stack和queue(priority_queue)
1. 容器适配器
适配器(Adapter):一种用来修饰容器(Containers)或仿函数(Functors)或迭代器(Iterator)接口的东西。
适配器是一种设计模式,该模式将一个类的接口转换成客户希望的另外一个接口。
现实中拿插座来说,一个插座可以适配不同的插头,以适应不同电器的电压或者其他要求。
STL中的适配器相当于一个插座,以适应不同容器,可以"插入"vector, 也可以插入 list,等等。
虽然
stack和queue也可以存放元素,但在STL中并没有将其划分在容器的行列,而是将其称为容器适配器。
例如stack只提供LIFO(先进先出)的概念,对其他容器的接口进行了包装,并没有完全重新创建了一个容器。在STL中,stack和queue默认使用deque,而priority_queue默认使用vector。

类似于list中iterator的实现,实际上是更高一层的封装。__list_iterator是对Node*的封装,以支持运算符重载;相对应的,stack是对其Container的封装,以支持LIFO的上下文。
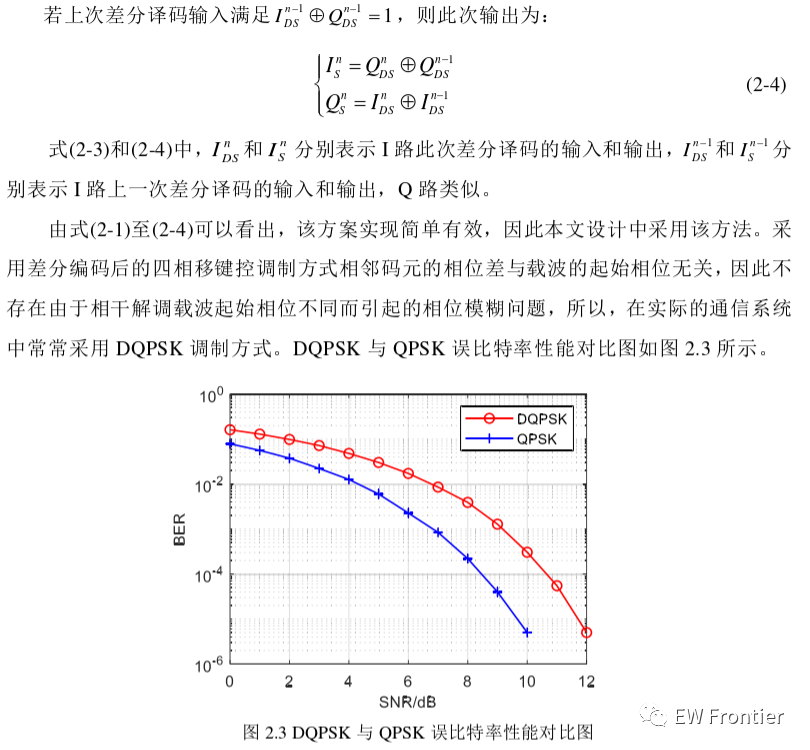
2. stack 的介绍和实现
2.1 stack 的介绍
stack文档介绍
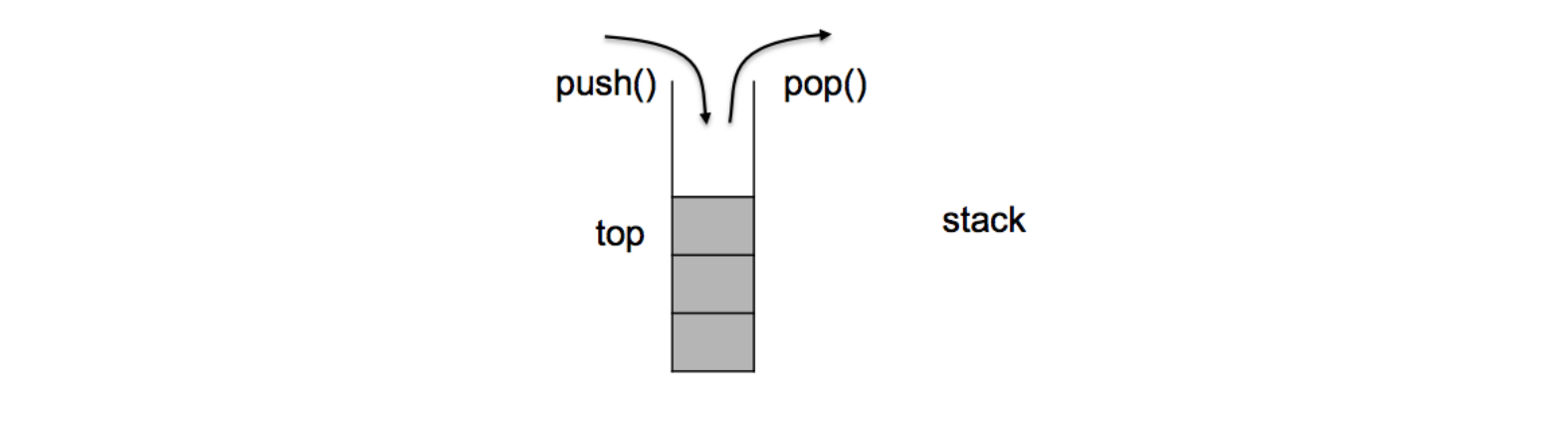
stack是一种容器适配器,设计用于在具有后进先出操作的上下文中,其删除和插入只能从容器的末尾进行操作。
stack是作为容器适配器被实现的,容器适配器即是对特定类封装作为其底层的容器,并提供一组特定的成员函数来访问其元素,元素特定从容器的尾部(即栈顶)被压入和弹出。
stack的底层容器可以是任何标准的容器类模板或者一些特殊设计的容器类。这些容器应该支持如下操作:empty() // 判空操作 size() // 得到元素个数操作 back() // 得到容器尾部元素操作 push_back() // 尾插操作 pop_back() // 尾删操作标准容器
list,vector和deque均满足这些要求。默认情况下,如果没有为stack指定特定的底层容器,默认使用deque作为底层容器。
2.2 stack 的实现
stack 有如下成员函数(不包括C++11)

利用适配器概念进行实现:
#pragma once
#include <deque>namespace wr
{template <class T, class Con = deque<T>> class stack{public:void push(const T &x){_con.push_back(x);}void pop(){_con.pop_back();}T &top(){return _con.back();}T &top() const{return _con.back();}size_t size(){return _con.size();}bool empty(){return _con.empty();}private:Con _con; // 底层的容器类对象作为成员变量};
