目录
10.1激活函数作用:
10.2 为什么激活函数都是非线性的
10.3 常见激活函数的优缺点及其取值范围
10.4 激活函数问题的汇总
10.4.1 Sigmoid的缺点,以及如何解决
10.4.2 ReLU在零点可导吗,如何进行反向传播
10.4.3 Softmax溢出怎么处理
10.4.4 怎么理解ReLU负半区间也是非线性激活函数
10.4.5 ReLU函数的特点
10.5 如何选择激活函数
10.6 激活函数有哪些性质

欢迎大家订阅我的专栏一起学习共同进步,主要针对25届应届毕业生
祝大家早日拿到offer! let's go
🚀🚀🚀http://t.csdnimg.cn/dfcH3🚀🚀🚀
10.1激活函数作用:
- 引入非线性性:神经网络的每一层都是由线性变换(如矩阵相乘)和激活函数组成。如果没有激活函数,多层神经网络就会退化成单个线性变换,无法学习复杂的非线性关系。激活函数的非线性特性使得神经网络可以学习和表示更加复杂的函数。
- 映射到合适的范围:不同的激活函数可以将神经网络的输出映射到不同的范围内。例如,sigmoid 函数将输出映射到 (0, 1) 区间内,tanh 函数将输出映射到 (-1, 1) 区间内,ReLU 函数将负数映射为 0,而保持正数不变。这样的映射可以使得网络的输出符合特定的要求,例如在分类任务中输出概率值。
- 提供非线性导数:在反向传播算法中,梯度下降法用于调整神经网络中的参数以最小化损失函数。激活函数的非线性性质使得网络的损失函数对参数的导数不为零,从而使得梯度下降算法能够进行有效的参数更新。
- 增加网络的表达能力:通过合适选择激活函数,可以增加神经网络的表达能力,使其能够更好地适应不同类型的数据和任务。
10.2 为什么激活函数都是非线性的
假若网络中全是线性部件,那么线性的组合还是线性,与单独一个线性分类器无异。做不到用非线性来逼近任意函数。使用非线性激活函数 ,使网络更加强大,可以学习复杂的事物,表示输入输出之间非线性的复杂的任意函数映射。使用非线性激活函数,能够从输入输出之间生成非线性映射。
10.3 常见激活函数的优缺点及其取值范围
