本章节主要介绍缓冲区管理器机制,从原理上介绍共享缓冲区如何管理内存页。
1、缓冲区管理器的结构
PostgreSQL缓冲区管理器由缓冲区hash表、缓冲区buffer描述符和缓冲池组成。下面依次介绍这几个结构。
1.1 缓冲区标签
typedef struct buftag
{RelFileNode rnode; /* 表文件物理ID*/ForkNumber forkNum; /* 表文件的分支,下面有详细介绍*/BlockNumber blockNum; /* 表文件的页号,从0开始 */
} BufferTag;typedef struct RelFileNode
{Oid spcNode; /* 表空间ID*/Oid dbNode; /* 数据库ID*/Oid relNode; /* 表文件的ID*/
} RelFileNode;typedef enum ForkNumber
{InvalidForkNumber = -1,MAIN_FORKNUM = 0, /* 表主分支*/FSM_FORKNUM, /* 表fsm文件*/VISIBILITYMAP_FORKNUM,/* 表VM文件*/INIT_FORKNUM /* 创建时初始状态*/
} ForkNumber;PG中每个数据文件页面都分配一个唯一的标签,即缓冲区标签。当缓冲区管理器收到请求时会用到目标页的缓冲区标签。其中rnode用于定位页面的从属关系,表示某个表空间的某个数据库下的某一页,forkNum标记页面属于哪个分支(main分支,为0;空闲空间映射,fsm,为1;可见性映射,vm,为2)。
通过宏定义INIT_BUFFERTAG对标签进行初始化:
#define INIT_BUFFERTAG(a,xx_rnode,xx_forkNum,xx_blockNum) \
( \(a).rnode = (xx_rnode), \(a).forkNum = (xx_forkNum), \(a).blockNum = (xx_blockNum) \
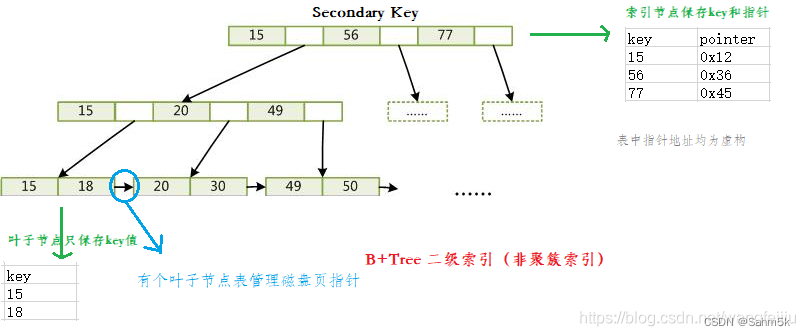
)缓冲区hash表存储着页面的buftag与描述符的buf_id之间的映射关系。缓冲区描述符层是一个由缓冲区buffer描述符组成的数组,每个描述符与缓冲池槽一一对应。缓冲池层是一个数组,每个槽都存储一个数据页,槽的索引为buf_id。他们之间的关系如下图所示:

通过buftag从缓冲区hash表里查询对应页是否已在内存,若在则返回buffer描述符数组的下标值,由此得到buffer描述符,由buffer描述符的buf_id计算出内存页。
这些层在下面进行详细介绍。
1.2 缓冲区hash表
缓冲区hash表为SharedBufHash,逻辑上分为散列函数、散列桶槽、数据项。
通过buftag利用其hash函数tag_hash计算出hash值。由hash值结合散列函数calc_bucket计算出桶槽号,从而得到数据项buftag值及buffer id值。

缓冲区hash表在启动时进行初始化:
CreateSharedMemoryAndSemaphores->InitBufferPool->StrategyInitialize->
InitBufTable(int size)
{HASHCTL info;/* BufferTag maps to Buffer */info.keysize = sizeof(BufferTag);//keyinfo.entrysize = sizeof(BufferLookupEnt);//hash桶存储的数据部分info.num_partitions = NUM_BUFFER_PARTITIONS;SharedBufHash = ShmemInitHash("Shared Buffer Lookup Table",size, size,&info,HASH_ELEM | HASH_BLOBS | HASH_PARTITION);
}Hash值数据部分为:
/* entry for buffer lookup hashtable */
typedef struct
{BufferTag key; /* Tag of a disk page */int id; /* 对应的buffer ID */
} BufferLookupEnt;缓冲区hash表通过链表的分离链接方法解决冲突,当数据项被映射到同一个桶槽时,该方法会将这些数据项保存到一个链表中。
1.3 缓冲区buffer描述符
缓冲区buffer描述符管理页面的元数据,对应页面保存在缓冲池中。缓冲区buffer描述符由结构BufferDesc定义,其定义如下:
typedef struct BufferDesc
{BufferTag tag; /*页的缓冲区标签*/int buf_id; /* 缓冲区buffer的ID,从0开始 *//* tag的状态,包括 flags, refcount and usagecount */pg_atomic_uint32 state;int wait_backend_pid; /* 等待pin该页的进程ID */int freeNext; /* 空闲链表链 */LWLock content_lock; /* 访问缓冲区内容的锁 */
} BufferDesc;其中,tag保存着页面的BufferTag;buf_id,表示缓冲区描述符,也对应缓冲池槽的buffer_id;state包含:
- refcount:保存访问相应页面的进程数,即钉数。当PG进程访问页面时,需要计数加1,访问结束时减1。当refcount值是0时表示页面未被访问,页面将取钉。
- usagecount:保存对应页加载到对应缓冲池槽后,访问次数。在页面置换驱逐时使用。
- flag状态:保存页面的状态,该状态包括:
#define BM_LOCKED (1U << 22) /* buffer header is locked */
#define BM_DIRTY (1U << 23) /* 页变脏 */
#define BM_VALID (1U << 24) /* 数据有效 */
#define BM_TAG_VALID (1U << 25) /* tag 已分配 */
#define BM_IO_IN_PROGRESS (1U << 26) /* 正在读写 */
#define BM_IO_ERROR (1U << 27) /* 之前I/O 错误*/
#define BM_JUST_DIRTIED (1U << 28) /* 写之前已变脏 */
#define BM_PIN_COUNT_WAITER (1U << 29) /* 有人等着pin页面*/
#define BM_CHECKPOINT_NEEDED (1U << 30) /* 必须在checkpoint时写入 */
#define BM_PERMANENT (1U << 31) /* 永久缓冲 */三种状态:
空:refcount和usagecount都是0,相应缓冲池槽不存储数据页
钉住:缓冲池槽存储着数据页,有进程在访问,refcount和usagecount都需要大于0
未钉住:缓冲池槽存储着数据页,没有进程在访问,refcount为0,usagecount大于0
对于这些状态标签的说明:
- 对于BM_LOCKED,比如取页头信息时都需要通过LockBufHdr将state设置成这个状态:
-
buf_state = LockBufHdr(buf); lsn = BufferGetLSN(buf);//在这个BM_LOCKED内取页头的lsn信息 UnlockBufHdr(buf, buf_state); - 当数据读取到内存后,需要将state设置成BM_VALID;成功分配了一个buffer后,buffer描述符的tag标签赋值为对应数据页的标记符BM_TAG_VALID,也就是说buffer时有效的;当正在读取数据页时,状态位设置成BM_IO_IN_PROGRESS。
对于wait_backend_pid:若进程A需要删除的元组所在的缓冲块有其他进程访问,即refcount>0时,进程A不能物理上删除元组。系统将该进程的ID记录在wait_backend_pid上,然后对缓冲块加pin并阻塞自己。当refcount为1时最后一个使用该缓冲块的进程释放缓冲区时,会向wait_backend_pid进程发送消息。
FreeNext为空闲链表的下一个节点的下标。
content_lock为buffer锁,当进程访问缓冲块时加锁,读加LW_SHARE锁,写加LW_EXCLUSIVE锁。
1.4 缓冲区buffer描述符数组
Buffer描述符数组是BufferDescriptors,为缓冲区描述符层,该数组结构为:
BufferDescPadded *BufferDescriptors;
typedef union BufferDescPadded
{BufferDesc bufferdesc;char pad[BUFFERDESC_PAD_TO_SIZE];//用于cache line大小对齐,提升效率
} BufferDescPadded;数组大小为NBuffers,即共享缓冲区块数。当PG启动时,所有缓冲区描述符的状态都为空,这些描述符通过其成员变量的freeNext构成一个freelist链表BufferStrategyControl。