}
可以看到,适配器模式下设计的stack十分简洁,相比用C语言实现的stack,完全体现了适配器模式的优势。
总结:从使用者角度来看,不需要知道stack底层使用的是什么容器实现,只需要知道其可以实现对应适合LIFO的操作。无论是STL中的容器,还是自定义类容器,只要拥有对应的接口,就可以作为stack的底层容器。
2. queue的介绍和实现
2.1 queue 的介绍
queue文档介绍
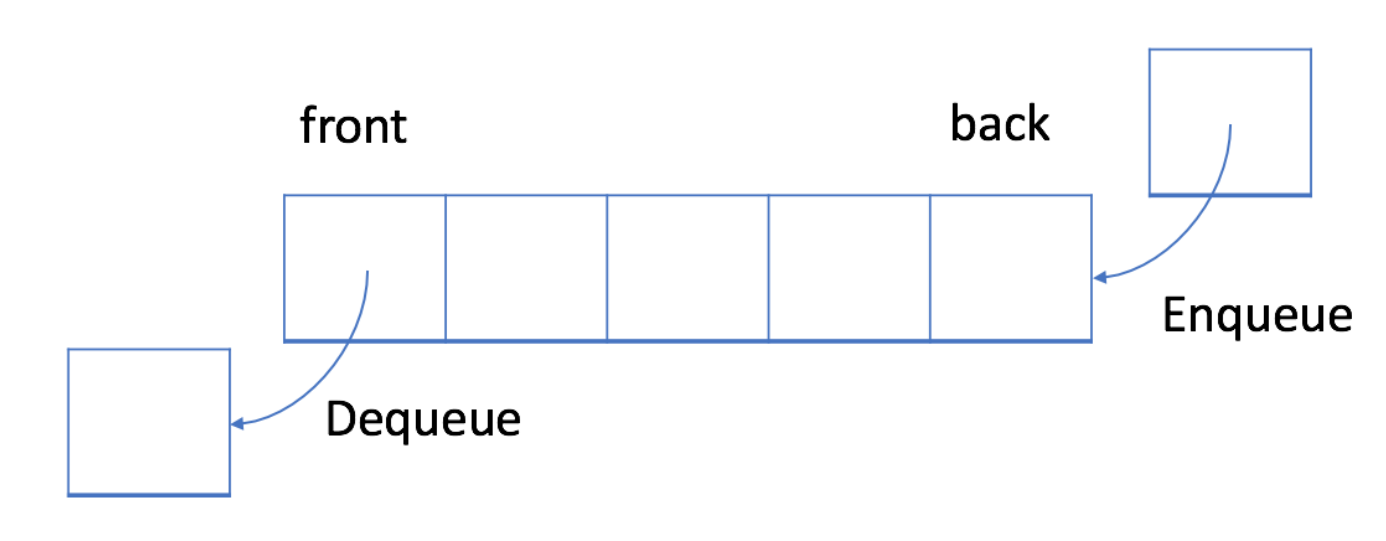
queue是一种容器适配器,专门用于在FIFO(先进先出)的上下文中操作,其中从容器一端插入元素,另一端提取元素。
queue作为容器适配器实现,用一个底层是特定容器类的封装类来实现,queue提供了特定了成员函数来访问它的元素。元素队尾入队列,从队头出队列。
queue的底层容器可以是标准容器中的一种,或者是经过特别设计的容器类。底层容器应该至少指出如下操作:empty() // 判空操作 size() // 得到元素个数操作 front() // 得到容器头部元素 back() // 得到容器尾部元素 push_back() // 容器尾插元素操作 pop_back() // 容器头删元素操作
STL中deque和list可以满足这些需求。默认情况下,如果没有容器类被指定,默认使用deque作为queue的底层容器。
2.2 queue 的实现
queue有如下成员函数:

实现如下:
#pragma once#include <deque>namespace wr
{template <class T, class Con = deque<T>>class queue{public:void push(const T &x){_con.push_back(x);}void pop(){_con.pop_front();}T &back(){return _con.back();}const T &back() const{return _con.back();}T &front(){return _con.front();}const T &front() const{return _con.front();}size_t size() const{return _con.size();}bool empty() const{return _con.empty();}private:Con _con;};
}
和stack的实现差不多,唯一需要注意的是 :queue的底层容器不能是vector,因为vector类根本不支持pop_front()的操作。并且vector的头删效率太低,需要挪动后面的所有元素。