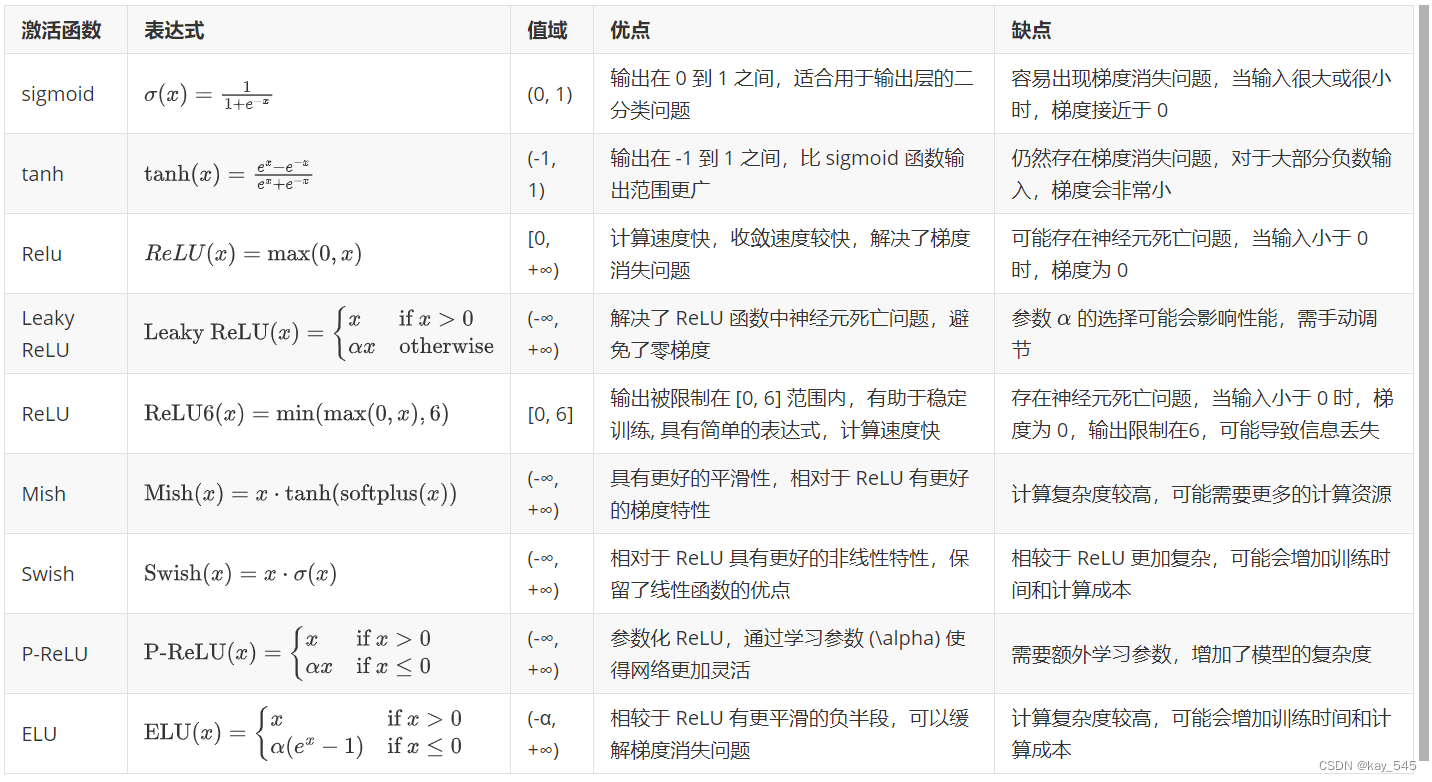
| 激活函数 | 表达式 | 值域 | 优点 | 缺点 |
| sigmoid | σx=11+e-x | (0, 1) | 输出在 0 到 1 之间,适合用于输出层的二分类问题 | 容易出现梯度消失问题,当输入很大或很小时,梯度接近于 0 |
| tanh | tanhx=ex-e-xex+e-x | (-1, 1) | 输出在 -1 到 1 之间,比 sigmoid 函数输出范围更广 | 仍然存在梯度消失问题,对于大部分负数输入,梯度会非常小 |
| Relu | ReLUx=max0,x | [0, +∞) | 计算速度快,收敛速度较快,解决了梯度消失问题 | 可能存在神经元死亡问题,当输入小于 0 时,梯度为 0 |
| Leaky ReLU | Leaky ReLUx=xif x>0αxotherwise | (-∞, +∞) | 解决了 ReLU 函数中神经元死亡问题,避免了零梯度 | 参数 α的选择可能会影响性能,需手动调节 |
| ReLU | ReLU6x=minmax0,x,6 | [0, 6] | 输出被限制在 [0, 6] 范围内,有助于稳定训练, 具有简单的表达式,计算速度快 | 存在神经元死亡问题,当输入小于 0 时,梯度为 0,输出限制在6,可能导致信息丢失 |
| Mish | Mishx=x⋅tanhsoftplusx | (-∞, +∞) | 具有更好的平滑性,相对于 ReLU 有更好的梯度特性 | 计算复杂度较高,可能需要更多的计算资源 |
| Swish | Swishx=x⋅σx | (-∞, +∞) | 相对于 ReLU 具有更好的非线性特性,保留了线性函数的优点 | 相较于 ReLU 更加复杂,可能会增加训练时间和计算成本 |
| P-ReLU | P-ReLUx=xif x>0αxif x≤0 | (-∞, +∞) | 参数化 ReLU,通过学习参数 (\alpha) 使得网络更加灵活 | 需要额外学习参数,增加了模型的复杂度 |
