贴脸细看Mixtral 8x7B- 稀疏混合专家模型(MoE)的创新与推动
原创 一路到底孟子敬 上堵吟 2024年01月15日 20:05 美国
I. 引言
A. Mixtral 8x7B的背景和目的
• 背景:随着大型语言模型在自然语言处理(NLP)领域的广泛应用,模型的规模和性能不断增长,但同时也带来了计算资源和存储成本的挑战。为了在保持模型性能的同时,提高效率和可扩展性,研究者们探索了多种模型架构和技术。
• 目的:Mixtral 8x7B模型的开发旨在通过稀疏混合专家(MoE)架构,实现在保持或超越现有模型性能的同时,减少模型的活跃参数数量,从而提高推理速度和降低成本。
B. 稀疏混合专家(MoE)模型的基本概念
• 定义:稀疏混合专家模型是一种神经网络架构,它通过将模型的前馈网络(FFN)分解为多个专家网络,并通过一个路由机制来选择哪些专家参与当前输入的处理。
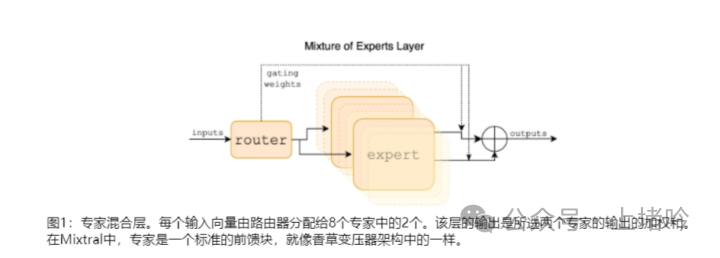
• 核心思想:MoE模型通过在每个层级中只激活部分专家网络来处理输入,从而减少了每个输入标记所需的计算量。这种方法允许模型在保持大规模参数的同时,通过有效利用这些参数来提高性能。
• 优势:MoE模型通过这种稀疏激活机制,可以在不牺牲模型容量的情况下,实现更快的推理速度,这对于实时应用和资源受限的环境尤为重要。此外,MoE模型在多任务学习和迁移学习中也显示出了潜力,因为它可以为不同的任务或数据类型分配专门的专家网络。
II. Mixtral 8x7B的架构与创新
A. 与Mistral 7B的比较
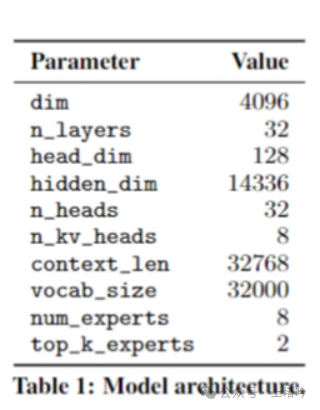
• Mixtral 8x7B在架构上与Mistral 7B保持一致,但在专家网络的组织和使用上有所不同。Mistral 7B是一个标准的Transformer模型,而Mixtral 8x7B则引入了MoE架构,每个层级由8个专家组成,这些专家是独立的前馈网络。
• Mixtral 8x7B通过MoE架构实现了在保持模型大小不变的情况下,提高了模型的灵活性和效率,这在处理不同任务和数据类型时尤为重要。
B. 每个层级包含8个前馈块(专家)的设计
• 在Mixtral 8x7B中,每个Transformer层级被分解为8个独立的专家网络,每个专家网络负责处理输入数据的一部分。这种设计允许模型在每个层级上并行处理信息,从而提高了计算效率。
