Java进阶08 集合(续)&Stream流
一、HashSet集合类(续)
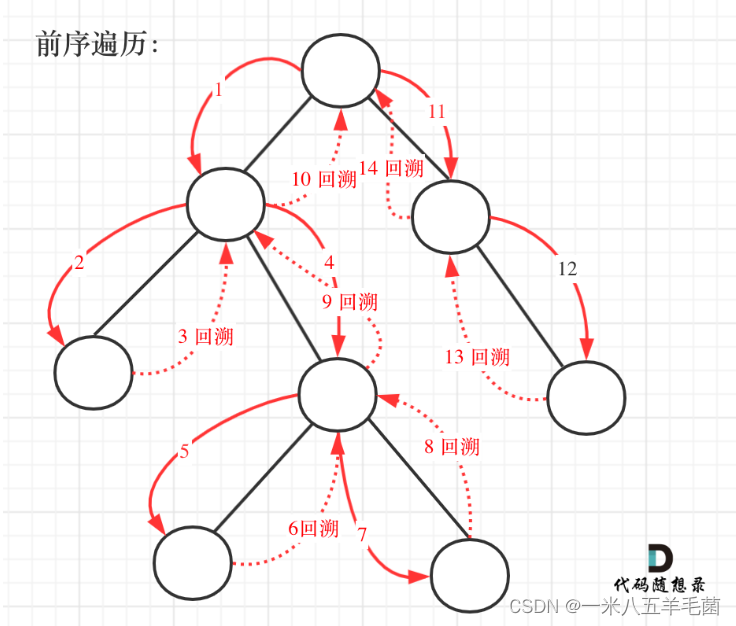
1、JDK7(-)HashSet原理解析
1.1 底层结构
数组+链表
1.2 执行过程
①创建一个默认长度为16的数组,数组名为table
②根据元素的哈希值跟数组的长度求余计算出应存入的位置
③判断当前位置是否为null,如果是null直接头插法存入
④如果位置不为null,表示该位置已用元素,则调用equals方法比较
⑤如果元素内容一样,则不存;如果不一样,则头插法存入
2、⭐JDK8(+)HashSet原理解析
2.1 底层结构
哈希表(数组+链表+红黑树)
2.1 执行过程
①创建HashSet集合,默认长度为16、默认加载因子0.75的数组,数组名table
②调用集合的添加方法,添加对象调HashCode方法计算出应存入的索引位置(二次哈希值%数组长度)

③判断索引位置元素是否是null:是null,尾插法存入、不是null说明有元素,调用equals方法比较内容
④比较内容一样,不存;不一样,尾插法存入
2.3 提高查询性能
-
扩容数组
扩容条件
-
当数组中的元素个数到达了16*0.75(加载因子)=12,扩容发生在第13次,扩容原数组2倍的大小,
-
链表挂载的元素超过了8(阈值),并且数组长度没有超过64
-
-
链表转红黑树(极少触发)
链表挂载的元素超过了(>)阈值8个,并且数组长度到达了(>=)64
3、相关面试题
Q:请说明HashSet实现的原理
A:首先,在添加元素时会先调用HashCode方法得到一个应存入位置的索引,然后检查该位置上是否有元素,没有直接尾插法存入,已有元素就需要调用equals方法逐个与该索引位置已存入的元素比较内容;内容均不相同则尾插法存入,相同就不存。其次,HashCode计算索引位置的过程是:首先调用HashCode方法得到原始的哈希值,再对该值进行哈希扰动右移16位,再和原始哈希值做异或操作得到二次哈希值,最后使用二次哈希值模与数组长度得到索引位置。但是在源码实现中,最后索引计算是通过数组长度减1再和二次哈希值逻辑与得到的,结果和上面一致,但与的执行效率比模更快。最后,之所以要对哈希值进行这么多复杂的操作是为了尽可能让要添加的元素哈希值散列在不同索引下,降低索引冲突。
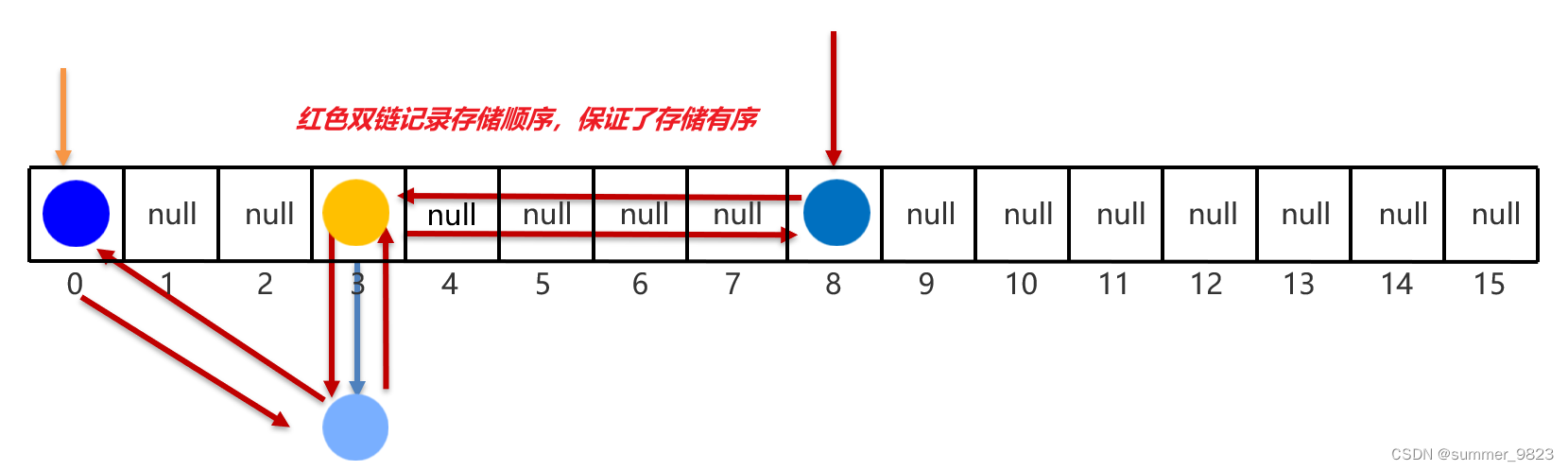
二、LinkedHashSet集合类
LinkedList是Set集合中唯一可以去重并且存取有序的集合
1、存取有序原理
底层数据结构依然是哈希表,只是每个元素又额外的多了一个双链表的机制记录存储的顺序
♥单列集合使用场景大总结♥
List派系集合中,ArrayList集合首选;Set集合中,HashSet集合用的最多!
-
集合元素可重复→→→选择ArrayList集合(用的最多)
-
集合元素可重复,且增删操作多于查询→→→选择LinkedList
-
对集合元素去重→→→选择HashSet集合(用的最多)
-
对集合元素去重,且保证存取顺序→→→选择LinkedHashSet,效率低于HashSet
-
对集合元素进行排序→→→选择TreeSet,后续也可以用List集合实现排序
三、Collections集合类
1、可变参数
JDK5版本出现的技术,可以在定义方法的时候灵活的接收参数(可以不给参数,可以给1个或多个,也可以给一个数组),其底层本质就是一个数组。
-
格式:数据类型...参数名称,参考addAll方法的第二个参数
-
注意事项:一个形参列表中可变参数只能有一个;可变参数必须放在形参列表的最后面。
2、Collections集合工具类
java.utils.Collections是集合工具类,并不属于集合,只是用来操作集合的工具类
2.1 常用方法
| 方法 | 说明 |
|---|---|
| public static <T> boolean addAll(Collection<? super T> c,T...elements) | 批量添加数据到集合 |
| public static void shuffle(List<?> list) | 打乱list集合元素的顺序(洗牌) |
| public static <T> int binarySearch(List<T> list,T key) | 以二分查找法查找元素(只能操作list集合) |
| public static <T> void copy(List<T> dest,List<T> src) 不常用 | 拷贝集合中的元素 |
| public static <T> int fill(List<T> list,T obj) 不常用 | 使用指定的集合填充 |
