目录
- 一、总体概述
- 1.7系列FPGA的BRAM特点
- 2.资源情况
- 二、BRAM分类
- 1.单端口RAM
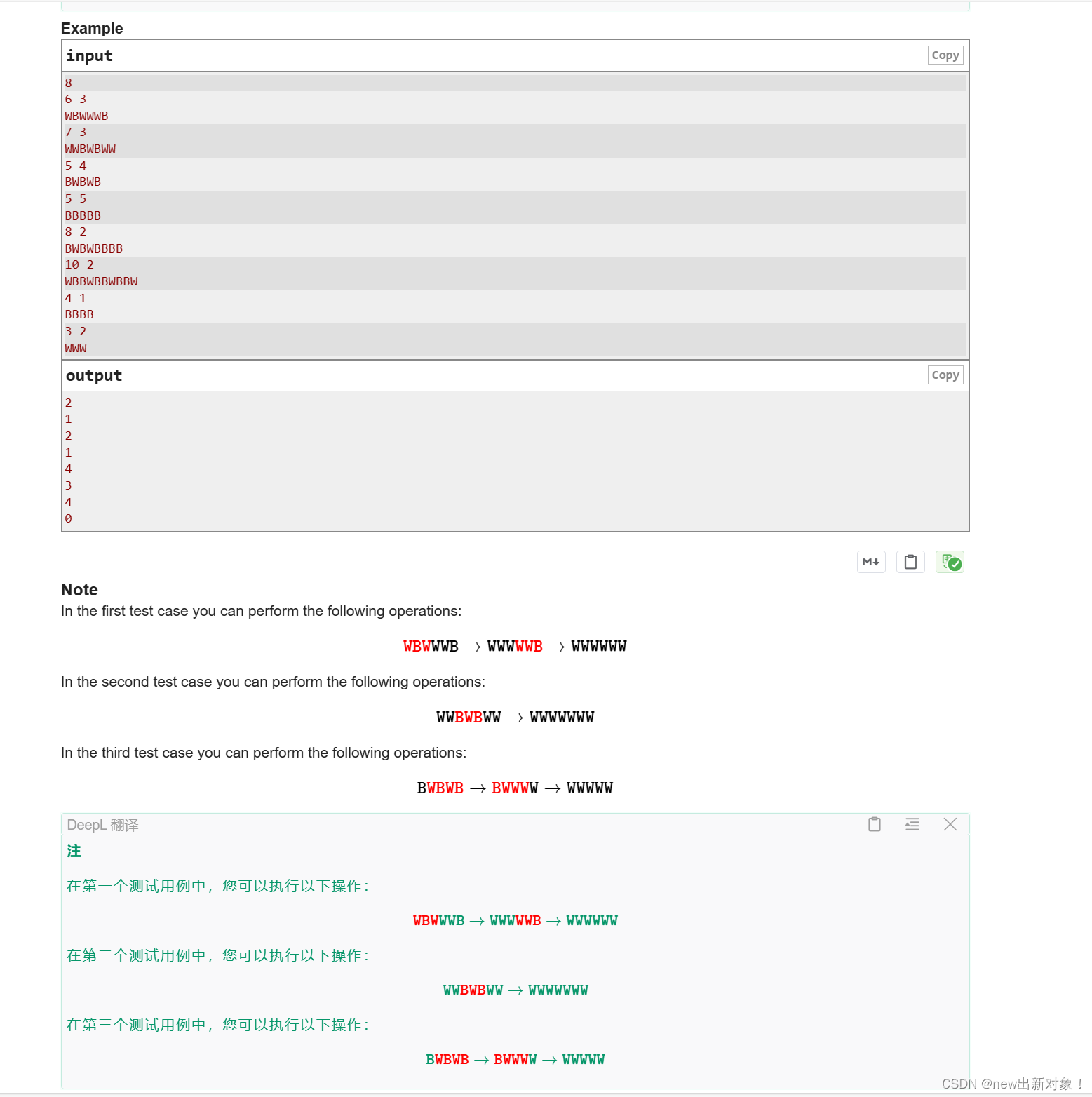
- 2.简单双端口RAM
- 3.真双端口RAM
- 三、BRAM的读写
- 1、Primitives Output Registers读操作注意事项
- 2.三种写数据模式
- (1)Write_First
- (2)Read_First
- (3)No_change
- 3.读写冲突
- (1)读写时钟同步
- (2)读写时钟异步
- 四、三种BRAM实现算法
- 1.最小面积
- 2.低功耗
- 3.固定原语
一、总体概述
Xilinx 7系列fpga中的块RAM存储高达36 Kb的数据,可以配置为两个独立的18 Kb BRAM或一个36 Kb RAM。
每个36Kb块RAM也可以配置成深度×宽度为64K × 1(当与相邻的36KB块RAM级联时)、32K × 1、16K × 2、8K × 4、4K × 9、2K × 18、1K × 36或512 × 72的简单双端口模式。
每个18Kb块RAM可以配置成深度×宽度为16K × 1、8K × 2、4K × 4、2K × 9、1K × 18或512 × 36的简单双端口模式。
为什么36Kb会配置为32K×1,少的那4Kb去哪了?
