every blog every motto: You can do more than you think.
https://blog.csdn.net/weixin_39190382?type=blog
0. 前言
detr之decoder逐行梳理
1. 整体
decoder由多个decoder layer串联构成
输入
- tgt: query是一个shape为(n,bs,embed),内容为0的tensor
- memory: encoder最终的输出
- mask: backbone特征图对应的mask
- pos_embed 位置编码
- query_embed: 当做query的位置编码
class Transformer(nn.Module):def __init__(self, d_model=512, nhead=8, num_encoder_layers=6,num_decoder_layers=6, dim_feedforward=2048, dropout=0.1,activation="relu", normalize_before=False,return_intermediate_dec=False):super().__init__()encoder_layer = TransformerEncoderLayer(d_model, nhead, dim_feedforward,dropout, activation, normalize_before)encoder_norm = nn.LayerNorm(d_model) if normalize_before else None# encoder 部分self.encoder = TransformerEncoder(encoder_layer, num_encoder_layers, encoder_norm)decoder_layer = TransformerDecoderLayer(d_model, nhead, dim_feedforward,dropout, activation, normalize_before)decoder_norm = nn.LayerNorm(d_model)# decoder 部分self.decoder = TransformerDecoder(decoder_layer, num_decoder_layers, decoder_norm,return_intermediate=return_intermediate_dec)self._reset_parameters()self.d_model = d_modelself.nhead = nheaddef forward(self, src, mask, query_embed, pos_embed):# flatten bxCxHxW to HWxbxCbs, c, h, w = src.shape# (b,c,h,w) ->(b,c,hw) -> (hw,b,c) src = src.flatten(2).permute(2, 0, 1)# (b,c,h,w) ->(b,c,hw) -> (hw,b,c) pos_embed = pos_embed.flatten(2).permute(2, 0, 1)mask = mask.flatten(1)memory = self.encoder(src, src_key_padding_mask=mask, pos=pos_embed)# (num_query,hidden_dim) -> (num_query,1,hidden_dim) -> (num_query_bs,hidden_dim)# (100,512) -> (100,1,512) -> (100,bs,512)query_embed = query_embed.unsqueeze(1).repeat(1, bs, 1)# (100,bs,512)tgt = torch.zeros_like(query_embed)hs = self.decoder(tgt, memory, memory_key_padding_mask=mask,pos=pos_embed, query_pos=query_embed)return hs.transpose(1, 2), memory.permute(1, 2, 0).view(bs, c, h, w)
2. 部分
2.1 get_clone
和encoder中类似,用于对指定的层进行复制
def _get_clones(module, N):return nn.ModuleList([copy.deepcopy(module) for i in range(N)])
2.2 Decoder
串联多个layer,输出作为输入
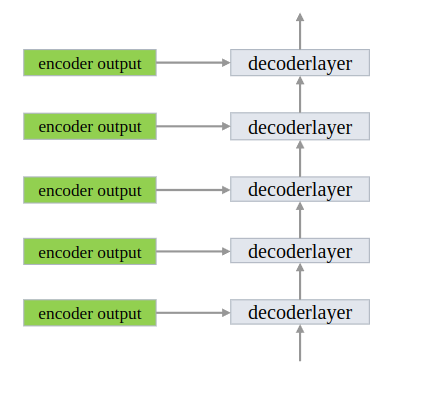