| public static <T> void max/min(Collection<T> coll) | 根据默认的自然排序获取最大/最小值 |
| public static <T> void swap(List<?> list,int i,int j) | 交换集合中指定位置的元素 |
| public static <T> void sort(List<T> list) | 将集合中元素按默认规则排序 |
| public static <T> void sort(List<T> list,Comparator<? super T> c) | 将集合中元素按照指定规则排序 |
注意:两个排序方法只能对List集合排序;使用默认规则排序方法对自定义类型的List集合排序时,要让自定义类实现比较规则Comparable接口
2.2 方法使用Demo
public class CollectionsDemo {public static void main(String[] args) {// 1. 批量添加数据到集合ArrayList<String> list = new ArrayList<>();Collections.addAll(list, "a", "b", "c", "d");System.out.println(list);
// 2. 打乱集合中的元素Collections.shuffle(list);System.out.println(list);
// 3. 使用二分查找法, 查找元素在集合的索引位置ArrayList<Integer> nums = new ArrayList<>();Collections.addAll(nums, 1, 2, 3, 4, 5, 6, 7);System.out.println(Collections.binarySearch(nums, 3));
// 4. 求最值 (这两个方法操作的数据, 需要具有可比性)System.out.println(Collections.max(nums));System.out.println(Collections.min(nums));
ArrayList<Student> students = new ArrayList<>();Collections.addAll(students, new Student("张三", 23),new Student("李四", 24), new Student("王五", 25));
System.out.println(Collections.max(students));System.out.println(Collections.min(students));
// 5. 交换集合中指定索引位置的元素Collections.swap(nums, 0, 1);System.out.println(nums);
// 6. 对集合内容排序 (自然排序)Collections.sort(list);System.out.println(list);
// 7. 对集合内容排序 (比较器)Collections.sort(nums, new Comparator<Integer>() {@Overridepublic int compare(Integer o1, Integer o2) {return o2 - o1;}});
System.out.println(nums);}
}四、Map接口
1、Map介绍
-
三类Map集合(TreeMap、HashMap、LinkedHashMap都实现了Map接口)
-
Map集合都是双列集合,每个元素包含两个数据
-
Map集合的每个元素的格式:key=value(键值对元素)
key(键)不允许重复;value(值)允许重复
键值对是一一对应的,每个键只能找到自己对应的值
-
key+value这个整体,称之为键值对或键值对对象,在Java中使用Entry对象表示
2、Map的常见API
Map是双列集合的顶层接口,它的功能是全部双列集合都可以继承使用的
| 方法 | 说明 |
|---|---|
| V put(K key,V value) | 添加元素 |
| V remove(Object kesy) | 根据键删除键值对元素 |
| void clear() | 移除所有的键值对元素 |
| boolean containesKay(Object key) | 判断集合是否包含指定的键 |
| boolean containsValue(Object value) | 判断集合是否包含指定的值 |
| boolean isEmpty() | 判断集合是否为空 |
| int size() | 集合的长度,也就是集合中键值对的个数 |
3、实现Map接口的集合
-
TreeMap:键(红黑树)键排序
-
HashMap:键(哈希表)键唯一