1.7系列FPGA的BRAM特点
7系列FPGA的BRAM特点如下:
- 每块的存储能力达到36Kbits
- 可以配置成两个独立的18Kb BRAM或一个36Kb的BRAM
- 每个36Kb的BRAM可以设置为512×72的简单双端口模式,每个18Kb的BRAM可以配置为512×36的简单双端口模式
- 简单双端口RAM的两个端口宽度可以不一致
- 两个相邻的块RAM可以组合成一个更深的64K x 1的存储器,而无需任何外部逻辑
- 每36 Kb BRAM或36 Kb FIFO提供一个64位纠错编码块,独立的编码/解码功能。在ECC模式下注入错误的能力
- 输出的同步设置/复位为初始值可用于块RAM输出的锁存器和寄存器模式
- 单独的同步Set/Reset引脚独立控制块RAM中可选输出寄存器和输出锁存阶段的Set/Reset
- 将块RAM配置为同步FIFO以消除标志延迟不确定性的属性
- 7系列FPGA中的FULL标志在没有任何延迟的情况下被断言
- 18、36或72位宽的块RAM端口可以为每个字节启用单独的写入
- 每个36Kb BRAM包含可选的地址和控制电路,作为内置的双时钟FIFO存储器,但是无法将36Kb的BRAM当作两个18Kb的FIFO(因为无法共享FIFO控制逻辑)
- 输出数据路径有一个可选的内部寄存器,强烈建议使用该寄存器。这允许更高的时钟速率,但是它增加了一个时钟周期延迟
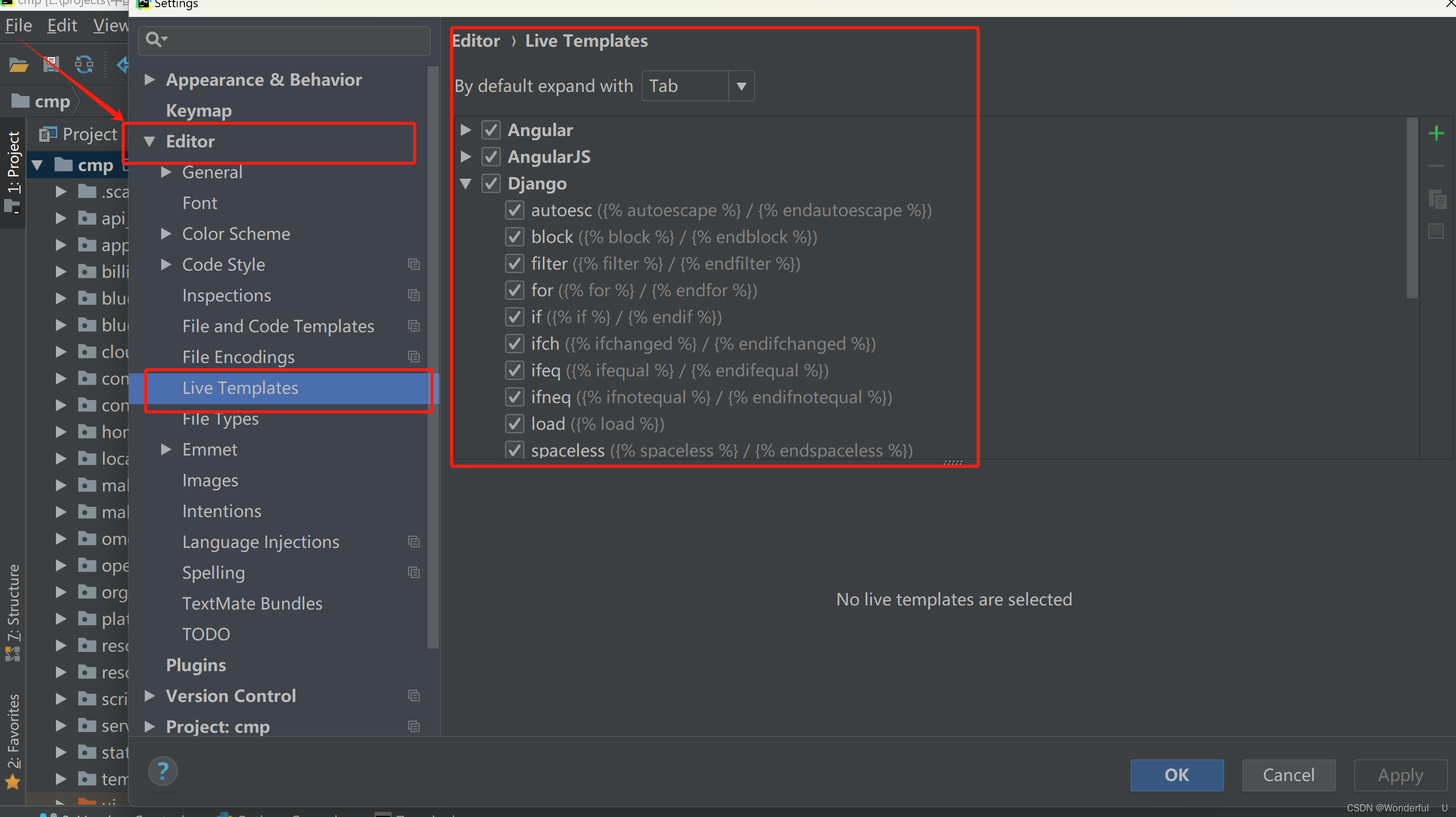
2.资源情况
在7系列FPGA中,块RAM按列排列。7系列设备的块RAM资源总数如下图所示。36kb块可级联,以最小的时间损失实现更深更宽的内存。
N
二、BRAM分类
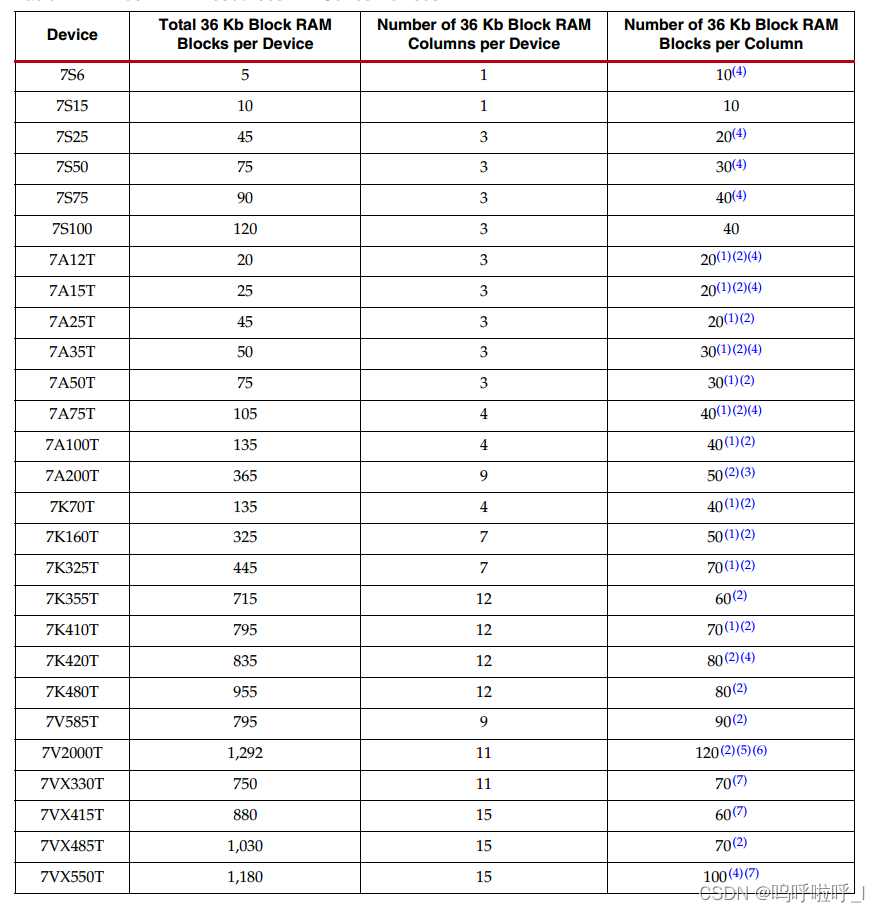
1.单端口RAM
只有一个端口,该端口可读可写。