3. priority_queue 的介绍和使用
3.1 priority_queue 的介绍
priority_queue文档介绍
priority_queue(优先队列)是一种容器适配器,根据严格的弱排序标准,它的第一个元素总是它所包含元素最大的。此上下文类似于
heap(堆),在这种上下文中,元素可以随时被插入到堆中,并且只有最大的堆元素可以被访问(位于优先队列的top())。
priority_queue被作为容器适配器实现,并将特定容器类封装作为其底层容器类,同时提供了特定的一组成员函数来访问其元素。元素从特定容器的“尾部”弹出,其成为优先队列的顶部。底层容器可以是任何标准容器类模板,也可以是其他特定设计的容器类。容器应该可以通过随机访问迭代器访问,并支持以下操作:
empty() // 判空操作 size() // 得到元素个数操作 front() // 得到容器头部元素 push_back() // 容器尾插元素操作 pop_back() // 容器头删元素操作
STL中vector和deque满足这些需求。默认情况下,如果没有为特定的priority_queue类实例化指定容器类,则使用vector。需要支持随机访问迭代器,一边始终在内部保持堆结构。容器适配器通过在需要时自动调用算法函数
make_heap、push_heap和pop_heap来自动完成此操作。
优先级队列默认使用vector作为其底层的容器,在vector上又使用了堆算法将vector中元素构造成堆的结构,因此priority_queue就是堆,所有需要用到堆的位置,都可以考虑使用priority_queue。
需要注意的是,下面是优先级队列的模板参数,第三个参数默认使用less仿函数,以构造大堆。若指定Compare是greater仿函数,则构成小堆。

// 默认情况下构造小堆
priority_queue<int> pq1;
// 相当于
priority_queue<int, vector<int>, less<int>> pq1;// 指定底层容器构造大堆
priority_queue<int, deque<int>, greater<int>> pq2;
如果需要使用priority_queue存放自定义类元素,需要自行重载>和<。
3.2 priority_queue 的实现
之前已经用C语言实现过堆,C++实现的重点是对STL的使用、仿函数的使用以及适配器模式概念的理解。
数据结构:堆的实现和堆排序及TopK问题
堆的插入元素和删除元素的时间复杂度是O(logN) ,默认情况下优先级队列是大堆,先不考虑使用仿函数去实现大小堆兼容的问题。首先先来实现大堆,最后在代码基础上加上仿函数的设计就可以了。
priority_queue与queue的区别主要是在push和pop上,优先级队列需要进行额外的向上调整和向下调整以满足堆序。
