# 数据清洗概念
通常情况下,大数据平台获得原始数据文件中,存在大量无效数据和缺失数据,需要再第一时间,对数据进行清洗,获得符合后续处理需求的数据内容和格式
# 需求
对手机流量原始数据,将其中的手机号为"null"和不完整的数据去除
数据格式说明

# 源数据
id 手机号 手机mac ip地址 上传 下载 HTTP状态码
1363157985066 13726230503 00-FD-07-A4-72-B8:CMCC 120.196.100.82 24 27 2481 24681 200 1363157995052 13826544101 5C-0E-8B-C7-F1-E0:CMCC 120.197.40.4 4 0 264 0 200 1363157991076 13926435656 20-10-7A-28-CC-0A:CMCC 120.196.100.99 2 4 132 1512 200 1363154400022 13926251106 5C-0E-8B-8B-B1-50:CMCC 120.197.40.4 4 0 240 0 200 1363157985066 13726230503 00-FD-07-A4-72-B8:CMCC 120.196.100.82 24 27 2481 24681 200 1363157995052 13826544101 5C-0E-8B-C7-F1-E0:CMCC 120.197.40.4 4 0 264 0 200 1363157991076 13926435656 20-10-7A-28-CC-0A:CMCC 120.196.100.99 2 4 132 1512 200 1363154400022 13926251106 5C-0E-8B-8B-B1-50:CMCC 120.197.40.4 4 0 240 0 200 1363157995052 13826544109 5C-0E-8B-C7-F1-E0:CMCC 120.197.40.4 4 0
1363157995052 null 5C-0E-8B-C7-F1-E0:CMCC 120.197.40.4 4 0 240 0 200 1363157991076 13926435659 20-10-7A-28-CC-0A:CMCC 120.196.100.99 2 4 null nullnull
