多线程案例分析
- 单例模式
- 饿汉模式
- 懒汉模式
- 指令重排序
- 阻塞队列
- 生产者消费者模型
- 实现阻塞队列
单例模式
单例模式是一种设计模式。所谓“单例”,就是只有一个实例
如果某个类在一个进程中只应该创建出一个实例(或者说原则上不应该有多个),那么使用单例模式就可以对我们的代码进行更严格的校验和检查
要严格控制实例的数量是因为有时候我们需要用一个对象来管理大量数据,比如一个对象管理 10G 数据,如果不小心创建多个对象,那么占用的内存空间就会成倍增长,这就会带来很大的开销
有很多种方式来实现单例模式,本文介绍两种基础的实现方式——饿汉模式和懒汉模式
饿汉模式
public class Singleton {private static Singleton instance = new Singleton(); //这个引用就是我们期望创建出的唯一实例的引用,加 static 保证唯一性public static Singleton getInstance() { //其他类如果想使用这个类的实例,必须通过这个方法获取现成的实例return instance;}private Singleton() {} //为了防止在类外 new 一个 Singleton对象,用 private 把构造方法封装起来
}
上面的代码就称为饿汉模式,实例在类加载的时候就创建了,相当于程序一启动,实例就创建了,创建时机非常早。而“饿”字形容“非常迫切的样子”,所以就用饿汉来描述很早就创建实例这种行为
懒汉模式
这种模式创建实例的时机和饿汉模式不一样。它创建时机会更晚,只有第一次使用的时候才会创建实例
我们来看下具体如何实现:
public class SingletonLazy {private static SingletonLazy instance = null;public static SingletonLazy getInstance() {if(instance == null)instance = new SingletonLazy(); //如果是首次调用这个方法,就会创建一个实例;如果后续再次调用 getInstance,就会返回之前创建好的引用return instance;}private SingletonLazy() {} //同样是防止在类外创建实例
}
接下来我们来分析一下上述两种模式是否是线程安全的,其实也就是分析在多线程中并发调用 getInstance 是否线程安全
对于饿汉模式来说,getInstance 直接返回 instance 实例,这个操作本质上是“读”操作,多个线程读取同一个变量,肯定是线程安全的
而懒汉模式的 getInstance 涉及到读和写
那么考虑下面这个场景:
- t1 第一次调用 getInstance,在执行完 if 语句后被调度走,轮到 t2 来执行
- 那此时 t2 就会创建一个新实例,并把它的引用给到 instance,instance 就不为空了
- 当 t2 执行完轮到 t1,t1 又会 new 一个实例,这就 new 了两次实例!!!不再是单例模式

所以懒汉模式不是线程安全的,我们需要使用 synchronized 加锁来改进懒汉模式
我们需要把 if 语句和 new 实例打包成一个原子
synchronized (locker) {if (instance == null)instance = new SingletonLazy(); //若为空,则创建一个实例
}
不过这样有一个问题,就是如果一个线程已经创建好实例了,后续其他线程每次调用还要拿到锁之后再进来判断 instance 是否为空,但显然都不为空,所以就做了无用功,而且加锁解锁会导致效率非常低
所以需要再在 synchronized 外面套一个条件语句判断是否需要加锁
public static SingletonLazy getInstance() {if (instance == null) {synchronized (locker) {if (instance == null)instance = new SingletonLazy();}}return instance;
