什么样的事情最有价值?难且正确的事情。把 1B 级别的大模型优化到和 200M级别模型相同水平的 RTF 同时 WER 维持代差,难道不是一件该令人亢奋的事情吗?
-- 向前看,别回头
在两个月前的年度总结中,WeNet 社区已经开始向着更“大”更“强”迈进,去全面拥抱语音大模型的无限未来。然而,横在语音大模型面前的还有两座必须翻越的山峰: 训练效率 和 推理效率。
经过 2023 年下半年的努力,WeNet 已经翻越了第一座山峰,达成了训练平权,将 1.5B 级别语音大模型(Whisper, etc)的训练门槛降到了 8 张 3090 (24GB) 10~20h 内以全量参数更新的方式跑完 1.5B 模型在 aishell 上的 40 轮训练。而两个月之后的今天,我们将发起向第二座山峰冲锋的号角,走出一条迈向语音大模型的推理平权之路。
1. 语音大模型的阿喀琉斯之踵
Scale up 已经在无数领域被证明其正确性,然而一个 1B 级别的“大”模型虽然可以做到性能大幅超越 200M “小”模型,但是 RTF 却会成倍增加,让语音大模型难免有些食之无味,弃之可惜。
常见的 RTF 优化手段,如量化,剪枝,蒸馏等,固然会给大模型推理带来一些收益,但是这些仍然难以抹平“大”和“小”之间的效率差异,更不用说还存在着精度和速度之间的 trade-off,因此,我们需要从源头处就做出改变,用推理效率反过来指导模型训练,用一个新的架构尝试解决上述的死局。
2. U2++ MoE
(https://arxiv.org/pdf/2404.16407)
为了解决语音大模型的推理效率问题,同时尽可能地减少掉点,我们探索了 MoE[1]技术,将其用应用到我们现有的 U2++ 框架中,在16万小时的数据上验证了其有效性:
we prove that MoE-1B model can achieve Dense-1B level accuracy with Dense-225M level inference cost
