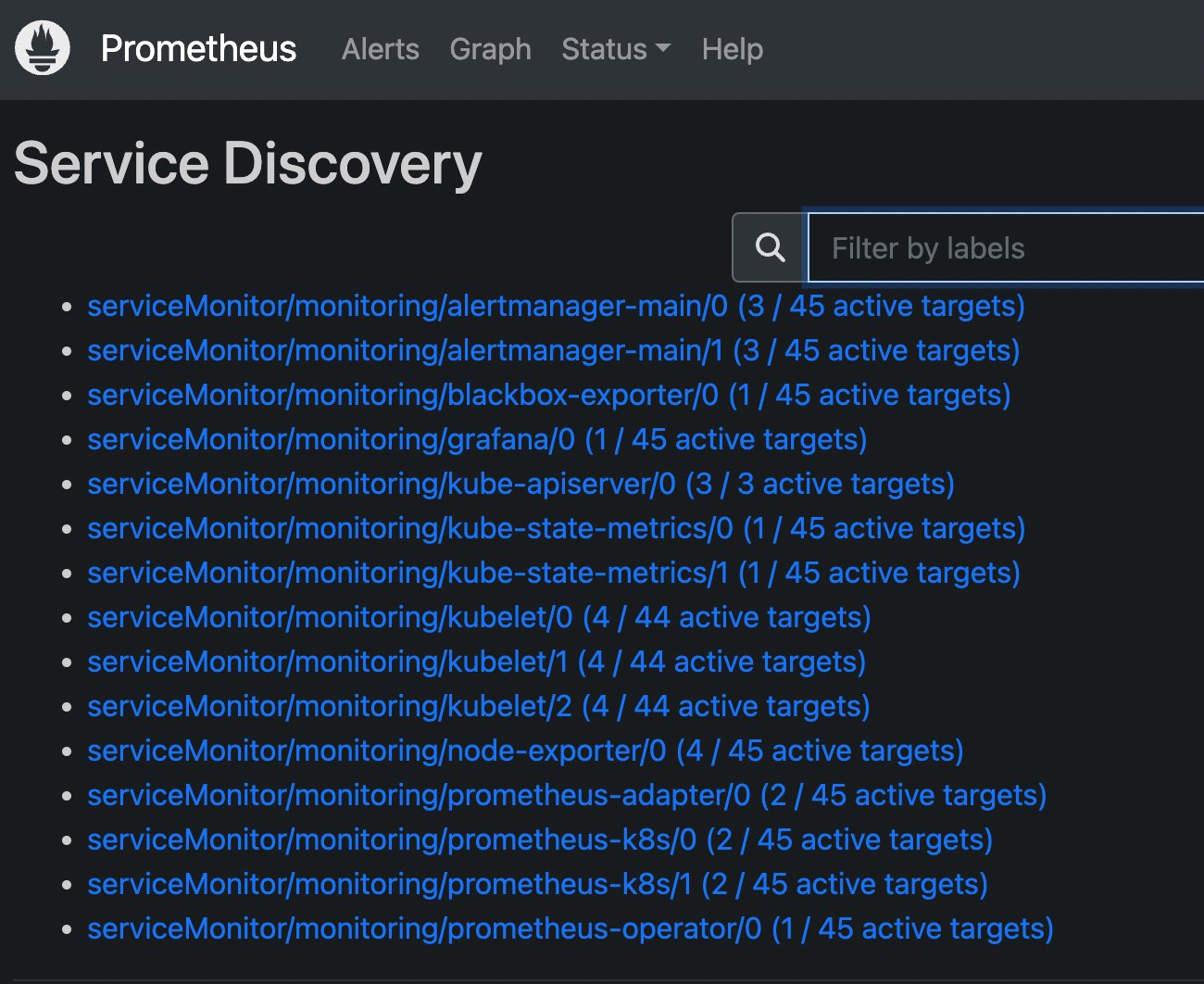
可以看到已经监控上了很多指标数据了,上面我们可以看到 Prometheus 是两个副本,我们这里通过 Service 去访问,按正常来说请求是会去轮询访问后端的两个 Prometheus 实例的,但实际上我们这里访问的时候始终是路由到后端的一个实例上去,因为这里的 Service 在创建的时候添加了 sessionAffinity: ClientIP 这样的属性,会根据 ClientIP 来做 session 亲和性,所以我们不用担心请求会到不同的副本上去:
https://kubernetes.renkeju.com/chapter_6/6.2.3.Service_session_stickiness.html
apiVersion: v1
kind: Service
metadata:labels:app.kubernetes.io/component: prometheusapp.kubernetes.io/instance: k8sapp.kubernetes.io/name: prometheusapp.kubernetes.io/part-of: kube-prometheusapp.kubernetes.io/version: 2.52.0name: prometheus-k8snamespace: monitoring
spec:ports:- name: webport: 9090targetPort: web- name: reloader-webport: 8080targetPort: reloader-webtype: NodePortselector:app.kubernetes.io/component: prometheusapp.kubernetes.io/instance: k8sapp.kubernetes.io/name: prometheusapp.kubernetes.io/part-of: kube-prometheussessionAffinity: ClientIP
为什么会担心请求会到不同的副本上去呢?正常多副本应该是看成高可用的常用方案,理论上来说不同副本本地的数据是一致的,但是需要注意的是 Prometheus 的主动 Pull 拉取监控指标的方式,由于抓取时间不能完全一致,即使一致也不一定就能保证网络没什么问题,所以最终不同副本下存储的数据很大可能是不一样的,所以这里我们配置了 session 亲和性,可以保证我们在访问数据的时候始终是一致的。
卸载Stack
如果要清理 Prometheus-Operator,可以直接删除对应的资源清单即可:
kubectl delete --ignore-not-found=true -f manifests/ -f manifests/setup
Prometheus 配置
数据持久化
上面我们在修改完权限的时候,重启了 Prometheus 的 Pod,如果我们仔细观察的话会发现我们之前采集的数据已经没有了,这是因为我们通过 prometheus 这个 CRD 创建的 Prometheus 并没有做数据的持久化。
我们可以直接查看生成的 Prometheus Pod 的挂载情况就清楚了:
$ kubectl get pod prometheus-k8s-0 -n monitoring -o yaml
......volumeMounts:- mountPath: /etc/prometheus/config_outname: config-outreadOnly: true- mountPath: /etc/prometheus/certsname: tls-assetsreadOnly: true- mountPath: /prometheusname: prometheus-k8s-db
......volumes:
......- emptyDir: {}name: prometheus-k8s-db
......