}
这里巧合的是两个 if 的条件是一样的,不过它们的目的不同。既保证了线程安全,又保证执行效率,这样的锁称为双重校验锁
在多线程中,上面这样的代码是很有意义的,看起来是两个一样的条件,但实际上这两个条件的结果可能是相反的
不过尽管如此,上面的代码还是有一些问题,就是指令重排序引起的线程安全问题
指令重排序
这也是编译器的一种优化方式,编译器会在保证逻辑不变的前提下,调整原有代码的执行顺序,提高程序效率
instance = new SingletonLazy();
上面这行代码,其实可以拆分为三个大的步骤
- 申请一段内存空间
- 在内存中调用构造方法,创建出实例
- 把这个内存地址赋值给 instance
正常情况下是按照 1 2 3 的顺序执行的,但是编译器可能会优化为 1 3 2 的顺序
先执行 1 再执行 3 的话,instance 虽然不为 null,但是它指向的是尚未初始化的对象
这两种顺序在单线程下都是可以的,但是多线程下就有问题。接下来我们按照 1 3 2 的顺序演示一下

我们把 new 拆分成 3 步,如果 t1 执行完 3 后被调度走,轮到 t2 执行,那么会直接跳转到 return,但此时 instance 为空, 这就会导致 t2 使用的是一个未初始化的对象,这就可能会出现错误!(因为你可能在构造方法中给实例赋值)
要解决指令重排序问题,还是得用到我们之前提到的 volatile
只需在 instance 前面加上它就 ok 了
private volatile static SingletonLazy instance = null;
总结一下 volatile 的功能
① 保证内存可见性,让每次访问变量都必须重新读取内存,而非使用寄存器中缓存的值
② 禁止指令重排序,被 volatile 修饰的变量,它读写操作相关的指令不能被重排序
下面摆出整个代码,注意思考注释中的问题(面试常考)
public class SingletonLazy {private volatile static SingletonLazy instance = null; //3.这里加 volatile 有什么用private static Object locker = new Object();public static SingletonLazy getInstance() {if (instance == null) { //2.这里为啥要判断 instance 是否为空synchronized (locker) { //1.这里为啥要加锁if (instance == null)instance = new SingletonLazy();}}return instance;}private SingletonLazy() {}
}
阻塞队列
阻塞队列是在普通队列的基础上进行了拓展。它有以下两个特点:
- 线程安全
- 具有阻塞特性
入队列时,如果队列已经满了,那此时入队列操作就会阻塞,一直阻塞到队列不满的时候(其他线程出队列元素)
出队列时,如果队列为空,那么出队列操作也会阻塞,一直阻塞到队列不为空(其他线程入队列元素)
生产者消费者模型
基于阻塞队列,可以实现生产者消费者模型
以生活中包饺子为例,有一个人负责擀饺子皮,另一个人包饺子
擀饺皮的人称为生产者,因为他擀完一个饺皮后饺子皮数目+1;与之相对,包饺子的人就是消费者
假设擀饺皮擀得很快,那么包饺子的人就会跟不上,这就会导致桌上的饺皮越来越多,直到满了,此时生产饺皮的人就要停下来等一会儿,等饺子皮少一些之后再继续生产
同理,如果包饺子的人包得很快,就会导致桌上没有饺皮了,那么他就得等擀出一些饺子皮后再包饺子
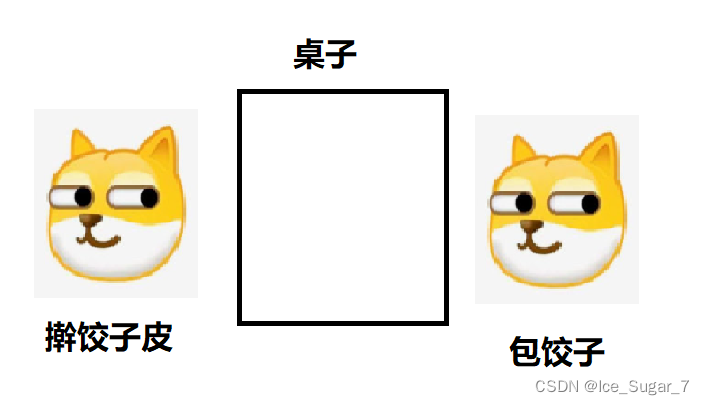
在上面的例子中,我们会发现桌子起到传递饺子皮的作用,它就相当于阻塞队列
生产者消费者模型在实际开发中是非常有意义的
- 引入这个模型可以更好地做到解耦合
所谓解耦合就是降低代码的耦合程度
