目录
编辑
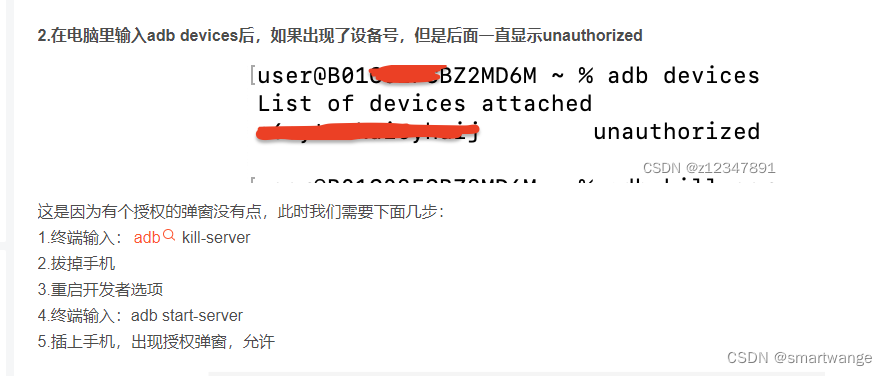
52.元学习适合哪些学习场景?可解决什么样的学习问题?
55.元学习与有监督学习/强化学习具体有哪些区别?
1、迁移学习(Transfer Learning)
2、元学习(Meta Learning)
3、小样本学习(Few-Shot Learning)
4、强化学习(Reinforcement Learning)
5、深度强化学习(Deep Reinforcement Learning DRL)
6、联邦学习
7、对比学习
52.元学习适合哪些学习场景?可解决什么样的学习问题?
1. 元学习在解决什么问题
传统的深度学习方法需要大量数据,在某些场景下我们无法获得太多的数据,传统深度学习方法失效,因此我们使用元学习。但传统的元学习方法依然无法解决某些场景的问题,因此需要提出一些更加General的元学习的算法,提高元学习的泛化能力。
2. 元学习是什么
元学习的初衷是学会学习(学会如何为具体任务构建模型),即提取元知识,使用元知识。
从网络结构角度讲,元学习应该由两种网络组成——meta-net 和 net,一方面net从meta-net中获取知识,另一方面meta-net观察net的表现改进自身


元知识有很多种类,如神经网络初始化参数(optimization-based meta learning)、适合度量数据距离的特征空间(metric-based meta learning)、Net的网络结构和网络参数(model-based meta learning)等等。
但这些方法提取的元知识未必足够好,并且我们对元知识的理解还不够充分,因此需要更好地提取元知识。
3. 主流元学习方法的思想
主流的元学习方法包括optimization-based meta learning、metric-based meta learning、model-based meta learning. 这些方法之所以是主流,是因为它们具有较好的性能、较强的泛化能力。对主流元学习方法(如MAML和Prototype network)的改进也是一个热门的方向。
综上所述,Meta-Learning的研究有三个主要方向
提高元学习的泛化能力。提取出更好的元知识。改进现有的元学习方法。
General Meta Learning
主流的meta learning算法要求训练数据(一组任务)的distribution=测试数据(全新的任务)的distribution,这个设定还需要改进。
一方面,这不符合现实世界的多样性特点;另一方面,改进设定有助于我们提取出更好的元知识,更加靠近同样人工智能。
因此,可以大致提出三种不同的设定——Data type相同,Data distribution不同;Data type不同,data distribution不同;训练数据和测试数据种类不同。
元学习领域的Open Challenge
Meta-generalization
(1)当用一组任务训练元学习器时,它很难拟合出任务的分布。
可能是因为任务数量少导致过拟合,也可能是因为不同任务的梯度更新方向相互冲突。
(2)由于上面的问题,当模型从meta-train task向meta-test task generalize时,测试任务必须与训练任务比较相似才能实现generalize
(3)更进一步,当meta-test task是从完全不同的分布中获得时,模型的表现就更差了。
这个问题涉及到迁移学习、领域自适应。在去年被提出,今年已经有几个团队开始解决这一问题。
2. Multi-modality of task distribution
现在的元学习框架都隐式假设任务的分布是uni-modal(单峰),因此一个元学习器就可以为所有任务提供好的解。但实际上任务的分布可能是multi-modal的,不同modal的任务可能需要不同的学习策略。
在一篇论文中,作者生成了多M元参数θ,在实际应用时根据具体任务选择合适的θ。虽然作者这么做是为了解决其它问题,但可以借鉴他们的思路解决这类问题。
3. Task families
很多现有的元学习框架都要求测试数据集是一系列任务,这在某些场景下无法满足。
无监督元学习、在线元学习有助于解决这一限制。
