一、关于大语言模型
LLM 对于无数的应用程序非常有用,如果我们自己从头开始构建一个,那我们可以了解底层的ML技术,并可以根据特定需求定制LLM,但是对资源的需求巨大。大型语言模型是一种 ML 模型,可以执行各种自然语言处理任务,比如创建内容或者将文本从一种语言翻译为另一种语言。 “大”一词描述了语言模型在学习期间可以改变的参数数量,拥有数十亿、百亿、千亿,甚至万亿级别的参数。

大型学习模型必须经过预训练,然后进行微调,以教授人类语言来解决文本分类、文本生成挑战、问题解答和文档摘要。顶级大型语言模型解决各种问题的潜力在金融、医疗保健和娱乐等领域都有应用。这些 LLM 模型服务于一系列 NLP 应用程序,例如人工智能助手、聊天机器人、翻译等。大型语言模型由无数的参数组成,类似于模型在训练过程中学习时收集的记忆。您可以将这些参数视为模型的知识库。
二、Transformer 模型
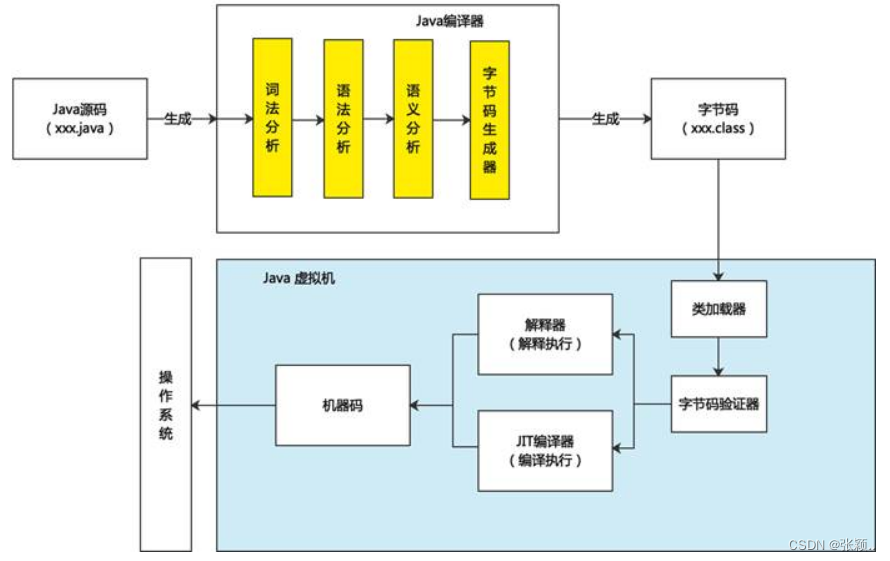
2017年,论文“ Attention is All You Need ”面世,该论文使用了一种称之为“Transformer”的新颖架构。如今,Transformer 模型是大型语言模型最常见的架构。 Transformer 模型通过对输入进行标记并进行数学方程来识别标记之间的关系来处理数据。这使得计算系统能够看到人类在给出相同查询时会注意到的模式。
此外,Transformer 模型采用自注意力机制,这使得模型比传统的扩展短期记忆模型学习得更快。自注意力允许 Transformer 模型封装序列的不同部分或完整的句子,以创建预测。

Transformer 模型在自然语言处理中发挥了重要作用。随着这项革命性技术出现并涌现了无数的大语言模型,如果对于大语言模型感兴趣,肯定要了解这项技术的工作原理。尤其重要的是了解这些模型如何处理自然语言查询,使它们能够准确地响应人类的问题和请求。
三、大型语言模型的关键要素
大型语言模型由多个神经网络层组成。这些定义的层协同工作来处理输入文本并创建所需的内容作为输出。
-
嵌入层:是大型学习模型的关键要素。嵌入层接受输入(单词序列),并将每个单词转换为向量表示。单词的这种向量表示捕获了单词的含义以及它与其他单词的关系。
-
前馈层:LLM 的前馈层由几个完全连接的层组成,用于转换输入嵌入。在执行此操作时,这些层允许模型提取更高级别的抽象,即通过文本输入确认用户的意图。
-
循环层:循环层允许LLM学习依赖性并生成语法正确且语义有意义的文本。
-
注意力机制:大语言模型中的注意力机制允许人们关注输入文本的单个元素,以验证其与手头任务的相关性。此外,这些层使模型能够创建最精确的输出。
四、大型语言模型的类型
通常,大型语言模型是根据它们所做的任务进行分类的:
Autoregressive LLMs、Transformer-Based LLMs、Multilingual Models、Hybrid Models
1、Autoregressive LLMs
大型学习模型经过训练用来生成自然语言文本。


属于此类别的大型学习模型有 Transformers、LaMDA、XLNet、BERT 和 GPT-3。
- GPT - 3 - GPT-3 是一种革命性的语言模型,有可能根据所提供的描述提供高质量和类似人类的文本。此外,GPT-3 使用数十亿个参数和技术来创建类似人类的句子。
- LaMDA - LaMDA 经过训练可以创建不同的创意文本模式,如诗歌、代码、脚本、音乐作品、电子邮件、信件等,并非正式地回答您的问题。
- XLNet - XLNet 是一种自回归语言模型,可以理解文本序列的无监督表示。
