文章目录
- yaml 三大组件的方式
- 交互流程
- hive 使用
- 安装mysql(hadoop03主机)
- 出现错误
- 解决方式
- 临时密码
- 卸载mysql (hadoop02主机)
- 卸载mysql(hadoop01主机执行)
- 安装hive
- 上传文件
- 解压
- 解决版本差异
- 修改hive-env.sh
- 修改 hive-site.xml
- 上传驱动包
- 初始化元数据
- 在hdfs 创建hive 存储目录
- 启动hive的方式
- 远程连接hive
- 连接 hive
- hive 默认存储路径
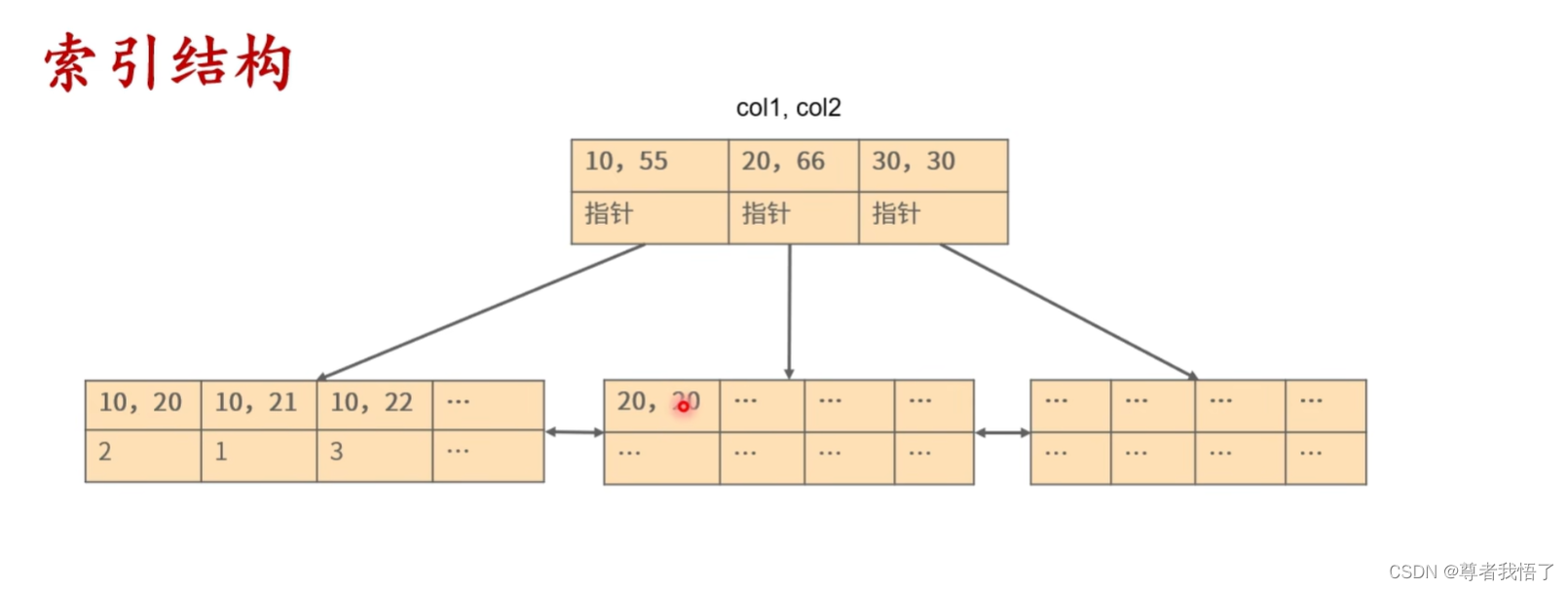
yaml 三大组件的方式
resoureManger
负责进行资源分配
nodeManger
一台机器一个负责管理本地资源信息
这个俩个属于(node,resoure)物理层组件
applicatiMange
负责程序运行和监控
这个属于一个app 组件信息
交互流程
交互流程有点高级了,有点看不懂了
hive 使用
安装mysql(hadoop03主机)
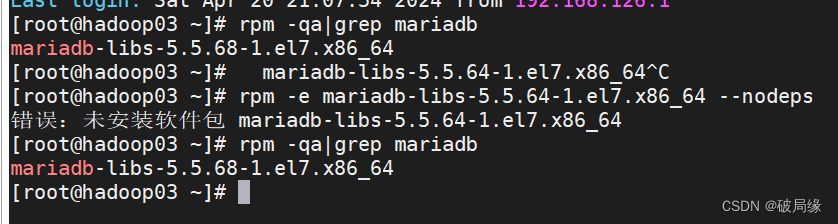
查看mariabdb文件
rpm -qa|grep mariadb
卸载mariaba 文件
rpm -e mariadb-libs-5.5.64-1.el7.x86_64 --nodeps