4. Computation Cost
训练每一个任务都需要更新参数,很多时候要求二阶导数,计算代价大。
5. Corss-modal
从一个模态的许多任务中获取元知识,应用到另一个模态的新任务中。
三种主流方法的问题
1.Metric-based method
1.1 总结
这类方法元学习一个特征空间,可用于基于输入相似度预测类别。
进一步说,这类方法的目标是获取一个可以度量相似性的好的特征空间, 随后把这一特征空间用于各种各样的新任务。在神经网络的情况下,该特征空间与网络的权重weights相吻合。
然后,通过比较元学习特征空间中的新输入和示例输入,可以学习新的任务。具体来说,新输入与示例之间的相似性越高,它们属于同一类的可能性就越大。
这类方法计算输入的相似性,简单有效,计算快,训练模型不需要针对测试任务进行调整。
未来的改进方向:
应用在监督学习之外的设定中;当测试与训练任务距离远时,效果不好;任务变得更大时,逐对比较导致计算上成本昂贵;
1.2 经典算法的不足
(1)Siamese Neural Networks(Siamese Neural Networks for One-shot Image Recognition)
idea:训练模型以判断两张图片是否属于同一类,借此完成分类任务。
不足:优化的目标不是在多个任务上表现好,而仅仅是在一个任务上表现好;无法应用到监督学习之外的场景。
(2)Matching Networks(Matching Networks for One Shot Learning)
idea:学习到了跨任务的特征空间,以便在输入之间进行两两比较。与上一种方法相比,该特征空间是跨任务学习的,而不是在一个不同的验证任务上学习的。
不足:无法应用到监督学习外的场景,当label的分布是有偏时表现不好。
(3)Prototypical Networks(Prototypical Networks for Few-shot Learning)
idea不计算输入和支持集示例之间的相似性,而是将输入与类原型(质心)进行比较,类原型是嵌入空间中类的单一向量表示。由于类原型的数量比支持集中的示例数量要少,因此两两比较所需的数量减少,节省了计算成本。
不足:原型的确定有改进空间
(4)Relation Networks(Learning to Compare: Relation Network for Few-Shot Learning)
idea:采用一个神经网络作为可训练的相似度度量方法,而不是预定义的度量,例如,前面使用的余弦相似度。这使得模型具有更强的表达能力。
不足:还没想出来不足点。
2. Model-based/Black-box method
2.1 总结
这类方法先学习任务的表示,再用任务的表示生成分类模型的部分参数。当一个任务出现时,基于模型的神经网络按顺序处理数据集。在每一个时间步骤中,都会有一个输入进入,并改变模型的内部状态。因此,内部状态可以捕获相关的特定于任务的信息,这些信息可以用于生成另一个分类模型的部分参数。
Black-box名字的由来:模型的输出不是分类标签本身,而是分类模型的参数(或一部分参数),因而是黑盒的。
未来的改进方向:
由于其系统内部动力学的灵活性,相比大多数基于度量的元学习有更广泛适用性;在很多监督任务上表现不如度量学习;当数据量增大时,效果变差;任务间距离大时,效果不如基于优化的元学习方法;
2.2 经典算法的不足
(1)MANN(Meta-learning with Memory-augmented Neural Networks)
idea:采用神经图灵机,将神经网络与外部记忆模块结合起来;和matric based方法相比,可以应用在回归问题。
不足:模型太过复杂,缺乏理论分析,无法确定到底是怎么work的;meta learning和base learning交缠在一起,分不清楚。
(2)Meta Networks
idea:使用meta-learner和base-learner分别代表mata learning和base learning,base-learner负责完成任务,并为meta-learner提供元信息,如损失梯度。然后meta-learner可以为自己和base-learner快速计算特定任务的权重,这样就可以更好地完成给定的任务