class TransformerDecoder(nn.Module):def __init__(self, decoder_layer, num_layers, norm=None, return_intermediate=False):super().__init__()# 对指定层进行复制self.layers = _get_clones(decoder_layer, num_layers)self.num_layers = num_layersself.norm = normself.return_intermediate = return_intermediatedef forward(self, tgt, memory,tgt_mask: Optional[Tensor] = None,memory_mask: Optional[Tensor] = None,tgt_key_padding_mask: Optional[Tensor] = None,memory_key_padding_mask: Optional[Tensor] = None,pos: Optional[Tensor] = None,query_pos: Optional[Tensor] = None):output = tgtintermediate = []for layer in self.layers:# 输出作为输入output = layer(output, memory, tgt_mask=tgt_mask,memory_mask=memory_mask,tgt_key_padding_mask=tgt_key_padding_mask,memory_key_padding_mask=memory_key_padding_mask,pos=pos, query_pos=query_pos)if self.return_intermediate:intermediate.append(self.norm(output))if self.norm is not None:output = self.norm(output)if self.return_intermediate:intermediate.pop()intermediate.append(output)# 用于分割的深监督if self.return_intermediate:return torch.stack(intermediate)return output.unsqueeze(0)
2.3 DecoderLayer
最开始的输入是全0的tensor,后续的输入是上一层的输出,还有encoder最终的输出作为(第二个MSA)的v和k
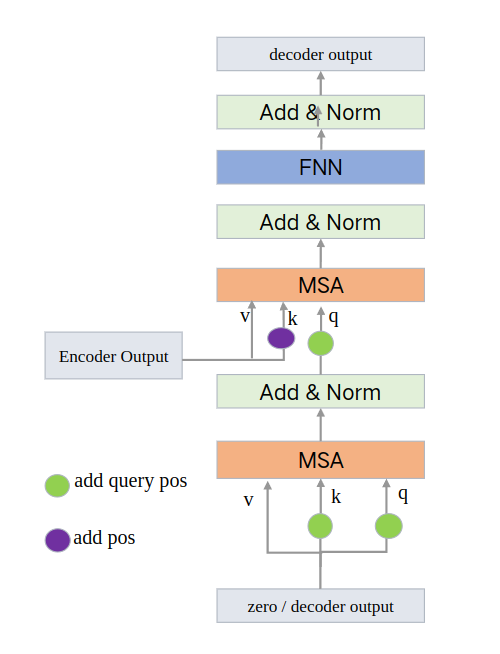
其中forward包含forward_post和forward_pre两个函数,主要区别是最开始进行标准化还是最后进行标准化。和encoder类似。还是以forawd_post为例:
在encoder中qkv都来源同一个值,而decoder中不是,所以有必要探究一下:
最开始的输入是全0的tensor,记为tgt,后续的输入是上一层DecoderLayer的输出。还有一个encoder最终的输出,记为memory。
以第一个DecoderLayer为例,
2.3.1 第一个MultiheadAttention
q,k: tgt (100,bs,512)
v: tgt (100,bs,512)
由于nn.MultiheadAttention默认batch_first=False,所以传如的batch_size在中间。
在内部会将batch_size置换到最前面,
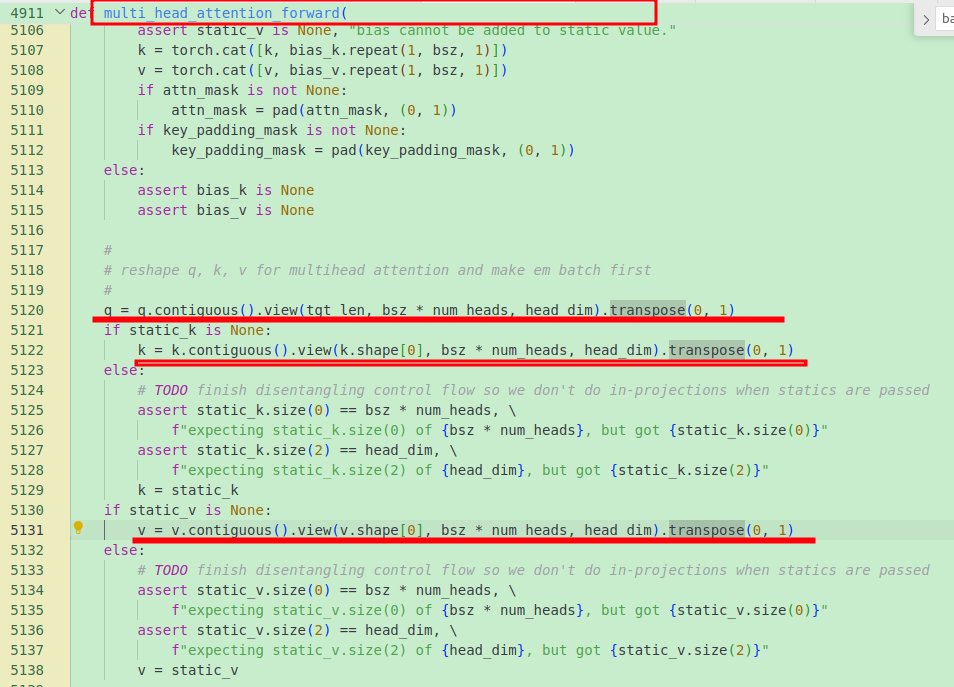
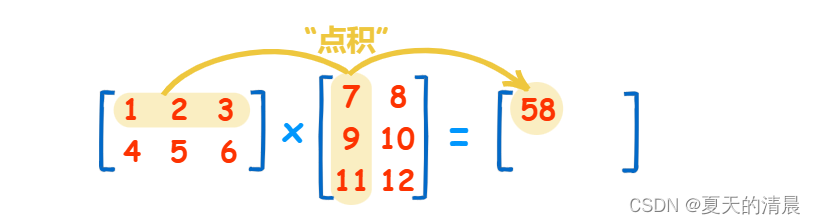
内部的乘积会使用torch.baddbmm,简单说,是两个向量相乘,(b,n,m)@(b,m,p),要保证第一个向量的最后一个维和第二个向量的中间维相等,结果shape (b,n,p),具体看:

具体attention的内部计算如下:
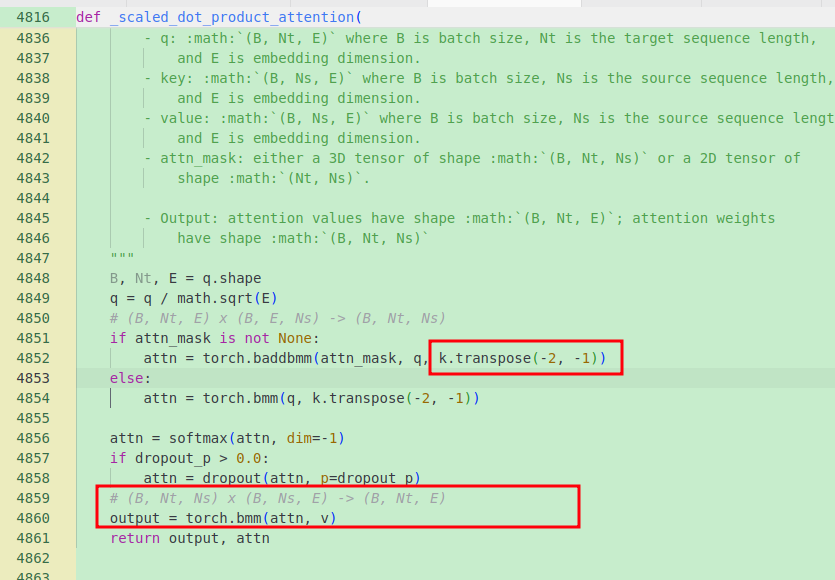
所以有:
q: (100,bs,512) -> (bs,100,512)
k: (100,bs,512) -> (bs,100,512)
v: (100,bs,512) -> (bs,100,512)
att = q@k: (bs,100,512)@(bs,100,512) -> (bs,100,100)
out = att@v: (bs,100,100)@(bs,100,512) -> (bs,100,512)
out reshape -> (100,bs,512)
最终的输出又会将batch放到中间

2.3.2 第二个MultiheadAttention
q: 第一个MultiheadAttention的输出 (100,bs,512)
k,v: memory (hw,bs,512)
整体过程和上述类似
q: (100,bs,512) -> (bs,100,512)
k: (hw,bs,512) -> (bs,hw,512)
v: (hw,bs,512) -> (bs,hw,512)
att = q@k: (bs,100,512)@(bs,hw,512) -> (bs,100,hw)
out = att@v: (bs,100,hw)@(bs,hw,512) -> (bs,100,512)
out reshape -> (100,bs,512)
2.3.3 小结
通过上述变换会有如下形式:
注: batch_frist=True
q: (b, a, m)
k: (b, d, m)
v: (b, d, c)
则,
out: (b, a, c)
由于我们的m=c=512,所以最终输出是(b,a,512),和q一样。这个输出会当做下一层DecoderLayer的输入,作为内部的第一个MultiheadAttention的q、k和v。
有如下结论:
- 我们看到最终的输出个数是由q决定的,所以当q设置成100时,我们的最终输出也是100个。
- k和v的token个要相同,即d个
- q和k的hidd_embeding维要相同,m个。
