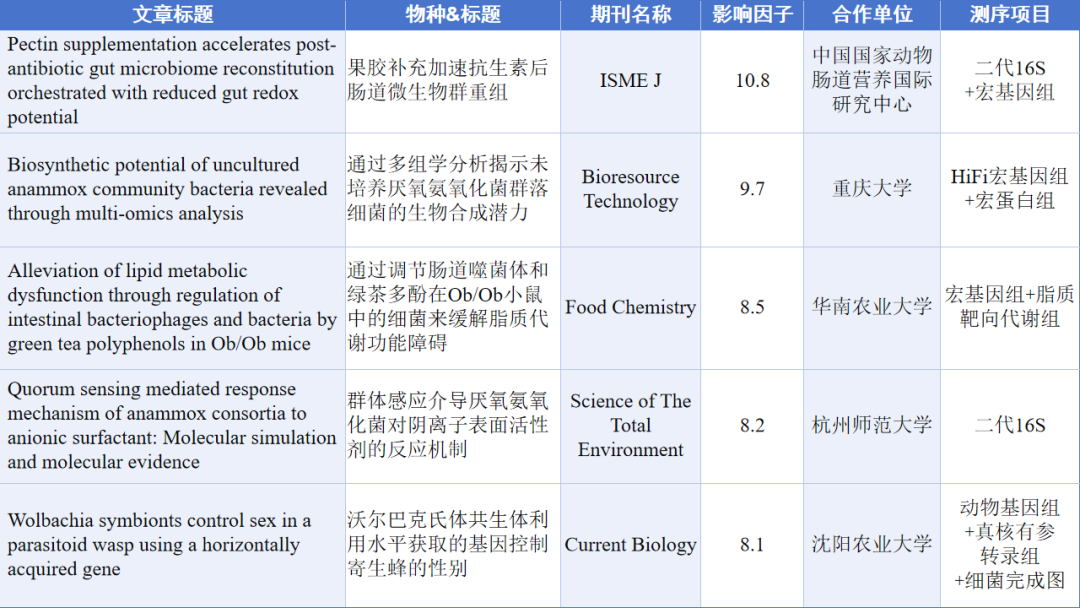
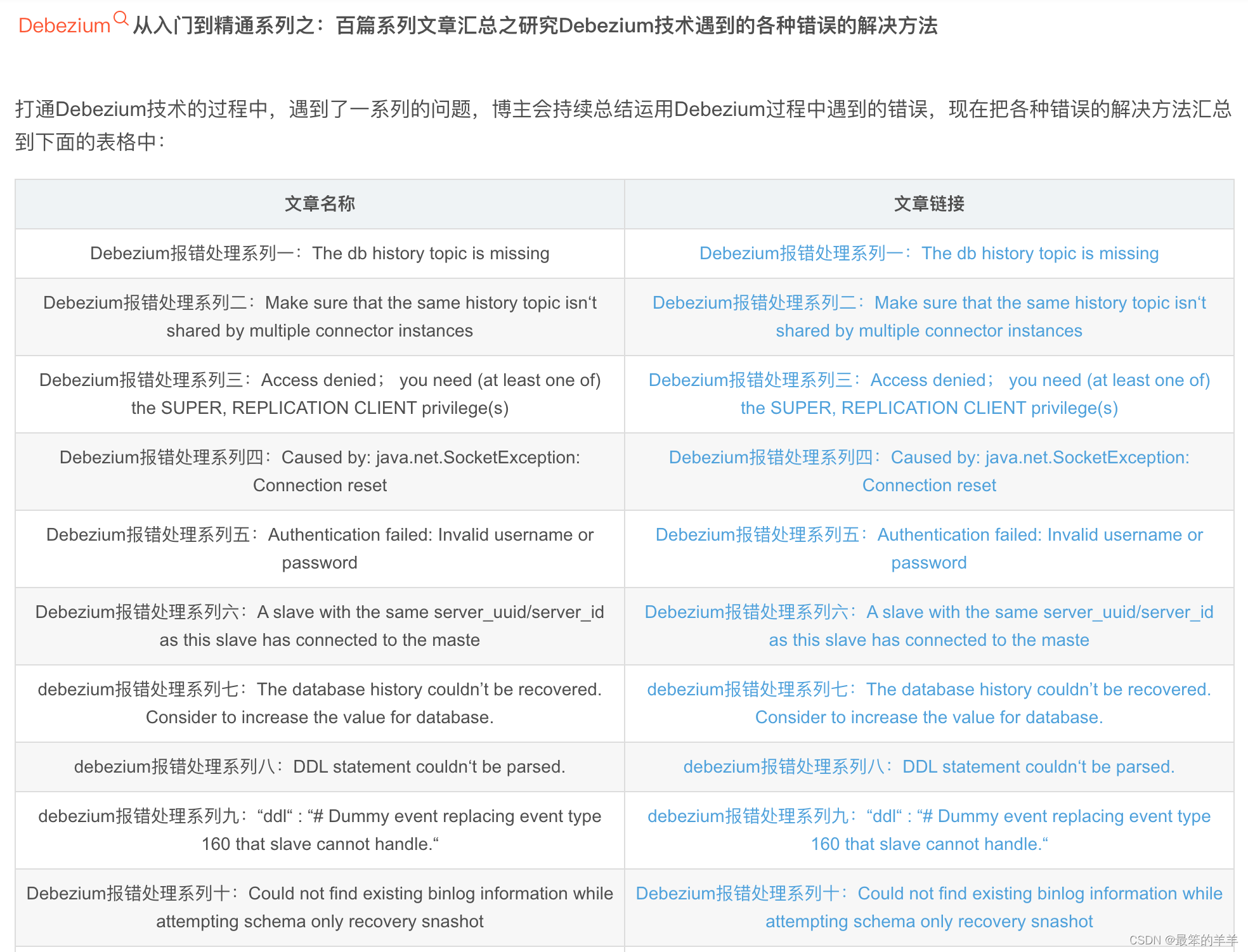
正文
我们先来看一个简单的case。
有一组坐落在x轴的点集,最小和最大的数值为-4和4。我用浅绿色将这些点标记,记作 X 0 X_0 X0

X 0 ∈ { ( − 4 , 0 ) , ( − 3 , 0 ) , ( − 2 , 0 ) , ( − 1 , 0 ) , ( 0 , 0 ) , ( 1 , 0 ) , ( 2 , 0 ) , ( 3 , 0 ) , ( 4 , 0 ) } X_0 \in \{(-4,0), (-3,0),(-2,0),(-1,0),(0,0),(1,0),(2,0),(3,0),(4,0) \} X0∈{(−4,0),(−3,0),(−2,0),(−1,0),(0,0),(1,0),(2,0),(3,0),(4,0)}
很明显, X 0 X_0 X0分布的特点是9个点都坐落在X轴上,并且有大小范围约束。
那么,如果我们想将 X 0 X_0 X0代表的线段分布变成半圆线段,该如何做呢?