• 每个专家网络都有自己的参数集,但模型在推理时只会激活部分专家,这减少了所需的计算资源。
C. 路由器网络在每个时间步选择专家的机制
• 路由器网络是MoE架构的关键组成部分,它负责在每个时间步为每个输入标记选择两个专家网络。这种选择基于输入标记的特征,通过一个门控网络来实现,该网络输出一个概率分布,指示哪些专家应该被激活。
• 路由器网络的设计使得模型能够动态地根据输入内容调整专家的激活,从而提高了模型的适应性和灵活性。
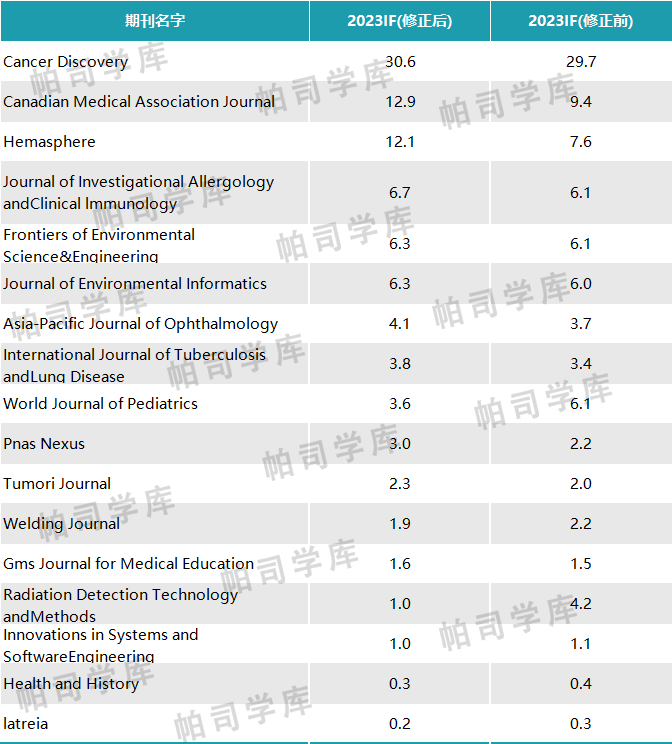
D. 参数使用效率:47B参数中的13B活跃参数
• 尽管Mixtral 8x7B模型拥有47B的总参数量,但在推理过程中,每个输入标记实际上只使用了13B的活跃参数。这种参数稀疏性使得模型在保持高性能的同时,大幅降低了计算成本和内存需求。
• 这种效率的提升对于在资源受限的环境下部署大型语言模型至关重要,它使得模型可以在更广泛的应用场景中发挥作用,包括移动设备和边缘计算。
III. Mixtral 8x7B的性能与效果
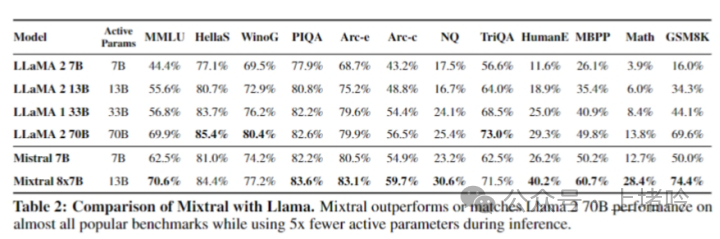
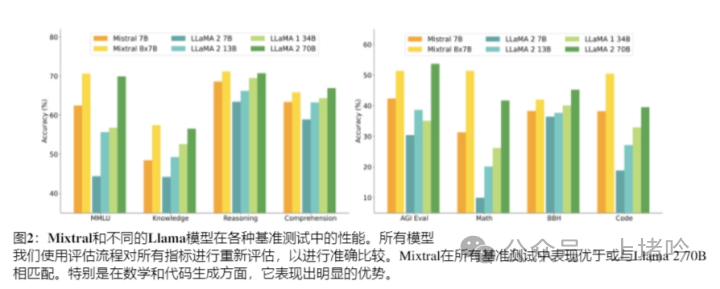
A. 在多语言理解、数学和代码生成任务中的卓越表现
• Mixtral 8x7B在多语言理解任务中表现出色,特别是在处理法语、德语、西班牙语和意大利语等语言时,其性能显著优于Llama 2 70B。
• 在数学任务中,Mixtral 8x7B展示了其强大的计算能力和对复杂数学概念的理解,这在GSM8K和MATH等数学基准测试中得到了验证。
• 在代码生成任务中,Mixtral 8x7B能够生成高质量的代码,这在Humaneval和MBPP等代码生成基准测试中得到了体现。
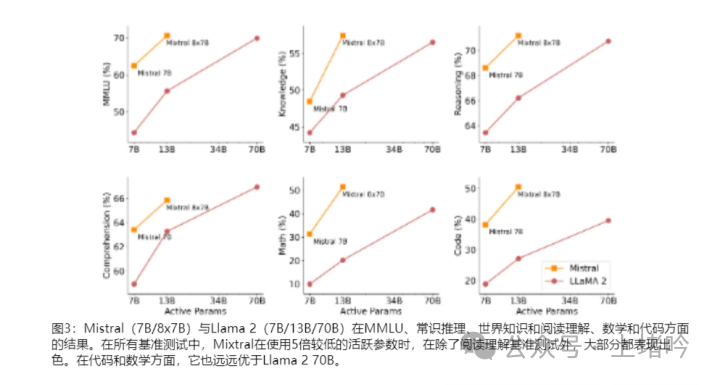
B. 与Llama 2 70B和GPT-3.5的比较
• Mixtral 8x7B在多个基准测试中与Llama 2 70B和GPT-3.5进行了比较,结果显示Mixtral在大多数任务中都能匹配或超越这两个模型的性能。
• 尤其是在数学和代码生成任务中,Mixtral 8x7B的性能远远超过了Llama 2 70B,这表明MoE架构在这些领域具有显著的优势。