-
LinkedHashMap:键(哈希表+双向链表)键唯一,并保证存储顺序
双列集合的数据结构,都只针对于键有效,和值没有关系。HashMap的底层是哈希表结构的,依赖于hashCode方法和equals方法保证键值唯一。因此,如果键存储的是自定义对象,需要重写hashCode和equals方法;如果值存储自定义对象,就不需要重写hashCode和equals方法
五、Map集合的遍历方式(3种)
1、 通过键找值
| 方法 | 说明 |
|---|---|
| V get(Object key) | 根据键查找对应的值 |
| Set<K> keySet() | 获取Map集合中所有的值 |
①调用keySet方法获取所有的键(得到的是Set集合)
②遍历Set集合,获取每一个键
③遍历的过程中调用get方法,根据键找值
public class HashMapDemo1 {public static void main(String[] args) {HashMap<String,String> map = new HashMap<>();
map.put("张三","北京");map.put("李四","上海");map.put("王五","广州");
//1、获取所有的键Set<String> keySet = map.keySet();//2、遍历Set集合,获取每一个键for (String key : keySet) {//3、根据键查找对应的值String value = map.get(key);System.out.println(key+"---"+value);}}
}2、通过键值对对象获取键和值
| 方法 | 说明 |
|---|---|
| Set<Map.Entry<K,V>> entrySet() | 获取集合中所有的键值对对象 |
Map.Entry类的方法
| 方法 | 说明 |
|---|---|
| getKey() | 获取键 |
| getValue() | 获取值 |
①调用entrySet方法获取所有的键值对对象,得到Set集合
②遍历Set集合,获取每一个键值对对象
③通过键值对对象的getKey()和getValue()获取键和值
public class TreeMapDemo2 {/*键如果存储的是自定义类记得实现Comparable接口本Demo中的Student类要实现comparable接口*/public static void main(String[] args) {TreeMap<Student,String> map = new TreeMap<>();
map.put(new Student("张三",23),"北京");map.put(new Student("李四",24),"上海");map.put(new Student("王五",25),"广州");
//1、调用entrySet方法,获取所有的键值对对象Set<Map.Entry<Student, String>> entrySet = map.entrySet();//2、遍历entrySet集合获取每一个对象for (Map.Entry<Student, String> entry : entrySet) {//3、获取每一个entry对象的键和值System.out.println(entry.getKey()+entry.getValue());}}
}3、通过foreach方法遍历
调用foreach方法直接遍历map拿到键和值
public class LinkedHashMapDemo3 {public static void main(String[] args) {LinkedHashMap<Student,String> map = new LinkedHashMap<>();
map.put(new Student("张三",23),"北京");map.put(new Student("李四",24),"上海");map.put(new Student("王五",25),"广州");
//匿名内部类foreachmap.forEach(new BiConsumer<Student, String>() {@Overridepublic void accept(Student key, String value) {System.out.println(key + "----" + value);}});
//Lambda表达式foreachmap.forEach((key,value)->{System.out.println(key + "------" + value);});}
}六、Stream流
1、Stream介绍
Stream流可以Lambda表达式,简化数组和集合操作
1.1 Stream流思想