class TransformerDecoderLayer(nn.Module):def __init__(self, d_model, nhead, dim_feedforward=2048, dropout=0.1,activation="relu", normalize_before=False):super().__init__()self.self_attn = nn.MultiheadAttention(d_model, nhead, dropout=dropout)self.multihead_attn = nn.MultiheadAttention(d_model, nhead, dropout=dropout)# Implementation of Feedforward modelself.linear1 = nn.Linear(d_model, dim_feedforward)self.dropout = nn.Dropout(dropout)self.linear2 = nn.Linear(dim_feedforward, d_model)self.norm1 = nn.LayerNorm(d_model)self.norm2 = nn.LayerNorm(d_model)self.norm3 = nn.LayerNorm(d_model)self.dropout1 = nn.Dropout(dropout)self.dropout2 = nn.Dropout(dropout)self.dropout3 = nn.Dropout(dropout)self.activation = _get_activation_fn(activation)self.normalize_before = normalize_beforedef with_pos_embed(self, tensor, pos: Optional[Tensor]):return tensor if pos is None else tensor + posdef forward_post(self, tgt, memory,tgt_mask: Optional[Tensor] = None,memory_mask: Optional[Tensor] = None,tgt_key_padding_mask: Optional[Tensor] = None,memory_key_padding_mask: Optional[Tensor] = None,pos: Optional[Tensor] = None,query_pos: Optional[Tensor] = None):# 添加query pos,q,k:(100,bs,512)q = k = self.with_pos_embed(tgt, query_pos)# 第一个MultiheadAttention# (100,bs, 512)tgt2 = self.self_attn(q, k, value=tgt, attn_mask=tgt_mask,key_padding_mask=tgt_key_padding_mask)[0]# 残差tgt = tgt + self.dropout1(tgt2)# 标准化tgt = self.norm1(tgt)# 第二个MultiheadAttention# q: (100,bs,512); key: (hw,bs,512) value: (hw,bs,512)# att = q@k: (100,bs,512)@(hw,bs,512) -> (100,bs,hw)# out = att@v: (100,bs,hw)@(hw,bs,512) -> (100,bs,512)tgt2 = self.multihead_attn(query=self.with_pos_embed(tgt, query_pos),key=self.with_pos_embed(memory, pos),value=memory, attn_mask=memory_mask,key_padding_mask=memory_key_padding_mask)[0]# 残差tgt = tgt + self.dropout2(tgt2)# 标准化tgt = self.norm2(tgt)# FFNtgt2 = self.linear2(self.dropout(self.activation(self.linear1(tgt))))# 残差tgt = tgt + self.dropout3(tgt2)# 标准化tgt = self.norm3(tgt)return tgt... # 略def forward(self, tgt, memory,tgt_mask: Optional[Tensor] = None,memory_mask: Optional[Tensor] = None,tgt_key_padding_mask: Optional[Tensor] = None,memory_key_padding_mask: Optional[Tensor] = None,pos: Optional[Tensor] = None,query_pos: Optional[Tensor] = None):# 默认Falseif self.normalize_before:return self.forward_pre(tgt, memory, tgt_mask, memory_mask,tgt_key_padding_mask, memory_key_padding_mask, pos, query_pos)return self.forward_post(tgt, memory, tgt_mask, memory_mask,tgt_key_padding_mask, memory_key_padding_mask, pos, query_pos)
完整代码:
class TransformerDecoderLayer(nn.Module):def __init__(self, d_model, nhead, dim_feedforward=2048, dropout=0.1,activation="relu", normalize_before=False):super().__init__()self.self_attn = nn.MultiheadAttention(d_model, nhead, dropout=dropout)self.multihead_attn = nn.MultiheadAttention(d_model, nhead, dropout=dropout)# Implementation of Feedforward modelself.linear1 = nn.Linear(d_model, dim_feedforward)self.dropout = nn.Dropout(dropout)self.linear2 = nn.Linear(dim_feedforward, d_model)self.norm1 = nn.LayerNorm(d_model)self.norm2 = nn.LayerNorm(d_model)self.norm3 = nn.LayerNorm(d_model)self.dropout1 = nn.Dropout(dropout)self.dropout2 = nn.Dropout(dropout)self.dropout3 = nn.Dropout(dropout)self.activation = _get_activation_fn(activation)self.normalize_before = normalize_beforedef with_pos_embed(self, tensor, pos: Optional[Tensor]):return tensor if pos is None else tensor + posdef forward_post(self, tgt, memory,tgt_mask: Optional[Tensor] = None,memory_mask: Optional[Tensor] = None,tgt_key_padding_mask: Optional[Tensor] = None,memory_key_padding_mask: Optional[Tensor] = None,pos: Optional[Tensor] = None,query_pos: Optional[Tensor] = None):# 第一个MultiheadAttentionq = k = self.with_pos_embed(tgt, query_pos)tgt2 = self.self_attn(q, k, value=tgt, attn_mask=tgt_mask,key_padding_mask=tgt_key_padding_mask)[0]tgt = tgt + self.dropout1(tgt2)tgt = self.norm1(tgt)# 第二个MultiheadAttentiontgt2 = self.multihead_attn(query=self.with_pos_embed(tgt, query_pos),key=self.with_pos_embed(memory, pos),value=memory, attn_mask=memory_mask,key_padding_mask=memory_key_padding_mask)[0]tgt = tgt + self.dropout2(tgt2)tgt = self.norm2(tgt)tgt2 = self.linear2(self.dropout(self.activation(self.linear1(tgt))))tgt = tgt + self.dropout3(tgt2)tgt = self.norm3(tgt)return tgtdef forward_pre(self, tgt, memory,tgt_mask: Optional[Tensor] = None,memory_mask: Optional[Tensor] = None,tgt_key_padding_mask: Optional[Tensor] = None,memory_key_padding_mask: Optional[Tensor] = None,pos: Optional[Tensor] = None,query_pos: Optional[Tensor] = None):tgt2 = self.norm1(tgt)q = k = self.with_pos_embed(tgt2, query_pos)tgt2 = self.self_attn(q, k, value=tgt2, attn_mask=tgt_mask,key_padding_mask=tgt_key_padding_mask)[0]tgt = tgt + self.dropout1(tgt2)tgt2 = self.norm2(tgt)tgt2 = self.multihead_attn(query=self.with_pos_embed(tgt2, query_pos),key=self.with_pos_embed(memory, pos),value=memory, attn_mask=memory_mask,key_padding_mask=memory_key_padding_mask)[0]tgt = tgt + self.dropout2(tgt2)tgt2 = self.norm3(tgt)tgt2 = self.linear2(self.dropout(self.activation(self.linear1(tgt2))))tgt = tgt + self.dropout3(tgt2)return tgtdef forward(self, tgt, memory,tgt_mask: Optional[Tensor] = None,memory_mask: Optional[Tensor] = None,tgt_key_padding_mask: Optional[Tensor] = None,memory_key_padding_mask: Optional[Tensor] = None,pos: Optional[Tensor] = None,query_pos: Optional[Tensor] = None):if self.normalize_before:return self.forward_pre(tgt, memory, tgt_mask, memory_mask,tgt_key_padding_mask, memory_key_padding_mask, pos, query_pos)return self.forward_post(tgt, memory, tgt_mask, memory_mask,tgt_key_padding_mask, memory_key_padding_mask, pos, query_pos)
2.4 decoder输出
decoder最终的输出,即,最后一层DecoderLayer的输出,(b,100,512) -> (1,b,100,512)
说明: 由于我们是batch_first=False,所以实际b在中间,上面表述放在前面为了方便理解。
class TransformerDecoder(nn.Module):def __init__(self, decoder_layer, num_layers, norm=None, return_intermediate=False):super().__init__()# 对指定层进行复制self.layers = _get_clones(decoder_layer, num_layers)self.num_layers = num_layersself.norm = normself.return_intermediate = return_intermediatedef forward(self, tgt, memory,tgt_mask: Optional[Tensor] = None,memory_mask: Optional[Tensor] = None,tgt_key_padding_mask: Optional[Tensor] = None,memory_key_padding_mask: Optional[Tensor] = None,pos: Optional[Tensor] = None,query_pos: Optional[Tensor] = None):output = tgtintermediate = []for layer in self.layers:# 输出作为输入output = layer(output, memory, tgt_mask=tgt_mask,memory_mask=memory_mask,tgt_key_padding_mask=tgt_key_padding_mask,memory_key_padding_mask=memory_key_padding_mask,pos=pos, query_pos=query_pos)if self.return_intermediate:intermediate.append(self.norm(output))if self.norm is not None:output = self.norm(output)if self.return_intermediate:intermediate.pop()intermediate.append(output)# 用于分割的深监督if self.return_intermediate:return torch.stack(intermediate)# (100,b,512) -> (1,100,b,512)return output.unsqueeze(0)
3. Transformer输出
Transformer返回两个:
- 第一个返回值,decoder的输出,(1,bs,100,512)
- 第二个返回值,encoder的输出,(hw,b,c) -> (b,c,hw)-> (b,c,h,w)
class Transformer(nn.Module):def __init__(self, d_model=512, nhead=8, num_encoder_layers=6,num_decoder_layers=6, dim_feedforward=2048, dropout=0.1,activation="relu", normalize_before=False,return_intermediate_dec=False):super().