C. Mixtral 8x7B – Instruct模型在遵循指令方面的改进
• Mixtral 8x7B – Instruct是一个经过指令微调的版本,它在遵循指令方面进行了优化,这在MT-Bench等人类评估基准测试中得到了验证。
• 通过监督微调和直接偏好优化(DPO),Mixtral 8x7B – Instruct在遵循指令和生成连贯对话方面表现出色,其性能超过了GPT-3.5 Turbo、Claude-2.1、Gemini Pro和Llama 2 70B – chat模型。
• 这种改进不仅提高了模型的实用性,还减少了偏见,提供了更平衡的情感分析,这在BBQ和BOLD等偏见基准测试中得到了体现。
IV. MoE技术的推动效应
A. 提高模型的计算效率和推理速度
• MoE技术通过在每个时间步只激活部分专家网络,显著减少了模型在推理过程中的计算需求,从而提高了计算效率。
• 这种设计使得模型能够在保持性能的同时,减少所需的计算资源,这对于资源受限的环境尤其有益。
B. 在低批量大小下实现更快的推理速度
• 对于小批量输入,MoE模型能够快速地处理每个输入标记,因为每个标记只需要与少数专家网络交互,而不是整个模型。
• 这种特性使得MoE模型在处理小规模查询时能够提供快速响应,这对于需要实时交互的应用场景至关重要。
C. 在大批量大小下实现更高的吞吐量
• 在处理大量数据时,MoE模型可以通过并行化处理多个输入标记来提高吞吐量。每个专家网络可以独立地处理分配给它的标记,从而加速整体处理速度。
• 这种并行处理能力使得MoE模型在数据中心和云计算环境中特别有吸引力,因为它们可以有效地利用多核处理器和分布式计算资源。
D. 对多语言数据和长序列处理的改进
• MoE模型在处理多语言数据时表现出了优势,因为它可以为不同的语言分配专门的专家网络,从而提高模型在特定语言任务上的性能。
• 对于长序列数据,MoE模型通过在每个层级上只激活部分专家网络,有效地管理了模型的内存需求,使得模型能够处理更长的文本序列,而不会出现性能下降。

V. 专家选择的分析
A. 专家选择的随机性与领域无关性
• 分析表明,专家选择在不同领域(如数学、生物学、哲学等)之间没有明显的模式,这表明专家选择过程在很大程度上是随机的,而不是基于领域特定的内容。
• 这种随机性可能意味着MoE模型在处理不同类型数据时能够保持一定的通用性,而不是过度依赖于特定领域的专家网络。