不足:模型太过复杂,缺乏理论分析,无法确定到底是怎么work的,计算量大,内存需求大;对每个任务,meta-learner和base-learner都需要重新参数化;内部的模块需要手动设计。
(3)SNAIL(A Simple Neural Attentive Meta-Learner)
idea:提出了更好的记忆模块——通过时序卷积和软注意力机制,将模型看到的所有任务记忆到Memory中。比MANN的模型更加简化。
不足:内部的模块——TCBlocks和DenseBlocks需要手动设计。
(4)CNPs(Conditional neural processes)
idea:不使用记忆模块生成参数,而是把训练集编码成一个向量,将向量与测试数据拼接起来,进行预测;作者把编码的向量视作神经网络第1层的参数;简单优雅的黑盒模型。
不足:方法太简单粗暴,表现不如其它的方法。
3. Optimization-based method
3.1 总结
基于优化的方法目标是通过参数优化快速学习新任务。这与经典的学习方法非常类似,经典的学习也是通过优化(如梯度下降)实现的。
然而,与传统方法相比,基于优化的元学习器可以学习优化本身,并且是在多个任务下执行参数优化得到的,这让模型可以学会快速学习新任务。
基于优化的方法的一个关键优势是,与基于模型的方法相比,它们可以在更广泛的任务分配上取得更好的表现。但是计算代价太昂贵了,这为引入新的模块/设定新的应用场景造成了很大的阻碍。
未来的几个主要改进方向:
减少计算量;减少模型在训练任务上的过拟合;在概率论的框架下实现模型,使用更好的概率近似方法,从任务中提取更好的先验;
3.2 经典算法的不足
(1)MAML
不足:需要计算模型的二阶导数,计算量大,计算需要的内存大
(2)iMAML(Meta-Learning with Implicit Gradients)
idea:通过数学推导简化了MAML二阶导的计算,改变了inner-loop的计算形式,解决了计算需要内存大的问题
不足:没有解决计算量大的问题
(3)Meta-SGD(Meta-SGD: Learning to Learn Quickly for Few-Shot Learning)
idea:为MAML的每层参数都学习一个学习率
不足:效果更好,但没解决计算量大、需要内存大的问题
(4)Reptile(On First-Order Meta-Learning Algorithms)
idea:MAML的极其简化版本,解决了计算量和内存消耗问题
不足:理论基础薄弱,表现不如MAML
(5)LEO(Meta-Learning with Latent Embedding Optimization)
idea:在低维latent embedding space进行优化,解决参数过多引发的过拟合问题
不足:比MAML复杂,只能适用于few-shot learning问题
(6)LLAMA(Recasting Gradient-Based Meta-Learning as Hierarchical Bayes)
idea:把MAML引入到概率框架中,使得task-specific parameter Φ不再是一个确定的值,而是一个概率分布,从而刻画出了模型对于预测结果的confidence。
不足:增加了计算量;使用的概率推理近似方法Laplace approximation有近似误差,应该试着找一下更好的近似方法。
(7)PLATIPUS(Probabilistic Model-Agnostic Meta-Learning)
idea:在上一篇论文的基础上,学习到了初始化参数θ的概率分布,而不是Φ的概率分布,这样一来,我们可以针对不同的任务,选择合适的初始化参数θ
不足:增加了计算量,无法应用到监督学习之外的场景
(8)Bayesian MAML(Bayesian Model-Agnostic Meta-Learning)
idea:在前面论文的基础上,使用MAML生成许多个候选解,可用于强化学习。
不足:没有学到解的分布,仅仅学习了M个可能的解;内存需求大,保存了M组参数。
53.使用学习优化算法的方式处理元学习问题,与基于记忆的元学习模型有哪些区别?