__init__()encoder_layer = TransformerEncoderLayer(d_model, nhead, dim_feedforward,dropout, activation, normalize_before)encoder_norm = nn.LayerNorm(d_model) if normalize_before else None# encoder 部分self.encoder = TransformerEncoder(encoder_layer, num_encoder_layers, encoder_norm)decoder_layer = TransformerDecoderLayer(d_model, nhead, dim_feedforward,dropout, activation, normalize_before)decoder_norm = nn.LayerNorm(d_model)self.decoder = TransformerDecoder(decoder_layer, num_decoder_layers, decoder_norm,return_intermediate=return_intermediate_dec)self._reset_parameters()self.d_model = d_modelself.nhead = nheaddef _reset_parameters(self):for p in self.parameters():if p.dim() > 1:nn.init.xavier_uniform_(p)def forward(self, src, mask, query_embed, pos_embed):# flatten bxCxHxW to HWxbxCbs, c, h, w = src.shape# (b,c,h,w) ->(b,c,hw) -> (hw,b,c) src = src.flatten(2).permute(2, 0, 1)# (b,c,h,w) ->(b,c,hw) -> (hw,b,c) pos_embed = pos_embed.flatten(2).permute(2, 0, 1)mask = mask.flatten(1)# (hw,b,c)memory = self.encoder(src, src_key_padding_mask=mask, pos=pos_embed)# (num_query,hidden_dim) -> (num_query,1,hidden_dim) -> (num_query_bs,hidden_dim)# (100,512) -> (100,1,512) -> (100,bs,512)query_embed = query_embed.unsqueeze(1).repeat(1, bs, 1)# (100,bs,512)tgt = torch.zeros_like(query_embed)# hs (1,100,bs,512)hs = self.decoder(tgt, memory, memory_key_padding_mask=mask,pos=pos_embed, query_pos=query_embed)# 第一个返回值,(1,bs,100,512)# 第二个返回值,(hw,b,c) -> (b,c,hw)-> (b,c,h,w)return hs.transpose(1, 2), memory.permute(1, 2, 0).view(bs, c, h, w)
4. Detr输出
在detr实际使用中只获取decoder最后的输出,如下代码注释。
分别获取了类别和坐标,
类别:(bs, 100, num_classes+1)
box: (bs, 100, 4)
注意: 这个100的维度可以追溯到最开始输入decoder的全0向量(tgt,(100,bs,512))
detr局部代码:
# 取decoer的最后的输出 (1,bs,100,512)
hs = self.transformer(self.input_proj(src), mask, self.query_embed.weight, pos[-1])[0]# 类别, (1,bs,100,512) -> (1,bs,100,num_class+1)
outputs_class = self.class_embed(hs)
# box, (1,bs,100,512) -> (1,bs,100,4)
outputs_coord = self.bbox_embed(hs).sigmoid()# (bs,100,num_class+1) , (bs,100,4)
out = {'pred_logits': outputs_class[-1], 'pred_boxes': outputs_coord[-1]}
if self.aux_loss:out['aux_outputs'] = self._set_aux_loss(outputs_class, outputs_coord)return out
detr完整代码:
class DETR(nn.Module):""" This is the DETR module that performs object detection """def __init__(self, backbone, transformer, num_classes, num_queries, aux_loss=False):""" Initializes the model.Parameters:backbone: torch module of the backbone to be used. See backbone.pytransformer: torch module of the transformer architecture. See transformer.pynum_classes: number of object classesnum_queries: number of object queries, ie detection slot. This is the maximal number of objectsDETR can detect in a single image. For COCO, we recommend 100 queries.aux_loss: True if auxiliary decoding losses (loss at each decoder layer) are to be used."""super().