查看mariadb文件
rpm -qa|grep mariadb
创建文件夹
mkdir -p /export/software/mysql
上传文件
到 /export/software/mysql/
执行安装
yum -y install libaio
解压文件
tar xvf mysql-5.7.29-1.el7.x86_64.rpm-bundle.tar
安装
rpm -ivh mysql-community-common-5.7.29-1.el7.x86_64.rpm mysql-community-libs-5.7.29-1.el7.x86_64.rpm mysql-community-client-5.7.29-1.el7.x86_64.rpm mysql-community-server-5.7.29-1.el7.x86_64.rpm
出现错误

解决方式
rpm -e mariadb-libs --nodeps
数据库初始化
mysqld --initialize
更改属性组
chown mysql:mysql /var/lib/mysql -R
启动mysql
systemctl start mysqld.service
查看临时生成的密码
cat /var/log/mysqld.log
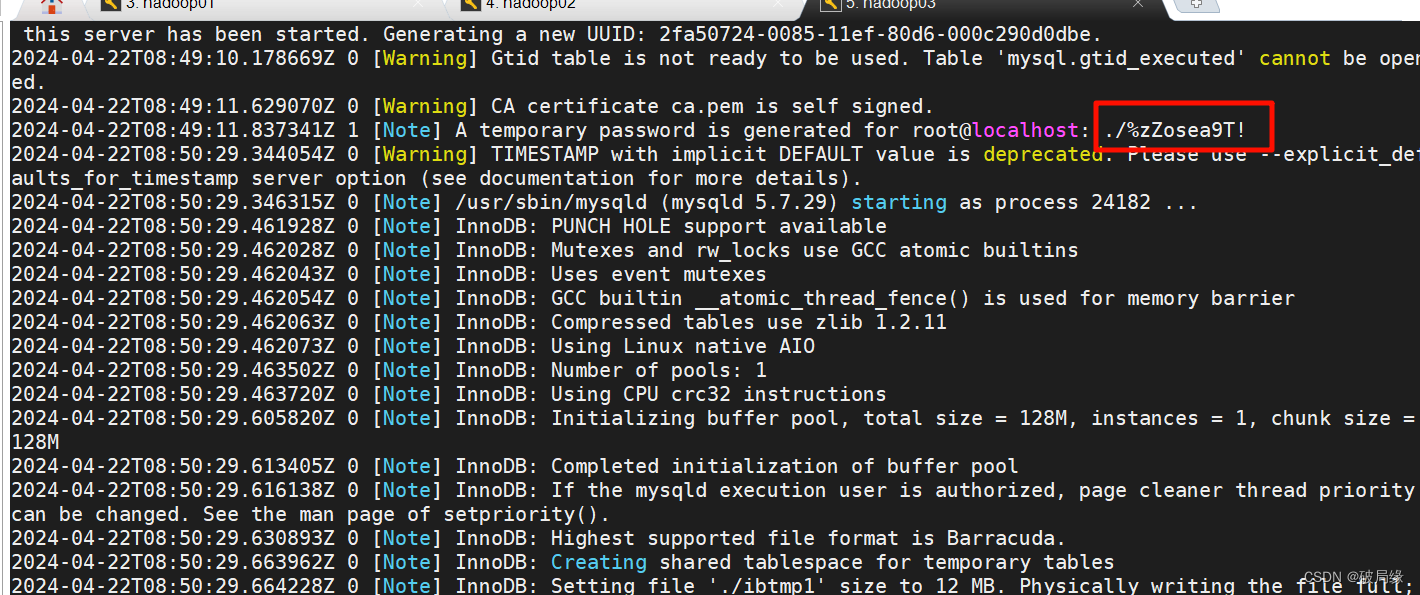
临时密码
./%zZosea9T!