push:先将元素尾插到容器,随后将该元素进行向上调整以满足堆序。
pop:直接将容器最后一个元素覆盖堆顶元素,随后对此时的堆顶元素进行向下调整以满足堆序。注意:不能直接将堆顶元素删除,因为不能保证左孩子和右孩子之间也满足堆序,两个孩子之间没有关系,它们只和他们的父亲有关系。
void push(const T &x)
{_con.push_back(x);adjust_up(_con.size() - 1);
}void pop()
{assert(!_con.empty());_con[0] = _con[_con.size() - 1];_con.pop_back();adjust_down(0);
}
随后就是向上调整和向下调整算法,这里先直接用不等号直接实现大堆。
// 向上调整算法
void adjust_up(int child)
{int parent = (child - 1) / 2;while (parent >= 0){// 默认less,大堆,a[child] > a[parent] 交换if (_con[parent] < _con[child]){swap(_con[parent], _con[child]);child = parent;parent = (child - 1) / 2;}else{break;}}
}// 向下调整算法
void adjust_down(int parent)
{int child = parent * 2 + 1;while (child < _con.size()){// 默认less, 如果_con[child+1] > _con[child], 更新childif (child + 1 < _con.size() && _con[child] < _con[child+1]){child++;}// 如果_con[parent] < _con[child] 交换if (_con[parent] < _con[child]){swap(_con[parent], _con[child]);parent = child;child = parent * 2 + 1;}else{break;}}
}
具体实现细节在以前博客,这里不过多赘述。
随后是其他一些简单接口。注意:top()的参数和返回值都是const,保证数据不被修改。
bool empty() const
{return _con.empty();
}size_t size() const
{return _con.size();
}const T &top() const
{return _con.front();
}
这是固定死了的大堆,如果要使用小堆,难道需要再写一个类或者在需要时再修改吗?答案显然是否定的。
在C语言阶段,可以用函数指针进行实现,通过对comp()函数的回调实现特定的需求。例如实现bubble_sort()函数时通过传入函数指针来指定比较方法。
