概述
从GPT-1到GPT-3,OpenAI的模型不断进步,推动了自然语言处理技术的发展。这些模型在处理语言任务方面展现出了强大的能力,包括文本生成、翻译、问答等。
然而,当涉及到面部识别和生物特征估计等任务时,这些基于文本的语言模型可能面临一些挑战。面部识别和生物特征估计通常需要专门的图像处理技术和深度学习模型,这些模型能够从视觉数据中提取和分析复杂的特征。
尽管如此,人工智能领域正在不断探索如何将语言模型与其他类型的模型(如计算机视觉模型)结合起来,以解决多模态问题,即同时涉及文本和图像的任务。例如,一些研究可能正在探索如何利用语言模型来提高面部识别系统的准确性或解释其决策过程。
- 人脸识别:确定图像中的人脸是谁的过程。
- 软生物识别属性估计:估计与个人身份相关但不唯一的特征,如年龄、性别、情绪等。
这些任务的挑战在于:
- 姿势变化:人脸在不同角度和姿态下的外观差异很大。
- 年龄变化:随着时间的推移,人脸的外观会发生变化。
- 光照条件:不同的光照条件会影响面部特征的可见性。
- 面部表情:不同的表情会改变面部的几何结构。
尽管ChatGPT在文本处理方面表现出色,但它并不是专门为图像处理设计的,因此在面部识别和生物特征估计方面可能存在局限性。对于这些任务,通常需要使用专门的深度学习架构,如卷积神经网络(CNNs),它们在图像识别和处理方面经过了优化。
最后,提高技术的透明度和责任感是非常重要的。这意味着需要对人工智能系统的工作原理、它们的决策过程以及可能的偏差和局限性有深入的理解。这有助于建立用户对这些系统的信任,并确保它们以负责任和道德的方式被使用。
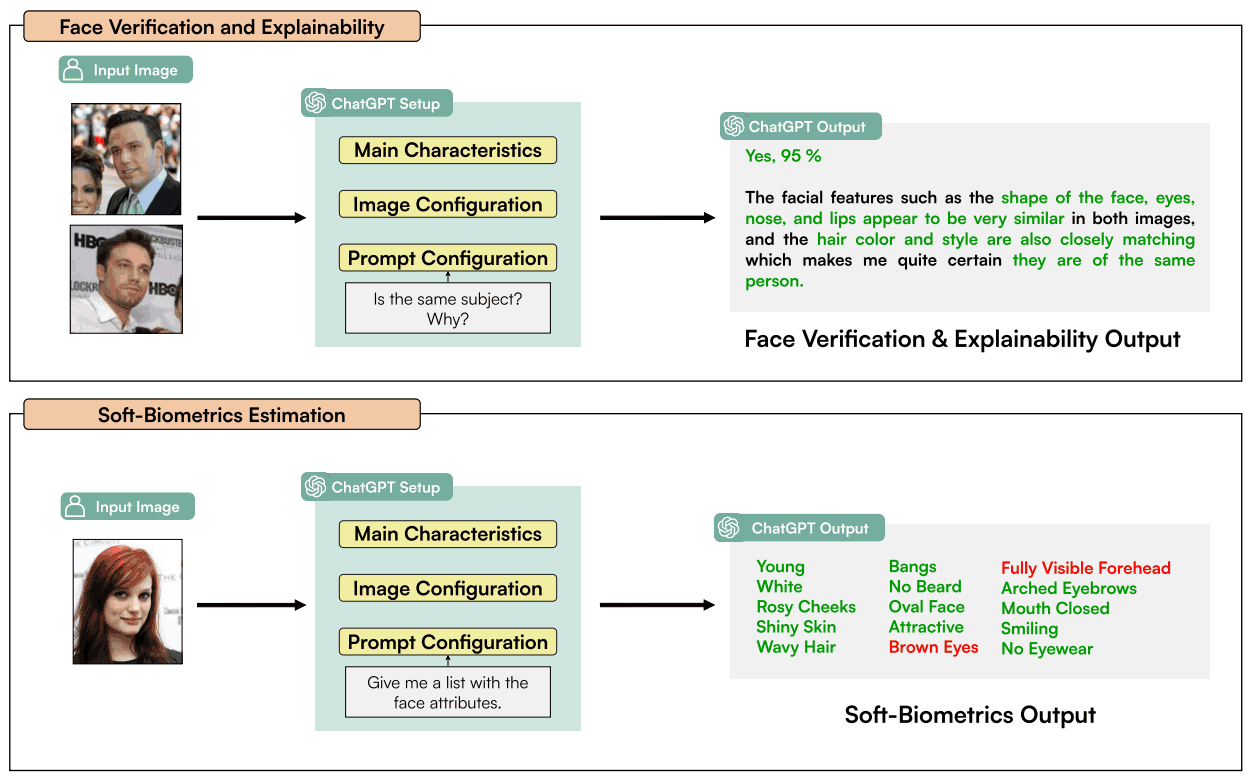
下图概述了本文开展的研究,重点是 ChatGPT 执行人脸识别、软生物识别估计和结果问责等任务的能力。
项目地址:https://github.com/BiDAlab/ChatGPT_FaceBiometrics.git
论文地址:https://arxiv.org/abs/2401.13641
ChatGPT 设置及其在实验中的主要功能
OpenAI 提供了两种主要方式来访问 ChatGPT:一种是通过用户友好的交互式聊天机器人界面,另一种是通过灵活的 API 接口。虽然两者在功能上大致相同,但 API 为开发者提供了一个简洁的界面,使得可以轻松地执行大量基于 Python 的实验。在本文的研究中,我们选择了使用 API,这允许我们更高效地进行实验和数据处理。同时,在项目的早期阶段,我们也利用了聊天机器人界面来快速探索和确定合适的设置。值得注意的是,为了访问 OpenAI 最新的大规模语言模型 GPT-4,需要具备高级订阅,该模型不仅能够处理文本,还能处理图像和其他文件格式,进一步扩展了 OpenAI 产品的使用范围。在实验中,我们设置了每个请求的最大令牌数为 “1,000 个令牌”,并选择了 “高” 级别的图像细节设置,以确保图像处理的准确性。
为了进一步优化 ChatGPT 的使用,我们在实验中测试了几种不同的配置,旨在降低成本和时间开销,同时提升面部生物识别的性能。在图像组成的策略上,我们考虑了两种主要方案。第一种方案是将两张需要进行比较的人脸图像合并为一张单一的图像,如下面的左侧图所示。第二种方案则是将这两张图像排列成一个 4x3 的矩阵格式,如下面的右侧图所示。这两种方法都旨在提高模型处理面部图像的效率和准确性。
(注:由于无法显示图像,上述段落中的“下图(左)”和“下图(右)”是示意性的,实际文本中没有附上图像。)
通过这些优化策略,我们希望在保持成本效率的同时,提升面部生物识别任务的性能,这对于提升 ChatGPT 在相关领域的应用潜力具有重要意义。