| ELU | ELUx=xif x>0αex-1if x≤0 | (-α, +∞) | 相较于 ReLU 有更平滑的负半段,可以缓解梯度消失问题 | 计算复杂度较高,可能会增加训练时间和计算成本 |
公式乱码,在下图中显示

10.4 激活函数问题的汇总
10.4.1 Sigmoid的缺点,以及如何解决
Sigmoid型函数的输出存在均值不为0的情况,并且存在梯度消失与梯度爆炸的问题。(因为函数本身的表达式导致的梯度消失/爆炸)
解决办法:
1.在深层网络中使用其他激活函数替代。如ReLU(x)、Leaky ReLU(x)等
2.在分类问题中,Sigmoid做激活函数时,使用交叉熵损失函数替代均方误差损失函数。
3.采用正确的权重初始化方法。
4.加入BN层。
5.分层训练权重。
10.4.2 ReLU在零点可导吗,如何进行反向传播
不可导。人为将梯度规定为0。当输入小于等于 0 时,将梯度传递到下一层的神经元时,梯度将变为零,从而无法更新参数。这就是所谓的“神经元死亡”问题。
解决办法
Leaky ReLU
10.4.3 Softmax溢出怎么处理
解决办法:https://www.cnblogs.com/guoyaohua/p/8900683.html
10.4.4 怎么理解ReLU负半区间也是非线性激活函数
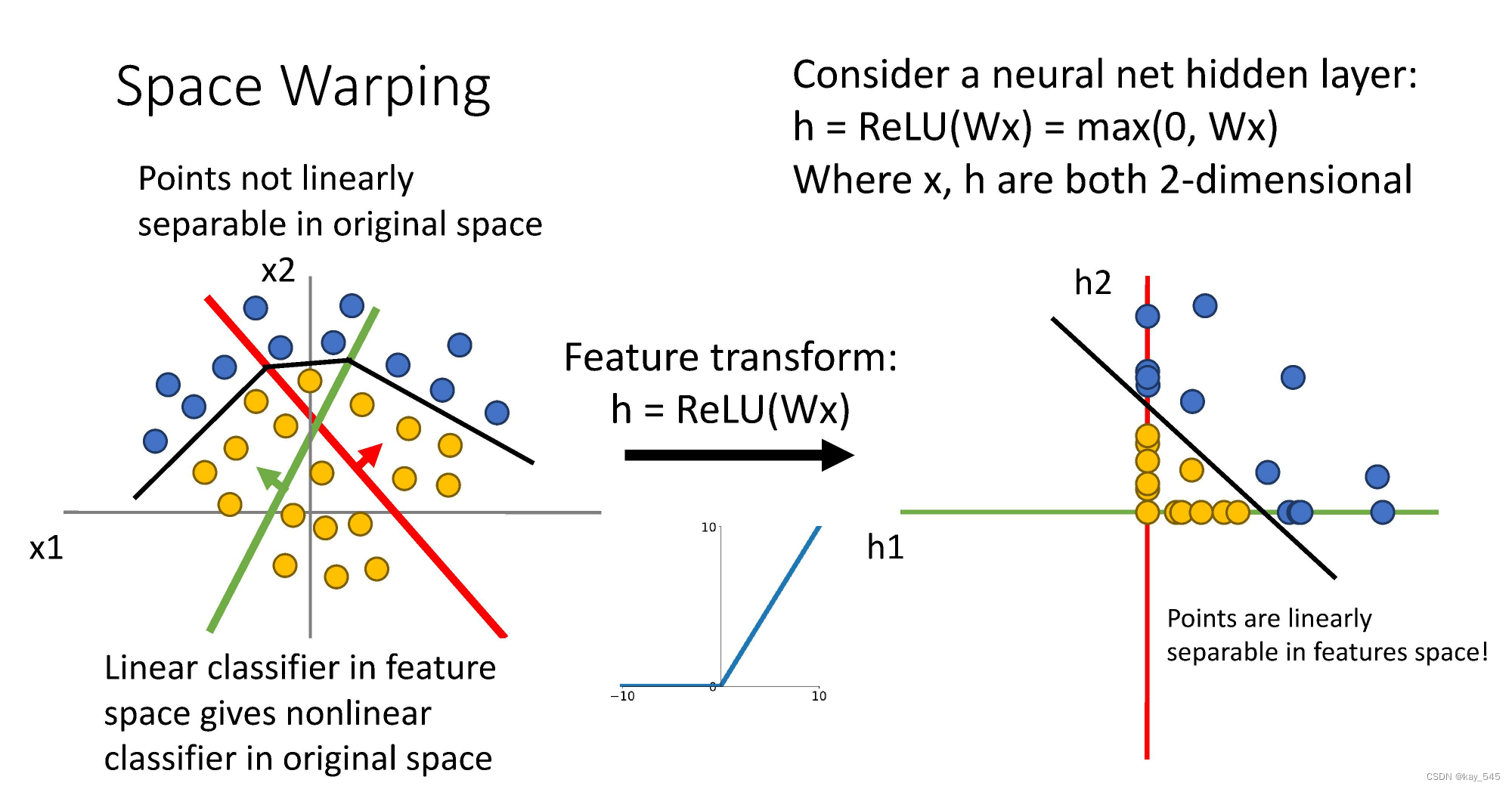
- 单侧抑制;ReLU 函数从图像上看,是一个分段线性函数,把所有的负值都变为 0,而正值不变,这样就成为单侧抑制。因为有了这单侧抑制,才使得神经网络中的神经元也具有了稀疏激活性。
- 稀疏激活性:从信号方面,神经元同时只对输入信号的少部分选择性响应,大量信号被刻意屏蔽,这样可以提高学习精度,更好更快地提取稀疏特征。当 x<0 时,ReLU 硬饱和,而当 x>0 时,则不存在饱和问题。ReLU 能够在 x>0 时保持梯度不衰减,从而缓解梯度消失问题
10.4.5 ReLU函数的特点
- 在区间变动很大的情况下,ReLU激活函数的导数都会远大于 0,使用 ReLu 激活函数神经网络通常会比使用Sigmoid 或者 tanh 激活函数学习的更快