- 如果未指定存储选项,Prometheus 的数据目录 /prometheus 默认情况下将使用EmptyDir 。
- 如果指定了多个存储选项,则优先级如下: 1. emptyDir 2. ephemeral 3. volumeClaimTemplate
创建一个 StorageClass 对象:
emptyDir 挂载的数据的生命周期和 Pod 生命周期一致的,如果 Pod 挂掉了,数据也就丢失了,对应线上的监控数据肯定需要做数据的持久化的,由于我们的 Prometheus 最终是通过 Statefulset 控制器进行部署的,所以我们这里需要通过 storageclass 来做数据持久化。
$ cat prometheus-storageclass.yaml
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:name: prometheus-data-db
provisioner: fuseim.pri/ifs
$ kubectl create -f prometheus-storageclass.yaml
storageclass.storage.k8s.io "prometheus-data-db" created
配置 CRD 资源对象中 storage 属性
然后在 prometheus 的 CRD 资源对象中通过 storage 属性配置 volumeClaimTemplate 对象即可,更多配置项见API reference。
# vim prometheus/prometheus-prometheus.yaml
apiVersion: monitoring.coreos.com/v1
kind: Prometheus
......replicas: 2storage:volumeClaimTemplate:metadata:name: prometheus-data-dbspec:storageClassName: prometheus-data-dbresources:requests:storage: 50Gi
然后更新 prometheus 这个 CRD 资源,更新完成后会自动生成两个 PVC 和 PV 资源对象:
$ kubectl apply -f prometheus-prometheus.yaml
prometheus.monitoring.coreos.com/k8s configured$ kubectl get pvc -n monitoring
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
prometheus-k8s-db-prometheus-k8s-0 Bound pvc-4c67d0a9-e97c-4820-9c66-340a7da3c53f 20Gi RWO local-path 4s
prometheus-k8s-db-prometheus-k8s-1 Bound pvc-6f26e85c-01c6-483c-9d42-55166f77e5d0 20Gi RWO local-path 4s$ kubectl get pv |grep monitoring
pvc-4c67d0a9-e97c-4820-9c66-340a7da3c53f 20Gi RWO Delete Bound monitoring/prometheus-k8s-db-prometheus-k8s-0 local-path 17s
pvc-6f26e85c-01c6-483c-9d42-55166f77e5d0 20Gi RWO Delete Bound monitoring/prometheus-k8s-db-prometheus-k8s-1 local-path 17s
现在即使我们的 Pod 挂掉了,数据也不会丢失了。
自动发现配置
如果在我们的 Kubernetes 集群中有了很多的 Service/Pod,那么我们都需要一个一个的去建立一个对应的 ServiceMonitor 或 PodMonitor 对象来进行监控吗?这样岂不是又变得麻烦起来了?
为解决上面的问题,Prometheus Operator 为我们提供了一个额外的抓取配置来解决这个问题,我们可以通过添加额外的配置来进行服务发现进行自动监控。
Service服务监控指标采集
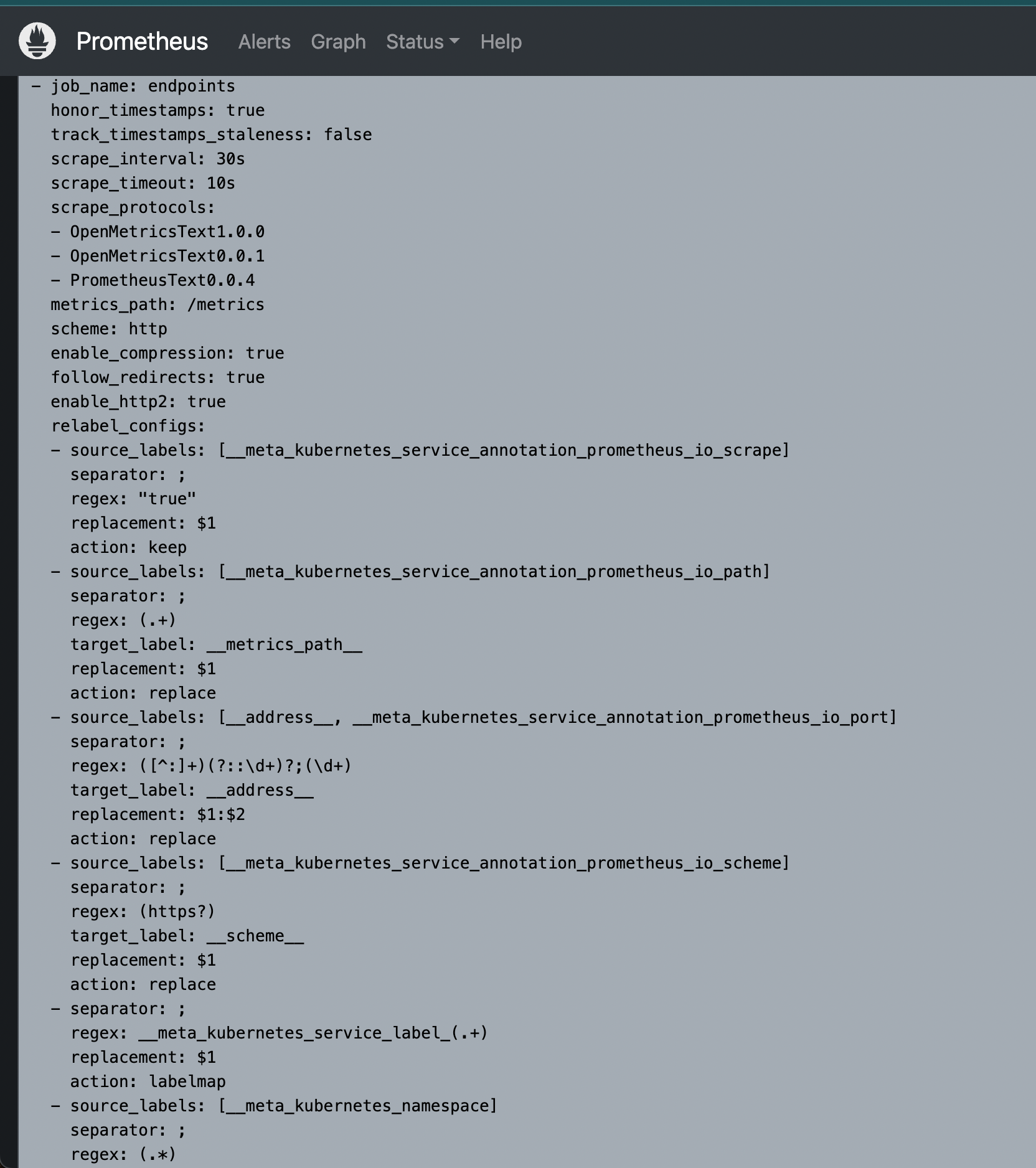
我们可以在 Prometheus Operator 当中去自动发现并监控具有 prometheus.io/scrape=true 这个 annotations 的 Service加入到endpoints这个target中,否则就会被删除。之前我们定义的 Prometheus 的配置如下:
$ vim ./prometheus/prometheus-additional.yaml
- job_name: 'kubernetes-nodes'kubernetes_sd_configs:- role: nodescheme: httpstls_config:insecure_skip_verify: truebearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/tokenrelabel_configs:- source_labels: [__address__]target_label: __address__regex: "(.*):10250"replacement: "${1}:9100"action: replace- source_labels: [__meta_kubernetes_node_label_cce_cloud_com_cce_nodepool]target_label: nodepool- source_labels: [__meta_kubernetes_node_label_env]target_label: env- source_labels: [__meta_kubernetes_node_label_os_name]target_label: OSmetric_relabel_configs:- source_labels: [__meta_kubernetes_node_label_os_name]target_label: platformregex: (?i)Huawei.*replacement: Huaweiaction: replace