其次是提示结构。这是需要分析的最重要方面。首先,人脸识别任务的提示设计侧重于图像的第一种配置情况,即比较图像中的一对人脸时。首先,如下图所示,我们按照 OpenAI 的建议创建了一个详细的提示,要求用户识别两张人脸图像是否为同一个人。然而,由于 ChatGPT 并未正式提供面部识别功能,因此如下图所示,用户的答案被拒绝(蓝色为输入提示,黑色为 ChatGPT 答案)。

因此,本文假定这些回复可能是出于对现实生活中身份隐私的担忧而实施的,并修改了初始提示,以表明这些是人工智能生成的人,如下所示。
使用上述修改过的提示后,ChatGPT 做出了积极的回应。这表明面部图像是否来自同一个人,同时也为做出决定提供了依据。
不过,虽然 “从面部结构、发型和其他可见特征来看,这两张图像似乎是不同的人”,但它也指出 “关于这两张图像是否描绘的是同一个人的结论是推测性的”。可以认为,这妨碍了该系统作为人脸识别任务的输出结果的使用。
随后,论文还试图减少作为输入的信息量,防止系统识别出自己正在执行人脸识别任务。然而,ChatGPT 检测到了这一点,并做出了否定的回应。

我们还尝试限制 ChatGPT 的输出。特别是,我们将答案限制为 "是 "或 “否”,同时限制置信度。

通过使用修改过的提示,ChatGPT 能够对问题提供简洁明了的回答。人脸识别实验中就使用了这一提示。在此基础上,我们还创建了另一个矩阵策略提示。该提示还指定了比较在矩阵中的位置以及每个单元格的引用方式。