这些描述符数组在共享内存中,所有进程共享,可以看到描述符数组的地址一样:
进程1:
(gdb) p BufferDescriptors
$1 = (BufferDescPadded *) 0xa615fb80
(gdb) p *BufferDescriptors
$2 = {bufferdesc = {tag = {rnode = {spcNode = 1664, dbNode = 0, relNode = 1262}, forkNum = MAIN_FORKNUM, blockNum = 0}, buf_id = 0, state = {value = 2199126016}, wait_backend_pid = 0, freeNext = -2, content_lock = {tranche = 53, state = {value = 536870912}, waiters = {head = 2147483647, tail = 2147483647}}}, pad = "\200"}
进程2:
(gdb) p BufferDescriptors
$1 = (BufferDescPadded *) 0xa615fb80
(gdb) p *BufferDescriptors
$2 = {bufferdesc = {tag = {rnode = {spcNode = 1664, dbNode = 0, relNode = 1262}, forkNum = MAIN_FORKNUM, blockNum = 0}, buf_id = 0, state = {value = 2199126016}, wait_backend_pid = 0, freeNext = -2, content_lock = {tranche = 53, state = {value = 536870912}, waiters = {head = 2147483647, tail = 2147483647}}}, pad = "\200"}1.5 缓冲池
缓冲池为共享内存中数据块数组BufferBlocks,数组大小也是NBuffers,每个block大小是BLCKSZ,默认是8KB。在函数InitBufferPool中进行初始化:
BufferBlocks = (char *)ShmemInitStruct("Buffer Blocks",NBuffers * (Size) BLCKSZ, &foundBufs);1.6 缓冲池BufferStrategyControl空闲链表
typedef struct
{/* spin锁,保护以下值*/slock_t buffer_strategy_lock;pg_atomic_uint32 nextVictimBuffer;int firstFreeBuffer;/* 空闲链表头 */int lastFreeBuffer; /* 空闲链表尾*/uint32 completePasses; /* Complete cycles of the clock sweep */pg_atomic_uint32 numBufferAllocs; /* Buffers allocated since last reset */int bgwprocno;
} BufferStrategyControl;
static BufferStrategyControl *StrategyControl = NULL;空闲链表为StrategyControl,链表头为firstFreeBuffer,链表尾为lastFreeBuffer。该链表存储描述符数组的下标,从0开始。firstFreeBuffer为-1时表示链表为空。
除了空闲链表外,还通过一个环形管理这些描述符。在进行大表扫描时使用。由环形strategy->buffers[]数组管理,该数组存储的是BufferDescriptors[]数组下标+1后的值。每次取buffer描述符时,从strategy->current值开始进行选择。如果选出后的不可用,则依次向后进行遍历,遍历到头后重新循环选择,即形成一个环。后文详述这个时钟算法。
下面在上述结构体理解基础上,介绍缓冲池的初始化。
2、缓冲池的初始化

缓冲池初始化函数为InitBufferPool,其流程如上图所示。
- 首先创建buffer描述符,该描述符数组大小为NBuffers。
- 在共享内存中申请缓冲池大,共有NBuffers个数据块,每个大小为BLCKSZ,默认8kb
- 为每个buffer创建一个IO锁
- 对于每个buffer描述符,对其进行初始化,通过freeNext构成链表