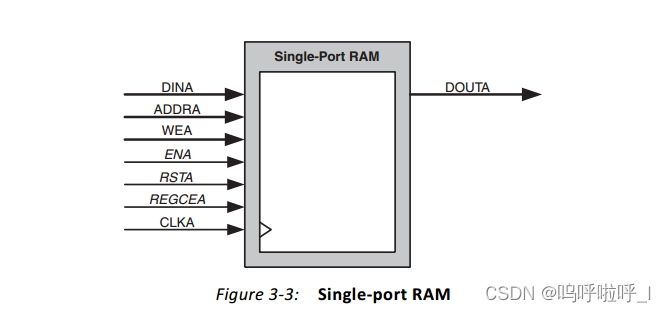
2.简单双端口RAM
有两个端口A和B,A端口用于写数据B端口用于读数据。读写数据位宽可以是倍数关系,最大为32倍。
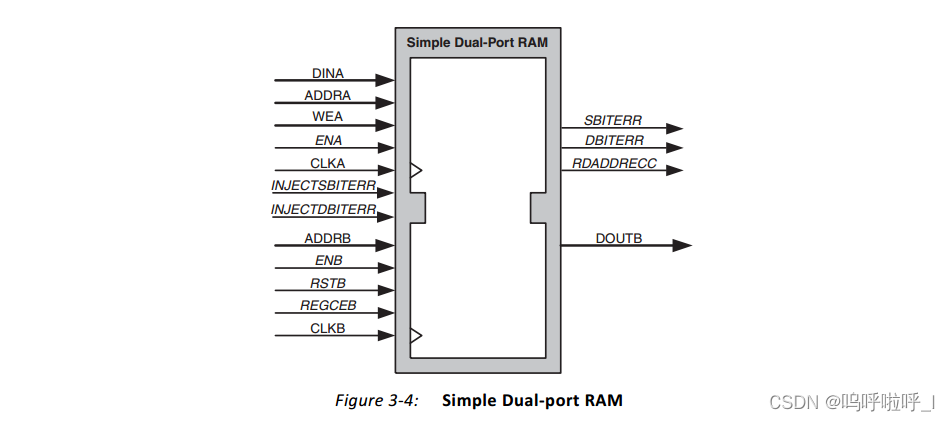
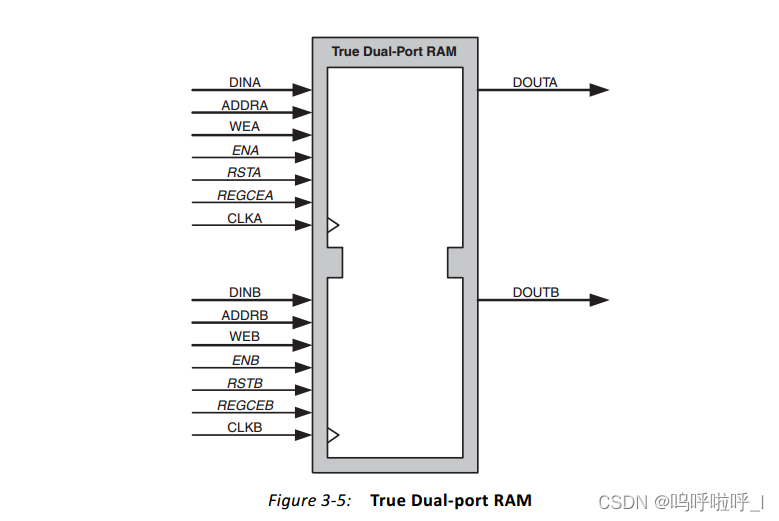
3.真双端口RAM
有两个端口A和B,A、B端口均能读写数据。读写数据位宽可以是倍数关系,最大为32倍。
三、BRAM的读写
1、Primitives Output Registers读操作注意事项
在使用BRAM IP核时我们会发现有一个选项位Primitives Output Registers:
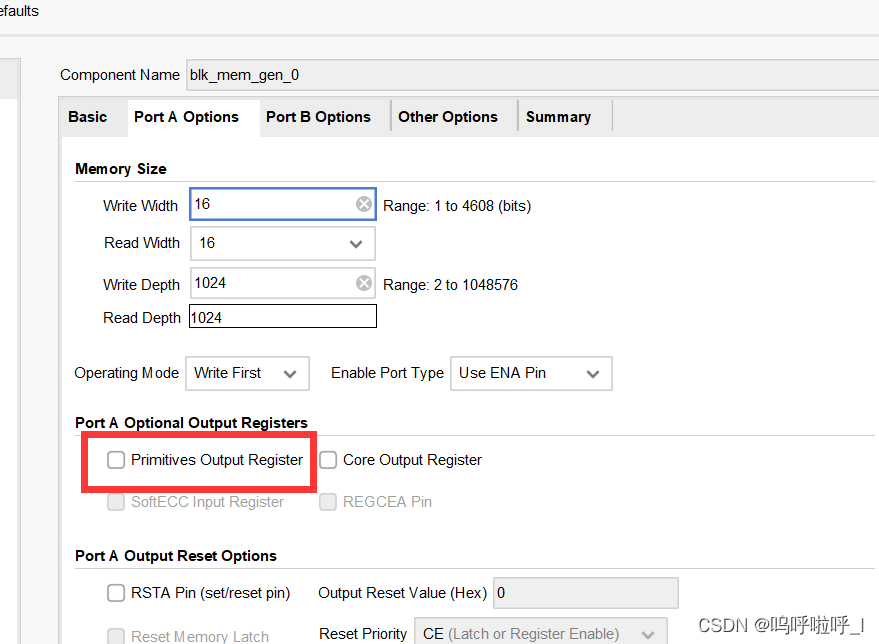
勾选它时需要注意的事项:

在锁存模式下,读操作使用一个时钟边。读地址在读端口上寄存,存储的数据在RAM访问时间之后加载到输出锁存器中。当使用输出寄存器时,读取操作需要一个额外的延迟周期。可以参考下面这篇文章,是一年多以前遇到的双口RAM数据丢失问题,当时给出了自己的猜想,没想到在这时候完成了闭环。
双口RAM输出数据丢失问题_双口ram读取不到最后一个数据-CSDN博客
2.三种写数据模式
当端口向某一个地址写数据,此时这个地址下RAM的数据输出DOUT的结果会是新写的数据还是原来的数据呢?这就和端口的写模式有关系了。
(1)Write_First
写优先模式下,写入数据的将数据写入内存,并将数据传递到输出中。即读出的数据会是新写的数据,时序图如下:
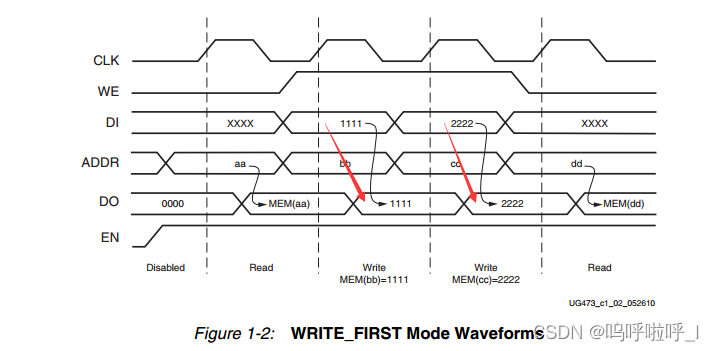
可以发现,当向地址bb写入1111时,RAM在地址bb下的输出也会变为1111.