# 期望结果
1363157985066 13726230503 00-FD-07-A4-72-B8:CMCC 120.196.100.82 24 27 2481 24681 200 1363157995052 13826544101 5C-0E-8B-C7-F1-E0:CMCC 120.197.40.4 4 0 264 0 200 1363157991076 13926435656 20-10-7A-28-CC-0A:CMCC 120.196.100.99 2 4 132 1512 200 1363154400022 13926251106 5C-0E-8B-8B-B1-50:CMCC 120.197.40.4 4 0 240 0 200 1363157985066 13726230503 00-FD-07-A4-72-B8:CMCC 120.196.100.82 24 27 2481 24681 200 1363157995052 13826544101 5C-0E-8B-C7-F1-E0:CMCC 120.197.40.4 4 0 264 0 200 1363157991076 13926435656 20-10-7A-28-CC-0A:CMCC 120.196.100.99 2 4 132 1512 200 1363154400022 13926251106 5C-0E-8B-8B-B1-50:CMCC 120.197.40.4 4 0 240 0 200
思路分析
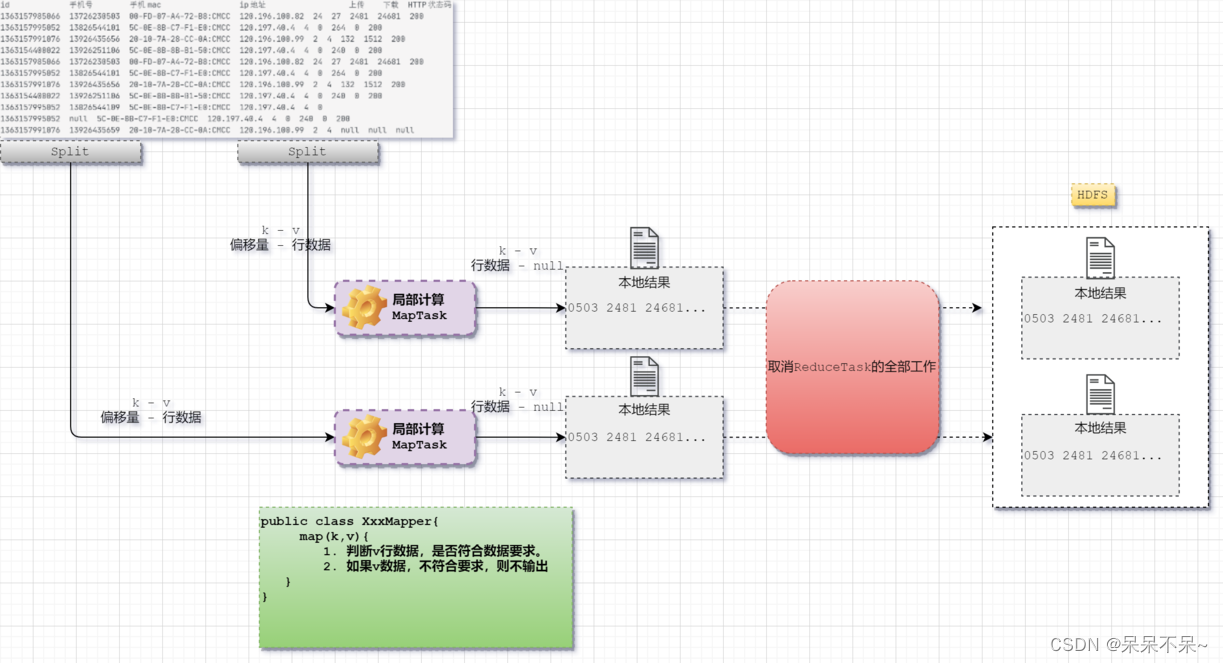
1.将数据上传到hdfs
命令:hdfs dfs -put /mapreduce /
2.Idea代码
package demo4;import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;import java.io.IOException;public class CleanDataJob {public static void main(String[] args) throws IOException, InterruptedException, ClassNotFoundException {Configuration conf = new Configuration();conf.set("fs.defaultFS","hdfs://hadoop10:8020");Job job = Job.getInstance(conf);job.setJarByClass(CleanDataJob.class);job.setInputFormatClass(TextInputFormat.class);job.setOutputFormatClass(TextOutputFormat.class);TextInputFormat.addInputPath(job,new