连接mysql
mysql -u root -p
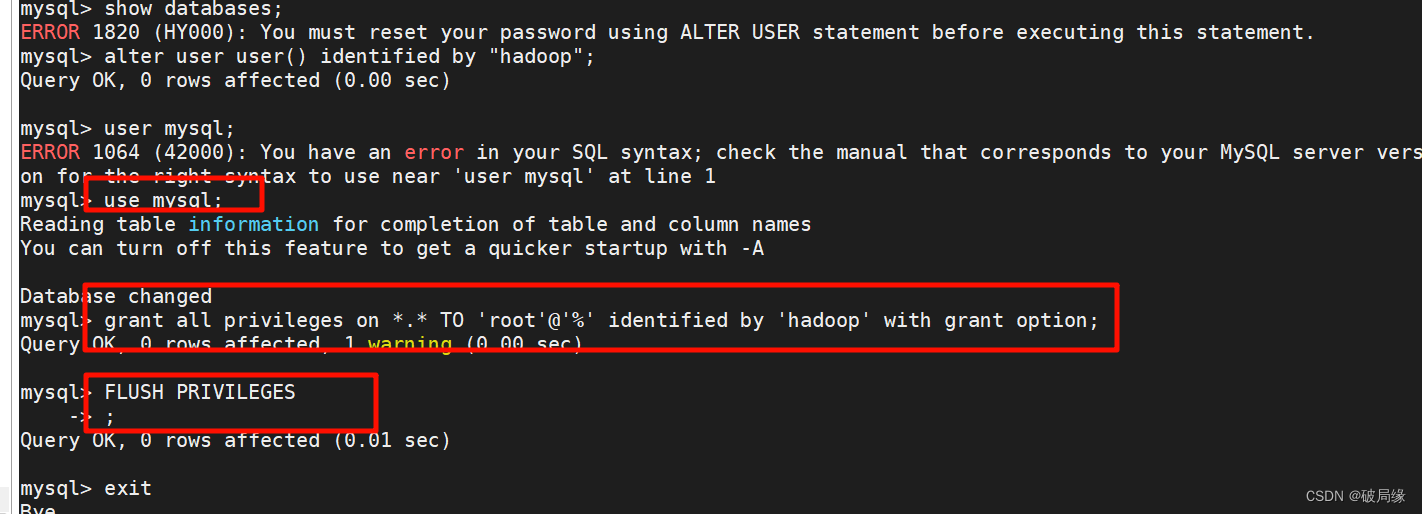
更新密码
alter user user() identified by "hadoop";
授权
use mysql;
GRANT ALL PRIVILEGES ON *.* TO 'root'@'%' IDENTIFIED BY 'hadoop' WITH GRANT OPTION;
FLUSH PRIVILEGES;
mysql 停止 启动 状态
systemctl stop mysqldsystemctl status mysqldsystemctl start mysqld
开机启动
systemctl enable mysqld
查看是否成功开机自启动
systemctl list-unit-files | grep mysqld
卸载mysql (hadoop02主机)
查看mysql文件
rpm -qa | grep -i mysql
卸载mysql信息
yum remove mysql-community-libs-5.7.29-1.el7.x86_64 mysql-community-common-5.7.29-1.el7.x86_64 mysql-community-client-5.7.29-1.el7.x86_64 mysql-community-server-5.7.29-1.el7.x86_64
卸载mysql(hadoop01主机执行)
查询文件
find / -name mysql
删除mysql目录
rm -rf /usr/lib64/mysql
rm -rf /usr/share/mysql删除默认配置和日志
rm -rf /etc/my.cnf
rm -rf /var/log/mysqld.log
安装hive
上传文件
解压
tar zxvf apache-hive-3.1.2-bin.tar.gz
解决版本差异
cd apache-hive-3.1.2-bin/
rm -rf lib/guava-19.0.jar
cp /export/server/hadoop-3.3.0/share/hadoop/common/lib/guava-27.0-jre.jar ./lib/
修改hive-env.sh
cd conf
mv hive-env.sh.template hive-env.sh