- job_name: 'endpoints'kubernetes_sd_configs:- role: endpointsrelabel_configs: # 指标采集之前或采集过程中去重新配置- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_scrape]action: keep # 保留具有 prometheus.io/scrape=true 这个注解的Serviceregex: true- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_path]action: replacetarget_label: __metrics_path__regex: (.+)- source_labels:[__address__, __meta_kubernetes_service_annotation_prometheus_io_port]action: replacetarget_label: __address__regex: ([^:]+)(?::\d+)?;(\d+) # RE2 正则规则,+是一次多多次,?是0次或1次,其中?:表示非匹配组(意思就是不获取匹配结果)replacement: $1:$2- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_scheme]action: replacetarget_label: __scheme__regex: (https?)- action: labelmapregex: __meta_kubernetes_service_label_(.+)replacement: $1- source_labels: [__meta_kubernetes_namespace]action: replacetarget_label: kubernetes_namespace- source_labels: [__meta_kubernetes_service_name]action: replacetarget_label: kubernetes_service- source_labels: [__meta_kubernetes_pod_name]action: replacetarget_label: kubernetes_pod- source_labels: [__meta_kubernetes_node_name]action: replacetarget_label: kubernetes_node将上面文件直接保存为 prometheus-additional.yaml,然后通过这个文件创建一个对应的 Secret 对象:
kubectl create secret generic additional-configs --from-file=./prometheus/prometheus-additional.yaml -n monitoring
修改prometheus 的资源对象
然后我们需要在声明 prometheus 的资源对象文件中通过 additionalScrapeConfigs 属性添加上这个额外的配置:
# vim prometheus/prometheus-prometheus.yaml
apiVersion: monitoring.coreos.com/v1
kind: Prometheus
metadata:labels:app.kubernetes.io/component: prometheusapp.kubernetes.io/instance: k8sapp.kubernetes.io/name: prometheusapp.kubernetes.io/part-of: kube-prometheusapp.kubernetes.io/version: 2.35.0name: k8snamespace: monitoring
spec:alerting:alertmanagers:- apiVersion: v2name: alertmanager-mainnamespace: monitoringport: webenableFeatures: []externalLabels: {}image: quay.io/prometheus/prometheus:v2.35.0nodeSelector:kubernetes.io/os: linuxpodMetadata:labels:app.kubernetes.io/component: prometheusapp.kubernetes.io/instance: k8sapp.kubernetes.io/name: prometheusapp.kubernetes.io/part-of: kube-prometheusapp.kubernetes.io/version: 2.35.0podMonitorNamespaceSelector: {}podMonitorSelector: {}probeNamespaceSelector: {}probeSelector: {}replicas: 2resources:requests:memory: 400MiruleNamespaceSelector: {}ruleSelector: {}securityContext:fsGroup: 2000runAsNonRoot: truerunAsUser: 1000 additionalScrapeConfigs:name: additional-configskey: prometheus-additional.yamlserviceAccountName: prometheus-k8sserviceMonitorNamespaceSelector: {}serviceMonitorSelector: {}version: 2.52.0
关于 additionalScrapeConfigs 属性的具体介绍,我们可以使用 kubectl explain prometheus.spec.additionalScrapeConfigs命令来了解详细信息:
添加完成后,直接更新 prometheus 这个 CRD 资源对象即可:
$ kubectl apply -f prometheus/prometheus-prometheus.yaml
prometheus.monitoring.coreos.com "k8s" configured
隔一小会儿,可以前往 Prometheus 的 Dashboard 中查看配置已经生效了:
解决 RBAC 权限问题
但是当我们切换到 targets 页面下面却并没有发现对应的监控任务
查看 Prometheus 的 Pod 日志:
$ kubectl logs -f prometheus-k8s-0 prometheus -n monitoring
......
ts=2024-06-06T06:26:31.771Z caller=klog.go:108 level=warn component=k8s_client_runtime func=Warningf msg="pkg/mod/k8s.io/client-go@v0.29.3/tools/cache/reflector.go:229: failed to list *v1.Endpoints: endpoints is forbidden: User \"system:serviceaccount:monitoring:prometheus-k8s\" cannot list resource \"endpoints\" in API group \"\" at the cluster scope"
