目录
介绍
什么是TTS
安装Miniconda
框架功能
测试通过的环境
开始
1. 安装好miniconda
2. 进入下载的GPT-SoVITS目录
3. 创建虚拟环境并执行脚本
4. 执行过程中可能会出错
5. 下载预训练模型
6. 训练过程中可能会报错
7. 使用过程中可能出错
8.以下是使用全过程
政安晨的个人主页:政安晨
欢迎 👍点赞✍评论⭐收藏
收录专栏: 零基础玩转各类开源AI项目
希望政安晨的博客能够对您有所裨益,如有不足之处,欢迎在评论区提出指正!
介绍
这是一款开源的AI音色克隆框架,目前只有TTS(文字转语音)功能,将来会更新变声功能。现在介绍如何搭建部署。
GPT-SoVITS的正确缩写应该是GSV,请不要用sovits来简称它,这会让人把它和So-VITS-SVC搞混,两者并没有什么关系
项目地址:GitHub - RVC-Boss/GPT-SoVITS: 1 min voice data can also be used to train a good TTS model! (few shot voice cloning)
什么是TTS
TTS(Text-To-Speech)这是一种文字转语音的语音合成。
类似的还有SVC(歌声转换)、SVS(歌声合成)等。目前GPT-SoVITS只有TTS功能,也就是不能唱歌。
GPT-SoVITS实现了:
—— 由参考音频的情感、音色、语速控制合成音频的情感、音色、语速
—— 可以少量语音微调训练,也可不训练直接推理
—— 可以跨语种生成,即参考音频(训练集)和推理文本的语种为不同语种
安装Miniconda
这款开源音频克隆生成AI框架是基于conda的,在ubuntu系统中需要安装miniconda后再使用。
框架功能
零样本文本到语音(TTS): 输入 5 秒的声音样本,即刻体验文本到语音转换。
少样本 TTS: 仅需 1 分钟的训练数据即可微调模型,提升声音相似度和真实感。
跨语言支持: 支持与训练数据集不同语言的推理,目前支持英语、日语和中文。
WebUI 工具: 集成工具包括声音伴奏分离、自动训练集分割、中文自动语音识别(ASR)和文本标注,协助初学者创建训练数据集和 GPT/SoVITS 模型。
测试通过的环境
- Python 3.9,PyTorch 2.0.1,CUDA 11
- Python 3.10.13,PyTorch 2.1.2,CUDA 12.3
- Python 3.9,Pytorch 2.2.2,macOS 14.4.1(Apple 芯片)
- Python 3.9,PyTorch 2.2.2,CPU 设备
注: numba==0.56.4 需要 python<3.11
笔者政安晨在Ubuntu系统、128G内存、12核CPU的PC机上,用CPU跑起来使用,亲测可行。
(注:显卡是AMD的,2G显存,没啥用)
开始
1. 安装好miniconda
后在工作目录下将软件源码下载下来:
git clone git@github.com:RVC-Boss/GPT-SoVITS.git2. 进入下载的GPT-SoVITS目录
cd GPT-SoVITS3. 创建虚拟环境并执行脚本
conda create -n GPTSoVits python=3.9
conda activate GPTSoVits
bash install.sh4. 执行过程中可能会出错
注意网络情况。
5. 下载预训练模型
安装成功后,下载预训练模型
从 GPT-SoVITS Models 下载预训练模型,并将它们放置在 GPT_SoVITS\pretrained_models 中。
对于 UVR5(人声/伴奏分离和混响移除,附加),从 UVR5 Weights 下载模型,并将它们放置在 tools/uvr5/uvr5_weights 中。
中国地区用户可以进入以下链接并点击“下载副本”下载以上两个模型:
-
GPT-SoVITS Models
-
UVR5 Weights
对于中文自动语音识别(附加),从 Damo ASR Model, Damo VAD Model, 和 Damo Punc Model 下载模型,并将它们放置在 tools/asr/models 中。
对于英语与日语自动语音识别(附加),从 Faster Whisper Large V3 下载模型,并将它们放置在 tools/asr/models 中。 此外,其他模型可能具有类似效果,但占用更小的磁盘空间。
6. 训练过程中可能会报错
发现nltk报错时,去它的github中下载package里面的tokenkey的东西,解压后连同文件夹一起拷贝到出错里展示的搜索文件夹的目录中,但要注意网络情况。
7. 使用过程中可能出错
解决方法:多尝试几次,笔者就是这样做的。
8.以下是使用全过程
数据集处理
请认真准备数据集!以免后面出现各种报错,和炼出不理想的模型!好的数据集是炼出好的模型的基础!