本文还探讨了 ChatGPT 在其他面部生物识别任务中的潜在应用。这些应用包括软生物识别估计和结果的可解释性。为了实现这一目标,我们考虑了几种提示。对于面部软生物识别的估算,我们从一般提示开始,看看 ChatGPT 能在多大程度上以高准确度和属性可变性完成这项任务。下图显示了所考虑的提示和 ChatGPT 针对不同人脸图像提供的结果。

为了定量评估 ChatGPT 的性能,我们提出了包括流行的 MAADFace 数据库中考虑的面部属性的提示。这样就能与最先进的方法进行直接比较。接下来,我们将提供一个建议的提示来评估 ChatGPT 估算面部软生物识别的能力。

最后,关于使用 ChatGPT 所做决定的责任问题,我们考虑了与人脸识别任务相同的提示,并增加了最后一个问题,以评估 ChatGPT 做出决定的原因。

实验结果
本文比较了 ArcFace、AdaFace 和 ChatGPT 这三种模型,以衡量人脸识别技术的准确性。其中,ChatGPT 的性能使用两种方法进行验证,即对图像进行整体(4x3)和单独(1x1)评估。在这些模型之间进行比较时,使用余弦距离来测量相似度,并计算出相等错误率(EER)。在 ChatGPT 的情况下,EER 是直接使用其输出的置信度作为自定义指标得出的。
它主要分为两组,涵盖不同的人脸识别场景。一组是应用场景,包括受控环境(LFW)、监控场景(QUIS-CAMPI)和极端条件(TinyFaces)。另一个是突出人脸识别常见挑战的场景,如种族偏见(BUPT)、姿势变化(CFP-FP)、年龄差异(AgeDB)和屏蔽(ROF)。
下表显示了 ChatGPT 和主要人脸验证系统在人脸验证任务中的准确性。ChatGPT 4x3 "指的是在同一提示中进行 12 次人脸比对的图像设置,而 "ChatGPT 1x1 "指的是每次提示只进行一次人脸比对的情况。

下表还显示了 ChatGPT 和文献中流行的人脸识别系统在人脸验证任务中取得的相同错误率(%)。

一般来说,ArcFace(平均准确率 95.44%,EER 6.19%)和 AdaFace(平均准确率 95.80%,EER 5.59%)等最先进的模型显示出更好的整体性能。另一方面,ChatGPT 是为更一般的任务而开发的,因此在人脸识别任务中表现较差。特别是,当图像以矩阵格式呈现时,平均准确率和 EER 分别下降到 66.23% 和 34.96%,而单独比较时,平均准确率和 EER 分别下降到 80.19% 和 21.19%。
对不同数据库的性能分析表明,ChatGPT 的性能在很大程度上取决于图像质量、姿势变化和比较之间的领域差异。例如,在 LFW 数据库中,由于良好的图像质量和一致的姿势,ChatGPT 的性能接近最先进的模型(准确率 93.50%,EER 8.60%)。但是,在监控场景和质量极低的条件下,ChatGPT 的性能明显较低。
在处理种族偏见、姿势、年龄和屏蔽等问题的数据库中也发现了类似的不良表现。这也揭示了 ChatGPT 在不同人口群体之间存在明显的偏差。例如,从下表可以看出,在 BUPT 数据库评估中,不同种族和性别的表现非常不同,白人女性群体的 EER 为 14.94%,而印度女性群体的 EER 为 30.88%。

这些结果表明,虽然 ArcFace 和 AdaFace 等专业人脸识别模型具有很高的准确率,但 ChatGPT 的性能却因图像质量和任务复杂度的不同而存在很大差异。ChatGPT 的偏差问题也是人脸识别技术应用中的一个重要考虑因素。
它还分析了 ChatGPT 如何提高人脸识别任务结果的可解释性。下图显示了针对不同人脸识别数据库中的一些示例提出的提示和 ChatGPT 提供的输出;ChatGPT 的回答分为正确(左列)和错误(右列)。