可以将对数据的一系列操作理解为获取数据的Stream流对象将其放在Stream流水线上调用Stream的方法进行一些列处理操作。,因为Stream的方法处理完返回的对象也都是Stream对象,因此可以链式编程继续调用Stream的方法,直至最后有其他无返回值的方法终结操作。
2、获取Stream流对象
2.1 集合获取Stream流对象
使用Collection接口中的默认方法
| 方法名 | 说明 |
|---|---|
| default Stream<E> stream() | 获取当前集合对象的Stream流 |
注意:如果是双列集合Map,只能间接获取。有以下三种方式
-
map.KeySet().Stream不推荐
-
map.values().Stream不推荐
-
map.EntrySet().Stream推荐
public class StreamDemo2 {public static void main(String[] args) {List<String> list = new ArrayList<String>();Collections.addAll(list,"张三丰","张无忌","张翠山","王二麻子","张良","谢广坤"); Set<String> set = new HashSet<String>();Collections.addAll(set,"张三丰","张无忌","张翠山","王二麻子","张良","谢广坤"); Map<String, Integer> map = new HashMap<String, Integer>();map.put("张三丰", 100);map.put("张无忌", 35);map.put("张翠山", 55);map.put("王二麻子", 22);map.put("张良", 30);map.put("谢广坤", 55); //list集合获取stream流对象遍历并打印list.stream().forEach(s-> System.out.println(s));//set集合获取stream流对象遍历并打印set.stream().forEach(s-> System.out.println(s));//map集合获取stream流对象遍历并打印map.entrySet().stream().forEach(s-> System.out.println(s));} }
2.2 数组获取Stream流对象
使用Arrays工具类中的静态方法Arrays.Stream(数组名)
| 方法名 | 说明 |
|---|---|
| static <T> Stream<T> stream(T[] array) | 将传入的数组封装到Stream流对象中 |
public class StreamDemo2 {public static void main(String[] args) {String[] names = {"张三","李四","王五"};//数组获取Stream流对象遍历并打印Arrays.stream(names).forEach(s-> System.out.println(s));
int[] arr = {11,22,33};Arrays.stream(arr).forEach(s-> System.out.println(s));}
}2.3 零散的数据获取Stream对象
使用Stream类中的静态方法
| 方法名 | 说明 |
|---|---|
| static <T> Stream<T> of(T...values) | 把一堆零散的数据封装到Stream流对象中 |
public class StreamDemo2 {Stream<Integer> s1 = Stream.of(1, 2, 3, 4, 5, 6);s1.forEach(s-> System.out.println(s));}
}3、中间方法
| 方法 | 说明 |
|---|---|
| Stream<T> filter(Predicate<? super T> predicate) | 用于对流中的数据进行过滤 |
| Stream<T> limit(long maxSize) | 获取前几个元素 |
| Stream<T> skip(long n) | 跳过前几个元素 |
| Stream<T> distinct() | 去除流中重复的元素依赖(依赖hashCode和equals方法) |
| static <T> Stream<T> concat(Stream a,Stream b) | 合并a和b两个流为一个流 |
注意事项:如果流对象已经被消费过,就不允许再次使用了