(2)Read_First
读优先模式下,输出会是原有的数据,时序图如下:
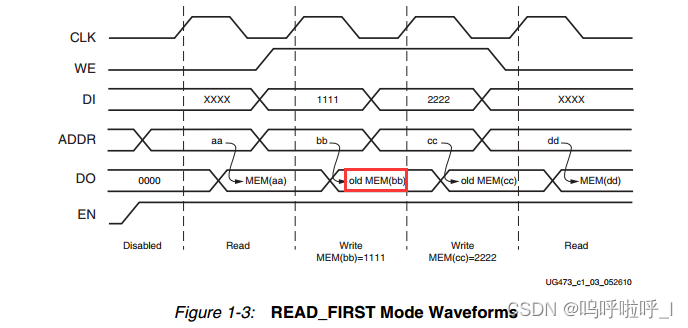
输出的内容是old mem(bb),即bb地址下的旧数据。
(3)No_change
No_change模式下,输出锁存器在写操作期间保持不变。
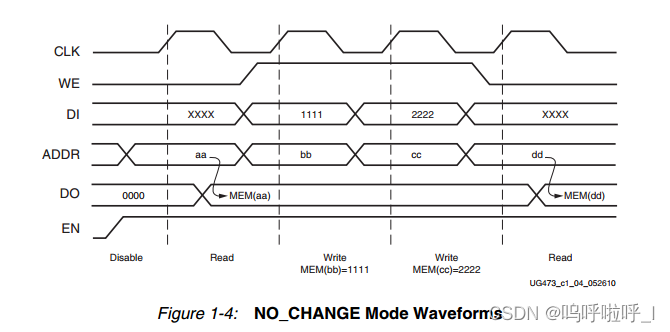
我们可以发现当检测到写使能为高时,输出一直保持MEM(aa)不变,直到检测到写使能为低,才会输出当前地址的数据,这种模式使用的功耗最低。
3.读写冲突
对于双端口RAM而言,当一个端口写另一个端口读时会存在读写冲突的可能,对于真双口RAM而言当两个端口同时写时还会出现写-写冲突的可能。
我们以读写时钟是否同步来分析:
(1)读写时钟同步
-
对于真双口RAM规定
两个端口不能同时写
两个端口可以同时读
可以一读一写
-
对于简单双口RAM无规定
(2)读写时钟异步
-
对于真双口RAM规定
两个端口不能同时写
两个端口可以同时读
不能一写一读
-
对于简单双口RAM
不能一写一读,读写需要分开
四、三种BRAM实现算法
在Block Memory Generator IP中,生成RAM时有三种算法选项,分别是:
- 最小面积(MinimumArea)
- 低功耗(Low Power)
- 固定原语(Fixed Primitives)
根据Xinlinx官方手册,下面以3K×16和5K×17的端口RAM为例介绍
1.最小面积
最小面积算法使所用的BRAM原语数量最少,同时减少了输出多路复用。
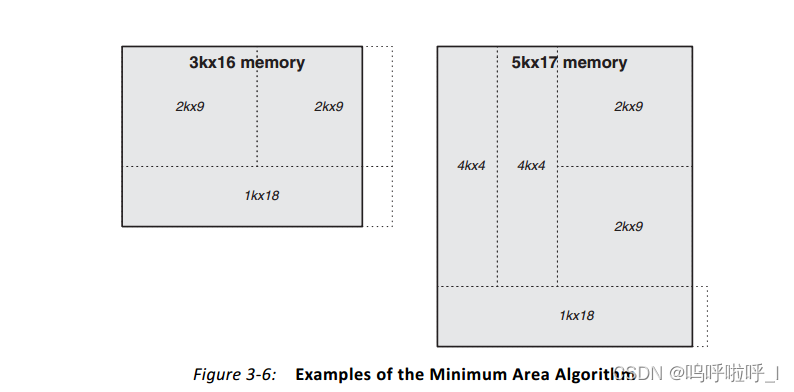
在3k×16RAM的实现中,我们用到了三个18Kb的RAM。为了能够形成对比,我们将3个1K×18的BRAM放在一列构成一个3k×16,如下图。
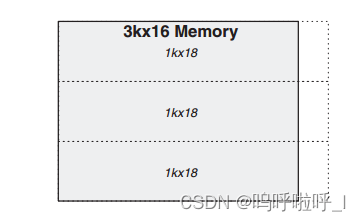