ts=2024-06-06T06:26:31.771Z caller=klog.go:116 level=error component=k8s_client_runtime func=ErrorDepth msg="pkg/mod/k8s.io/client-go@v0.29.3/tools/cache/reflector.go:229: Failed to watch *v1.Endpoints: failed to list *v1.Endpoints: endpoints is forbidden: User \"system:serviceaccount:monitoring:prometheus-k8s\" cannot list resource \"endpoints\" in API group \"\" at the cluster scope"
ts=2024-06-06T06:26:35.337Z caller=klog.go:108 level=warn component=k8s_client_runtime func=Warningf msg="pkg/mod/k8s.io/client-go@v0.29.3/tools/cache/reflector.go:229: failed to list *v1.Pod: pods is forbidden: User \"system:serviceaccount:monitoring:prometheus-k8s\" cannot list resource \"pods\" in API group \"\" at the cluster scope"
ts=2024-06-06T06:26:35.337Z caller=klog.go:116 level=error component=k8s_client_runtime func=ErrorDepth msg="pkg/mod/k8s.io/client-go@v0.29.3/tools/cache/reflector.go:229: Failed to watch *v1.Pod: failed to list *v1.Pod: pods is forbidden: User \"system:serviceaccount:monitoring:prometheus-k8s\" cannot list resource \"pods\" in API group \"\" at the cluster scope"
可以看到有很多错误日志出现,都是 xxx is forbidden,这说明是 RBAC 权限的问题,通过 prometheus 资源对象的配置可以知道 Prometheus 绑定了一个名为 prometheus-k8s 的 ServiceAccount 对象,而这个对象绑定的是一个名为 prometheus-k8s 的 ClusterRole:
要解决这个问题,我们只需要添加对 Service 或者 Pod 的 list 权限即可:
# vim prometheus/prometheus-clusterRole.yaml
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:labels:app.kubernetes.io/component: prometheusapp.kubernetes.io/instance: k8sapp.kubernetes.io/name: prometheusapp.kubernetes.io/part-of: kube-prometheusapp.kubernetes.io/version: 2.52.0name: prometheus-k8s
rules:- apiGroups:- ''resources:- nodes- services- endpoints- pods- nodes/proxyverbs:- get- list- watch- apiGroups:- ''resources:- configmaps- nodes/metricsverbs:- get- nonResourceURLs:- /metricsverbs:- get
kubectl apply -f prometheus/prometheus-clusterRole.yaml
更新上面的 ClusterRole 这个资源对象,然后重建下 Prometheus 的所有 Pod,正常就可以看到 targets 页面下面有 endpoints 这个监控任务了:
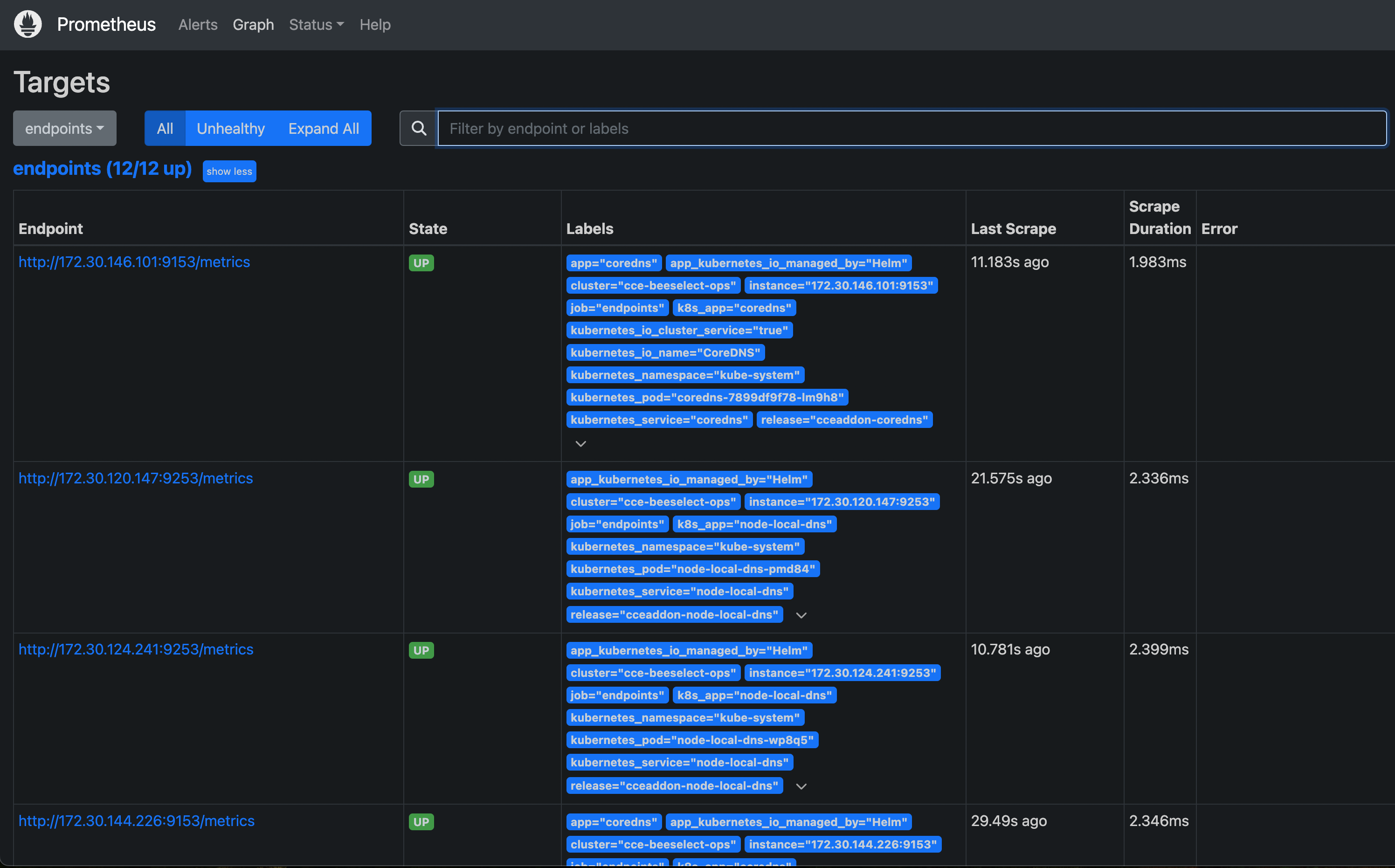
这里发现的几个抓取目标是因为 Service 中都有 prometheus.io/scrape=true 这个 annotation。
查看coredns的metrics类型Before Relabling中的值
$ kubectl get svc/coredns -n kube-system -oyaml
apiVersion: v1
kind: Service
metadata:annotations:meta.helm.sh/release-name: cceaddon-corednsmeta.helm.sh/release-namespace: kube-systemprometheus.io/port: "9153"prometheus.io/scrape: "true"labels:app: corednsapp.kubernetes.io/managed-by: Helmk8s-app: corednskubernetes.io/cluster-service: "true"kubernetes.io/name: CoreDNSrelease: cceaddon-corednsname: corednsnamespace: kube-system...
...
可以发现,存在如下类型的Prometheus的标签:
- __meta_kubernetes_service_annotation_prometheus_io_scrape=“true”
- __meta_kubernetes_service_annotation_prometheus_io_port=“9153”
服务添加 Labels
当然我们也可以用同样的方式去配置 Pod、Ingress 这些资源对象的自动发现。
apiVersion: v1
kind: Service
metadata:name: qsh-svcannotations:prometheus.io/scrape: "true" # Annotation,用于自发现
...