当然,还有必不可少的:
Streaming capability
3. 相关工作
U2++ MoE 并不是第一个将 MoE 引入到语音识别这项任务的,早在 2021 年,腾讯 AI Lab 的研究员们就已经探索出 SpeechMoE[2](以及后续的一系列工作),谷歌[3]、网易[4]等也在最近一两年内相继跟进。然而,这些工作无一例外,都是从提升多语言/多方言/中英混等的识别性能为出发点来使用 MoE。此外还有快手[5]的工作,尝试使用 MoE + Layer reuse 减少模型参数量(但是计算量并没有减少,因此 RTF 预期持平)。
那么,U2++ MoE 的出发点是什么?我们希望循着 scaling law 探索边界的同时能加速 scaling law 的落地。
我们即不关心如何在现有数据下提升 多语言/多方言/中英混 的性能,也不关心如何减少参数量,相反,我们认为解决 多语言/多方言/中英混 的问题,scale up 数据在现阶段比任何雕花都是更有效的手段,而减少参数量则是完全和 scaling law 背道而驰。
不同的出发点显然会让动作的执行出现差异,其中最明显的便是使用上的便捷性。
-
与上述所有工作相比,我们不使用任何额外的loss(balance loss, etc)。我们甚至想argue 一下,balance loss 是用来解决 文本 token 被分发到专家时的负载不均问题,文本 token 天然是离散的,连续两个token之间是不具有相似性的,做出“文本 tokens 应当被均匀地分给所有专家”的假设是合理的。但是这个假设对语音帧构成的 tokens 是否合理有待商榷,毕竟,相连语音帧之间具有极高的相似性,我们为什么要强制地把这些具有相似性的帧 token 打散到不同的专家呢?当然,我们这里的argue也只是打打嘴炮,并没有做实际的消融和对比,WeNet 的一贯风格是简单至上,Keep it simple, Keep it stupid。