- 调用StrategyInitialize初始化hash表及空闲链表。hash表大小为NBuffers+128,然后初始化链表。
初始化完后,链表形式如下:

3、共享缓冲区申请
读取数据页的函数是ReadBuffer_common,如果数据页不在共享缓冲,则需要从磁盘读取。这时就需要共享缓冲区提供一个空闲缓冲块以保存磁盘数据页。ReadBuffer_common函数调用BufferAlloc获取指定数据页。
有三种方式获取内存中空闲缓冲块:1)从Ring buffer中;2)从free list链表中;3)根据时钟算法,从缓冲区中找到一个受害者进行替换。
下面首先介绍BufferAlloc整体流程。
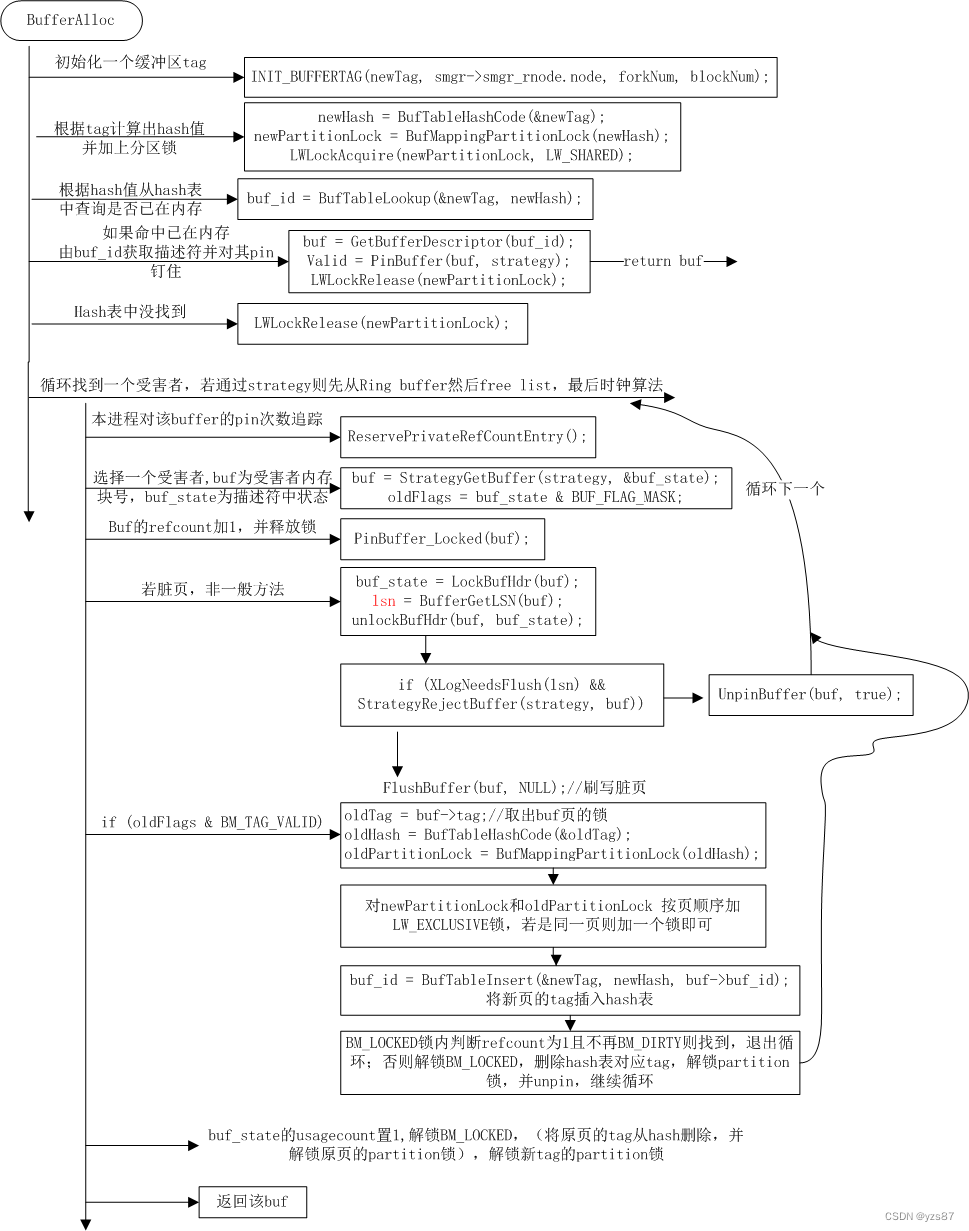
流程如下:
1)创建所需页面的buffer tag
2)使用BufTableHashCode将buffer tag newTag转换成散列桶槽newHash
3)根据newHash获取对应分区上的锁newPartitionLock,然后对这个锁加共享锁
注意:
从hash表搜索时需要对hash表加锁。因为hash表的查询、向hash表添加或者删除记 录都需要加锁。所以如果只有一个hash表的锁时,锁竞争就会非常激烈。所以,PG对 hash表进行了分区,每个分区一个锁。PG12里有NUM_BUFFER_PARTITIONS即128个分 区和分区锁。分区锁如下,根据hash值取余法,映射到对应的锁。
#define BufTableHashPartition(hashcode) \((hashcode) % NUM_BUFFER_PARTITIONS)
#define BufMappingPartitionLock(hashcode) \(&MainLWLockArray[BUFFER_MAPPING_LWLOCK_OFFSET + \BufTableHashPartition(hashcode)].lock)
/* Number of partitions of the shared buffer mapping hashtable */
#define NUM_BUFFER_PARTITIONS 1284)在hash表中查找newTag的条目,并从条目中获取buf_id
5)这个buf_id若大于1,则表示对应页已在内存,它表示描述符数组下标,由此可以获得对应页的描述符buf。调用函数PinBuffer将这个缓冲区描述符钉住,即将描述符的refcount和usage_count都增加1。钉住后,就可以将锁释放掉了。然后就将该缓冲区描述符返回,该描述符对应的数据页就可以访问了。
6)Hash表中没有找到,则需要通过循环找到一个可用的空闲内存块以存储即将读入的磁盘页。以下步骤为hash表没有找到的情况
7)首先调用ReservePrivateRefCountEntry预留一个空间以追踪页pin次数。这一部分在3.1节详述
8)通过StrategyGetBuffer函数选择一个受害者作为替换缓冲块,用于存储即将读入的磁盘页。这部分在3.2节详述。
9)选择好受害者后,对此buf pin住即refcount+1,并释放BM_LOCKED;同时还需要对进程私有的PrivateRefCountArray的refcount+1。
10)如果选好的受害者是脏页,(在buffer描述符的content_lock的LW_SHARED锁内做以下动作,没加上锁后把之前Pin进行unpin并循环找下一个受害者),若该页的WAL日志没刷写并且BAS_BULKREAD批量读的策略,则将该buf从Ring缓冲池移除。然后释放锁并unpin后循环找下一个受害者。
11)若选好的受害者是脏页,且一般方法下,将该脏页刷写下去
12)选择的受害者里有合法数据:获取该受害者的map partition锁,若需要定位的页和选择的受害者同一页,则加一个map partition锁即可,否则按页顺序进行加锁(以防死锁),将该页加入缓冲区hash表。
13)再次在BM_LOCKED内判断:受害者的refcount为1且不为脏则成功,返回该缓冲块。否则,解一系列锁并循环找下一个受害者。
3.1 追踪页pin次数
除了页面描述符中state记录页面pin次数外,还通过一个数组加一个hash表对其pin次数进行跟踪。作用:1)当前进程如果需要pin多次,那么通过这个方式可以仅pin一次;2)事务结束和退出时检查还有没有buffer还在被pin着。
数组为:PrivateRefCountArray,该数组结构如下。每次ReservedRefCountEntry为当前空闲可用的数组成员。数组大小是8。