在实际开发中,服务器的所有功能不只由一个服务器完成,而是每个服务器负责其中一部分功能,然后通过服务器之间的网络通信完成整个功能
以电商平台为例,服务器之间是这样处理请求的:
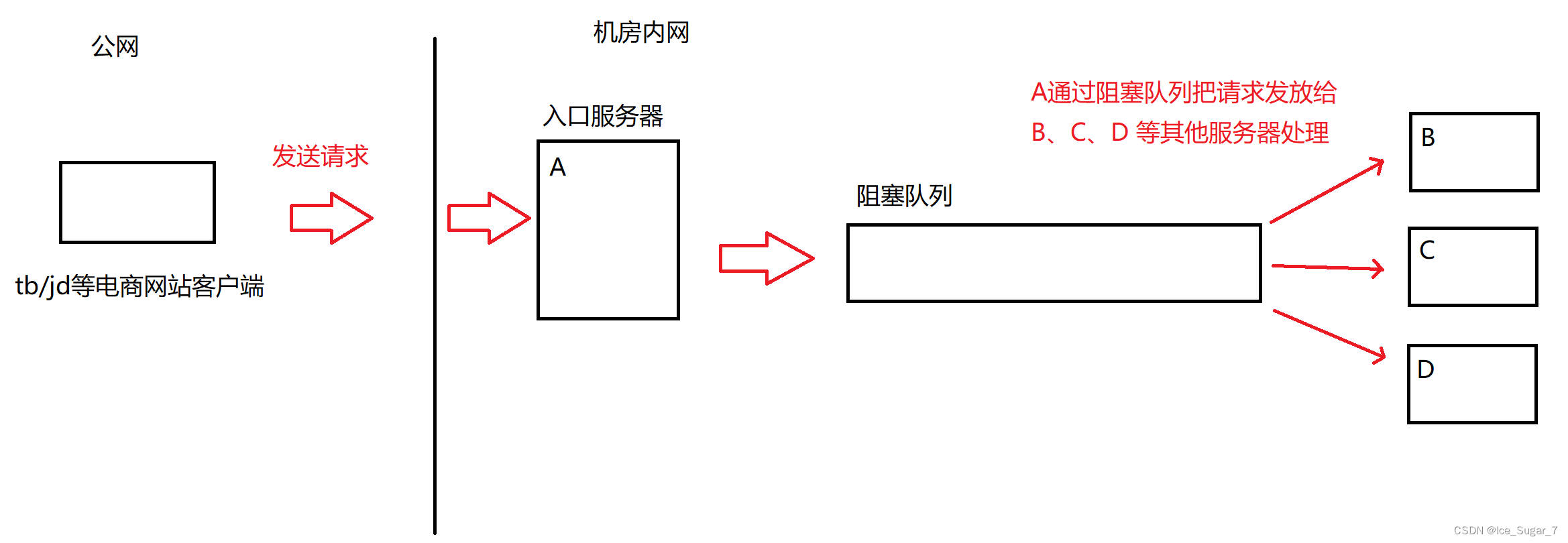
A 和处理请求的服务器 B、C、D 之间不是直接进行交互,而是通过队列传递请求。这样,如果 B、C 挂了,对 A 的影响其实是微乎其微的,而且如果后续再添加其他服务器,A的代码也几乎不用变化
- 削峰填谷
所谓“削峰”,就是当外界的请求突然大量增加的时候,让阻塞队列来存放这些请求,B、C 仍然按照之前的速度来取请求,这样就保证 B 和 C 不会因为请求骤增然后挂了
(一般 B 和 C 这些服务器的抗压能力比 A 的弱很多,不小心就会寄了)
而“填谷”则是指在外界请求突然减少的时候,由于阻塞队列之前已经存了一些请求,所以它仍然可以按照原先的速率发放请求给 B、C 等服务器
这两个场景都说明阻塞队列具有缓冲作用
实现阻塞队列
分为三步来实现
- 先实现一个普通队列
- 再考虑线程安全问题
- 再加上阻塞功能。有阻塞就有 notify,因入队列而阻塞的线程,当队列不满的时候就应该解除阻塞,所以要在出队列操作中加入 notify;同理入队列操作中也要有 notify
队列的话可以用一个数组来实现,用两个“指针”分别指向队首和队尾元素,同时用一个变量 size 标记当前队列有多少元素
public class MyBlockingQueue {String[] queue;int head,tail; //队首和队尾int size; //当前队列元素个数Object locker = new Object();MyBlockingQueue(int capacity) {queue = new String[capacity];}public void put(String str) throws InterruptedException {synchronized (locker) {if (size >= queue.length) { //注意“判断队列是否满了”这一步也要加锁(即放在 synchronized 里面)locker.wait();}queue[tail++] = str;if (tail >= queue.length) tail = 0; //也可以不用判断,直接写成 tail %= queue.length; 不过这样的效率会低一些size++; //不要忘了让 size++locker.notify(); //唤醒一个“因出队列时队列为空而阻塞”的线程}}public String take() throws InterruptedException { //出队并返回该元素String ret = null;synchronized (locker) {if (size == 0) {locker.wait();}ret = queue[head];head++;if (head == queue.length) head = 0;size--;locker.notify(); //唤醒一个“因入队列时队列满了而阻塞”的线程}return ret;}
}
不过上面代码出入队列的操作还是有问题
拿入队列来说,如果队列已经满了,两个线程同时执行 put,那么它们都会阻塞。当出队列唤醒其中一个线程后,它继续执行 put,执行到最后会 notify,因为锁对象只有一个,所以此时另外一个线程就有可能因此被唤醒。而队列已经满了,再 put 一次就会出问题了
(同理出队列也是这样分析的)
解决办法就是把判断队列为空/为满的 if 语句改成 while 循环,因为 if 语句只会判断一次,而 while 循环可以多次判断
在上面的情况中,当另一个线程被唤醒之后,会先判断队列是否满了,显然此时已经满了,那么它就会再次进入阻塞状态
while (size >= queue.length) {locker.wait();
}while (size == 0) {locker.wait();
}
值得一提的是,Java 标准库中也推荐 wait 和 while 配套使用