//通用冒泡排序
void bubble_sort(void* base, size_t num, size_t size, int (*cmp)(const char*, const char*))
C++中有更好的实现方法,称为仿函数。
3.2.1 仿函数
仿函数就是仿造的函数,它并不是一个真正意义上的函数。它是一个类中的
operator()重载,使之它具有类似于函数的功能。
就如仿羊皮一样,仿函数不是函数,而是一个类中的operator()重载,既然在类中,那么就可以使用模板参数,这相比函数指针就更加的范式化。
下面是greater和less的模拟实现
template <class T>
struct greater
{// 运算符()重载bool operator()(const T &a, const T &b){return a > b;}
};template <class T>
struct less
{bool operator()(const T &a, const T &b){return a < b;}
};
使用仿函数就可以构建一个对应的类对象,随后调用operator()即可
less<int> le;
cout << le(100, 200) << endl;
将仿函数类模板放入priority_queue的模板参数列表中,就可以实现在构建优先级队列的时候指定堆序了。因为模板参数传入的是类型,在编译的时候进行传递,随后程序运行都是基于传入模板的参数类型下进行运行的。
下面是引入了仿函数的完整priority_queue完整实现:
template <class T>
class greater
{
public:bool operator()(const T &a, const T &b){return a > b;}
};template <class T>
class less
{
public:bool operator()(const T &a, const T &b){return a < b;}
};template <class T, class Con = vector<T>, class Compare = less<T>>
class priority_queue
{void adjust_up(int child){int parent = (child - 1) / 2;while (parent >= 0){// 默认less,大堆,a[child] > a[parent] 交换if (_comp(_con[parent], _con[child])){swap(_con[parent], _con[child]);child = parent;parent = (child - 1) / 2;}else{break;}}}void