public class StreamDemo4 {public static void main(String[] args) {ArrayList<String> list = new ArrayList<String>();Collections.addAll(list,"林青霞","张曼玉","王祖贤","柳岩","张敏","张无忌")// 需求1:取前4个数据组成一个流Stream<String> s1 = list.stream().limit(4);// 需求2:跳过2个数据组成一个流Stream<String> s2 = list.stream().skip(2);// 需求3:合并需求1和需求2得到的流,并把结果在控制台输出/*Stream.concat(s1,s2).forEach(s -> System.out.println(s));*/// 需求4:合并需求1和需求2得到的流,并把结果在控制台输出,要求字符串元素不能重复//如果需求3的代码不注释掉,那需求4会报错。因为需求3已经消费过s1和s2这两个流了,需求4已不能再使用Stream.concat(s1,s2).distinct().forEach(s -> System.out.println(s));
System.out.println(list.stream().count());}
}4、终结操作方法
| 方法 | 说明 |
|---|---|
| void forEach(Consumer action) | 对此流的每个元素执行遍历操作 |
| long count() | 返回此流中的元素数 |
5、Stream收集操作
-
Stream流操作,不会修改数据源
-
把Stream流操作后的结果数据转回到集合
方法 说明 R collect(Collector collector) 开始收集Stream流,指定收集器 -
Collectors工具类提供了具体的收集方式
方法 说明 public static <T> Collector tolist() 把元素收集到list集合中 public static <T> Collector toSet() 把元素收集到Set集合中 public static Collector toMap(Function keyMapper,Function valueMapper) 把元素收集到Map集合中 -
收集toMap小Demo(格外注意)
public class StreamDemo5 {/*需求:保留年龄大于等于24岁的人,并将结果收集到Map集合中,姓名为键,年龄为值*/public static void main(String[] args) {ArrayList<String> list = new ArrayList<>();Collections.addAll(list,"zhangsan,23","lisi,24","wangwu,25");//根据需求创建Map来接,姓名为键所以k为String类型,年龄为值,所以v为Integer类型 Map<String,Integer> map = list.stream().filter(new Predicate<String>() {@Override//此处传入的参数s表示stream流拿到的list集合中的每一个数据,即每一个字符串public boolean test(String s) {//将拿到的每个字符串按逗号拆分为字符数组,下标0的元素为姓名,下标1的元素为年龄String[] arr = s.split(",");//由于接收到的年龄为String类型,需要转为int做范围逻辑判断int age = Integer.parseInt(arr[1]);//filter方法内部这个test方法接收布尔返回值,结果为true数据保留return age>=24;}//调toMap往集合里装,该方法有两个参数,又分别是函数式接口,写的时候要格外注意,先写逗号}).collect(Collectors.toMap(new Function<String, String>() {@Overridepublic String apply(String s) {//第一个参数位置存入k值,即姓名return s.split(",")[0];}}, new Function<String, Integer>() {@Overridepublic Integer apply(String s) {//第二个参数存入v值,即年龄return Integer.parseInt(s.split(",")[1]);}})); System.out.println(map); } }









![P9420 [蓝桥杯 2023 国 B] 子 2023 / 双子数](https://img-blog.csdnimg.cn/direct/8d0ebfbc8a9c47a0987887dc8054a573.png)