用 X 1 X_1 X1记作半圆线段对应的分布,学过高中数学的同学会想到圆形公式:
x 0 2 + x 1 2 = 4 2 x 1 = 4 2 − x 0 2 x_0^2 + x_1^2 = 4^2 \\ x_1 = \sqrt {4^2 - x_0^2} x02+x12=42x1=42−x02
这里我们只考虑正半轴的情况。因此,定义 f ( x ) = 4 2 − x 2 f(x)=\sqrt {4^2 - x^2} f(x)=42−x2 是将分布 X 0 X_0 X0转为 X 1 X_1 X1的精准映射函数

用红色的点集表示分布 X 1 X_1 X1。
然而现实问题会更加复杂,我们往往找不到一个精准映射的函数,更多的问题是已知 X 0 X_0 X0和 X 1 X_1 X1,需要找到 f f f。因此考虑一种复杂的情况,已知X和Y,但不知道 f f f,如何让X分布映射到Y上。
有的同学可能想到了,我们可以设计一条轨迹,或者叫路径,让 X 0 X_0 X0逐渐往 X 1 X_1 X1上迁移,这个轨迹可能有很多步,我们假设第0步为0,最后一步为1。0-1之间的任意步骤都是轨迹上的中间态 X t X_t Xt。
那我们可以设计一个最简单的路径,路径上的中间态 X t X_t Xt为
X t = ( 1 − t ) × X 0 + t × X 1 X_t = (1-t) \times X_0 + t \times X_1 Xt=(1−t)×X0+t×X1
t t t表示0-1之间的任意一步,当t为0,即轨迹的起点,公式最终得到的是 X 0 X_0 X0;反之当t越大, X t X_t Xt越接近 X 1 X_1 X1
但就像之前说的,实际情况往往更加复杂,假设X0是一个非常复杂的分布,比如真实图像;X1是个很简单的分布,比如标准高斯噪声,就像DDPM做图像生成任务一样。
我们发现,从X0到X1是简单的,使用以上设计的路径依然成立,即我们可以将任何来自真实图像分布的数据变成随机标准正态分布;但从X1到X0是复杂的,我们无法使用这么简单的路径将随机噪声变成真实图像。
首先约定,从 X 0 X_0 X0到 X 1 X_1 X1的过程为正向过程;从 X 1 X_1 X1到 X 0 X_0 X0的过程为反向过程。 t t t的每一步变化长度最小为 d t dt dt
如果没办法使用前向路径的反向公式变换,实现反向过程,我们就设计一个映射函数,帮助我们实现反向过程。
在前向过程中,根据公式
X t = ( 1 − t ) × X 0 + t × X 1 X_t = (1-t) \times X_0 + t \times X_1 Xt=(1−t)×X0+t×X1,我们可以得到任意 x t x_t xt,当然也包括 x t − d t x_{t-dt} xt−dt。因此我们就可以得到训练pair数据 ( x t , x t − d t ) (x_t, x_{t-dt}) (xt,xt−dt),用于训练一个映射模型 f ( x t , t ) f(x_t, t) f(xt,t),得到轨迹中的 t t t时刻前一时刻 t − d t t-dt t−dt的状态 x t − d t x_{t-dt} xt−dt。
那么,再细想一下,映射模型的拟合对象该如何设计?
根据公式 X t = ( 1 − t ) × X 0 + t × X 1 X_t = (1-t) \times X_0 + t \times X_1 Xt=(1−t)×X0+t×X1,我们已知 x t x_t xt是模型的输入,得到 X 0 X_0 X0可以推导出 X 1 X_1 X1的有偏估计,反之得到 X 1 X_1 X1也能推导出 X 0 X0 X0的有偏估计,通过 X t − d t = ( 1 − ( t − d t ) ) × X 0 + ( t − d t ) × X 1 X_{t-dt}= (1-(t-dt)) \times X_0 + (t-dt) \times X_1 Xt−dt=(1−(t−dt))×X0+(t−dt)×X1,我们就能得到前一个状态的估计了,也就是 x t − d t x_{t-dt} xt−dt。
因此 f f f的拟合对象有3个选择:
- 直接拟合 x t − d t x_{t-dt} xt−dt,毕竟我们有了训练数据pair对,我们直接拟合前一步的状态值即可。
- 拟合 X 0 X_0 X0
- 拟合 X 1 X_1 X1
然而,论文DDPM中证明了这三种在原理上是等价的(经过一系列的公式换算可以等价,本篇文章目的是使用简单的方式介绍DDPM,因此不进行展开描述)。同时作者经过实验,认为拟合 X 1 X_1 X1效果较好。因此
x 1 e s t = f ( x t , t ) x 0 e s t = x t − t × x 1 1 − t x t − d t e s t = ( 1 − ( t − d t ) ) × x 0 e s t + ( t − d t ) × x 1 e s t x_1^{est} = f(x_t, t) \\ x_0^{est} = \frac{x_t - t \times x_1}{1-t} \\ x_{t-dt}^{est} = (1-(t-dt)) \times x_0^{est} + (t-dt) \times x_1^{est} x1est=f(xt,t)x0est=1−txt−t×x1xt−dtest=(1−(t−dt))×x0est+(t−dt)×x1est