3.1:使用UVR5处理原音频(如果原音频足够干净可以跳过这步,比如游戏中提取的干声)
3.1.1:方法1:用自带的UVR5处理音频
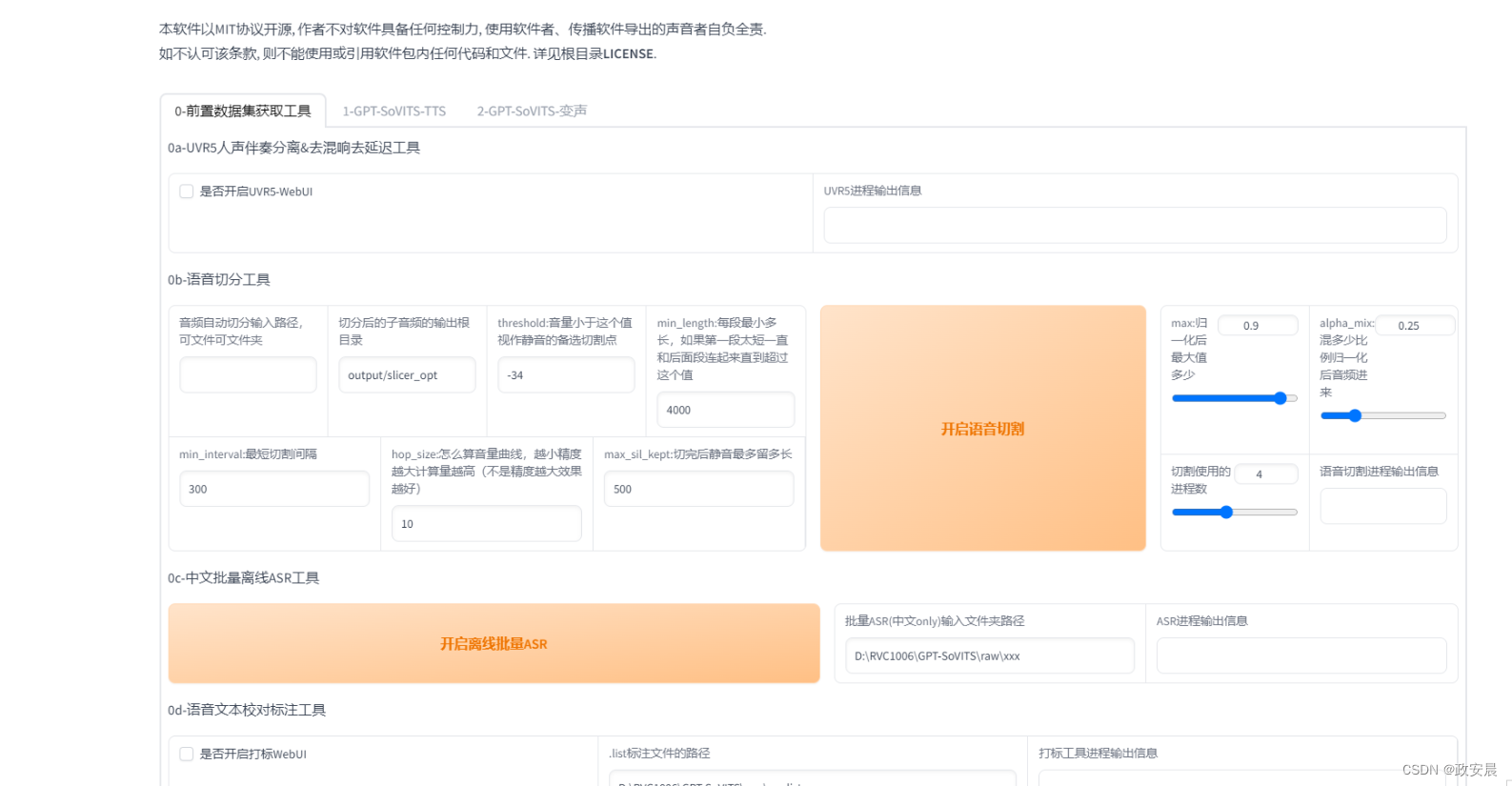
点击开启UVR5-WebUI稍加等待就会自动弹出图二的网页,如果没有弹出复制http://0.0.0.0:9873到浏览器打开


首先输入音频文件夹路径或者直接选择文件(2选1)
文件夹上面那个地址框就是文件夹路径

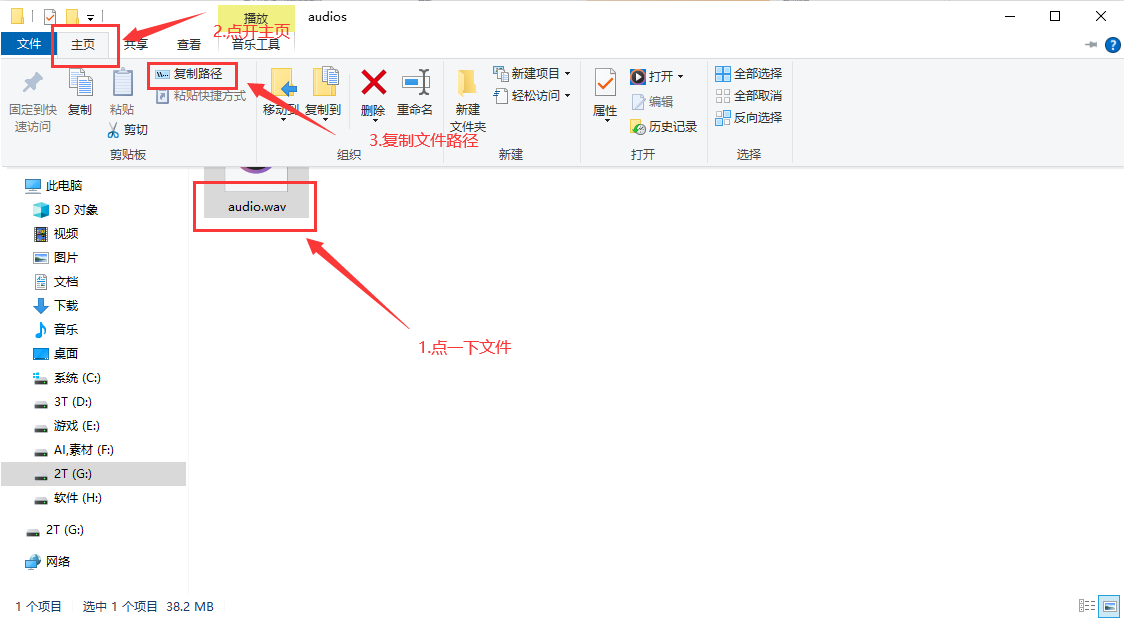
如果要复制文件路径就是这样↓
先用HP2模型处理一遍(提取人声),然后将输出的干声音频再用onnx_dereverb最后用DeEcho-Aggressive(去混响),输出格式选wav。输出的文件默认在GPT-SoVITS-beta\GPT-SoVITS-beta\output\uvr5_opt这个文件夹下,建议不要改输出路径,到时候找不到文件谁也帮不了你。处理完的音频(vocal)的是人声,(instrument)是伴奏,(No Reverb)的没混响的,(Reverb)的是混响。(vocal)(No Reverb)才是要用的文件,其他都可以删除。结束后记得到WebUI关闭UVR5节省显存。
如果没有成功输出,报错了。那么推荐使用下面一种方法——UVR5客户端。(✅可能兼容性有问题,但是效果是和UVR5对齐的,不要瞎黑内置工具效果有问题)
报错原因
报错原因一般是音频太短了,导致音频缓冲区爆了。也有一些是因为显卡性能不够的。
3.1.2:方法2:使用UVR5客户端(没有bug,模型更多)
官方下载地址:Releases · TRvlvr/model_repo · GitHub(beta版)
https://github.com/Anjok07/ultimatevocalremovergui/releases(正式版)
macOS和Liunx的使用方法
由于苹果的严格管控应用程序的安全性,您可能需要按照以下步骤打开UVR:
首先,使用终端运行以下命令,允许应用程序从所有来源运行:
sudo spctl --master-disable
其次,运行以下命令来绕过验证:
sudo xattr -rd com.apple.quarantine /Applications/Ultimate\ Vocal\ Remover.app
Linux:嗯?都用Linux了,用Git拉代码自己部署不是难事吧?欸嘿~
为了最好的分离效果教程中使用的是beta版,网盘中的windows安装包是beta版
目前MAC使用beta版要自己拉代码装环境,或者等安装包制作完成
网盘中的安装包是正式版的
警告:安装路径必须为全英文!!!不推荐修改默认安装路径,否则会有权限问题!!!
打开UVR5首先要下载模型,建议下载我打包好的,里面有几乎所有模型,包含vip模型。下载解压后先把Ultimate Vocal Remover根目录的models文件夹删了,再把解压的文件夹直接拖进Ultimate Vocal Remover根目录替换models文件夹
如果觉得模型包太大,也可以自己下载(需要科学上网,且速度很慢,一次只能下一个)。点击左下角的小扳手,打开设置界面,点击第三个下载模型。需要下载的模型有:MDX-Net:model_bs_roformer_ep_317_sdr_12.9755、VR Architecture:UVR-De-Echo-Normal、UVR-De-Echo-Aggressive、UVR-De-Echo-Dereverb、UVR-DeNoise。
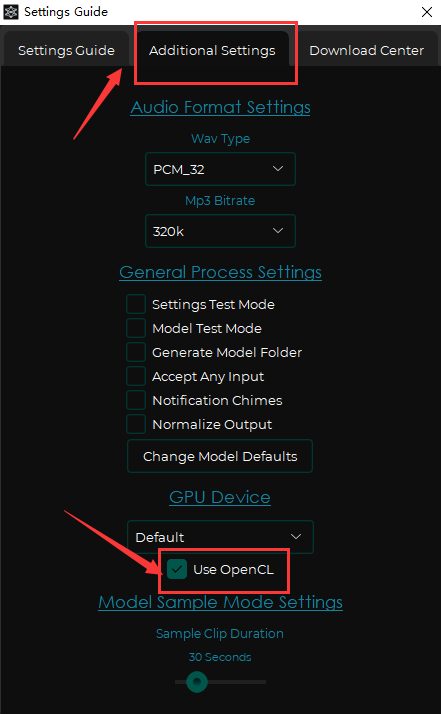
如果是A卡或I卡用户需要在第二个设置界面点上Use OpenCL
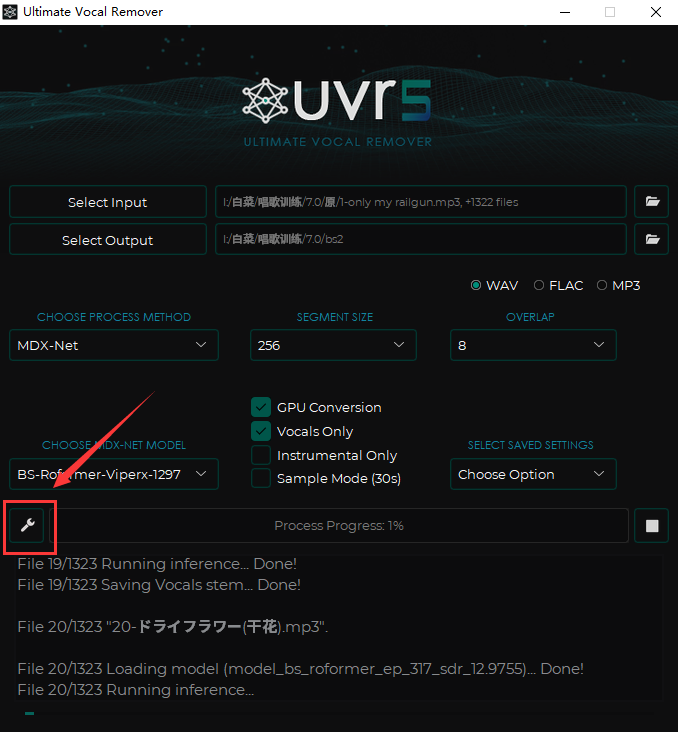

下载完模型后开始处理音频,select input选择输入文件,select output选择输出文件夹,输出格式选WAV,记得点上GPU Conversion(使用GPU),首先选择MDX-Net类型使用Bs-Roformer-Viperx-1297(目前最好的提取人声的模型,又快又好)提取人声。处理完的音频(vocals)的是人声。然后把人声再输入去混响(下面三选一):VR Architecture:UVR-De-Echo-Normal(轻度混响)、UVR-De-Echo-Aggressive(重度混响)、UVR-De-Echo-Dereverb(变态混响),最后用UVR-DeNoise降噪一下。这套流程弄完会比自带的UVR5在人声提取方面好一点。