无论是正确答案还是错误答案,都证明了 ChatGPT 根据图像特征做出合理判断的能力。例如,在大多数情况下,ChatGPT 在面部识别任务中的输出分数与面部毛发或肤色等软性生物识别属性有关。此外,它还显示了专注于眼睛颜色、面部形状或鼻子形状等更详细属性的能力,表明了处理粗细节和细细节的能力。
值得注意的是,尽管 ChatGPT 在预测时考虑了面部表情,但这是一个不应该考虑的可变属性。此外,该模型还能感知图像之间的时间差,并将这一信息纳入预测。
对于错误答案,我们可以看到,即使预测是错误的,ChatGPT 提供的一些描述也准确地描述了图像中的人物。
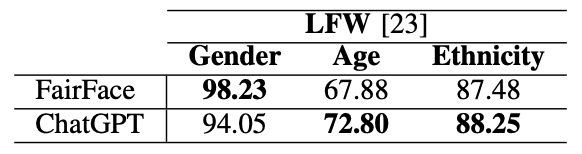
此外,它还显示了在 LFW 和 MAAD-Face 数据库中进行软生物识别估计任务所取得的结果。下表显示了 ChatGPT 在 LFW 数据库中进行软生物识别性别、年龄和种族估计时取得的准确率(%)。
下表显示了 ChatGPT 在 MAAD-Face 数据库中估算 47 种软生物识别属性时达到的准确率(%)。