typedef struct PrivateRefCountEntry
{Buffer buffer;//缓冲块号int32 refcount;//pin次数
} PrivateRefCountEntry;
static struct PrivateRefCountEntry PrivateRefCountArray[REFCOUNT_ARRAY_ENTRIES];
#define REFCOUNT_ARRAY_ENTRIES 8
这里数组大小8,正好64字节,一个cache line大小,对性能友好。Hash表为:PrivateRefCountHash,它的hash键是buffer id,hash条目为PrivateRefCountEntry结构。hash表初始100大小。数组和hash表都是进程私有。
数组和hash表初始调用关系:在进程初始化时调用:
BaseInit->InitBufferPoolAccess:hash_ctl.keysize = sizeof(int32);hash_ctl.entrysize = sizeof(PrivateRefCountEntry);PrivateRefCountHash = hash_create("PrivateRefCount", 100, &hash_ctl,HASH_ELEM | HASH_BLOBS);Pin一个页需要做的事:
- 先从PrivateRefCountArray[]数组中查找对应的块号,然后再从hash表PrivateRefCountHash查找
- 若找到则对PrivateRefCountEntry中refcount加1
- 1)中没有找到,ReservePrivateRefCountEntry函数确保数组有一个空闲的:若数组满,则从PrivateRefCountClock++ % REFCOUNT_ARRAY_ENTRIES将其放入hash表以腾出空间。
- 将指定的buffer id保存到PrivateRefCountEntry的buffer中
- 获取buffer页的一般方法:对buffer描述符的refcount和usagecount都加1
- 获取buffer页的strategy方法:仅对refcount加1,并确保usagecount为1。这样保证Ring buffer不会导致别人从缓冲池中替换作为受害者。
检查是否有页还在Pin的函数是CheckForBufferLeaks,从数组和hash表里依次检查。该函数被调用的地方分别为:
1)CommitTransaction->AtEOXact_Buffers->CheckForBufferLeaks
2)InitBufferPoolBackend->//进程退出on_shmem_exit(AtProcExit_Buffers, 0);->CheckForBufferLeaks3.2 StrategyGetBuffer获取一个受害着
1)若非一般方式,则先从Ring缓冲区找一个buf,由函数GetBufferFromRing完成,对于从Ring缓冲区找一个替换者,在3.3节详述。若Ring中找到则返回
2)非一般方式没有在ring缓冲区找到一个buf,或者一般方式下,从free list头StrategyControl->firstFreeBuffer取出一个缓冲块(在StrategyControl->buffer_strategy_lock锁内操作)
3)仅在buf的refcount和usagecount都为0的情况下,算找到一个空闲缓冲块(非一般方式下将该buf加入Ring缓冲区),否则放弃这个缓冲块,再接着从free list链表取
4)若free list没有找到,则通过时钟算法取一个受害者。
- 从StrategyControl->nextVictimBuffer+1开始,若循环到NBuffers,则victim = victim % NBuffers;重新从头开始
- 若取出的buf的refcount为0,但usagecount不为0,则将usagecount减去1后继续时钟算法取下一个buf
- 取出的buf的refcount为0,usagecount也变成0了,此时成功找到一个受害者并返回(非一般方式下还需添加到Ring缓冲区)
3.3 GetBufferFromRing从Ring缓冲区找一个受害者
Ring缓冲区结构:
typedef struct BufferAccessStrategyData *BufferAccessStrategy;
typedef struct BufferAccessStrategyData