vim hive-env.sh
export HADOOP_HOME=/export/server/hadoop-3.3.0
export HIVE_CONF_DIR=/export/server/apache-hive-3.1.2-bin/conf
export HIVE_AUX_JARS_PATH=/export/server/apache-hive-3.1.2-bin/lib
修改 hive-site.xml
vim hive-site.xml
添加配置文件信息
<configuration>
<!-- 存储元数据mysql相关配置 -->
<property><name>javax.jdo.option.ConnectionURL</name><value>jdbc:mysql://hadoop03:3306/hive3?createDatabaseIfNotExist=true&useSSL=false&useUnicode=true&characterEncoding=UTF-8</value>
</property><property><name>javax.jdo.option.ConnectionDriverName</name><value>com.mysql.jdbc.Driver</value>
</property><property><name>javax.jdo.option.ConnectionUserName</name><value>root</value>
</property><property><name>javax.jdo.option.ConnectionPassword</name><value>hadoop</value>
</property><!-- H2S运行绑定host -->
<property><name>hive.server2.thrift.bind.host</name><value>hadoop03</value>
</property><!-- 远程模式部署metastore metastore地址 -->
<property><name>hive.metastore.uris</name><value>thrift://hadoop03:9083</value>
</property><!-- 关闭元数据存储授权 -->