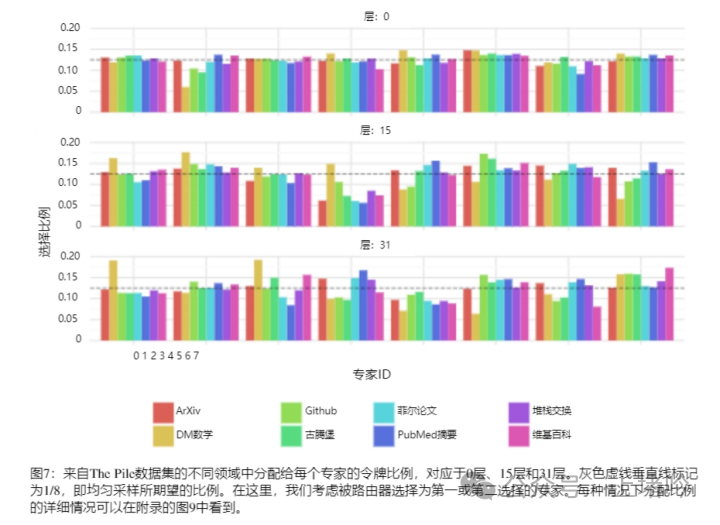
B. 专家选择与语法结构的关联性
• 研究观察到,专家选择似乎更倾向于与语法结构相关,尤其是在模型的初始和最终层级。例如,连续的标记(如代码中的缩进标记)倾向于被分配给相同的专家。
• 这种关联性可能反映了MoE模型在处理语言时对语法结构的敏感性,这可能有助于模型更好地理解和生成语言。

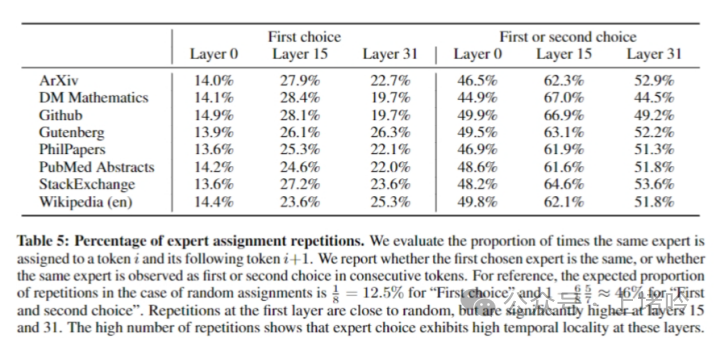
C. 时间局部性对模型训练和推理的影响
• 在模型的不同层级中,连续标记被分配给相同专家的比例有所不同,特别是在模型的中间层级,这种时间局部性更为明显。
• 时间局部性可能对模型的训练和推理有重要影响。在训练过程中,这种局部性可能导致某些专家网络的过载,而在推理过程中,这种局部性可以被用来优化模型的并行处理和缓存策略,从而提高效率。
VI. 结论
A. Mixtral 8x7B在开放源码模型中达到的最新性能水平
• Mixtral 8x7B模型展示了MoE架构在开放源码模型中的潜力,它在多个基准测试中超越了现有的大型语言模型,如Llama 2 70B和GPT-3.5,同时使用了更少的活跃参数。
• 这一成就标志着MoE技术在提高模型效率和性能方面的一个重要里程碑,为未来的研究和应用奠定了基础。
B. 通过Apache 2.0许可的模型发布对研究和应用的促进
• 将Mixtral 8x7B模型及其变体发布在Apache 2.0许可下,有助于促进学术界和工业界的广泛研究和创新。
• 开放源码的模型使得研究人员可以自由地探索新的训练技术、微调策略和应用场景,同时也为开发者提供了一个强大的工具,用于构建各种语言处理应用。
C. MoE技术对未来语言模型发展的潜在影响
• MoE技术通过其在计算效率和性能上的优势,预示着未来大型语言模型的新发展方向。
• 随着MoE技术的进一步发展和优化,预计它将在多任务学习、跨语言理解和长序列处理等领域发挥更大的作用,推动自然语言处理技术的边界不断扩展。
论文:
arXiv:2401.04088v1 [cs.LG] 8 Jan 2024
代码和网页
Code: https://github.com/mistralai/mistral-src
Webpage: https://mistral.ai/news/mixtral-of-experts/