- Sigmoid 和 tanh 函数的导数在正负饱和区的梯度都会接近于 0,会造成梯度弥散,而 ReLU和Leaky ReLU函数大于 0 部分都为常数,不会产生梯度弥散现象。
- ReLU 进入负半区的时候,梯度为 0,神经元此时不会训练,产生所谓的稀疏性,而 Leaky ReLu 不会产生这个问题。
10.5 如何选择激活函数
- 如果输出是 0、1 值(二分类问题),则输出层选择 Sigmoid 函数,然后其它的所有单元都选择 ReLU函数。
- 如果在隐藏层上不确定使用哪个激活函数,那么通常会使用 ReLU激活函数。有时,也会使用 tanh 激活函数,但 Relu 的一个优点是:当是负值的时候,导数等于0。
- Sigmoid 激活函数,除了输出层是一个二分类问题基本不会用它。
- tanh 激活函数,tanh 是非常优秀的,几乎适合所有场合。
- ReLU激活函数,最常用的默认函数,如果不确定用哪个激活函数,就使用 ReLu 或者 Leaky ReLu,再去尝试其他的激活函数。
- 如果遇到了一些死的神经元,我们可以使用 Leaky ReLU 函数。
10.6 激活函数有哪些性质
- 非线性。
- 可微性。 当优化方法是基于梯度的时候,就体现了该性质。
- 单调性。当激活函数是单调的时候,单层网络能够保证是凸函数。
- f ( x ) ≈ x f(x)≈xf(x)≈x。 当激活函数满足这个性质的时候,如果参数的初始化是随机的较小值,那么神经网络的训练将会很高效;如果不满足这个性质,那么就需要详细地设置初始值;
- 输出值的范围。当激活函数输出值是有限的时候,基于梯度的优化方法会更加稳定,因为特征的表示受有限权值的影响更显著;当激活函数的输出是无限的时候,模型的训练会更加高效,不过在这种情况下,一般需要更小的学习率。

![血的教训之虚拟机重装[包含一系列虚拟机,c++,python,miniob配置]](https://img-blog.csdnimg.cn/direct/e8ab1e837fda4066ab97a9e3e0bef301.png)