Path("/mapreduce/demo3/dataclean.log"));TextOutputFormat.setOutputPath(job,new Path("/mapreduce/demo3/out"));job.setNumReduceTasks(0);job.setMapperClass(CleanDataMapper.class);job.setMapOutputKeyClass(Text.class);job.setMapOutputValueClass(NullWritable.class);boolean b = job.waitForCompletion(true);System.out.println(b);}static class CleanDataMapper extends Mapper<LongWritable, Text,Text, NullWritable>{@Overrideprotected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {context.getCounter("我的计数器","全部数据共计").increment(1L);String[] s = value.toString().split("\t");if(s.length != 9){return;}if("".equals(s[1]) || "null".equals(s[1])){return;}if("".equals(s[6]) || "null".equals(s[6])){return;}if("".equals(s[7]) || "null".equals(s[7])){return;}if("".equals(s[8]) || "null".equals(s[8])){return;}context.getCounter("我的计数器","数据清洗后的数据").increment(1L);context.write(value,NullWritable.get());}}
}
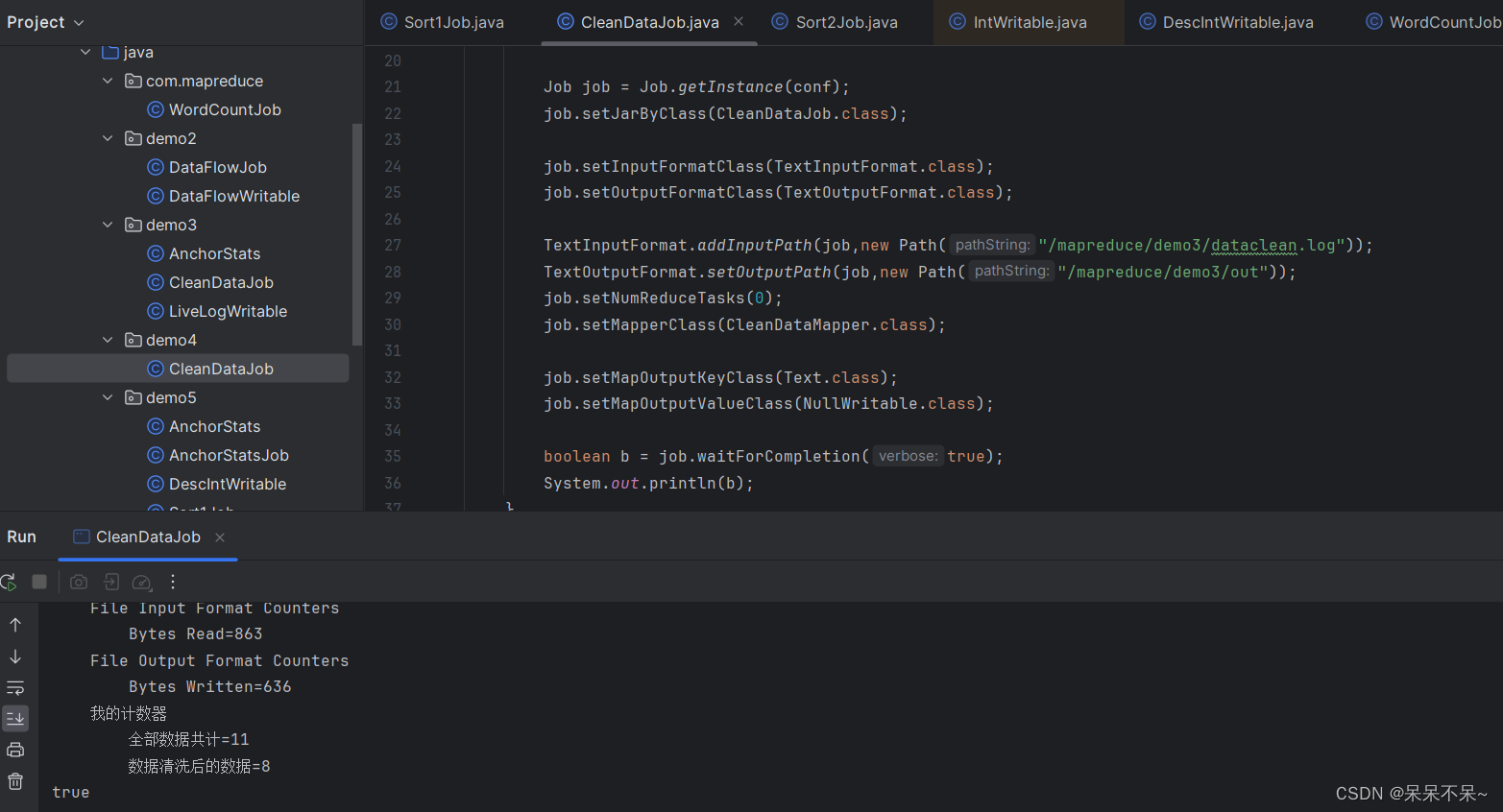
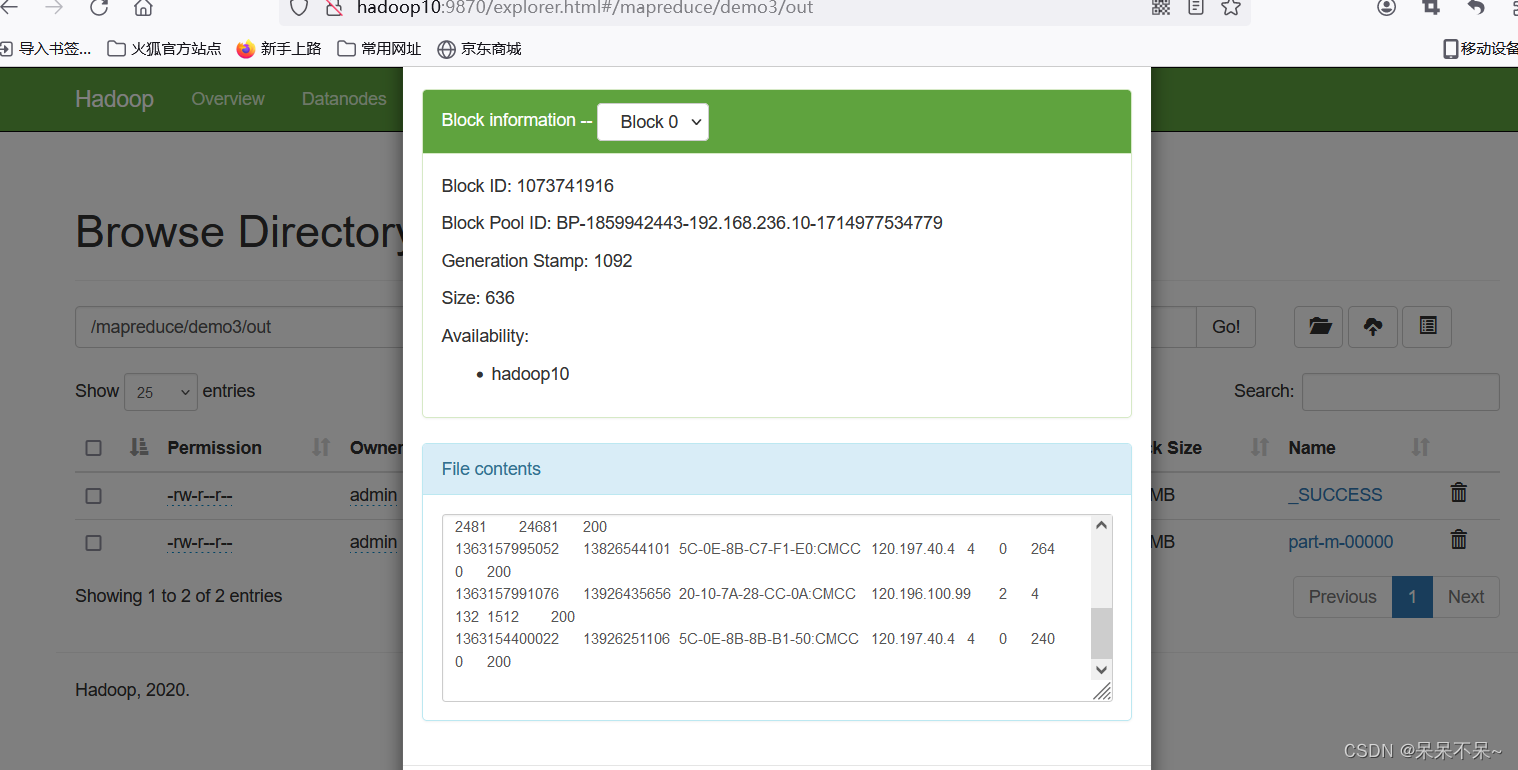
3.结果
希望今天的你,开开心心~ 喜欢我就关注我叭~