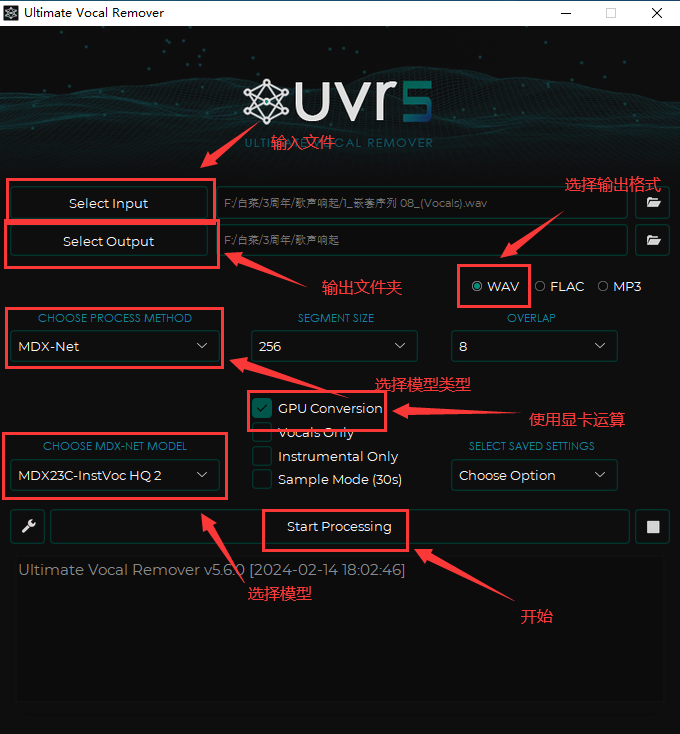
3.1.3:方法3:MDX23C(MAC用户暂时用)
因为目前MAC没有UVR5beta版的安装包,要么拉代码自己装,要么只能用5.6正式版
正式版目前最好的模型是MDX23C,流程和4.1.1.1.3.1一样的只是把Bs-Roformer-Viperx-1297换成MDX23C
3.2:切割音频
在切割音频前建议把所有音频拖进音频软件(如au、剪映)调整音量,最大音量调整至-9dB到-6dB,过高的删除
首先输入原音频的文件夹路径(不要有中文),如果刚刚经过了UVR5处理那么就是uvr5_opt这个文件夹。然后建议可以调整的参数有min_length、min_interval和max_sil_kept单位都是ms。min_length根据显存大小调整,显存越小调越小。min_interval根据音频的平均间隔调整,如果音频太密集可以适当调低。max_sil_kept会影响句子的连贯性,不同音频不同调整,不会调的话保持默认。其他参数不建议调整。点击开启语音切割,马上就切割好了。默认输出路径在output/slicer_opt。建议不要改输出路径,到时候找不到文件谁也帮不了你。当然也可以使用其他切分工具切分。
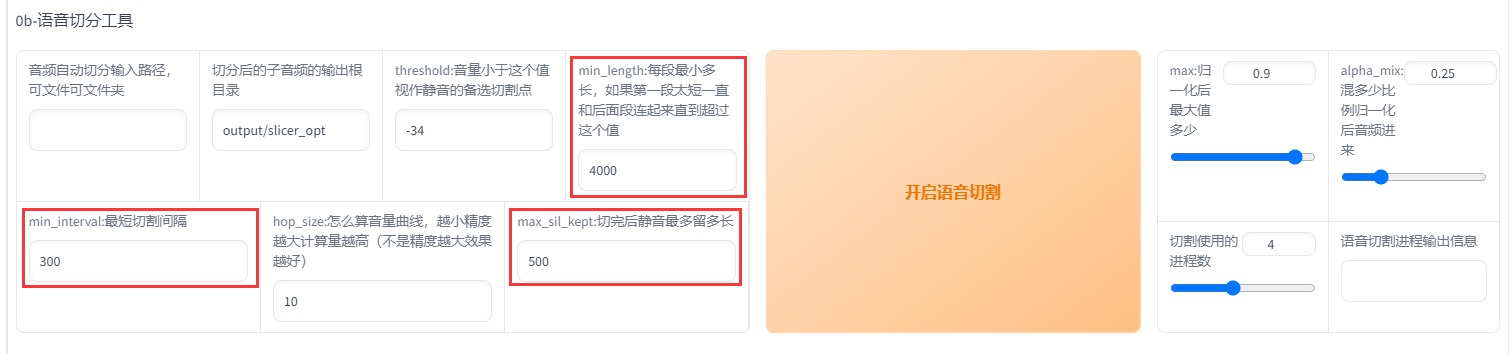
切分完后文件在\GPT-SoVITS-beta\GPT-SoVITS-beta\output\slicer_opt。打开切分文件夹,排序方式选大小,将时长超过 显存数 秒的音频手动切分至 显存数 秒以下。比如显卡是4090 显存是24g,那么就要将超过24秒的音频手动切分至24s以下,音频时长太长的会爆显存。如果语音切割后还是一个文件,那是因为音频太密集了。可以调低min_interval,实在不行用au手动切分。
3.3:音频降噪(如果原音频足够干净可以跳过这步,比如游戏中提取的干声)
在0221版本之后才有这个功能而且不太好用,对音质的破坏很大,谨慎使用。