2、Transformer-Based LLMs
主要可以用来对话,此类LLM 列表有ChatGPT、BERT、BARD、InstructorGPT、Falcon-40B-instruct 等。
- BERT - BERT(来自 Transformers 的双向编码器表示)是一种动态自回归LLM,适用于深度神经工作。它的主要重点是理解单词之间的关系,而不是关注一个单词的含义。
3、Multilingual Models
多语言模型在不同的语言数据集上进行训练,可以处理和生成不同语言的文本。它们对于跨语言信息检索、多语言机器人或机器翻译等任务很有帮助。
- XLM - XLM 是 Facebook 创建的跨语言语言模型。
4、Hybrid Models
混合模型是不同架构的混合体,以提高性能。例如,将基于变压器的架构和循环神经网络(RNN)相结合以进行顺序数据处理。
- UniLM(统一语言模型)是一种混合大型语言模型,结合了自回归和序列到序列建模方法。
五、如何构建大型语言模型?
我们将使用 TensorFlow 或 PyTorch 等机器学习框架来创建模型。这些框架提供了用于创建和培训LLM的预构建工具和库,因此几乎不需要重新发明轮子。
我们首先概述LLM的架构。另外,您需要选择要使用的模型类型,例如循环神经网络变压器,以及层数和每层中的神经元数量。
接下来是使用收集的预处理数据来训练模型。
不同类型的LMM的训练是不同的。假设你想建立一个生成自然语言文本的LLM;与对话优化的LLM相比,方法将完全不同。
1、Autoregressive LLMs
第 1 步:收集数据集
第 2 步:数据集预处理和清理
接下来是数据集预处理和清理步骤。由于数据集是从众多网页和不同来源爬取的,因此数据集很可能包含各种但细微的差异。因此,消除这些细微差别并为模型训练创建高质量的数据集至关重要。
首先,实际步骤取决于您当前正在处理的数据集。
标准预处理措施包括:
- 解决拼写错误。
- 删除有偏见的数据。
- 将表情符号转换为对应的文本。
- 删除数据重复。
训练数据可能有重复或几乎相同的句子,因为它是从互联网上的众多数据源收集的。因此将重复数据删除的工作不能逃避,这样的话模型不用训练相同的数据,并且有助于更好地评估LLM,因为测试和培训数据包含非重复信息。
第 3 步:准备数据
数据集准备是清理、转换和组织数据,使其成为机器学习的理想选择。这是任何机器学习项目中的重要步骤,因为数据集的质量对模型的性能有直接影响。
在预训练阶段,LLM 接受训练来预测文本中的下一个标记。因此,相应地开发了输入和输出对。
第 4 步:定义模型架构
您可以在 Hugging Face Open LLM 排行榜上了解所有 LLM 的概览。
https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard![]() https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard 通常,研究人员从现有的大型语言模型架构(例如 GPT-3)开始。
https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard 通常,研究人员从现有的大型语言模型架构(例如 GPT-3)开始。
第 5 步:超参数调优
解决这个问题的理想方法是使用当前工作的超参数;例如,如果您正在使用 GPT-3,请将其超参数与相应的架构结合使用,然后在小范围内确定最佳超参数,然后将它们插值以获得最终模式。