采集容器指标采集
目前cAdvisor集成到了kubelet组件内 ,因此可以通过kubelet的接口实现容器指标的采集,具体的API为:
- https://:10250/metrics/cadvisor # node上的cadvisor采集到的容器指标
- https://:10250/metrics # node上的kubelet的指标数据
获取token信息
# 方式一
## 可以通过curl -k -H "Authorization: Bearer xxxx" https://xxxx/xx查看
$ kubectl get secret -n monitor |grep 'prometheus-token'
prometheus-token-pkzfx kubernetes.io/service-account-token 3 2d21h$ kubectl -n monitor describe secret prometheus-token-pkzfx# 方式二
## 直接获取进入容器内token文件内容
kubectl exec prometheus-k8s-0 -n monitoring -- cat /var/run/secrets/kubernetes.io/serviceaccount/token
请求指标内容
$ curl -k -H "Authorization: Bearer XXXXXXXX" https://172.21.51.143:10250/metrics/cadvisor
因此,针对容器指标,我们期望的采集target是:
- https://172.21.51.143:10250/metrics/cadvisor
- https://172.21.51.67:10250/metrics/cadvisor
- https://172.21.51.68:10250/metrics/cadvisor
即每个node节点都需要去采集数据,联想到prometheus的服务发现中的node类型,因此,配置:
$ kubectl -n monitor edit configmap prometheus-config
...- job_name: 'kubernetes-sd-cadvisor'kubernetes_sd_configs:- role: node
重新reload后查看效果:
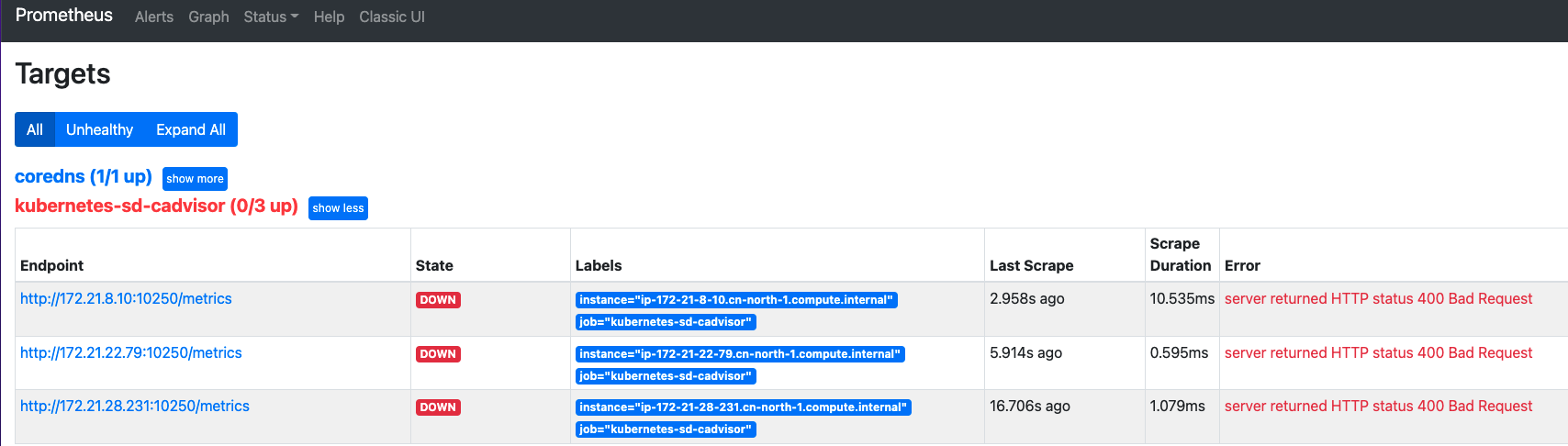
默认添加的target列表为:schema😕/address metrics_path ,和期望值不同,针对__metrics_path__可以使用relabel修改:
relabel_configs:- target_label: __metrics_path__replacement: /metrics/cadvisor
添加容器采集配置
$ vim ./prometheus/prometheus-additional.yaml
- job_name: 'kubernetes-cAdvisor-OPS'scheme: httpstls_config:insecure_skip_verify: true #跳过对服务端的认证bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token #token文件kubernetes_sd_configs: #kubernetes 自动发现配置- role: noderelabel_configs: #重新标记,用于在抓取metrics之前修改target的已有标签- source_labels: [__address__] #指定需要处理的源标签action: keep- target_label: __metrics_path__replacement: /metrics/cadvisor- source_labels: [__meta_kubernetes_node_label_cce_cloud_com_cce_nodepool]target_label: nodepool- source_labels: [__meta_kubernetes_node_label_env]target_label: env- source_labels: [__meta_kubernetes_node_label_os_name]target_label: OS
等待Prometheus 重新应用配置后,查看targets列表,查看cadvisor指标,比如container_cpu_system_seconds_total,container_memory_usage_bytes
综上,利用node类型的服务发现,可以实现对daemonset类型服务的目标自动发现以及监控数据抓取。
黑盒监控
Blackbox Exporter 是 Prometheus 社区提供的官方黑盒监控解决方案,其允许用户通过:HTTP、HTTPS、DNS、TCP 以及 ICMP 的方式对网络进行探测,可以用于下面的这些场景:
- HTTP 测试:定义 Request Header 信息、判断 Http status、Response Header、Body 内容
- TCP 测试:业务组件端口状态监听、应用层协议定义与监听
- ICMP 测试:主机探活机制
- POST 测试:接口联通性
- SSL 证书过期时间
Prometheus Operator 中提供了一个 Probe CRD 对象可以用来进行黑盒监控,我们需要单独运行一个 Blackbox 服务,然后作为一个 prober 提供给 Probe 对象使用。
配置 Blackbox Exporter
在 Kubernetes 集群中运行 Blackbox Exporter 服务,其实在前面的 kube-prometheus 中已经安装过了,这里我们将 pop3 的检测模块去掉,新增 dns 模块,修改后的配置文件如下所示:
$ vim blackbox_exporter/blackboxExporter-configuration.yaml
apiVersion: v1
data:config.yml: |-"modules":"http_2xx":"http":"preferred_ip_protocol": "ip4""prober": "http""http_post_2xx":"http":"method": "POST""preferred_ip_protocol": "ip4""prober": "http""ssh_banner":"prober": "tcp""tcp":"preferred_ip_protocol": "ip4""query_response":- "expect": "^SSH-2.0-"- "send": "SSH-2.0-blackbox-ssh-check""irc_banner":"prober": "tcp""tcp":"preferred_ip_protocol": "ip4""query_response":- "send": "NICK prober"- "send": "USER prober prober prober :prober"- "expect": "PING :([^ ]+)""send": "PONG ${1}"- "expect": "^:[^ ]+ 001""tcp_connect":"prober": "tcp""tcp":"preferred_ip_protocol": "ip4""dns": # DNS 检测模块"prober": "dns""dns":"transport_protocol": "udp" # 默认是 udp,tcp"preferred_ip_protocol": "ip4" # 默认是 ip6query_name: "kubernetes.default.svc.cluster.local" # 利用这个域名来检查dns服务器icmp: # ping 检测服务器的存活prober: icmp
kind: ConfigMap
metadata:labels:app.kubernetes.io/component: exporterapp.kubernetes.io/name: blackbox-exporterapp.kubernetes.io/part-of: kube-prometheusapp.kubernetes.io/version: 0.25.0name: blackbox-exporter-configurationnamespace: monitoring
kubectl apply -f blackbox_exporter/blackboxExporter-configuration.yaml
配置文件准备完成后,现在我们可以去看下 blackbox-exporter 应用的部署清单
配置添加 ping 监控
Prometheus Operator 使用 Probe 这个 CRD 对象来添加网络探测任务,关于这个对象的使用方法可以通过 kubectl explain probe 或者 API 文档 来了解更多。
比如这里我们来新增一个对百度的 ping 任务,创建一个如下所示的 Probe 资源对象:
$ vim blackbox_exporter/blackboxExporter-probePing.yaml
apiVersion: monitoring.coreos.com/v1
kind: Probe
metadata:name: pingnamespace: monitoring
spec:jobName: ping # 任务名称prober: # 指定blackbox的地址url: blackbox-exporter.monitoring:19115module: icmp # 配置文件中的检测模块targets: # 目标(可以是static配置也可以是ingress配置)# ingress <Object>staticConfig: # 如果配置了 ingress,静态配置优先static:- https://www.baidu.comrelabelingConfigs:- sourceLabels: [__address__]targetLabel: __param_target- sourceLabels: [__param_target]targetLabel: instance