-
与 SpeechMoE[2], 网易[4] 相比,我们不使用任何额外的 embedding network (语言emb,方言emb,etc) 。还是那句话,出发点不一样,动作执行会不一样,对于多语种问题,scale up 数据会是更经济环保+有效的手段,Keep it simple, Keep it stupid。
-
与 谷歌[3] 相比,我们证明了 MoE 可以用于且有益于流式模型。谷歌也曾尝试过在流式 encoder 中引入 MoE,但是失败了(见 [3] 中 section 5.1.1, paragraph 2, first sentence),而我们在 U2++ 框架中引入 MoE 后,流式问题则是一发入魂,丝滑无比,不需要堆砌任何额外的 trick,简单的 MoE + 简单的 U2++, 非流式和流式两者兼顾,Keep it simple, Keep it stupid。
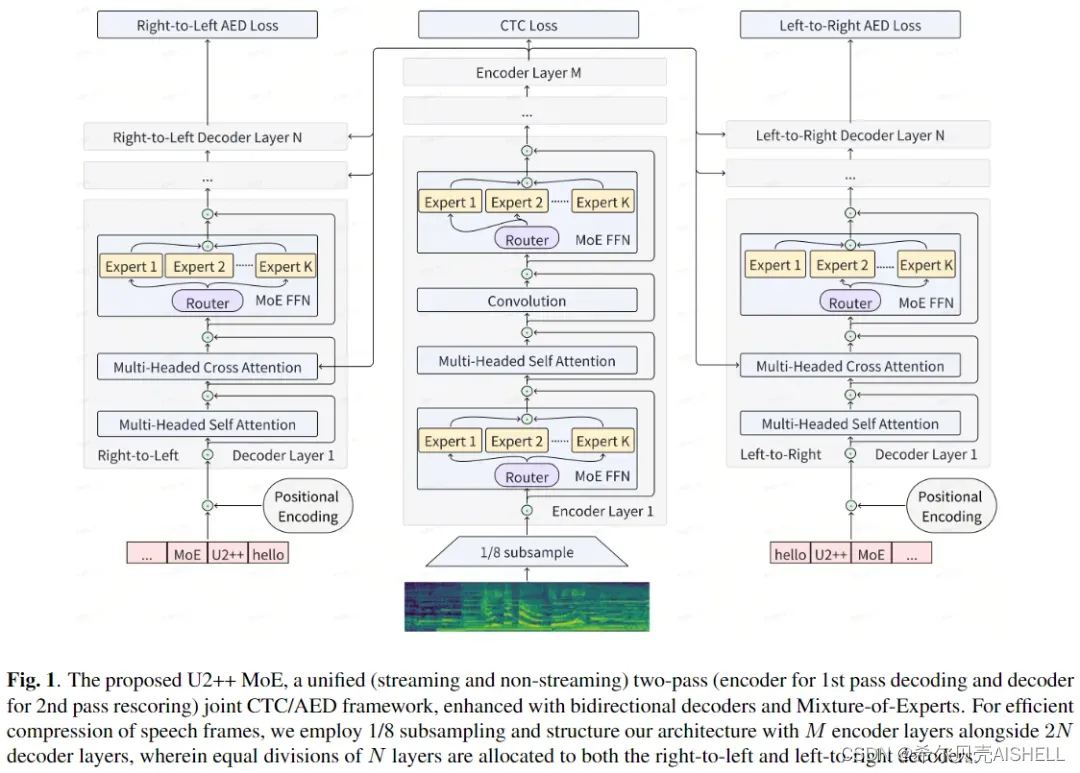
U2++ MoE 是如此的简单,甚至简单到令人尴尬,我们用一句话就可以描述 U2++ MoE 的使用方法和功效:
只需要将你原来模型yaml配置中的原始 FFN 修改为 MoE,其他的什么都不用动,重新硬 train 一发,你就有希望获得 4X 大小模型的 WER 和与当前baseline 相近的 RTF
Overall, Keep it simple, Keep it stupid
实验结果
我们在自己内部的16万小时数据上基于如下三个模型做了对比实验(其中 M 表示 encoder 层数,N 表示 decoder 层数):