主要包含位置嵌入、学习率、权重初始化、优化器、激活、损失函数、层数、参数和注意力头、密集层与稀疏层分组。
学习率调度器:经过验证的方法是随着训练的进行最小化学习率,因为它克服了局部最小值并提高了模型稳定性。
正则化:LLM通常容易出现过度拟合。因此,有必要使用 Dropout、Batch Normalization 和 L1/L2 正则化等技术来挽救模型免于过度拟合。
批量大小:理想情况下,选择适合 GPU 内存的大批量大小。
权重初始化:模型收敛很大程度上取决于训练前初始化的权重。毕竟,初始化合适的权重可以加快收敛速度。但请记住,仅在定义自己的 LLM 架构时才使用权重初始化。
2、Transformer-Based LLMs
在此类LLM中,第一步也是最重要的一步与之前相同。训练完成,LLM就有完成文本的能力。然后,为了生成特定问题的答案,LLM在监督数据集(包括问题和答案)上进行了微调。到这一步结束时,您的LLM就可以为所提出的问题创建解决方案。
例如, ChatGPT 是一个对话优化的 LLM,其训练与上面讨论的步骤类似。唯一的区别是,除了预训练和监督微调之外,它还包含一个额外的RLHF(人类反馈强化学习)步骤。
六、如何评估大语言模型?
大语言模型的评价不能是主观的。相反,它必须是评估LLM表现的逻辑过程。
如果是分类任务或回归挑战场景中的评估,比较实际表和预测标签有助于了解模型的性能。通常,我们会为此查看混淆矩阵。但是LLM是生成文本的,我们怎么办?
1、内在方法
传统的语言模型是使用每个字符的位数、困惑度、BLUE 分数等内在方法进行评估的。这些度量参数跟踪语言方面的性能,即模型在预测下一个单词方面的表现。
- 困惑度:困惑度是衡量LLM预测序列中下一个单词的能力的指标。较低的困惑度表明更好的性能。
- BLEU 分数: BLEU 分数衡量LLM生成的文本与参考文本的相似程度。 BLEU 分数越高表示性能越好。
- 人工评估:人工评估涉及要求人工评委对LLM生成的文本的质量进行评分。这可以通过使用各种不同的评估来实现,例如流畅性、连贯性和相关性。
此外,同样重要的是要注意,不存在一刀切的评估指标。每个指标都有自己的优点和缺点。因此,有必要使用各种不同的评估方法来全面了解LLM的表现。
以下是评估LLM的一些额外注意事项:
- 数据集偏差:LLM接受大型文本和代码数据集的训练。如果这些数据集有偏差,那么LLM也会受到限制。必须意识到数据集中可能存在偏差并采取措施减轻偏差。
- 安全:LLM可用于生成有害内容,例如仇恨言论和错误信息。制定保护机制以防止LLM被用来创建有害内容至关重要。
- 透明度:LLM的培训和评估方式必须保持透明。这将有助于建立对LLM的信任并确保负责任地使用它们。
2.) 外部方法
随着当今LLM的进步,外在方法正在成为评估LLM表现的首选。建议评估LLM的方法是考察他们在推理、解决问题、计算机科学、数学问题、竞争性考试等不同任务中的表现。
EleutherAI推出了一个名为语言模型评估框架的框架来比较和评估LLM的表现。 HuggingFace 集成了评估框架来衡量社区创建的开源LLM。
该框架评估四个不同数据集的LLM。最终得分是每个数据集得分的累加。以下是参数:
- A12 推理 -这是为小学生设计的科学问题集。
- MMLU -这是一项评估文本模型的多任务精度的综合测试。它包含 57 项不同的任务,包括美国历史、数学、法律等科目。
- TruthfulQA -此测试评估模型创建准确答案并跳过生成在线常见虚假信息的倾向。
- HellaSwag -这是一项挑战最先进模型的测试,以做出对人类来说很容易的常识性推论,精度为 95%。