监督学习:
只在一个任务上做训练;只有一个训练集和一个测试集;学习的是样本之间的泛化能力;要求训练数据和测试数据满足独立同分布;监督学习的训练和测试过程分别为train和test;
元学习:
元学习是面向多个任务做联合训练;每个任务都有训练集和测试集;学习到的是任务之间的泛化能力;要求新任务与训练任务再分布上尽可能一致;元学习的训练和测试过程分别叫做Meta-train和Meta-test;
基于度量的三个元学习模型:
MatchingNet:Support set经过特征提取后,在embedding空间中利用Cosine来度量,通过对测试样本进行计算匹配程度来实现分类;ProtoNet:利用聚类思想,将Support set投影到一个度量空间,在欧式距离度量的基础上获取向量均值,对测试样本计算到每个原型的距离,实现分类;RelationNet:关系网络提出的relation module结构替换了MatchingNet和ProtoNet中的Cosine和欧式距离度量,使其成为一种学习的非线性分类器用于判断关系,实现分类。
基于优化的三个元学习模型
基于优化的三个元学习模型示意图
MAML:Model Agnostic Meta-Learning通过优化二阶梯度的方式,学习一个通用的初始化模型,使得模型面对新任务时,进行少次迭代便可收敛;Reptile:命名可能单纯为了和MAML对应(Reptile:爬行动物;mammal:哺乳动物),由示意图可知,与 MAML不同的是,Reptile是一个一阶的基于梯度的元学习算法,每次base model的参数更新是在每个task的一阶梯度上做的,不过进行了多次;LEO:Latent Embedding Optimization方法针对模型的超高维参数空间,小样本情况下几步梯度下降导致的过拟合的问题,将模型高维参数空间学习到一个低维嵌入,在低维空间实施梯度下降来实现对问题进行改善;Fine-tune:除了上述三个典型的模型之外,基于优化的元学习还包括预训练方法(fine-tune),与MAML等学习一个通用的初始模型的思想很接近,基于预训练的是在一批已有的任务上或者一个大型数据集上学习到的模型,面对新任务时,将其模型参数做为初始点,在新任务进行微调。而上述三中元学习方法是学习一个通用的模型,使得这个模型在面对旧任务和新任务时都可以在几步梯度下降后达到相应任务的较优解。此外,由于预训练模型在面对新任务时更新了参数,让原先在旧任务上训练好的参数被新的信息覆盖,容易产生灾难性遗忘问题
基于优化的元学习存在的问题
基于优化的元学习方法即参数化方法在使用梯度下降法更新权重时,由于优化器选择(如:SGD、Adam等)和学习率lr设定的限制,通常需要更新多步达到较优的点,使得当模型在面对新任务时,学习过程缓慢;此外在训练小样本情况下,更新权重的过程中容易过拟合。
基于度量的元学习存在的问题
基于度量的元学习方法即非参数化方法虽然没有上述苦恼,但也绝对不是完美的,matrix learning的核心在于损失函数的设置,然而A Metric Learning Reality Check这篇文章却给这个领域泼了一盆冷水,该领域十三年来无进展,这也说明了度量学习领域正处于发展的瓶颈期,某些创新提出的loss在人脸数据集上涨了很多,但在其他任务上效果可能会变得更差,这也说明度量学习方法的鲁棒性不高,对数据集相对来说比较挑剔。
好的机器学习模型经常需要大量的数据来进行训练,但人却恰恰相反。小孩子看过一两次猫和小鸟后就能分辨出它们的区别。会骑自行车的人很快就能学会骑摩托车,有时候甚至不用人教。那么有没有可能让机器学习模型也具有相似的性质呢?如何才能让模型仅仅用少量的数据就学会新的概念和技能呢?这就是元学习要解决的问题。
我们期望好的元学习模型能够具备强大的适应能力和泛化能力。在测试时,模型会先经过一个自适应环节(adaptation process),即根据少量样本学习任务。经过自适应后,模型即可完成新的任务。自适应本质上来说就是一个短暂的学习过程,这就是为什么元学习也被称作学会学习。
元学习可以解决的任务可以是任意一类定义好的机器学习任务,像是监督学习,强化学习等。具体的元学习任务例子有:
在没有猫的训练集上训练出来一个图片分类器,这个分类器需要在看过少数几张猫的照片后分辨出测试集的照片中有没有猫(小样本学习)。
训练一个玩游戏的AI,这个AI需要快速学会如何玩一个从来没玩过的游戏(元强化学习)。
从目标上看元学习和迁移学习并无本质区分,都是增加学习器在多任务的范化能力,但元学习更偏重于任务和数据的双重采样,任务和数据一样是需要采样的,而学习到的F(x)可以帮助在未见过的任务f(x)里迅速建立映射关系。而迁移学习更多是指从一个任务到其它任务的能力迁移,不太强调任务空间的概念,具体上说,元学习可以如下展开:
机器学习围绕一个具体的任务展开,然而在生物体的一生中,学习的永远不只是一个任务。与之相对应的叫做元学习,元学习旨在掌握一种学习的能力,使得智能体可以掌握很多任务。如果用数学公式表达,这就好比先学习一个函数F(x),代表一种抽象的学习能力,在此基础上学习f(x)对应具体的任务。
我们做一个比喻,机器学习学习某个数据分布X到另一个分布Y的映射。而元学习学习的是某个任务集合D到每个任务对应的最优函数f(x)的映射(任务到学习函数的映射)。基本的元学习思路是学到一个能够很好地筛选得到有用的归纳偏差(inductive bias,即"学习器用来预测尚未遇到的给定输入的输出的一组假设")的能力,在此基础上寻找能够适应多任务的F。这个想法有点像是我们面对某个只有少量数据的任务时,会使用在相关任务的大数据集上预训练的模型,然后进行微调(fine-tuning)。像是图形语义分割网络可以用在ImageNet上预训练的模型做初始化。相比于在一个特定任务上微调使得模型更好地拟合这个任务,而元学习更进一步,它的目标是让模型优化以后能够在多个任务上表现得更好,类似于变得更容易被微调。
小样本学习(Few-shot classification)是元学习的在监督学习中的一个实例。数据集D经常被划分为两部分,一个用于学习的支持集(support set) S,和一个用于训练和测试的预测集(prediction set) B,即 D=〈S,B〉 。K-shot N-class分类任务,即支持集中有N类数据,每类数据有K个带有标注的样本。
常见方法
元学习主要有三类常见的方法:基于度量的方法(metric-based),基于模型的方法(model-based),基于优化的方法(optimization-based)。
55.元学习与有监督学习/强化学习具体有哪些区别?
1、迁移学习(Transfer Learning)
直观理解:站在巨人的肩膀上学习。根据已有经验来解决相似任务,类似于你用骑自行车的经验来学习骑摩托车。
专业理解:将训练好的内容应用到新的任务上,即将源域(被迁移对象)应用到目标域(被赋予经验的领域)。
迁移学习不是具体的模型,更类似于解题思路。
当神经网络很简单,训练一个小的神经网络不需要特别多的时间,完全可以从头开始训练。如果迁移之前的数据和迁移后的数据差别很大,这时迁移来的模型起不到很大的作用,还可能干扰后续的决策。
应用场景:目标领域数据太少、节约训练时间、实现个性化应用。
实际擅长应用例举:语料匮乏的小语种之间的翻译、缺乏标注的医疗影像数据识别、面向不同领域快速部署对话系统。
NLP领域中的应用:Transformer、Bert之类的预训练语言模型,微调后可以完成不同的任务。
2、元学习(Meta Learning)
与传统的监督学习不一样,传统的监督学习要求模型来识别训练数据并且泛化到测试数据。
训练目标:Learn to Learn,自己学会学习。例:你不认识恐龙,但是你有恐龙的卡片,这样看见一张新的图片时,你知道新的图片上的动物与卡片上的动物长得很像,是同类的。
靠一张卡片来学习识别叫做:one-shot learning。
3、小样本学习(Few-Shot Learning)
Few-Shot Learning是一种Meta Learning。
用很少的数据来做分类或回归。例如:模型学会了区分事物的异同,例如:虽然数据集中没有狗的照片,模型不会识别狗,但模型也能判断两张狗的图片上的事物是同类的。
数据集:Support Set。Support Set与训练集的区别:训练集的规模很大,每一类下面有很多图片,可以用来训练一个深度神经网络。相比这下,Support Set数据集比较小,每一类下面只有一张或几张图片,不足以训练一个大的神经网络。Support Set只能在做预测的时候提供一些额外的信息。
用足够大的训练集来训练一个大模型,比如深度神经网络,训练的目的不是为了让模型来识别训练集里的事物,而是让模型学会区分事物的异同。
传统监督学习 VS Few-Shot Learning:传统监督学习是先用一个训练集来学习一个模型,模型学习好之后可以用来做预测,给一张没有出现在训练集中的图片,模型没有见过这张图片,但是测试图片的类别包含在训练集中,模型能很容易就判断出图片的类别。而Few-Shot Learning不仅没有见过这张图片,训练集中也没有该类别的图片。Few-Shot Learning的任务比传统监督学习更难。