直接创建上面的资源清单即可:
$ kubectl apply -f blackboxExporter-probePing.yaml
$ kubectl get probe -n monitoring
NAME AGE
ping 35m
- 创建后正常隔一会儿在 Prometheus 里面就可以看到抓取的任务了。
- 回到 Graph 页面,可以使用 probe_duration_seconds{job=“ping”} 来查看检测的时间,这样就实现了对 ICMP 的黑盒监控。
如果是手动部署的 Prometheus 我们可以直接在 Prometheus 对应的配置文件中添加监控任务即可,比如我们要添加一个 ping 的任务:
- job_name: 'ping'metrics_path: /probe # 这里的指标路径是 /probeparams:modelus: [icmp] # 使用 icmp 模块static_configs:- targets: # 检测的目标- x.x.x.xlables: # 添加额外的标签instance: aliyunrelabel_configs: # relabel 操作- source_labels: [__address__]target_label: __param_target- source_labels: [__param_target]target_label: instance- target_label: __address__replacement: x.x.x.x:9115
配置添加 HTTP 监控
我们再创建一个用于检测网站 HTTP 服务是否正常的任务:
$ vim blackbox_exporter/blackboxExporter-probeDomain.yaml
apiVersion: monitoring.coreos.com/v1
kind: Probe
metadata:name: domain-probenamespace: monitoring
spec:jobName: domain-probe # 任务名称prober: # 指定blackbox的地址url: blackbox-exporter:19115module: http_2xx # 配置文件中的检测模块targets: # 目标(可以是static配置也可以是ingress配置)# ingress <Object>staticConfig: # 如果配置了 ingress,静态配置优先static:- prometheus.iolabels:module: http_2xxname: webrelabelingConfigs:- sourceLabels: [__address__]targetLabel: __param_target
直接创建该资源对象:
$ kubectl apply -f blackbox_exporter/blackboxExporter-probeDomain.yaml
$ kubectl get probe -n monitoring
NAME AGE
domain-probe 5s
ping 77m
创建后同样可以在 Prometheus 中看到对应的任务。
监控告警配置
我们来新增一个监控TLS 证书是否过期的 资源对象:
$ vim prometheusRules/blackboxExporter-prometheusRule.yaml
apiVersion: monitoring.coreos.com/v1
kind: PrometheusRule
metadata:labels:app.kubernetes.io/component: exporterapp.kubernetes.io/name: blackbox-exporterapp.kubernetes.io/part-of: kube-prometheusapp.kubernetes.io/version: 0.25.0prometheus: k8srole: alert-rulesname: blackbox-exporter-rulesnamespace: monitoring
spec:groups:- name: ssl_expiryrules:- alert: Ssl Cert Will Expire in 7 daysexpr: probe_ssl_earliest_cert_expiry - time() < 86400 * 7for: 5mlabels:severity: warningannotations:summary: '域名证书即将过期 (instance {{ $labels.instance }})'description: "域名证书 7 天后过期 \n VALUE = {{ $value }}\n LABELS: {{ $labels }}"
kubectl apply -f prometheusRules/blackboxExporter-prometheusRule.yaml
调试
当配置的任务有问题的时候,我们可以使用 blackbox-exporter 的 probe 接口加上 debug=true 来进行调试:http://192.168.0.106:31266/probe?target=prometheus.io&module=http_2xx&debug=true
AlertManager 报警配置
配置Prometheus集成
Prometheus把产生的警报发给Alertmanager进行处理时,需要在Prometheus使用的配置文件中添加关联Alertmanager的组件的对应配置信息。
配置范例:
alerting:alert_relabel_configs:- separator: ; #将 prometheus_replica 标签删除regex: prometheus_replicareplacement: $1action: labeldropalertmanagers:#- static_configs: #通过 __alerts_path__ 标签公开#- targets: ['127.0.0.1:9093'] # 单实例配置#- targets: ['172.31.10.167:19093','172.31.10.167:29093','172.31.10.167:39093'] # 集群配置- follow_redirects: true #设置为 true 表示在进行 HTTP 请求时遵循重定向。enable_http2: true #设置为 true 表示启用 HTTP/2 协议。scheme: http #设置为 http,定义使用 HTTP 协议与 Alertmanager 通信。path_prefix: / #设置请求路径的前缀。timeout: 10s #设置 HTTP 请求的超时时间。api_version: v2 #设置 Alertmanager API 版本。relabel_configs: #保留特定目标或指标,并删除与之不匹配的目标。- source_labels: [__meta_kubernetes_service_name]separator: ;regex: alertmanager-mainreplacement: $1action: keep- source_labels: [__meta_kubernetes_endpoint_port_name]separator: ;regex: webreplacement: $1action: keepkubernetes_sd_configs: #配置服务发现机制,搜索 monitoring 命名空间中的所有 Endpoints。- role: endpointskubeconfig_file: ""follow_redirects: trueenable_http2: truenamespaces:own_namespace: false #设置为 false 表示不只限于当前命名空间。names:- monitoring
- 上面的配置中的 alert_relabel_configs是指警报重新标记在发送到Alertmanager之前应用于警报。它具有与目标重新标记相同的配置格式和操作,外部标签标记后应用警报重新标记,主要是针对集群配置。
- 这个设置的用途是确保具有不同外部label的HA对Prometheus服务端发送相同的警报信息。
- Alertmanager 可以通过 static_configs 参数静态配置,也可以使用支持的服务发现机制其中一种动态发现。
- 此外,relabel_configs 允许从发现的实体中选择 Alertmanager,并对使用的API路径提供高级修改,该路径通过 alerts_path 标签公开。
完成以上配置后,重启Prometheus服务,用以加载生效,也可以使用前文说过的热加载功能,使其配置生效。
curl -X POST `kubectl -n monitoring get endpoints prometheus-k8s -o jsonpath={.subsets[0].addresses[0].ip}`:9090/-/reload
然后通过浏览器访问 http://172.30.145.142:9093 告警界面
数据持久化
我们可以直接查看生成的 alertmanager Pod 的挂载情况就清楚了:
# kubectl get pod alertmanager-main-0 -n monitoring -o yaml
......
spec:containers:
......volumeMounts:- mountPath: /etc/alertmanager/configname: config-volume- mountPath: /etc/alertmanager/config_outname: config-outreadOnly: true- mountPath: /etc/alertmanager/certsname: tls-assetsreadOnly: true- mountPath: /alertmanagername: alertmanager-main-db
......volumes:
......- emptyDir: {}name: alertmanager-main-db
......