<property><name>hive.metastore.event.db.notification.api.auth</name><value>false</value>
</property>
</configuration>上传驱动包
初始化元数据
cd /export/software/apache-hive-3.1.2-bin/bin/schematool -initSchema -dbType mysql -verbos
必须在这个目录下执行

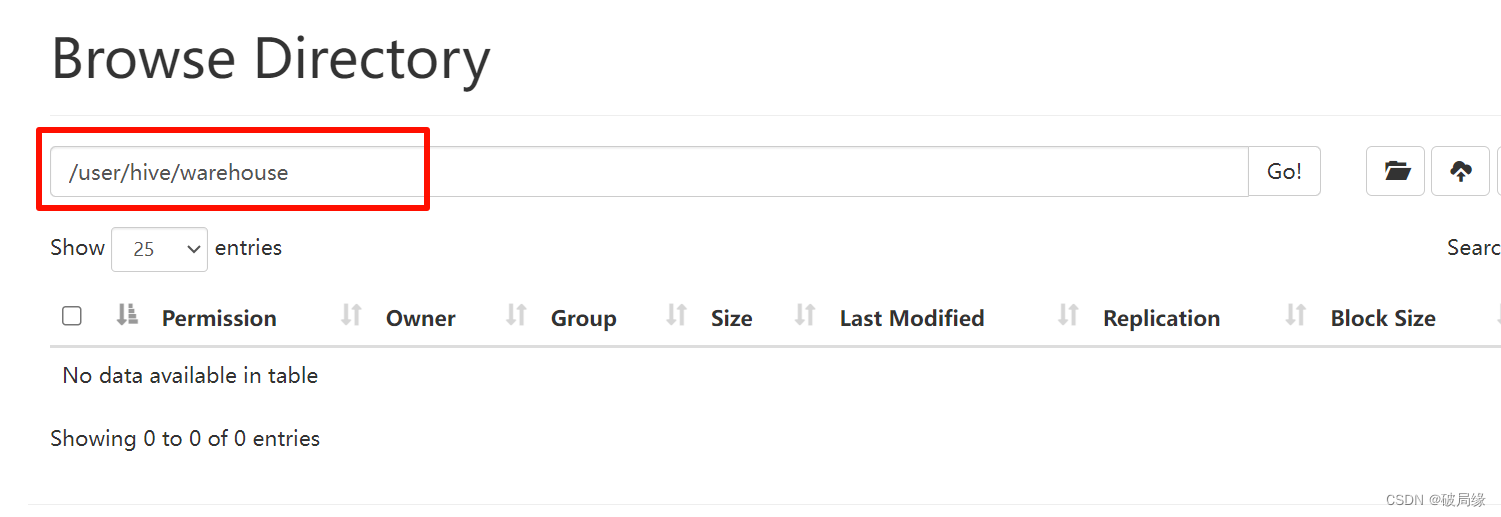
在hdfs 创建hive 存储目录
hadoop fs -mkdir /tmp
hadoop fs -mkdir -p /user/hive/warehouse
hadoop fs -chmod g+w /tmp
hadoop fs -chmod g+w /user/hive/warehouse
我们可以创建一个shell脚步执行命令
启动hive的方式
前台启动的方式
/export/server/apache-hive-3.1.2-bin/bin/hive --service metastore
cltr + c 可以退出前台启动的方式
前台启动开始dbug日志的方式
/export/server/apache-hive-3.1.2-bin/bin/hive --service metastore --hiveconf hive.root.logger=DEBUG,console
后台启动的方式(推荐)
nohup /export/server/apache-hive-3.1.2-bin/bin/hive --service metastore &
beelin 拷贝到node2中的
scp -r /export/server/apache-hive-3.1.2-bin/ hadoop02:/export/server/
刚在遇到了一个小问题
24/04/23 15:36:38 [main]: WARN jdbc.HiveConnection: Failed to connect to hadoop03:10000
Could not open connection to the HS2 server. Please check the server URI and if the URI is correct, then ask the administrator to check the server status.