输入刚才切割完音频的文件夹,默认是output/slicer_opt文件夹。然后点击开启语音降噪。默认输出路径在output/denoise_opt,建议不要改输出路径,到时候找不到文件谁也帮不了你。

3.4:打标
为什么要打标:打标就是给每个音频配上文字,这样才能让AI学习到每个字该怎么读。这里的标指的是标注
这步很简单只要把刚才的切分文件夹输入,如果你音频降噪过,那么默认是output/denoise_opt文件夹,如果你切分了没有降噪,那么默认是output/slicer_opt文件夹。然后选择达摩ASR或者fast whisper。达摩ASR只能用于识别中文,效果也最好。fast whisper可以标注99种语言,是目前最好的英语和日语识别,模型尺寸选large V3,语种选auto自动就好了。然后点开启离线批量ASR就好了,默认输出是output/asr_opt这个路径,建议不要改输出路径,到时候找不到文件谁也帮不了你。ASR需要一些时间,看着控制台有没有报错就好了
如果有字幕的可以用字幕标注,准确多了。内嵌字幕或者外挂字幕都可以,教程使用字幕标注(更准确)

3.5:校对标注(这步比较费时间,如果不追求极致效果可以跳过)
输入标注文件的文件路径,注意是文件路径!不是文件夹路径!示例:D:\GPT-SoVITS-beta\GPT-SoVITS-beta0128\output\asr_opt\slicer_opt.list 注意后面的文件名必须要输进去!打不开就再三检查路径是否正确!必须要有.list的后缀!!!然后开启打标webui
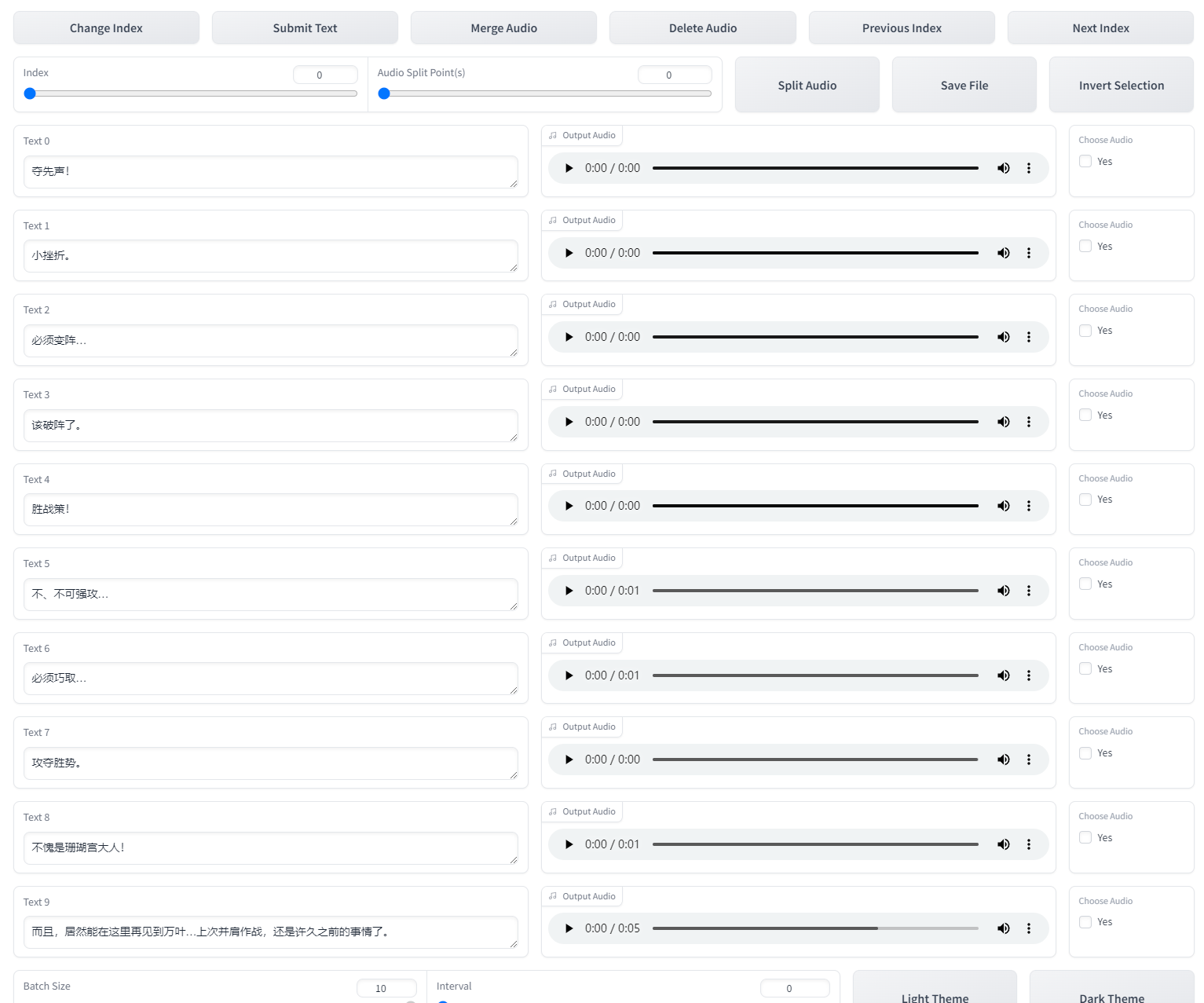
打开后就是SubFix,从左往右从上到下依次意思是:跳转页码、保存修改、合并音频、删除音频、上一页、下一页、分割音频、保存文件、反向选择。每一页修改完都要点一下保存修改(Submit Text),如果没保存就翻页那么会重置文本,在完成退出前要点保存文件(Save File),做任何其他操作前最好先点一下保存修改(Submit Text)。合并音频和分割音频不建议使用,精度非常差,一堆bug。删除音频先要点击要删除的音频右边的yes,再点删除音频(Delete Audio)。删除完后文件夹中的音频不会删除但标注已经删除了,不会加入训练集的。这个SubFix一堆bug,任何操作前都多点两下保存。