首先模型估计出 x 1 e s t x_1^{est} x1est,利用公式变换形式,进而估计出 x 0 e s t x_0^{est} x0est;最后仍然是根据公式得到 x t − d t e s t x_{t-dt}^{est} xt−dtest。接着这个过程只要重复 t / d t t / dt t/dt次,我们就可以得到将分布 X 1 X_1 X1变成 X 0 X_0 X0的轨迹,实现了完整的反向过程。
接着,我们以X1和X0的点集数据为例,训练一个 f f f模型,同时观察测试集上的轨迹变化,是否符合我们的预期。
记 X 1 X_1 X1为在半圆上的点, X 0 X_0 X0为x轴上的点,
定义公式 X t = ( 1 − t ) × X 0 + t × X 1 X_t = (1-t) \times X_0 + t \times X_1 Xt=(1−t)×X0+t×X1
def get_x_t(t, x0, x1):return x0 * (1-t) + x1 *
公式变换,定义 x 0 x_0 x0的有偏估计
def get_x0(xt, t, x1):return (xt - t * x1) / (1 - t + 1e-7)
定义 f ( x t , t ) f(x_t, t) f(xt,t),因为我们的任务很简单,使用一个简单的4层mlp足够了
class mlp(torch.nn.Module):def __init__(self, *args, **kwargs) -> None:super().__init__(*args, **kwargs)self.nn = torch.nn.Sequential(torch.nn.Linear(2+1, 128),torch.nn.ReLU(),torch.nn.Linear(128, 128),torch.nn.ReLU(),torch.nn.Linear(128, 128),torch.nn.ReLU(),torch.nn.Linear(128, 2),)def forward(self, xt, t):x_t = torch.cat([xt, t], dim=1)return self.nn(x_t)model = mlp()
model.cuda()
model.train()
定义反向采样过程
x 1 e s t = f ( x t , t ) x 0 e s t = x t − t × x 1 1 − t x t − d t e s t = ( 1 − ( t − d t ) ) × x 0 e s t + ( t − d t ) × x 1 e s t x_1^{est} = f(x_t, t) \\ x_0^{est} = \frac{x_t - t \times x_1}{1-t} \\ x_{t-dt}^{est} = (1-(t-dt)) \times x_0^{est} + (t-dt) \times x_1^{est} x1est=f(xt,t)x0est=1−txt−t×x1xt−dtest=(1−(t−dt))×x0est+(t−dt)×x1est
class DDPM():def __init__(self, model, total_step=11) -> None:self.total_step = total_stepself.model = model@torch.no_grad()def sample(self, x1):step = torch.linspace(0.0, 0.95, self.total_step).flip(0).to(x1.device)self.model.eval()x1[:, 1] = x1[:, 1] * 0.95 # 消除当t为1时,get_x0中的分母影响bs = x1.shape[0]traj = []xt = x1traj.append(xt)for step_idx in range(self.total_step):# step从0.95变到0x1 = self.model(xt, step[step_idx].view(1, 1).expand(bs, -1))x0 = get_x0(xt, step[step_idx].item(), x1)if step_idx < (self.total_step - 1):x_t_1 = get_x_t(step[step_idx + 1], x0, x1)# 将计算的前一时刻状态重新赋值给x_txt = x_t_1traj.append(xt)# 最终的x0是我们所需要的反向过程的最终输出traj.append(x0)return x0, trajddpm_sample = DDPM(mlp, total_step=100)
定义训练过程
