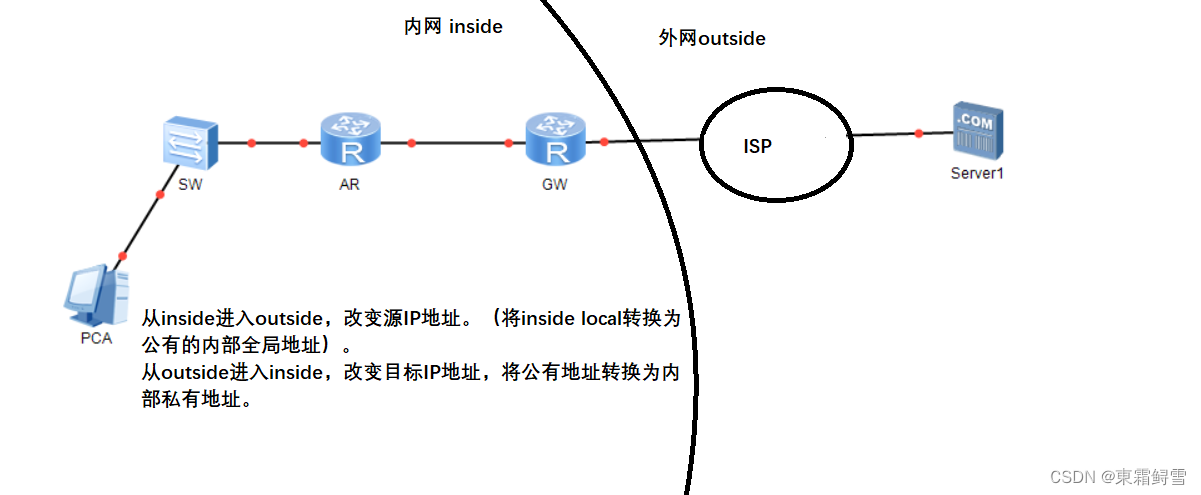
一、数据集
1.数据说明
-
fixed acidity 固定酸度
-
volatile acidity 挥发性酸度
-
pH 酸碱值
-
alcohol 酒精度数
-
quality 品质得分
2.部分数据展示
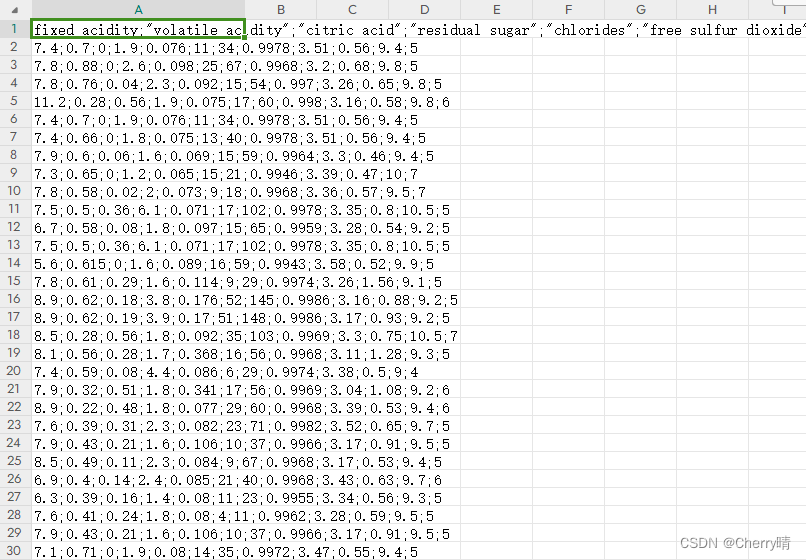
- 若需要全部数据,请私信作者,谢谢
二、导入数据——使用genfromtxt函数来读取文件
(1)genfromtxt函数详解
- 官网介绍:numpy.genfromtxt — NumPy v1.26 Manual
- genfromtxt(fname, dtype=<class 'float'>, comments='#', delimiter=None, skip_header=0, skip_footer=0, converters=None, missing_values=None, filling_values=None, usecols=None, names=None,...)
(1)fname:要读取的文件、文件名、列表或生成器;
(2)dtype【可选】:结果数组的数据类型。如果为“无”,则数据类型将分别由每列的内容确定;
(3)comments【可选】:str(字符串),用于指示注释开始的字符。注释后一行中出现的所有字符都将被丢弃;
(4)delimiter【可选】:str、int(整型) or sequence(序列),用于分隔值的字符串。默认情况下,任何连续的空格都充当分隔符。还可以提供整数或整数序列作为每个字段的宽度。
(5)skip_header【可选】:int,在文件开头要跳过的行数;
(6)skip_footer【可选】:int,文件末尾要跳过的行数;
(7)converters【可选】:variable(变量),将列数据转换为值的函数集。转换器还可用于为缺失数据提供默认值:converters = {3: lambda s: float(s or 0)}
(8)missing_values【可选】:variable,与缺失数据相对应的字符串集;
(9) filling_values【可选】:数据丢失时用作默认值的一组值;
(10)usecols【可选】:sequence,要读取哪些列,0 为第一列。例如, 将提取第 2、5 和 6 列。usecols = (1, 4, 5)
(11)names【可选】:True、str、sequence,默认值为None,如果names为True,则从第一个skip_header行之后的第一行读取字段名称。该行前面可以选择添加注释分隔符。如果名称是逗号分隔名称的序列或单字符串,则这些名称将用于定义结构化数据类型中的字段名称。如果名称为 None,则将使用 dtype 字段的名称(如果有)。
(2)读取文件数据
方法一:
# 1.导入numpy库,命名为numoy
import numpy as np # 2.使用genformtxt函数来读取文件,通过观察发现数据以分号(;)作为分割
wines1 = np.genfromtxt(r"D:/数据分析与可视化/实验/实验一——葡萄酒品质数据基础分析/winequality-red.csv",delimiter=";") # 3.查看数据
wines1
得到的结果如下图2-1所示:

- 问题:从上图的结果会发现,第一行的数据为nan,这是缺失值的意思,造成这种原因是因为数据第一行为各变量名,是字符串格式,而genfromtxt默认导入的数据格式为浮点型,故会被读成缺失值。
- 解决方法:为了防止缺失值的产生,可以调整参数skip_header为1,在读取时跳过第一行。
# 4.skip_header 用于设置数据加载时跳过文件头部的字符行数
wines1 = np.genfromtxt(r"D:/数据分析与可视化/实验/实验一——葡萄酒品质数据基础分析/winequality-red.csv",delimiter=";",skip_header=1) # 5.查看数据
wines1得到的结果如下图2-2所示:

方法二:
- 问题: 从上图2-1、2-2可发现,各变量名的数据均不显示
- 解决办法:设定names为True来解决
# 1.names关键字设置为True
wines2 = np.genfromtxt(r"D:/数据分析与可视化/实验/实验一——葡萄酒品质数据基础分析/winequality-red.csv",delimiter=";",names = True)# 2.查看数据
wines2
得到的结果如下图2-3所示:

- 注意:names参数的默认值为None。若为关键字赋予任何其他值,新名称将覆盖已使用dtype参数定义的字段名称
# 3.赋予参数names其他值
names = ['a','b','c','d','e','f','g','h','i','l','j','k']# 4.再次导入数据,查看变化
wines2 = np.genfromtxt(r"D:/数据分析与可视化/实验/实验一——葡萄酒品质数据基础分析/winequality-red.csv",delimiter=";",names = names)# 5.查看数据
wines2得到的结果如下图2-4所示:

- 从上图可见, 不仅修改了首行读取的列名,还默认了各列的数据类型都是浮点型'f8'
- 但两种方法读入的数据相同,但是在维度上却不相同,使用shape方法查看两种方法读入的数据的维度
# 第一种方法读入的数据的维度
print("第一份数据的维度",wines1.shape)# 第二种方法读入的数据的维度
print("第二份数据的维度",wines2.shape)得到的结果如下图2-5所示:

- 从上图可见: 通过第一种方法读入的数据是一个二维数组,而通过第二种方法读入的数据是一个一维数组
- 使用dtype方法查看两份数据的数据类型
# 通过dtype查看各这两个数组的数据类型
wines1.dtype 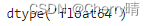
wines2.dtype 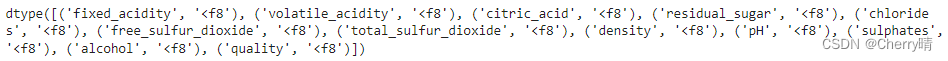
三、数据选取
1.使用索引选取数据
| 索引 | -5 | -4 | -3 | -2 | -1 | ||
| 0 | 1 | 2 | 3 | 4 | |||
| 0 | -2 | a | b | c | d | e | |
| 1 | -1 | f | g | h | i | j | |
- 若想获取字母c,那么使用的列索引为2或者是-3,行索引为0或者是-2
# 1. 导入numpy库
import numpy as np# 2. 使用numpy创建二维数组
data = np.array([['a','b','c','d','e'],['f','g','h','i','j'],
])# 3.列索引 2 or -3 ,行索引 0 or -2
print("列索引为2:",data[0,2],data[-2,2])print("列索引为-3:",data[0,-3],data[-2,-3])得到的结果如下图3-1所示:
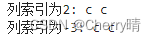
- 对于红酒品质的数据,若想获取第三种红葡萄酒的品质得分,即第三行第十二列的数据,对应的行索引为2,列索引为11
# 1.通过切片的方式来得到第三种红葡萄酒的品质得分
wines1[2,11] # 2.得到的结果
5.02.使用切片选取数据
-
如果我们想要从第四列中选择前三项,我们可以使用冒号(:)来完成。
-
冒号表示我们要从起始索引中选择所有元素,但不包括结束索引。
-
前括后不括——>(start(开始):end(结束):step(步长))
(1)通过切片的方式来得到葡萄酒的第四列中的前三项
# 1.通过切片的方式来得到葡萄酒的第四列中的前三项
wines1[0:3,3]# 2.得到的结果
array([1.9, 2.6, 2.3])# 3.若从第一位开始取数据,则0可以省略
wines1[:3,3]# 4.得到的结果
array([1.9, 2.6, 2.3])(2)通过切片的方式来得到葡萄酒的第四列中的全部数据
- 当不指定开始或结束索引,只用冒号制定时,将选择所有数据。
# 1. 通过切片的方式来得到葡萄酒的第四列中的全部数据
wines1[:,3] # 2.得到的结果为
array([1.9, 2.6, 2.3, ..., 2.3, 2. , 3.6])# 3.同理,提取第一种红葡萄酒的所有数据,即第一行整行数据
wines1[0,:]# 4.得到的结果为
array([ 7.4 , 0.7 , 0. , 1.9 , 0.076 , 11. , 34. ,0.9978, 3.51 , 0.56 , 9.4 , 5. ])
注意:本文中数据以及内容若有侵权,请第一时间联系删除。
本文是作者个人学习后的总结,未经作者授权,禁止转载,谢谢配合。







![[已解决]oneforAll ImportError: cannot import name ‘sre_parse‘ from ‘re‘](https://img-blog.csdnimg.cn/2e9b176a4d8640cf95857602c4aa85e5.png)