4:训练
4.1:输出logs
来到第二个页面
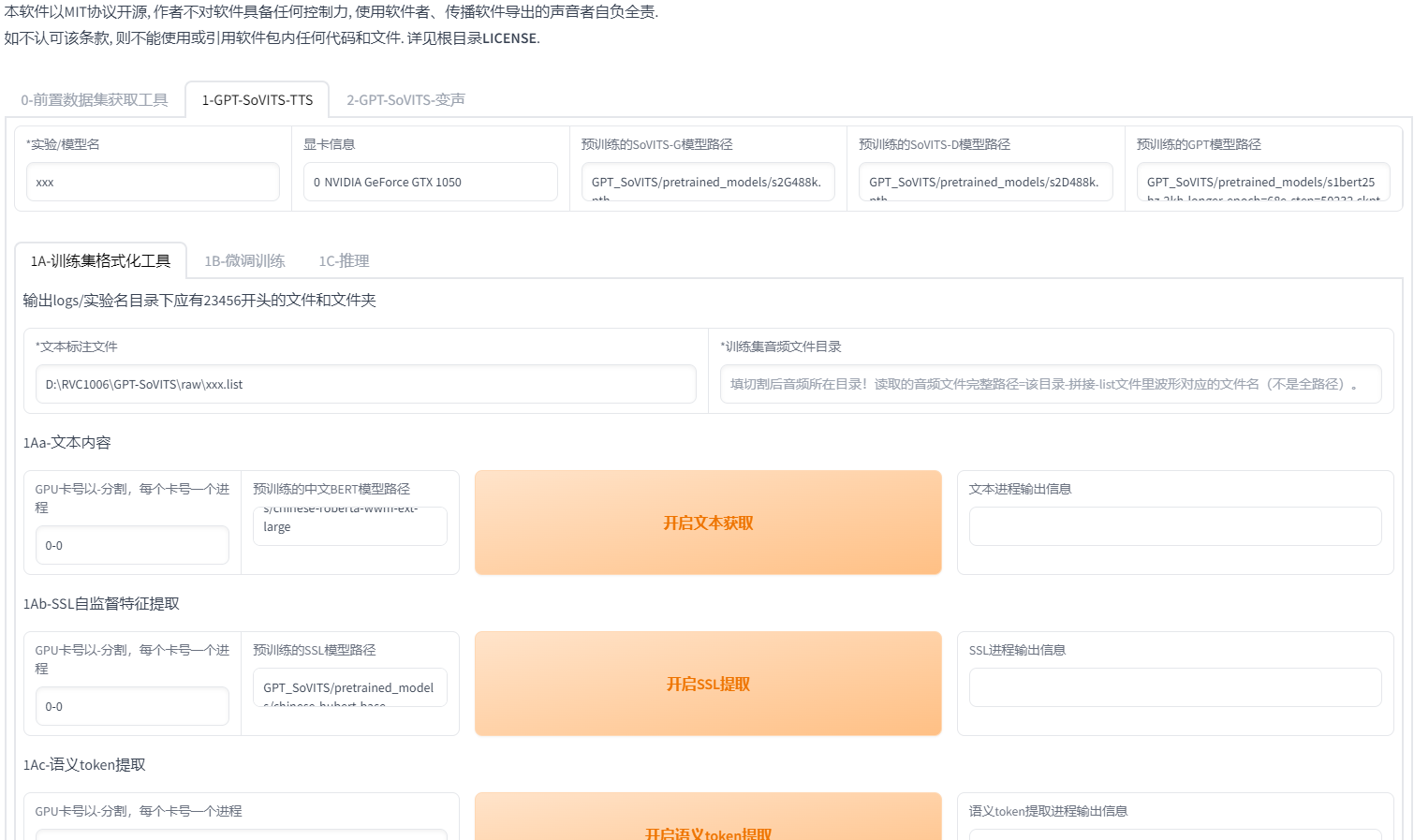
先设置实验名也就是模型名,不要有中文!然后第一个输入的是标注文件路径,注意是文件路径!不是文件夹路径!示例:D:\GPT-SoVITS-beta\GPT-SoVITS-beta0128\output\asr_opt\slicer_opt.list 注意后面的文件名必须要输进去!打不开就再三检查路径是否正确!必须要有.list的后缀!!!第二个输入的是切分音频文件夹路径 示例:G:\GPT-SoVITS\output\slicer_opt。注意复制的路径都不能有引号!!!千万不能有引号!然后点一键三连。
如果是英语或日语的话logs里的3-bert文件夹是空的,是正常的不用管。
4.2:微调训练
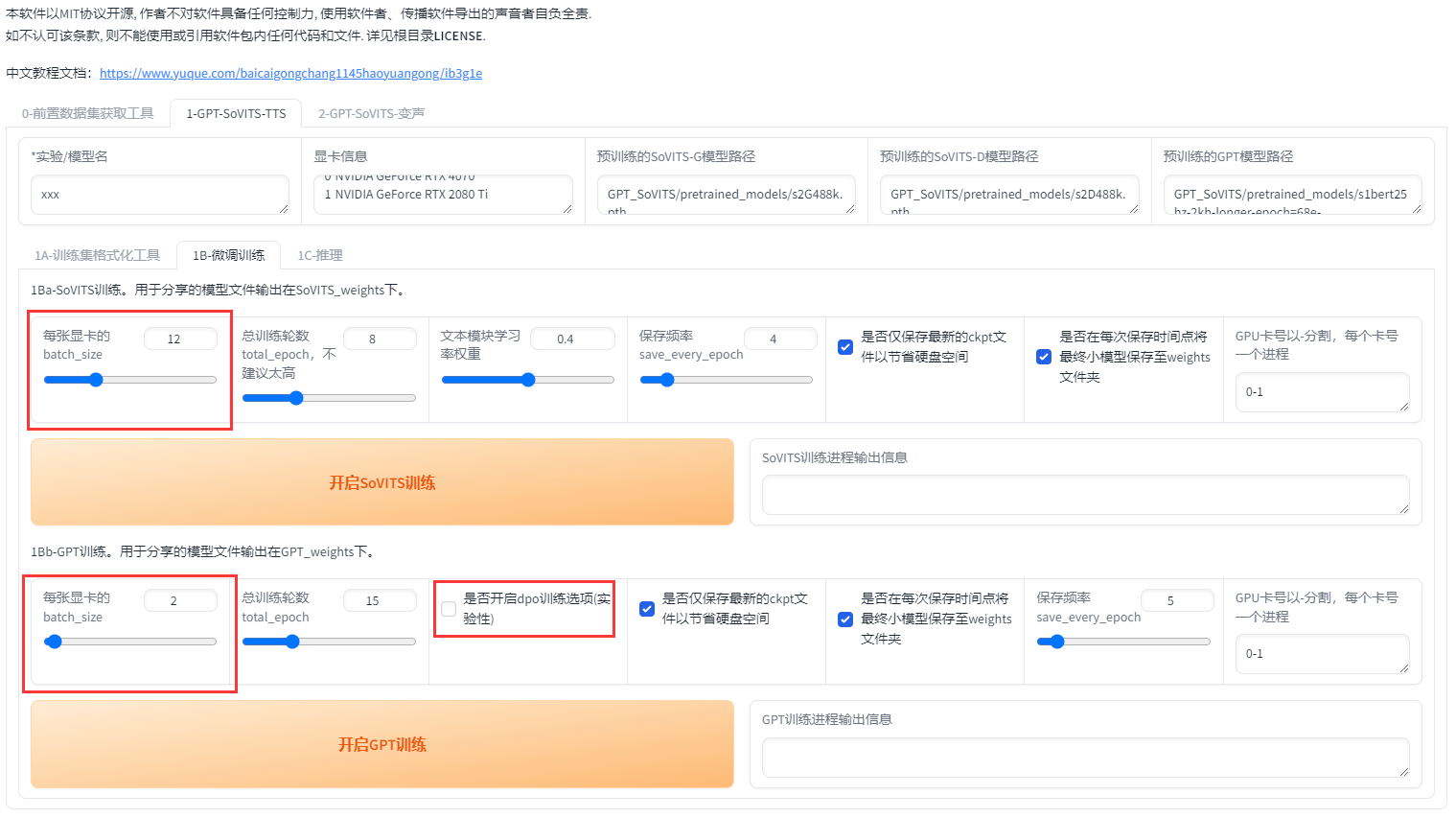
首先设置batch_size,sovits训练建议batch_size设置为显存的一半以下,高了会爆显存。bs并不是越高越快!batch_size也需要根据数据集大小调整,也并不是严格按照显存数一半来设置,比如6g显存需要设置为1。如果爆显存就调低。当显卡3D占用100%的时候就是bs太高了,使用到了共享显存,速度会慢好几倍。
以下是切片长度为10s时实测的不同显存的sovits训练最大batch_size,可以对照这个设置。如果切片更长、数据集更大的话要适当减少。
| 显存 | batch_size | 切片长度 |
| 6g | 1 | 10s |
| 8g | 2 | 10s |
| 12g | 5 | 10s |
| 16g | 8 | 10s |
| 22g | 12 | 10s |
| 24g | 14 | 10s |
| 32g | 18 | 10s |
| 40g | 24 | 10s |
| 80g | 48 | 10s |
在0213版本之后添加了dpo训练。dpo大幅提升了模型的效果,几乎不会吞字和复读,能够推理的字数也翻了几倍,但同时训练时显存占用多了2倍多,训练速度慢了4倍,12g以下显卡无法训练。数据集质量要求也高了很多。如果数据集有杂音,有混响,音质差,不校对标注,那么会有负面效果。