下图还显示了 ChatGPT 在建议提示中提供的一些输出示例。

对 LFW 数据库取得的结果进行的分析表明,ChatGPT 在性别分类(94.05% 对 98.23%)方面不如 FairFace,但在年龄分类(72.87% 对 67.88%)和种族分类(88.25% 对 87.48%)方面优于 FairFace。这些结果证明了 ChatGPT 在特定面部属性分类方面的潜力。
为了进行更广泛的评估,我们考虑了标注有 47 种不同属性的 MAAD-Face 数据集。自定义模型(ResNet-50)在大多数属性上表现良好(平均准确率为 87.28%)。另一方面,ChatGPT 的平均性能较低(平均准确率为 76.98%),但在多个人脸属性上表现出色。
ChatGPT 在性别分类(准确率为 96.30%)、某些种族(白人–准确率为 83.90%,黑人–准确率为 97.50%)和配饰(如戴帽子)等软生物识别属性方面表现较好。为这一特定任务训练的模型通常能取得更好的结果,但 ChatGPT 在没有事先学习的任务中也表现出了良好的结果和实用性。
环境设备
数据库
在探索 ChatGPT 在面部生物识别任务中的应用性能时,研究团队采用了多个数据库来模拟不同的应用场景和图像条件,以评估模型在各种挑战下的表现。以下是所使用的数据库和它们的描述:
-
Labeled Faces in the Wild (LFW):这是一个广泛使用的数据库,收录了高质量且姿态变化不大的人脸图像,常用于基准测试。
-
QUIS-CAMPI:此数据库收集了在户外无控制环境下、使用距离主体约50米远的相机拍摄的视频和图像,模拟了更为自然的监控场景。
-
TinyFaces:包含极低分辨率(平均20x16像素)的图像,用于测试模型对极端低质量图像的处理能力。
-
BUPT-BalancedFace:旨在解决不同种族群体间性能差异的数据库,由不同种族和性别组合形成的八个人口统计群体组成,用于评估人口统计偏差。
-
Celebrities in Frontal-Profile in the Wild (CFP-FP):包含了在野外环境中、姿态和环境变化显著的名人图像,用于评估姿态变化的影响。
-
AgeDB:展示了不同年龄段个体在多样环境背景下的图像,用于评估模型对年龄变化的识别能力。
-
ROF:由被遮挡的人脸图像组成,包括因太阳镜导致的上部遮挡和口罩导致的下部遮挡,用于评估模型在面对遮挡情况时的性能。
-
MAAD-Face:用于软生物识别属性估计的数据库,为每张面部图像提供了47个人脸相关的软生物识别属性。
通过这些数据库,研究团队能够全面评估 ChatGPT 在多种复杂条件下的性能,包括在控制环境下的表现、无控制监控场景的适应性、极端图像质量下的鲁棒性、以及处理人口统计偏差、年龄和姿态变化、遮挡等挑战的能力。此外,MAAD-Face 数据库的使用,让研究团队能够探索 ChatGPT 在软生物识别方面的潜力,这对于提高识别系统的准确性和效率具有重要意义。
模型
在评估 ChatGPT 的面部识别能力时,研究团队选择了两种业界领先的面部识别模型作为对照,以便于比较性能:
-
ArcFace:这是一种先进的面部验证系统,它采用特定的损失函数,将面部特征映射到一个高维的超球面上。在这个超球面上,系统通过优化嵌入特征,使得不同个体之间的角距离最大化,从而提高区分不同身份的能力。在本研究中,ArcFace 模型基于 iResNet-100 架构,该架构使用 MS1Mv3 数据库进行预训练。在比较特征嵌入的相似性时,系统采用余弦距离作为度量。
-
AdaFace:这个系统引入了一种新颖的损失函数,目的是在训练过程中更加关注图像质量较差的样本。AdaFace 通过自适应边界函数来实现这一点,该函数利用特征的范数来评估图像的质量。本研究所考虑的 AdaFace 模型同样基于 iResNet-100 架构,不过它使用的是 WebFace12M 数据库进行预训练。与 ArcFace 类似,AdaFace 也使用余弦距离来衡量特征嵌入之间的相似性。
除了标准的面部识别任务,研究团队还关注了软生物识别属性的估计。为此,他们开发了一个自定义模型,用于预测 MAAD-Face 和 FairFace 数据库中的 47 个属性。这些属性包括性别、年龄和种族等,有助于更全面地理解个体的生物特征。
官方提供的模型:model
import torch
import torch.nn as nn
from torchvision import modelsclass AttributeNN(nn.Module):"""Base network for learning representations. Just a wrapper forresnnet 18 which maps the last layer to 40 outputs instead of the1000 used for ImageNet classification."""def __init__(self, n_labels, pretrain=False):super().__init__()self.resnet = models.resnet50(pretrained=pretrain)self.fc_in_feats = self.resnet.fc.in_featuresself.resnet.fc = nn.Linear(self.fc_in_feats, n_labels, bias=True)self.n_labels = n_labelsdef forward(self, x):output = self.resnet(x)return outputnetwork = AttributeNN(47, False)state_dict = torch.load(r'path/to/pretrain')
state_dict = {k.replace('model.', 'resnet.'): v for k, v in state_dict.items()}
network.load_state_dict(state_dict)
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
network.to(device)
network.eval()
脚本使用
官方提供了两个不同的脚本:
- combine_img.py:这个脚本的用途是将图像组合成我们提出的两种不同的图像配置:1x1 对比和 4x3 对比。在面部识别任务中,不同的图像布局可能会对模型的性能产生影响,因此,这个脚本能够帮助研究者和开发者以不同的方式排列和组合图像,以测试和优化模型的识别能力。
这个脚本的具体使用方式可能涉及以下几个步骤:
- 将需要进行比较的两张人脸图像合并成一张图像,可能是为了并排展示,以便进行1x1的直接对比。
- 将四张图像排列成一个3x4的矩阵,这可能有助于模型更全面地分析面部特征,尤其是在考虑多个人脸同时出现的场景时。
这些图像配置可以用于不同的测试和评估场景,例如:
- 在1x1配置中,可能用于直接比较两个人脸的相似性或差异性。
- 在4x3配置中,可能用于更复杂的群体分析,或者在一个人脸数据库中搜索特定的人脸。
python combine_img.py --df_name comparisons/file/.csv --append_path append/path/for/the/images/in/comparison_file --path_save_combined where/to/save/1x1images --path_save_matrix where/to/save/4x3images
总结
本文通过一系列全面实验,深入评估了 ChatGPT 在人脸识别和特征估计等关键人脸生物识别任务中的表现。实验涉及多个不同的数据库,结果表明,在与专业训练模型的比较中,ChatGPT 展现了可观的准确性。尤其是在没有任何训练的情况下,ChatGPT 作为初始评估工具的潜力尤为突出。
具体而言,在 LFW(Labeled Faces in the Wild)数据库上进行的人脸识别任务中,ChatGPT 实现了约 94% 的准确率,这一结果令人鼓舞。同样,在 MAAD-Face 数据库的性别估计任务中,ChatGPT 达到了 96% 的准确率,显示出其在性别识别方面的高效能力。此外,在 LFW 数据库的年龄和种族估计任务中,ChatGPT 分别获得了 73% 和 88% 的准确率,这些结果进一步证明了其在不同人脸生物识别任务中的适用性和有效性。
除了提供准确的识别结果,ChatGPT 还能够生成解释性文本,对识别结果进行阐述,这极大地增强了分析过程的透明度,帮助用户更好地理解输出结果背后的逻辑和依据。这种能力对于提升用户对系统的信任和接受度至关重要。