Error: Could not open client transport with JDBC Uri: jdbc:hive2://hadoop03:10000: java.net.ConnectException: 拒绝连接 (Connection refused) (state=08S01,code=0)
查询到问题说没有启动hive服务的方式我们启动hive服务的方式我们进行测试一下
先杀死hive服务
jps - l -m
-l 输出具体名称
-m 输出具体pid

我们这里就可以找到hive pid重新启动hive的方式
kill -9 pid
这俩必须都需要执行,因为hive在metasore才可以访问数据服务
nohup /export/server/apache-hive-3.1.2-bin/bin/hive --service metastore &
nohup /export/server/apache-hive-3.1.2-bin/bin/hive --service hiveserver2 &
远程连接hive
我们在hadoop03上做的方式把成功的hive拷贝到hadoop01上
scp -r /export/server/apache-hive-3.1.2-bin/ hadoop02:/export/server/
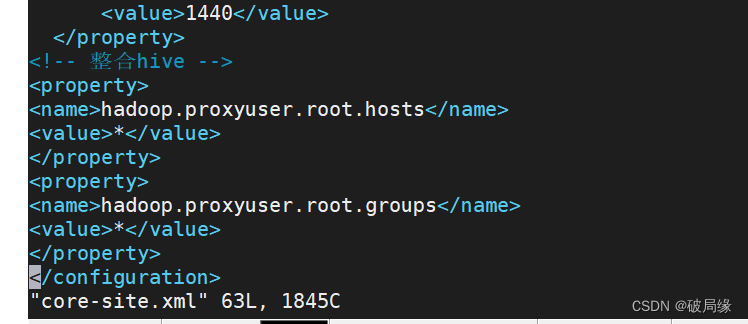
修改配置文件 core-site.xml
<property><name>hadoop.proxyuser.root.hosts</name><value>*</value>
</property>
<property><name>hadoop.proxyuser.root.groups</name><value>*</value>
</property>
连接
/export/server/apache-hive-3.1.2-bin/bin/beeline
beeline> ! connect jdbc:hive2://hadoop03:10000
beeline> root
beeline> 直接回车
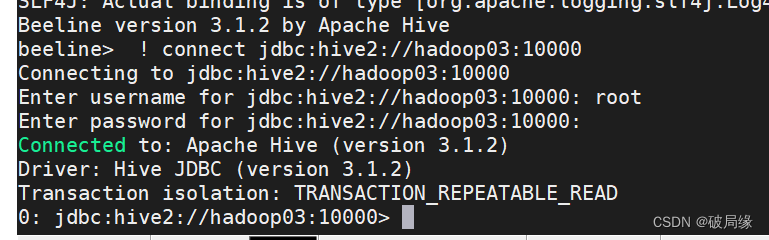
连接 hive
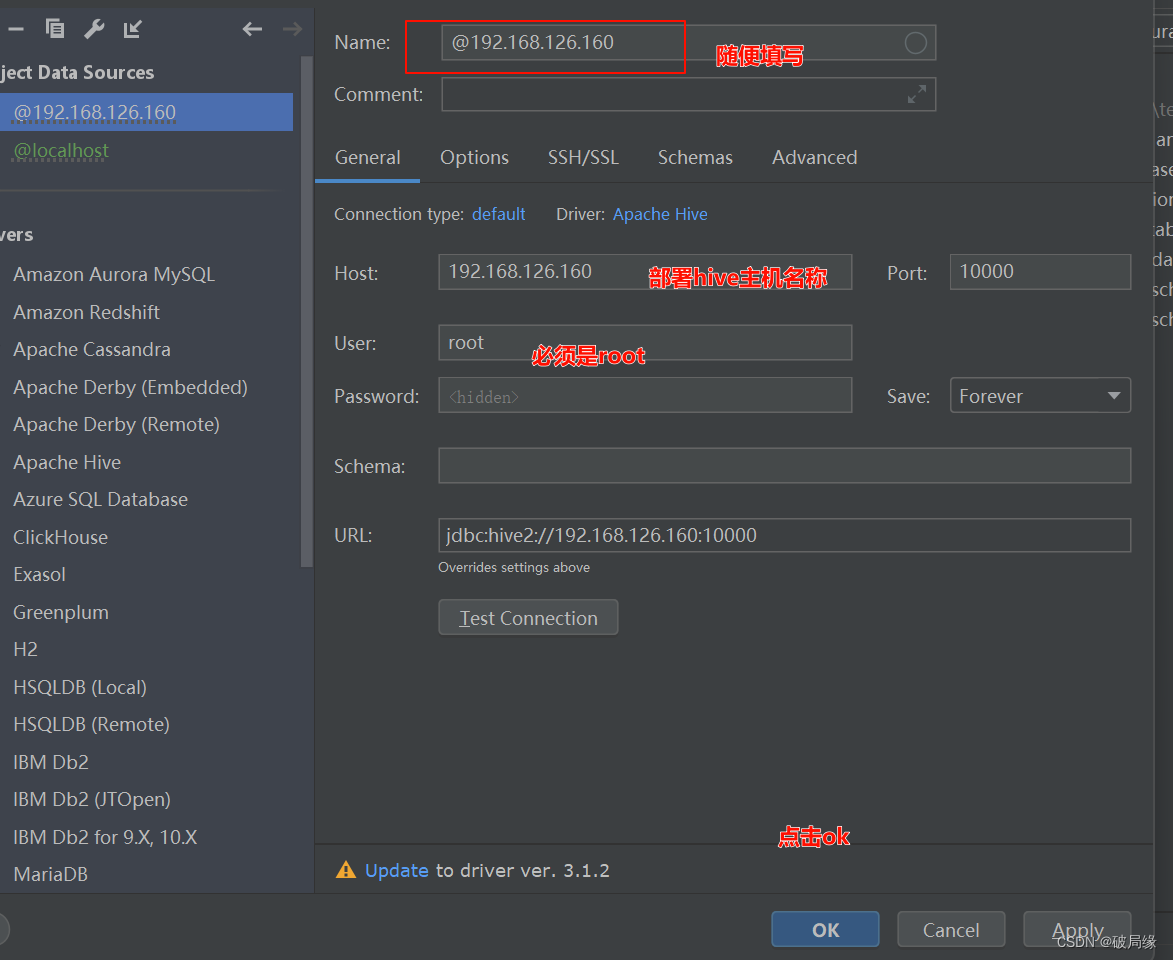
hive 默认存储路径