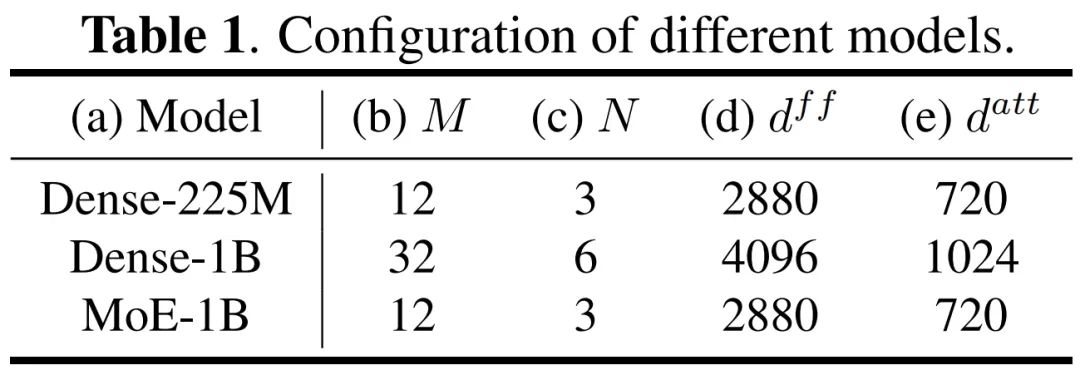
实验结果显示:
-
在相同的训练steps(236k steps)下,对比 (b) (d) (e) 列,MoE-1B (3.93) 模型会略差于 Dense-1B (3.72) 模型,但是两者都是远远超越了 Dense-225M (4.50)。
-
在相同的训练时间(25.9 days)下,对比 (c) (d) (f) 列,MoE-1B (3.80) 和 Dense-1B (3.72) 差距进一步缩小,两者相比 Dense-225M 模型仍有 10% 的相对提升。
这两组对比的结论向我们更进一步地展示了 The power of Scaling Law。不管你是固定训练步数,还是固定整体的训练计算资源(训练天数),更大的模型都是比更小的模型更 optimal 的选择(在不考虑RTF的前提下)。
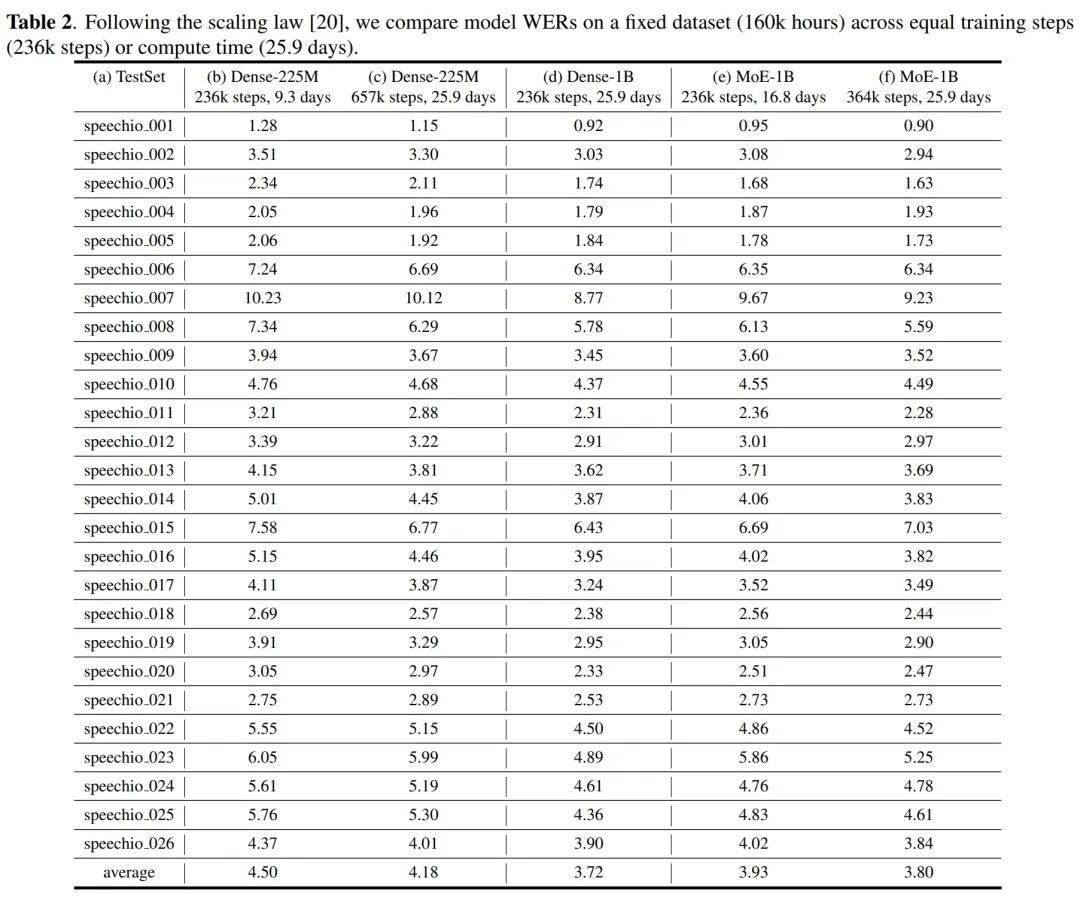
接下来是 RTF 的对比,我们看到,不管是 ctc greedy 解码,亦或是 rescore 解码,MoE-1B 模型整体上还是和 Dense-225M 模型在同一个量级,两者相比 Dense-1B 模型有成倍的降低。

上述结果均为非流式(MoE-1B, etc)的结果,对于流式模型(U2++-MoE-1B, etc),我们是在非流式模型的基础上,进一步进行的流式微调,结果如下表所示,在流式上,我们可以得到和非流式相同的结论:
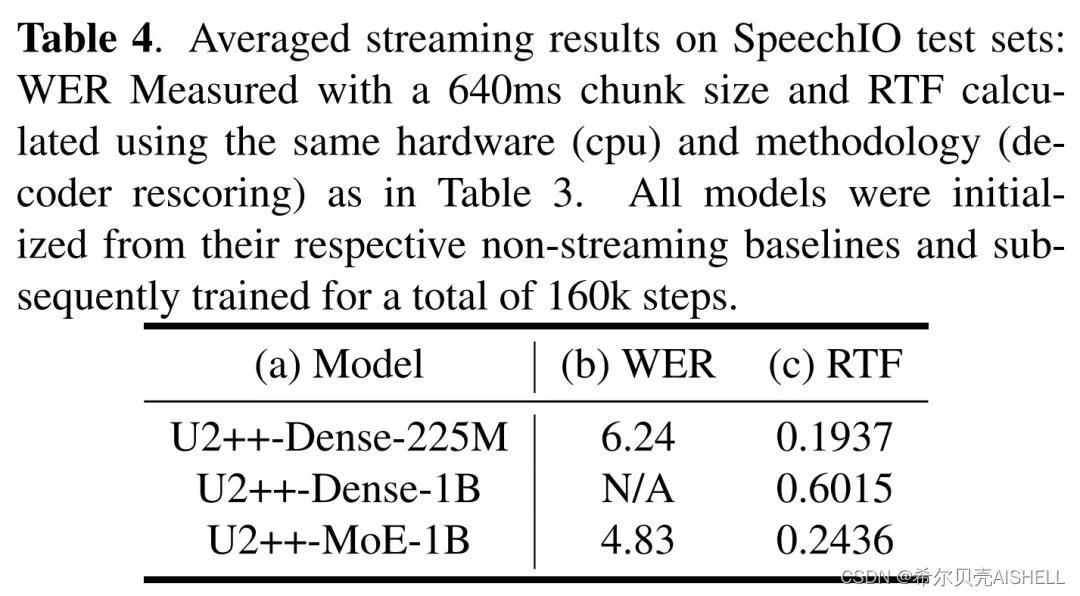
(注:这里没有U2++-Dense-1B的 WER 结果是因为模型会经常 crash,走几步就是 Loss Spike,训练很难进行下去,加上这个 RTF 已经没有实际部署的可行性,遂罢)
Towards Next Generation of ASR Backbone ?
