声明 本文章中所有内容仅供学习交流使用,不用于其他任何目的,不提供完整代码,抓包内容、敏感网址、数据接口等均已做脱敏处理,严禁用于商业用途和非法用途,否则由此产生的一切后果均与作者无关!本文章未经许可禁止转载,禁止任何修改后二次传播,擅自使用本文讲解的技术而导致的任何意外,作者均不负责,若有侵权,请在CSDN 私信 联系作者立即删除!
关于DrissionPage:
官方文档地址:DrissionPage官网
github地址:GitHub - g1879/DrissionPage: 基于python的网页自动化工具。既能控制浏览器,也能收发数据包。可兼顾浏览器自动化的便利性和requests的高效率。功能强大,内置无数人性化设计和便捷功能。语法简洁而优雅,代码量少。
gitee地址:DrissionPage: 基于python的网页自动化工具。既能控制浏览器,也能收发数据包。可兼顾浏览器自动化的便利性和requests的高效率。功能强大,内置无数人性化设计和便捷功能。语法简洁而优雅,代码量少。 (gitee.com)
- 使用DrissionPage可以减少对于一些特定网站的逆向。
- 关于DrissionPage的特性:💥 4.0 功能介绍 | DrissionPage官网
- 关于DrissionPage的使用文档:🛸 概述 | DrissionPage官网
- 反爬技术层出不断,自动化也是一种反反爬手段,虽然还有反反反爬
一. 概述
- DrissionPage 是一个基于 python 的网页自动化工具。
- 它既能控制浏览器,也能收发数据包,还能把两者合而为一。
- 可兼顾浏览器自动化的便利性和 requests 的高效率。
- 它功能强大,内置无数人性化设计和便捷功能。
- 它的语法简洁而优雅,代码量少,对新手友好。
二. 安装 DrissionPage
安装:pip install DrissionPage
如果你已经安装了DrissionPage可以升级为最新稳定版:pip install DrissionPage --upgrade
三.初体验
注:本次初体验不会太过具体的使用DrissionPage提供的api,本章需要了解的是DrissionPage 三种使用模式。
- ChromiumPage模式:用于控制浏览器访问网页
- SessionPage模式:用于以收发数据包的形式访问网页
- WebPage模式:支持以上两种模式,控制浏览器和收发数据包
ChromiumPage模式打开浏览器访问百度:
from DrissionPage import ChromiumPage# 创建对象
page = ChromiumPage()
# 访问网页
page.get("https://www.baidu.com")

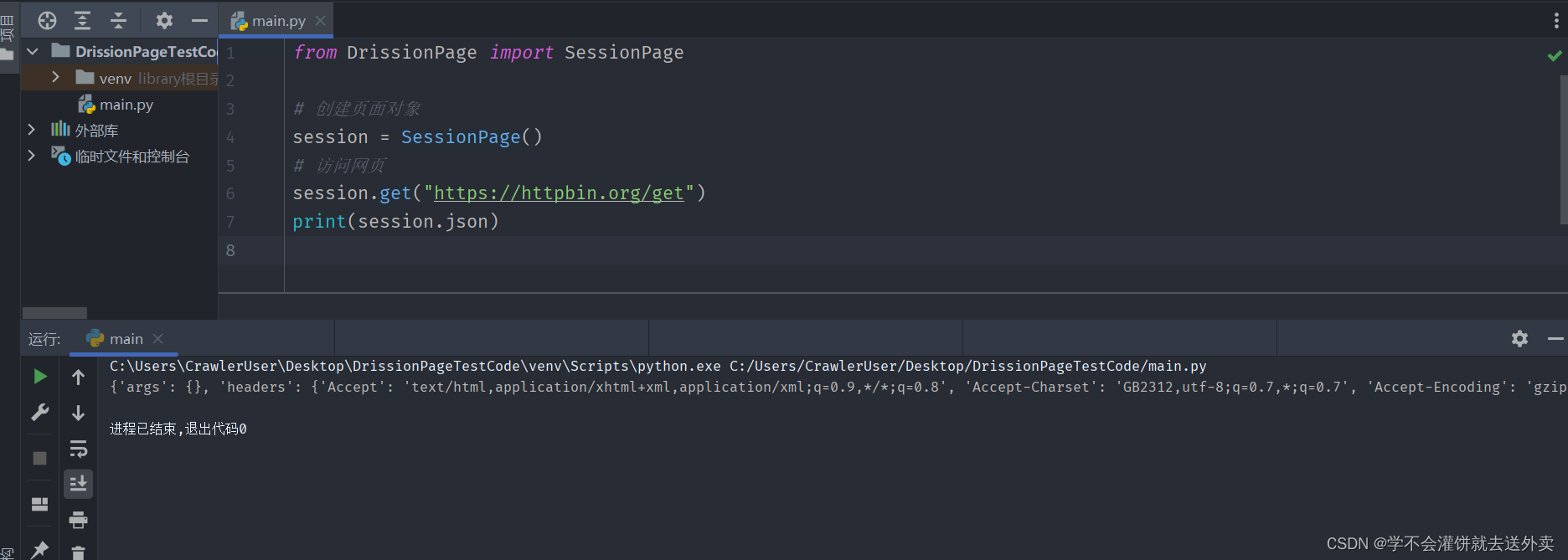
SessionPage模式:(可以理解为requests)
from DrissionPage import SessionPage# 创建页面对象
session = SessionPage()
# 访问网页
session.get("https://httpbin.org/get")
print(session.json)
WebPage模式:
- WebPage中有两种模式:
- d参数为ChromiumPage模式,默认
- s参数为SessionPage模式
from DrissionPage import WebPage# 创建WebPage,默认为 ChromiumPage模式
# page = WebPage()
# page.get("https://www.baidu.com")# 创建webpage,指定为SessionPage模式
session = WebPage("s")
session.get("https://httpbin.org/get")
print(session.json)
四. ChromePage的使用
关于ChromePage的使用建议直接是看官方文档:🚤 概述 | DrissionPage官网