- 如果未指定存储选项,Prometheus 的数据目录 /prometheus 默认情况下将使用EmptyDir 。
- 如果指定了多个存储选项,则优先级如下: 1. emptyDir 2. ephemeral 3. volumeClaimTemplate
创建一个 StorageClass 对象:
# cat alertmanager-storageclass.yaml
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:name: alertmanager-main-db
provisioner: fuseim.pri/ifs
# kubectl create -f alertmanager-storageclass.yaml
配置 CRD 资源对象中 storage 属性
然后在 prometheus 的 CRD 资源对象中通过 storage 属性配置 volumeClaimTemplate 对象即可,更多配置项见API reference。。
# cat alertmanager/alertmanager-alertmanager.yaml......
spec:......replicas: 3storage:volumeClaimTemplate:metadata:name: alertmanager-main-dbspec:storageClassName: alertmanager-main-dbresources:requests:storage: 50Gisecrets: []......
然后更新 prometheus 这个 CRD 资源:
# kubectl create -f alertmanager/alertmanager-alertmanager.yaml
alertmanager.monitoring.coreos.com/main configured# kubectl get pvc -n monitoring |grep 'alertmanager-main-db'
alertmanager-main-db-alertmanager-main-0 Bound pvc-d14694b8-0190-4562-bab6-17cff25e3396 50Gi RWO sfsturbo-monitoring-alertmanager-sc 23m
alertmanager-main-db-alertmanager-main-1 Bound pvc-3dde1f2b-aa44-4002-b3b5-6bd494ace249 50Gi RWO sfsturbo-monitoring-alertmanager-sc 23m
alertmanager-main-db-alertmanager-main-2 Bound pvc-be94da8a-8487-4f05-8eb7-26ce4321aa37 50Gi RWO sfsturbo-monitoring-alertmanager-sc 23m
邮件告警模板配置
创建邮件告警模板的yaml文件
$ vim alertmanager/alertmanager-template.yml
---
apiVersion: v1
kind: ConfigMap
metadata:name: alertmanager-templatesnamespace: monitoring
data:email.tmpl: |{{ define "email.to.html" }}{{- if gt (len .Alerts.Firing) 0 -}}{{ range .Alerts }}=========start==========<br>告警程序: prometheus_alert <br>告警级别: {{ .Labels.severity }} <br>告警类型: {{ .Labels.alertname }} <br>告警主机: {{ .Labels.instance }} <br>告警主题: {{ .Annotations.summary }} <br>告警详情: {{ .Annotations.description }} <br>触发时间: {{ (.StartsAt.Add 28800e9).Format "2006-01-02 15:04:05" }} <br>=========end==========<br>{{ end }}{{ end -}}{{- if gt (len .Alerts.Resolved) 0 -}}{{ range .Alerts }}=========start==========<br>告警程序: prometheus_alert <br>告警级别: {{ .Labels.severity }} <br>告警类型: {{ .Labels.alertname }} <br>告警主机: {{ .Labels.instance }} <br>告警主题: {{ .Annotations.summary }} <br>告警详情: {{ .Annotations.description }} <br>触发时间: {{ (.StartsAt.Add 28800e9).Format "2006-01-02 15:04:05" }} <br>恢复时间: {{ (.StartsAt.Add 28800e9).Format "2006-01-02 15:04:05" }} <br>=========end==========<br>{{ end }}{{ end -}}{{- end }}
kubectl apply -f alertmanager/alertmanager-template.yml
配置 CRD 资源对象 configMaps
$ cat alertmanager/alertmanager-alertmanager.yaml
apiVersion: monitoring.coreos.com/v1
kind: Alertmanager
metadata:labels:app.kubernetes.io/component: alert-routerapp.kubernetes.io/instance: mainapp.kubernetes.io/name: alertmanagerapp.kubernetes.io/part-of: kube-prometheusapp.kubernetes.io/version: 0.27.0name: mainnamespace: monitoring
spec:image: quay.io/prometheus/alertmanager:v0.27.0nodeSelector:kubernetes.io/os: linuxpodMetadata:labels:app.kubernetes.io/component: alert-routerapp.kubernetes.io/instance: mainapp.kubernetes.io/name: alertmanagerapp.kubernetes.io/part-of: kube-prometheusapp.kubernetes.io/version: 0.27.0replicas: 3storage:volumeClaimTemplate:metadata:name: alertmanager-main-dbspec:storageClassName: alertmanager-main-dbresources:requests:storage: 50Giresources:limits:cpu: 100mmemory: 100Mirequests:cpu: 4mmemory: 100Misecrets: []configMaps:- 'alertmanager-templates' # 与 Alertmanager 对象位于同一命名空间的 ConfigMaps 列表,这些 ConfigMaps 挂载到alertmanager容器的/etc/alertmanager/configmaps/<configmap-name>目录中。configSecret: alertmanager-main # 与 Alertmanager 对象位于同一命名空间中的 Secret 的名称,该对象包含此 Alertmanager 实例的配置,此配置应在 alertmanager.yaml 键下可用,原始密钥中的其他密钥将复制到生成的密钥中,并挂载到 alertmanager 容器的 /etc/alertmanager/config 目录中。securityContext:fsGroup: 2000runAsNonRoot: truerunAsUser: 1000serviceAccountName: alertmanager-mainversion: 0.27.0
kubectl apply -f alertmanager/alertmanager-alertmanager.yaml
修改AlertManager配置
$ vim alertmanager/alertmanager-secret.yaml
apiVersion: v1
kind: Secret
metadata:labels:app.kubernetes.io/component: alert-routerapp.kubernetes.io/instance: mainapp.kubernetes.io/name: alertmanagerapp.kubernetes.io/part-of: kube-prometheusapp.kubernetes.io/version: 0.27.0name: alertmanager-mainnamespace: monitoring
stringData:alertmanager.yaml: |-"global":"resolve_timeout": "5m""smtp_smarthost": "smtp.163.com:465""smtp_from": "notify@163.com""smtp_auth_username": "notify""smtp_auth_password": "password""smtp_require_tls": false"templates":- "/etc/alertmanager/configmaps/alertmanager-templates/email.tmpl" # configmaps 挂载的文件路径"route":"group_by": # 根据label标签的key进行匹配,如果是多个,就要多个都匹配- "namespace"- "service"- "alertname""group_interval": "3m" # 当组内已经发送过一个告警,组内若有新增告警需要等待的时间,默认为5m,这条要确定组内信息是影响同一业务才能设置,若分组不合理,可能导致告警延迟,造成影响"group_wait": "15s" # 组内等待时间,同一分组内收到第一个告警等待多久开始发送,目标是为了同组消息同时发送,不占用告警信息,默认30s"repeat_interval": "12h" # 告警已经发送,且无新增告警,若重复告警需要间隔多久 默认4h 属于重复告警,时间间隔应根据告警的严重程度来设置"receiver": "Default" #报警默认接收器"routes":- "matchers":- "alertname = Watchdog""receiver": "Watchdog"- "matchers":- "alertname = InfoInhibitor""receiver": "null"- "matchers":- "severity = critical""receiver": "Critical""inhibit_rules": # 告警收敛 抑制- "equal": # #在源和目标警报中的标签必须具有相等值才能使抑制生效。- "namespace"- "alertname""source_matchers": # 匹配当前告警发生后其他告警抑制掉- "severity = critical" # 指定告警级别"target_matchers": # 抑制告警- "severity =~ warning|info" # 指定抑制告警级别- "equal":- "namespace"- "alertname""source_matchers":- "severity = warning""target_matchers":- "severity = info"- "equal":- "namespace""source_matchers":- "alertname = InfoInhibitor""target_matchers":- "severity = info""receivers":- "name": "Default""email_configs":- "to": "qsh@163.com""html": "{{ template \"email.to.html\" . }}" #添加,指定template中的html页面(与模板中的define对应)"send_resolved": true- "name": "Watchdog"- "name": "Critical"- "name": "null"