def train_loop():optim = torch.optim.AdamW(model.parameters(), lr=1e-4)# 训练2000步loss_list = []for idx in tqdm(range(2000)):# 随机生成一些数据x_0_data_x = np.random.uniform(-4, 4, (1000,))x_0_data = np.stack([x_0_data_x, np.zeros_like(x_0_data_x)], axis=1) # 1000, 2x_1_data_x = np.random.uniform(-4, 4, (1000,))x_1_data_y = (16 - x_1_data_x ** 2) **0.5x_1_data = np.stack([x_1_data_x, x_1_data_y], axis=1) # 1000,2x_0_data = torch.from_numpy(x_0_data).float().cuda()x_1_data = torch.from_numpy(x_1_data).float().cuda()n_data = x_1_data.shape[0]# 随机生成一些时刻time_data = torch.rand((n_data, 1)).to(x_0_data.device)x_t = get_x_t(time_data, x_0_data, x_1_data)target = x_1_data # 拟合对象为X1pred = model(x_t, time_data)loss = torch.nn.functional.mse_loss(pred, target)# print(f'loss:{loss:.3f}, {pred[:10]}')optim.zero_grad()loss.backward()optim.step()loss_list.append(loss.item())return loss_list, model
# 开始训练
loss_list, model = train_loop()
plt.plot(np.arange(len(loss_list)), loss_list)
plt.savefig('loss_curve.jpg')
定义测试过程
ddpm_sample = DDPM(model, total_step=100)
# 测试, 重新生成一批X1, 一共20个点
x_1_data_x = np.random.uniform(-4, 4, (20,))
x_1_data_y = (16 - x_1_data_x ** 2) **0.5
x_1_data = np.stack([x_1_data_x, x_1_data_y], axis=1) # 20,2
x_1_data = torch.from_numpy(x_1_data).float().cuda()x0, traj = ddpm_sample.sample(x_1_data)
figure = plt.figure()
for t in traj[-1:]:t = t.cpu().numpy()plt.scatter(t[:, 0], t[:, 1])
x_1_data = x_1_data.cpu().numpy()
plt.scatter(x_1_data[:, 0], x_1_data[:, 1], c='r')
figure.savefig("trajectory.jpg")
loss曲线

下面是轨迹图,最上面的红色点是分布 X 1 X_1 X1,都在一个半圆上面。顺着轨迹上的100个中间状态,慢慢变成了最下面的蓝色点。蓝色点虽然不完全在X轴上,但都大致离X轴接近,并且数值范围在-4到4,满足 X 0 X_0 X0的分布特点。观察轨迹符合我们的预期,模型训练成功。

回到图像生成DDPM
DDPM的前向公式为

其实就是
x t = a ‾ t x 0 + ( 1 − a ‾ t I x_t = \sqrt{\overline{a}_t} x_0 + (1 - {\overline{a}_t} I xt=atx0+(1−atI
我们把 I I I当成 X 1 X_1 X1,那么DDPM前向公式的形式就和我之前介绍的一致了。
再看DDPM中如何得到 x t − 1 x_{t-1} xt−1

你会发现其实就是两项相加,第一项是关于 x 0 x_0 x0和 x t x_t xt的加权,这个也和我们的推导 x t − d t e s t = ( 1 − ( t − d t ) ) × x 0 e s t + ( t − d t ) × x 1 e s t x_{t-dt}^{est} = (1-(t-dt)) \times x_0^{est} + (t-dt) \times x_1^{est} xt−dtest=(1−(t−dt))×x0est+(t−dt)×x1est类似,只是他还有第三项 β t \beta_t βt,而这一项是已知的数值。
你可能会好奇,这个前向公式是如何得来的呢?
你还可能会好奇,建立在马尔科夫链假设上的ddpm,为何优化目标可以被简化到直接对x_1$进行拟合呢?
这些内容,在未来继续分享。
本文总结
本文从一个简化的问题入手,用两个不同分布的点集这种简单的数据类型作为样例,讲解了DDPM问题的建模过程,整个建模过程的核心是设计前向公式,并围绕着前向公式变换为推理过程,进而引导读者思考模型在推理过程中起到的作用。 并用python代码做了训练和测试的实验,最终的结果也符合我们的预期。从理论和实践上较为完整的介绍了DDPM的核心思想和使用方法。
本文为作者原创,转载请注明出处
















![C# Bitmap类型与Byte[]类型相互转化详解与示例](https://i-blog.csdnimg.cn/direct/a3bbd63c44ac40dd9eafd082c90cd103.jpeg#pic_center)