大多数人可能会和我有一样的疑问,为什么 SpeechMoE 早在三年前(2021年)就已经有了,但是时至今日,似乎还没有成为主流的 ASR Backbone?我想,制约其普及的关键因素可能是训练效率。
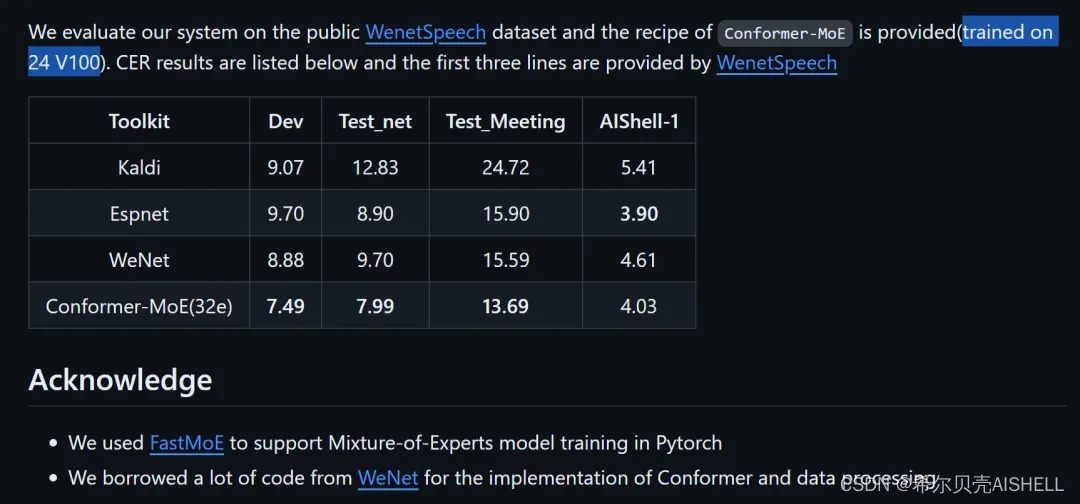
在上述提及的相关工作中,除了财大气粗的谷歌,其余工作要么是在小模型上做 MoE,要么需要引入额外的训练库 FastMoE 和 较多的训练资源来训大的模型。以 SpeechMoE 为例,为了在 WenetSpeech 上训练 1.37B 的 Conformer-MoE(32e),不仅需要在 WeNet 代码基础上额外整合 FastMoE,还动用了 24 张 V100 的训练资源(训练天数未知),门槛相对较高,不是所有人都玩得起。而 WeNet 在越过了训练平权的山峰后,根据 Wenetspeech上微调 1.5B Whisper的结果,这个门槛如今已降到 8 张 3090 + 5天时间,而 MoE 模型的训练则会更快。
旧时王谢堂前燕,飞入寻常百姓家,这,就是语音大模型的平权。
公平,公平,还是tmd公平。
One More Thing
把 1B 级别的大模型优化到和 200M 级别模型相同 level 的 RTF 同时性能维持代差,我们吹的牛皮实现了。
枪有了,还缺子弹。
Scaling Law 不仅仅是 scale 参数量,还包括 scale 数据量,我们的下一站,是 WenetSpeech 2.0, 既授人以鱼,也会授人以渔。
在 WenetSpeech 2.0 中,我们开源的数据量,将会有数量级的提升,而 WenetSpeech 2.0 也将不再单单服务于 ASR,会同时照顾 TTS 的需求。我们都知道,现在的 TTS 正处于日新月异的变革之中,然而其中万变不离其宗的,还是数据,idea is cheap,data is the king。

参考资料
[1]
Noam Shazeer, Azalia Mirhoseini, Krzysztof Maziarz, Andy Davis, Quoc V. Le, Geoffrey E. Hinton, and Jeff Dean, Outrageously large neural networks: The sparsely-gated mixture-of-experts layer, in 5th International Conference on Learning Representations, ICLR 2017, Toulon, France, April 24-26, 2017, Conference Track Proceedings. 2017, OpenReview.net.: https://arxiv.org/abs/1701.06538
[2]
You Z, Feng S, Su D, et al. Speechmoe: Scaling to large acoustic models with dynamic routing mixture of experts[J]. arXiv preprint arXiv:2105.03036, 2021.: https://arxiv.org/abs/2105.03036
[3]
Hu K, Li B, Sainath T N, et al. Mixture-of-expert conformer for streaming multilingual ASR[J]. arXiv preprint arXiv:2305.15663, 2023.: https://arxiv.org/abs/2305.15663
[4]
Wang W, Ma G, Li Y, et al. Language-routing mixture of experts for multilingual and code-switching speech recognition[J]. arXiv preprint arXiv:2307.05956, 2023.: https://arxiv.org/abs/2307.05956
[5]
Bai Y, Li J, Han W, et al. Parameter-Efficient Conformers via Sharing Sparsely-Gated Experts for End-to-End Speech Recognition[J]. arXiv preprint arXiv:2209.08326, 2022.: https://arxiv.org/abs/2209.08326