如果你的显卡大于12g,且数据集质量较好,且愿意等待漫长的训练时间,那么可以开启dpo训练。否则请不要开启。下面是切片长度为10s时实测的不同显存的gpt训练最大batch_size。如果切片更长、数据集更大的话要适当减少。
| 显存 | 未开启dpo batch_size | 开启dpo batch_size | 切片长度 |
| 6g | 1 | 无法训练 | 10s |
| 8g | 2 | 无法训练 | 10s |
| 12g | 4 | 1 | 10s |
| 16g | 7 | 1 | 10s |
| 22g | 10 | 4 | 10s |
| 24g | 11 | 6 | 10s |
| 32g | 16 | 6 | 10s |
| 40g | 21 | 8 | 10s |
| 80g | 44 | 18 | 10s |
接着设置轮数,SoVITS模型轮数可以设置的高一点,反正训练的很快。GPT模型轮数千万不能高于20(一般情况下)建议设置10。然后先点开启SoVITS训练,训练完后再点开启GPT训练,不可以一起训练(除非你有两张卡)!如果中途中断了,直接再点开始训练就好了,会从最近的保存点开始训练。
训练的时候请ctrl+shift+esc打开任务管理器看,下拉打开选项,选择cuda。如果cuda占用为0那么就不在训练。专用GPU内存就是显存,其他的内存都是共享的,并不是真正的显存。爆显存了就调低bs。或者存在过长的音频,需要回到2.2步重新制作数据集。
win11没有cuda打开设置--系统--显示--显示卡--默认图形设置
关闭硬件加速GPU计划,并重启电脑

训练完成会显示训练完成,并且控制台显示的轮数停在设置的(总轮数-1)的轮数上。
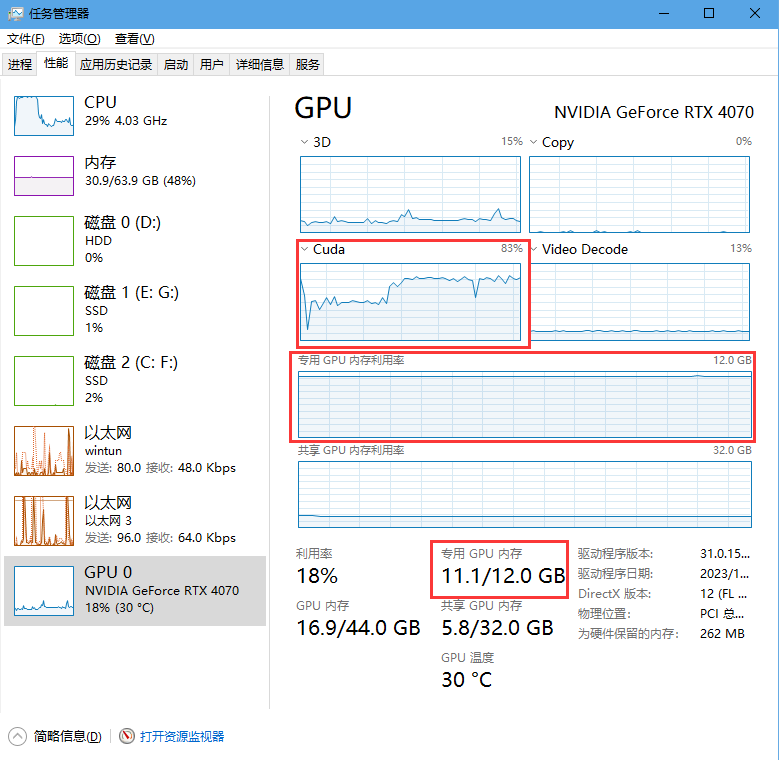
看cuda占用需要下拉选择cuda,如果win11找不到cuda界面需要关闭硬件加速GPU计划并重启
关于学习率权重:
可以调低但不建议调高。直接听对比,自己听效果