adjust_down(int parent){int child = parent * 2 + 1;while (child < _con.size()){// 默认less, 如果_con[child+1] > _con[child], 更新childif (child + 1 < _con.size() && _comp(_con[child], _con[child + 1])){child++;}if (_comp(_con[parent], _con[child])){swap(_con[parent], _con[child]);parent = child;child = parent * 2 + 1;}else{break;}}}public:template <class InputIterator>priority_queue(InputIterator first, InputIterator last){while (first < last){push(*first);first++;}}bool empty() const{return _con.empty();}size_t size() const{return _con.size();}const T &top() const{return _con.front();}void push(const T &x){_con.push_back(x);adjust_up(_con.size() - 1);}void pop(){_con[0] = _con[_con.size() - 1];_con.pop_back();adjust_down(0);}private:Con _con;Compare _comp;
};
4. deque 的简单介绍
deque 的文档介绍
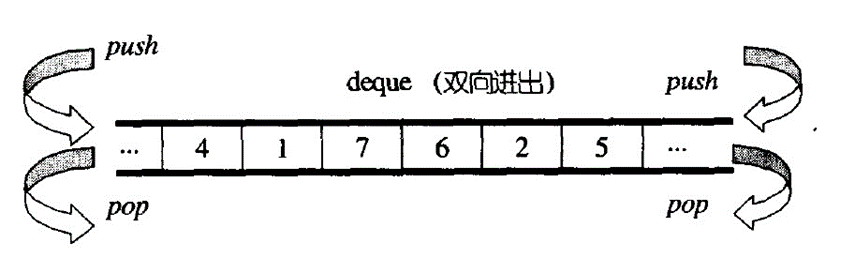
deque双端队列:是一种双开口的“连续”空间的数据结构,双开口的含义是:可以在头尾进行插入和删除操作,且时间复杂度是O(1),与vector比较,头插效率高,不需要搬移元素;与list比较,空间利用率比较高。
4.1 deque 的实现原理
deque并不是真正连续的空间,而是由一段段连续的小空间拼接而成的。
实际的deque类似于一个动态的二维数组,如下图所示:
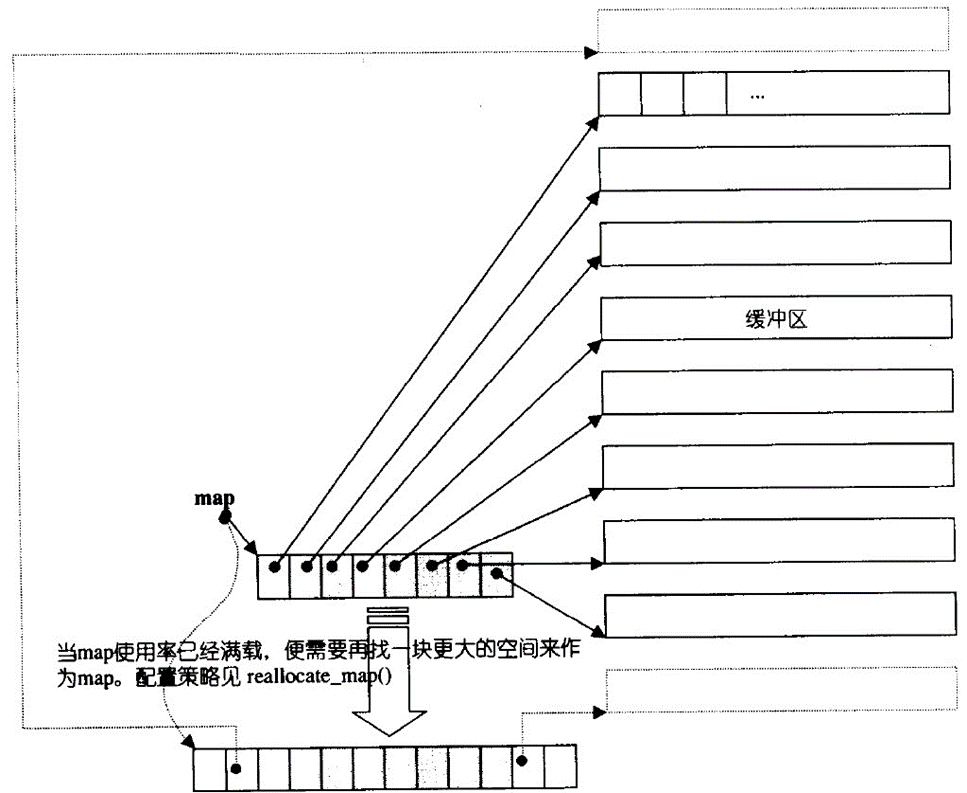
所有的小空间使用一个指针数组map进行管理的,相当于一个中控。
第一块空间的首地址存放在map的中间,第二块空间的首地址在map下一个位置,若需要头插元素,则新创建的空间首地址放在map中第一块空间首地址的前面。
双端队列底层是一段假象的连续空间,实际上是分段连续的,为了维护其“整体连续”以及随机访问的假象,这个任务落在了deque的迭代器身上,因此deque的迭代器设计就比较复杂,如下图所示:
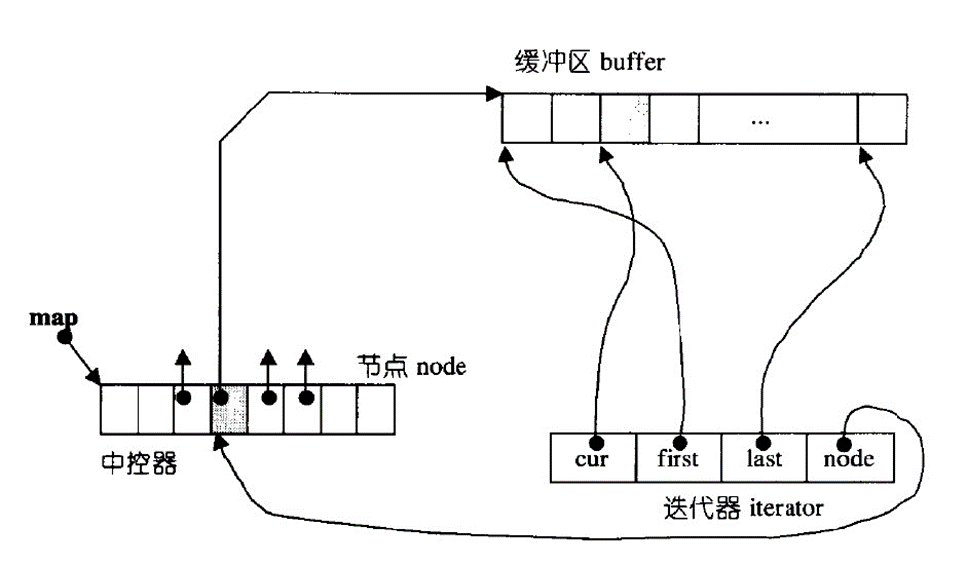
queue的iterator封装了四个指针,分别是cur、first、last、node;
first:当前元素所处缓冲区的开始
last:当前元素所处缓冲区的结束
cur:当前元素值
node:指针的指针,指向map中指向buffer的指针
deque通过迭代器start和finish维护其整体结构:
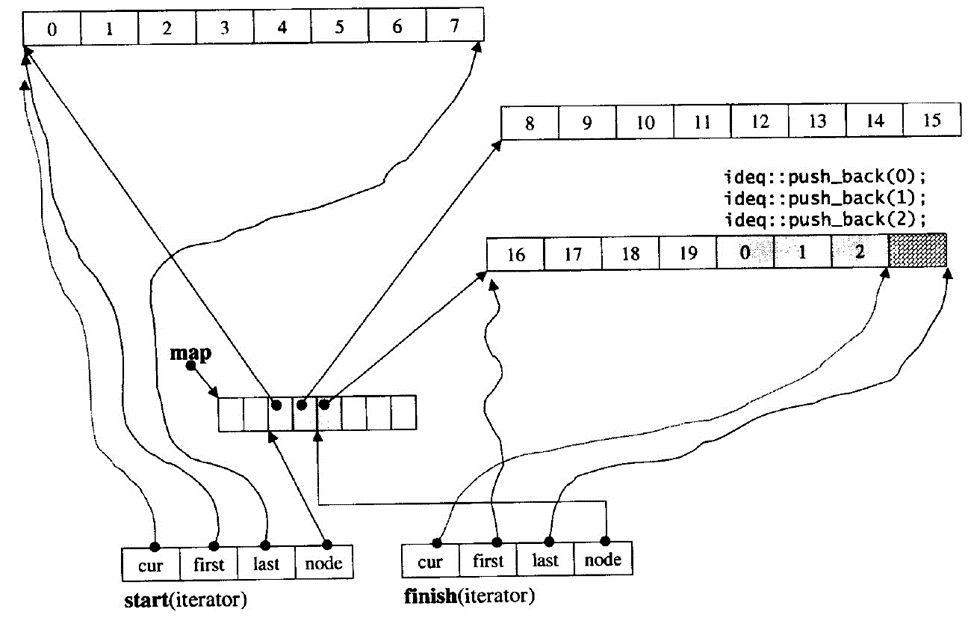
deque::begin()返回迭代器start,deque::end()返回迭代器finish,这两个迭代器都是deque的成员变量。
如果要头插元素,而此时迭代器start中node指向为第一个buffer的首地址,则需要创建一个新的buffer空间。node指向map前一个空间,*node指向新buffer的首元素地址,同时更新first、cur、last。
4.2 deque 与 vector和 list 的比较
deque的优势就是头插头删,尾插尾删,只有O(1)的时间复杂度。
但由于其复杂的底层结构,导致实现其随机访问(即[])很困难,有以下两点不足,或者说是冲突:
- 若规定
deque的每一个buffer的空间一样大(为n),那么访问第i个数据的思路:如果i不是第一个buffer中的数据,则i -= 第一个buffer的长度后,第i个数据的下标为[i/n, i%10]。若规定deque的每一个buffer不一样大,则需要依次将i减去buffer的长度,直至i小于下一个buffer的长度,才能找到第i个元素对应的位置 - 在
deque中间插入数据,若需要每个buffer的空间一样大,需要挪动所有该位置前面或者后面的数据。若不需要每个buffer空间一样大,则可以只挪动当前buffer的元素。
由此可以看到,对deque的buffer的长度是否一致的规定会影响随机访问和中间插入元素的效率。但无论怎么说,deque的随机访问是始终不如vector的,中间插入元素是始终不如list的。
| 容器 | 优点 | 缺点 |
|---|---|---|
vector | 物理结构连续存储 1.下标随机访问 2.缓存命中率高 | 1.前面部分插入删除效率低 2.扩容有损耗,还会存在一定程度空间浪费 |
list | 物理结构不一定连续 1. 任意位置插入删除效率高 2. 按需申请空间, | 1.不支持下标随机访问 2.缓存命中率高 |
deque | 1.支持下标随机访问 2. 扩容损耗小 3. 头部和尾部对元素处理效率高 4. 缓存命中率高 | 1.中间插入效率低 2.下标随机访问不如vector |
本章完。



【独一无二】](https://img-blog.csdnimg.cn/direct/9011f189160945b99764099a81484f91.png)