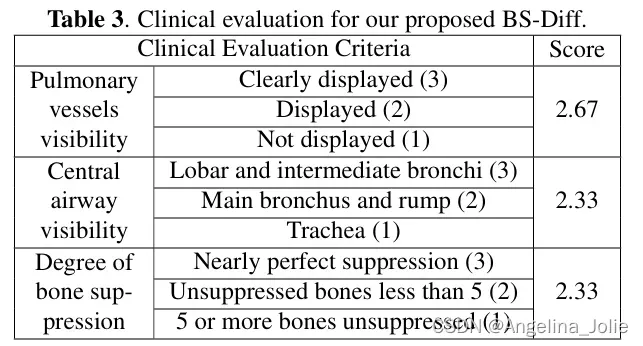
1、再一次清洗数据时,需要过滤重复数据,使用了ROW_NUMBER() 来分组给每组数据排序号
在获取每组的第一行数据
with records as(select cc.F_Id as Id,REPLACE(cc.F_CNKITitle,char(10),'1') as F_CNKITitle,REPLACE(REPLACE(cc.F_Special,'专题:',''),';','、') as F_Special,cc.F_Summary as F_Summary, REPLACE(REPLACE(cc.F_KeyValue,' ',''),';','、') as Keys, z.F_QiKan as F_QiKan,z.F_FaBiaoShiJian,ROW_NUMBER() OVER (PARTITION BY cc.F_CNKITitle,z.F_FaBiaoShiJian ORDER BY cc.F_CreatorTime DESC) AS rnfrom tzkj_CNKIContent ccinner join zhiwang z on cc.F_CnkiId =z.id where len(REPLACE(cc.F_CNKITitle ,char(10),''))>3--GROUP by F_CNKITitle,z.F_FaBiaoShiJian)select Id,F_CNKITitle,F_Special,F_Summary,Keys,F_QiKan,F_FaBiaoShiJianfrom recordswhere rn=1order by F_CNKITitle ASC OFFSET @pageSize * (@pageIndex - 1) ROWS FETCH NEXT @pageSize ROWS ONLY在这个查询中:
ROW_NUMBER()函数为每一行分配一个唯一的序号。PARTITION BY Name, IDCard确保序号是在每一组(由姓名和身份证号确定)内部重新开始的。ORDER BY (SELECT NULL)在这里是不必要的,因为我们不关心每一组内部的排序顺序,但我们需要在ORDER BY子句中放置一些东西来使查询有效,比如上面使用F_CreatorTime排序,而且也是没有提升查询速度,才使用这个排序的。WITH RankedPeople是一个公用表表达式(CTE),它允许我们为子查询结果集定义一个临时名称,并在主查询中引用它。而且使用with,发现也是比不使用with的要速度快- 主查询选择
rn = 1的行,即每一组的第一行,从而实现了去重。
今天这里主要遇到的坑是:清洗的表里的F_CNKITitle字段含有空格、换行符,所以导致内容看着一样,其实是不一样,可以点击字段内容,右键复制,粘贴到一对引号里就发现,换行了,
所以导致在使用ROW_NUMBER()分组时,把F_CNKITitle内容一样的分成两组了,引发数据库联合索引异常,如下图:
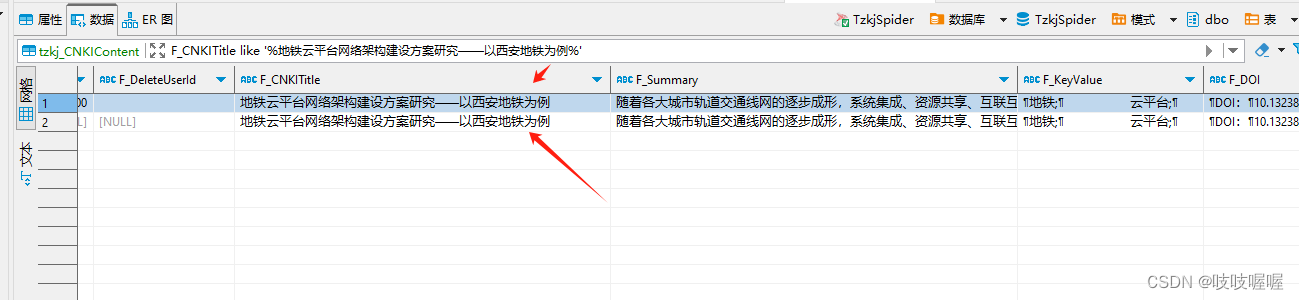
这两列中的F_CNKITitle看着是不是一样,且点击内容进入,也没有显示出空格换行啥,但是右键复制下放到引号中就会发现问题所在