{/* Overall strategy type */BufferAccessStrategyType btype;int ring_size;/*buffers[] 数组大小*/int current; /*Ring当前的slot*/bool current_was_in_ring;/*StrategyGetBuffer 获取的buf在Ring中*/Buffer buffers[FLEXIBLE_ARRAY_MEMBER];/*Ring buffer*/
}BufferAccessStrategyData;Ring缓冲区申请:
寻找空闲缓冲块非一般方式有4种:
typedef enum BufferAccessStrategyType
{BAS_NORMAL, /* 一般随机扫描,默认方式 */BAS_BULKREAD, /*批量读*/BAS_BULKWRITE, /* 批量写 (例如 COPY IN) */BAS_VACUUM /* VACUUM */
} BufferAccessStrategyType;三种方式批量读和批量写及VACUUM的Ring缓冲区大小分别是256KB、16MB、256KB。缓冲区申请如下:
GetAccessStrategy(BufferAccessStrategyType btype)
{switch (btype){case BAS_NORMAL:return NULL;case BAS_BULKREAD:ring_size = 256 * 1024 / BLCKSZ;break;case BAS_BULKWRITE:ring_size = 16 * 1024 * 1024 / BLCKSZ;break;case BAS_VACUUM:ring_size = 256 * 1024 / BLCKSZ;break;default:return NULL;}/* Make sure ring isn't an undue fraction of shared buffers */ring_size = Min(NBuffers / 8, ring_size);/* Allocate the object and initialize all elements to zeroes */strategy = (BufferAccessStrategy)palloc0(offsetof(BufferAccessStrategyData, buffers) +ring_size * sizeof(Buffer));strategy->btype = btype;strategy->ring_size = ring_size;return strategy;
}从Ring缓冲区获取一个缓冲块:
非一般方法下,开始Ring缓冲区里面是空的,随着不断访问共享缓冲区中的缓存块,并将其存入Ring缓冲区,直至放满。后续接着读取时,从Ring的current处开始取一个缓冲块作为替换。这样的好处显而易见,如果后端进程不使用Ring缓冲区情况下读取大表,则所有存储在缓冲池中的页面都可能被移除,这会导致缓存命中率降低。使用Ring缓冲区可以避免这个问题。
为什么批量读取和VACUUM过程的默认Ring缓冲区大小为256KB
顺序扫描使用256KB的Ring缓冲区,能够放入CPU的L2缓存中,从而使得操作系统缓存到共享缓冲区的页面传输率变的高效。通常更小一点也行,但Ring缓冲区需要足够大能同时容纳扫描中被钉住的所有页面。
批量写入使用Ring的场景
COPY FROM命令
CREATE TABLE AS命令
CREATE MATERIALIZED VIEW或REFRESH MATERIALIZED VIEW命令
ALTER TABLE命令
批量写入的Ring创建函数如下:
GetBulkInsertState->
bistate = (BulkInsertState) palloc(sizeof(BulkInsertStateData));bistate->strategy = GetAccessStrategy(BAS_BULKWRITE);bistate->current_buf = InvalidBuffer;4、总结
批量读、批量写和VACUUM场景下使用非一般方式,即通过Ring缓冲区获取。以这样的方式防止大量读将热数据又驱逐出共享缓冲。
非一般场景下,获取缓冲块的优先顺序:Ring缓冲区获取缓冲块-->free list获取缓冲块-->通过时钟算法顺序依次从缓冲池获取。
Ring缓冲区的方式,初始时是空的,所以以开始从free list-->时钟算法获取缓冲块,并将缓冲块加入Ring缓冲区。等它满时,就从Ring缓冲区找受害者提供缓冲块了。