下载滑块背景图
import re
import requests
from loguru import logger
from DrissionPage import ChromiumPageuserPhone = "手机号"page = ChromiumPage()
page.get('网站就不放了,看代码就行')
phone = page.ele('@name=phone')
if phone is None:raise Exception("找不到name属性为phone的参数")
phone.input(userPhone)click_sms = page.ele('@class=get-code')
if phone is None:raise Exception("找不到class属性为get-code的参数")
click_sms.click()# 等待网页进入加载状态
page.wait.load_start()try:# 获取iframe对象iframe = page.get_frame("#tcaptcha_iframe_dy")slideBg = iframe.ele("#slideBgWrap").ele('@class=tc-bg-img unselectable')slider_bg_url = re.search(r'url\("(.+)"', slideBg.html).group(1).replace("amp;", '')slider_bg_content = requests.get(slider_bg_url).contentwith open("bg.jpg", "wb") as f:f.write(slider_bg_content)logger.debug("下载完成咯")
except Exception as e:logger.error(f"未知错误: {e}")
拦截滑块数据包
from DrissionPage import ChromiumPagepage = ChromiumPage()
page.set.load_mode.none() # 设置加载模式为none
# 监听接口为cap_union_prehandle数据包
page.listen.start('dHVyaW5nLmNhcHRjaGEucWNsb3VkLmNvbS9jYXBfdW5pb25fcHJlaGFuZGxl')
page.get("aHR0cHM6Ly9jbG91ZC50ZW5jZW50LmNvbS9wcm9kdWN0L2NhcHRjaGE=")# 点击 "立即体验" 触发滑块,加载界面从而得到 cap_union_prehandle 接口的数据包
captcha_click = page.ele('#captcha_click')
if captcha_click is None:raise Exception("没找到id属性值为captcha_click")
captcha_click.click()# 等待数据包
packet = page.listen.wait()
# 打印数据包内容
print(packet.response.body)# 拿到数据包后强制当前页面加载
page.stop_loading()过5s盾
from DrissionPage import ChromiumPagepage = ChromiumPage()
page.get('https://www.emload.com/v2/')五. SessionPage的使用
DrissionPage中的SessionPage可以理解为requests和beautifulsoup的组合,用起来也可以方便,这里就不做文章。可以直接看官方文档
- 关于SessionPage的使用建议直接是看官方文档:🚄 概述 | DrissionPage官网
六.WebPage的使用
WebPage就是SessionPage和ChromePage的合体,可以边看文档边使用。
- WebPage官方文档:🛸 概述 | DrissionPage官网