关于高训练轮数:你可能会看见有人会说训练了几百轮,几千轮的(几万轮那就是搞错了轮数和步数)。但高轮数并不就是好。如果要训练高轮数请先保证数据集质量极好,标注全都经过手动校对,时长至少超过1小时才有必要拉高轮数。否则默认的十几轮效果已经很好了。
关于数据集长度:
请先保证质量!音频千万不能有杂音,要口齿清晰,响度统一,没有混响,每句话尽量完整,全部手动校对标注。30分钟内有明显提升,不建议再增加数据集长度(除非你有一堆4090)
模型怎样才算训练好了?
这是一个非常无聊且没有意义的问题。就好比上来就问老师我家孩子怎么才能学习好,谁都无法回答。
模型的训练关联于你的数据集质量、时长,轮数,甚至一些超自然的玄学因素;即便你有一个成品模型,最终的转换效果也要取决于你的参考音频以及推理参数。这不是一个线性的的过程,之间的变量实在是太多,所以你非得问“为什么我的模型出来不像啊”、“模型怎样才算训练好了”这样的问题。
但也不是一点办法没有,只能烧香拜佛了。我不否认烧香拜佛当然是一个有效的手段,但你也可以借助一些科学的工具,例如 Tensorboard 等,但还是戴上耳机,让你的耳朵告诉你吧。用耳朵听就是最科学的方式。
如果你的模型一直很差,那你该好好反思反思为什么不好好准备数据集了。
博主 政安晨 注:
在使用过程中有时会看到提示:
IMPORTANT: You are using gradio version 3.38.0, however version 4.29.0 is available, please upgrade.
放心更新它。
还是在conda环境中执行:
pip show gradio查看版本确实较旧时,执行:
pip install --upgrade gradio
(表示更新到最新版本)
另外,pip install gradio==<version>将“版本”替换为您要安装的 Gradio 版本。“<”和“>”是不需要的。
当然,如果更新之后,发现webui跑不起来,你由不愿意详细检查问题的话,就用上述命令更换回原来的版本。















![YOLOv8的训练、验证、预测及导出[目标检测实践篇]](https://img-blog.csdnimg.cn/direct/71584cb1e2cd435eb305f88ba7737ca1.png)