k-way n-shot Support Set:Support Set中有k个类别,每个类别;里有n个样本。
4、强化学习(Reinforcement Learning)
不是某种特定的模型和算法,指的是训练方法。
举例:下棋:每当落下一子,对方都会再落下一子,这时主体就要认识新的局面也就是新的环境,分析判断后再行动,主体的目标是在尽可能多的棋局中获胜。
由于主体的每个行为都会改变环境,这决定了强化学习无法使用数据集训练,只能通过真是环境或模拟器产生的数据来学习,由于计算量大,效率低,除AlphaGo和游戏AI外落地应用并不多。
实际应用:推荐系统每次都会影响人们的购买,系统需要根据新的市场数据给出新的推荐;股票市场中每个人每时每刻买入卖出都会影响股价,交易系统需要理解新的环境后再行动。
强化学习算法可以分为两类:基于模型的(试图用模型模拟真实环境)。无模型的(不模拟环境,只根据反馈数据构建关于回报的模型)。
在强化学习中,做出决策的一方称为Agent(主体),主体每做出一个动作,环境都会给予反馈,主体会在评估反馈之后决定下一个动作。一切动作的基础都是回报,目标是长期,也就是未来的回报尽可能的大。
5、深度强化学习(Deep Reinforcement Learning DRL)
深度强化学习:使用神经网络构建强化学习主体的方法。
使用深度强化学习原因:强化学习面对的情景多种多样,环境、行为、回报很难穷尽,只要有输入就一定有输出,神经网络面对没有见过的情况也能做出选择。
Value-Based Method,将关注点放在回报上:
DQN(Deep Q-Learning Network):用数值Q表示特定状态下采取某行动的收益,将计算Q的工作交给神经网络;
DDQN(Double Deep Q-Learning Network)增加一个对Q值评估相对谨慎的网络,平衡两者之间的看法,防止主体过于激进。
NoiseNet:为了提高探索能力,适当在网络中增加噪音,增加主体的随机性。
RainBow:DQN+DDQN+NoiseNet.
Policy-Based Method,将关注点放在动作的选择上:
Policy Gradient,策略梯度:如果一个动作能使最终回报变大,就增加这个动作出现的概率,反之就减少。
Combination
Actor-Critic:如果我们让选择动作的网络担任主体Actor,关注回报的网络担任老师Critic,为主体的表现打分提供指导。
A3C(Asynchronous Advantage Actor-Critic):使用多个Actor-Critic网络同时探索环境,并将采集到的数据交由主网络更新参数。
6、联邦学习
二人同心,其利断金。团结就是力量,机器学习同样如此,数据越多,训练出的模型效果越好,所以将大家的数据放在一起使用,每个人都能得到更好的模型。
现实世界中,数据是属于用户的,既不能不作申请的使用它们,还要保护数据的私密性。联邦学习:安全高效的实现数据合作。
横向联邦学习(Horizontal Federated Learning)或特征对对齐的联邦学习(Feature-Aligned Federated Learning):参与者们业务相似,数据的特征重叠多,样本重叠少(比如不同地区的两家银行),就可以通过上传参数,在服务器中聚合更新模型,再将最新的参数下放完成模型效果的提升。
纵向联邦学习(Vertical Federated Learning)或样本对对齐的联邦学习(Sample-Aligned Federated Learning):参与者的数据中样本重叠多,特征重叠少(比如同一地区的银行和电商),就需要先将样本对齐,由于不能直接比对,我们需要加密算法的帮助,让参与者在不暴露不重叠样本的情况下,找出相同的样本后联合它们的特征进行学习。
联邦迁移学习:如果样本和特征重合的都不多,希望利用数据提升模型能力,就需要将参与者的模型和数据迁移到同一空间中运算。
目标:解决数据的协作和隐私问题。
7、对比学习
通过对比来了解事物的本质,就是利用数据间的相关性去学习事物本质的一种方法。
对比学习是一种自监督学习方法,用于在没有标签的情况下,通过让模型学习哪些数据点相似或不同来学习数据集的一般特征。
举例:有两只猫和一只狗,即使没有人告诉你它们是“猫”和“狗”,你仍可能会意识到,与狗相比,这两只猫看起来很相似。
print('要天天开心呀')![YOLOv8的训练、验证、预测及导出[目标检测实践篇]](https://img-blog.csdnimg.cn/direct/71584cb1e2cd435eb305f88ba7737ca1.png)