type: Opaque
$ kubectl apply -f alertmanager/alertmanager-secret.yaml
secret/alertmanager-main configured
手动重新加载配置
# 重新加载prometheus配置
curl -X POST `kubectl -n monitoring get endpoints prometheus-k8s -o jsonpath={.subsets[0].addresses[0].ip}`:9090/-/reload# 重新加载alertmanager配置
curl -X POST "http://`kubectl -n monitoring get endpoints alertmanager-main -o jsonpath={.subsets[0].addresses[0].ip}`:9093/-/reload"
Grafana 配置
查看生成的 Grafana 挂载情况
$ kubectl get deployment grafana -n monitoring -o yamlapiVersion: apps/v1
kind: Deployment
......volumeMounts:
......- mountPath: /etc/grafananame: grafana-config
......volumes:- name: grafana-configsecret:defaultMode: 420secretName: grafana-config修改 CRD 资源对象配置
$ vim grafana/grafana-config.yaml
apiVersion: v1
kind: Secret
metadata:labels:app.kubernetes.io/component: grafanaapp.kubernetes.io/name: grafanaapp.kubernetes.io/part-of: kube-prometheusapp.kubernetes.io/version: 11.0.0name: grafana-confignamespace: monitoring
stringData:grafana.ini: |#################################### Grafana Image Renderer Plugin ##########################[date_formats]default_timezone = browser#################################### Server ####################################[server]domain = grafana.qshtest.net## 您在浏览器中使用的完整面向公众的 URL,用于重定向和电子邮件 如果您使用反向代理和子路径,请指定完整 url(带有子路径)root_url = %(protocol)s://%(domain)s:/grafana/serve_from_sub_path = true#################################### Database #########################################外部数据库配置[database]type = mysqlhost = 192.168.10.10:3306name = grafanauser = opspassword = Ops@dba#################################### Data proxy ###########################[dataproxy]timeout = 180#################################### Security ######################################默认管理员是admin,admin,也可以登录后修改,届时帐号密码就保存到mysql里了。[security]admin_user = admin#################################### SMTP / Emailing ##########################[smtp]enabled = truehost = smtp.163.com:465user = notify@163.compassword = xxxxxxxxxxxxxxJUskip_verify = truefrom_address = notify@163.comfrom_name = Grafana#################################### Auth LDAP ##########################[auth.ldap]enabled = trueconfig_file = /etc/grafana/ldap.toml# 启用 LDAP 后,默认行为是在 LDAP 身份验证成功后自动创建 Grafana 用户。# 如果您希望只有现有的 Grafana 用户能够登录,您可以在[auth.ldap]部分中更改allow_sign_up为falseallow_sign_up = true# 阻止同步 LDAP 用户|组织|角色;skip_org_role_sync = false[log]mode = 'console'#filters = 'ldap:debug' # 激活LDAP回传日志显示filters = 'auth:debug'ldap.toml: |[[servers]]host = "ldap.qshtest.net"port = 389use_ssl = falsestart_tls = falsessl_skip_verify = false# Search user bind dnbind_dn = "cn=admin,dc=qshtest,dc=net"bind_password = """Ldap@123"""# Timeout in seconds (applies to each host specified in the 'host' entry (space separated))timeout = 30# User search filter, for example "(cn=%s)" or "(sAMAccountName=%s)" or "(uid=%s)"#search_filter = "(cn=%s)"search_filter = "(|(cn=%s)(cn=grafana*))"# An array of base dns to search throughsearch_base_dns = ["ou=People,dc=qshtest,dc=net"]# Specify names of the ldap attributes your ldap uses[servers.attributes]name = "givenName"surname = "sn"username = "uid"member_of = "memberOf"email = "mail"# Map ldap groups to grafana org roles[[servers.group_mappings]]group_dn = "cn=grafana-admin,ou=Grafana,ou=Groups,dc=qshtest,dc=net"org_role = "Admin"grafana_admin = trueorg_id = 2[[servers.group_mappings]]group_dn = "cn=grafana-editor,ou=Grafana,ou=Groups,dc=qshtest,dc=net"org_role = "Editor"org_id = 2[[servers.group_mappings]]group_dn = "*"org_role = "Viewer"org_id = 2
type: Opaque然后更新这个 CRD 资源
kubectl apply -f grafana/grafana-config.yaml
Ingress 配置
---
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:name: ingress-grafananamespace: monitoringannotations:nginx.ingress.kubernetes.io/proxy-read-timeout: "3600"nginx.ingress.kubernetes.io/proxy-send-timeout: "3600"nginx.ingress.kubernetes.io/upstream-keepalive-timeout: "3600"nginx.ingress.kubernetes.io/server-snippet: |rewrite ^/$ /grafana/ permanent;
spec:ingressClassName: nginx-ingresstls:- {}rules:- host: grafana.qshtest.comhttp:paths:- path: /grafana/pathType: ImplementationSpecificbackend:service:name: grafanaport:number: 3000property:ingress.beta.kubernetes.io/url-match-mode: STARTS_WITH- path: /grafana/api/live/pathType: ImplementationSpecificbackend:service:name: grafanaport:number: 3000关于 Prometheus Operator 的其他高级用法可以参考官方文档 https://prometheus-operator.dev 了解更多信息。
本文参考资料:https://docs.youdianzhishi.com/k8s/monitor/operator/install/