我们可以发现,在水平和垂直方向上两种方法构成的Memory长度一致,那最小面积是怎么体现出来的呢?这是因为在各个BRAM构成的RAM输出时,需要进行选择。比如对于最小面积算法,在输出时需要对上面2k×19的输出和1k×18的输出进行选择,因此只需要一个2选1多路复用器。那上面两个相邻的2K×19需要进行选择吗,其实是不用的,两个9bit宽的RAM共同构成了要输出的16bit,任何时候都是拼在一起的不需要选择。
2.低功耗
低功耗算法可以最大限度地减少在读或写操作期间启用的原语数量。该算法没有针对面积进行优化,可能比最小面积算法使用更多的BRAM和多路复用器。
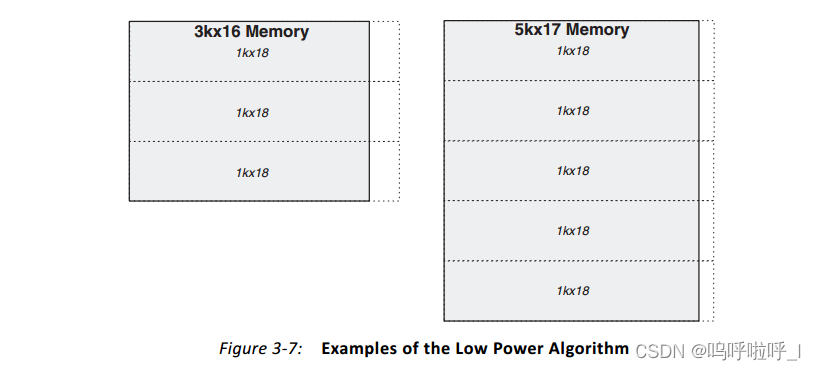
比如在上述3k×16的Memory中,3个1k×18的垂直方向排列,3个输出通过多路复用器输出到RAM外。当地址处于0-1k时只有上面一个RAM被启用,其余两个RAM不用使能,因此可以降低功耗。
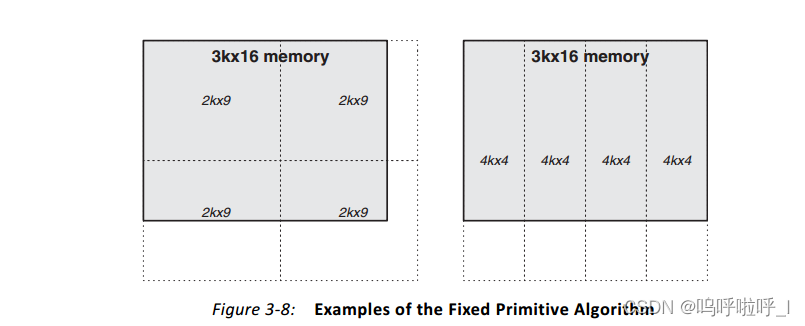
3.固定原语
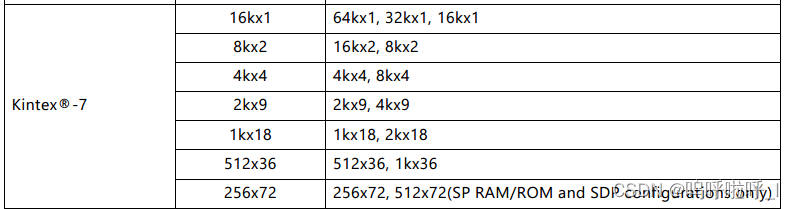
固定原语算法允许选择单个BRAM原语类型。内核通过在宽度和深度上连接这个单一的原语类型来构建内存。固定原语算法提供了16kx1、8kx2、4kx4、2kx9、1kx18和512x36原语的选择。
Xinlinx官方文档参考如下:
Block Memory Generator v8.4 Product Guide (PG058) • 查看器 • AMD 技术信息门户
7 Series FPGAs Memory Resources User Guide (UG473) • 查看器 • AMD 技术信息门户


![[Qt的学习日常]--初识Qt](https://img-blog.csdnimg.cn/direct/32bc61645d9d4b4fbb78b51a82fa7b04.png)