__init__()self.num_queries = num_queriesself.transformer = transformerhidden_dim = transformer.d_modelself.class_embed = nn.Linear(hidden_dim, num_classes + 1) # 类别 ,加1,背景self.bbox_embed = MLP(hidden_dim, hidden_dim, 4, 3) # boxself.query_embed = nn.Embedding(num_queries, hidden_dim)self.input_proj = nn.Conv2d(backbone.num_channels, hidden_dim, kernel_size=1)self.backbone = backboneself.aux_loss = aux_lossdef forward(self, samples: NestedTensor):""" The forward expects a NestedTensor, which consists of:- samples.tensor: batched images, of shape [batch_size x 3 x H x W]- samples.mask: a binary mask of shape [batch_size x H x W], containing 1 on padded pixelsIt returns a dict with the following elements:- "pred_logits": the classification logits (including no-object) for all queries.Shape= [batch_size x num_queries x (num_classes + 1)]- "pred_boxes": The normalized boxes coordinates for all queries, represented as(center_x, center_y, height, width). These values are normalized in [0, 1],relative to the size of each individual image (disregarding possible padding).See PostProcess for information on how to retrieve the unnormalized bounding box.- "aux_outputs": Optional, only returned when auxilary losses are activated. It is a list ofdictionnaries containing the two above keys for each decoder layer."""if isinstance(samples, (list, torch.Tensor)):samples = nested_tensor_from_tensor_list(samples)features, pos = self.backbone(samples)src, mask = features[-1].decompose()assert mask is not None# 取decoer的最后的输出 (1,bs,100,512)hs = self.transformer(self.input_proj(src), mask, self.query_embed.weight, pos[-1])[0]# 类别, (1,bs,100,512) -> (1,bs,100,num_class+1)outputs_class = self.class_embed(hs)# box, (1,bs,100,512) -> (1,bs,100,4)outputs_coord = self.bbox_embed(hs).sigmoid()out = {'pred_logits': outputs_class[-1], 'pred_boxes': outputs_coord[-1]}if self.aux_loss:out['aux_outputs'] = self._set_aux_loss(outputs_class, outputs_coord)return out
5. 问题
有的人可能疑问,为什么这里定义的物体信息tgt,初始化为全0,物体位置信息query_pos,随机初始化,但是可以表示这么复杂的含义呢?它明明是初始化为全0或随机初始化的,模型怎么知道的它们代表的含义?这其实就和损失函数有关了,损失函数定义好了,通过计算损失,梯度回传,网络不断的学习,最终学习得到的tgt和query_pos就是这里表示的含义。这就和回归损失一样的,定义好了这四个channel代表xywh,那网络怎么知道的?就是通过损失函数梯度回传,网络不断学习,最终知道这四个channel就是代表xywh。
参考
- https://blog.csdn.net/weixin_39190382/article/details/137905915?spm=1001.2014.3001.5501
- https://hukai.blog.csdn.net/article/details/127616634