简要介绍
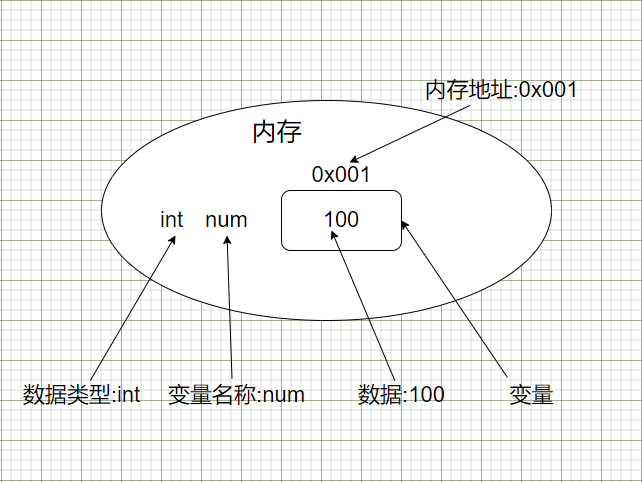
在Go的内存分配中存在几个关键结构,分别是page、mspan、mcache、mcentral、mheap,其中mheap中又包括heapArena,具体这些结构在内存分配中担任什么角色呢?
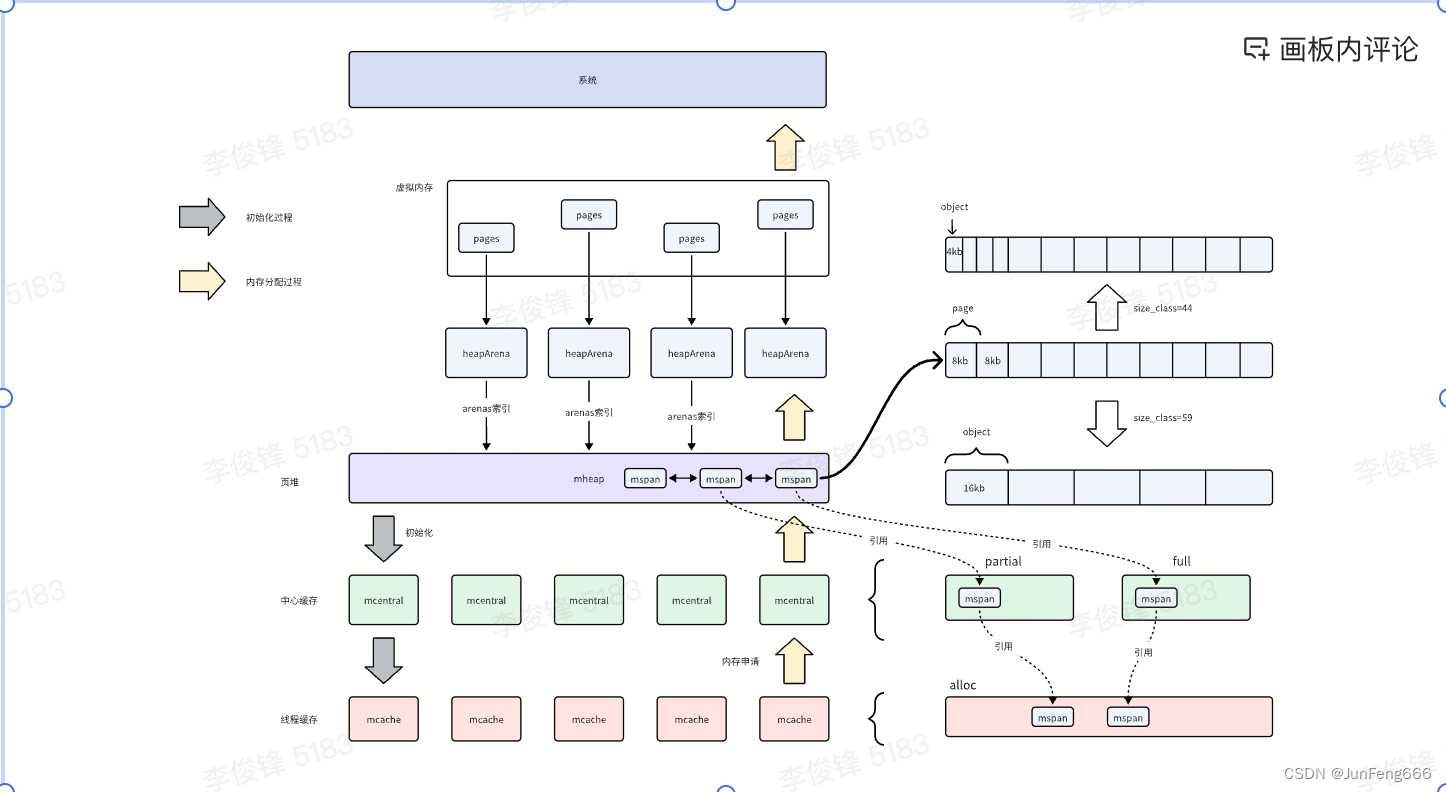
如下图,可以先看一下整体的结构:
mcache是线程缓存,GMP调度模型中,每个P对象都会绑定一个mcache对象,用来分配内存;- 当
mcache内存不够的时候会向mcentral申请内存,mcentral如果有合适大小(即size_class)的内存会直接分配给mcache; - 如果
mcentral也不够,就会继续向上从mheap中申请内存,mheap如果有空闲内存就直接分配(这里如果请求的页数较小,会直接从P对象绑定的页缓存分配),如果不够就会继续向系统申请; mheap向系统申请内存的时候最小粒度是page,mheap通常会申请若干页的内存,即pages,这些page会通过heapArena来管理,一个heapArena可以管理64M的内存,heapArena可以认为是虚拟内存管理单元
调用关系图:
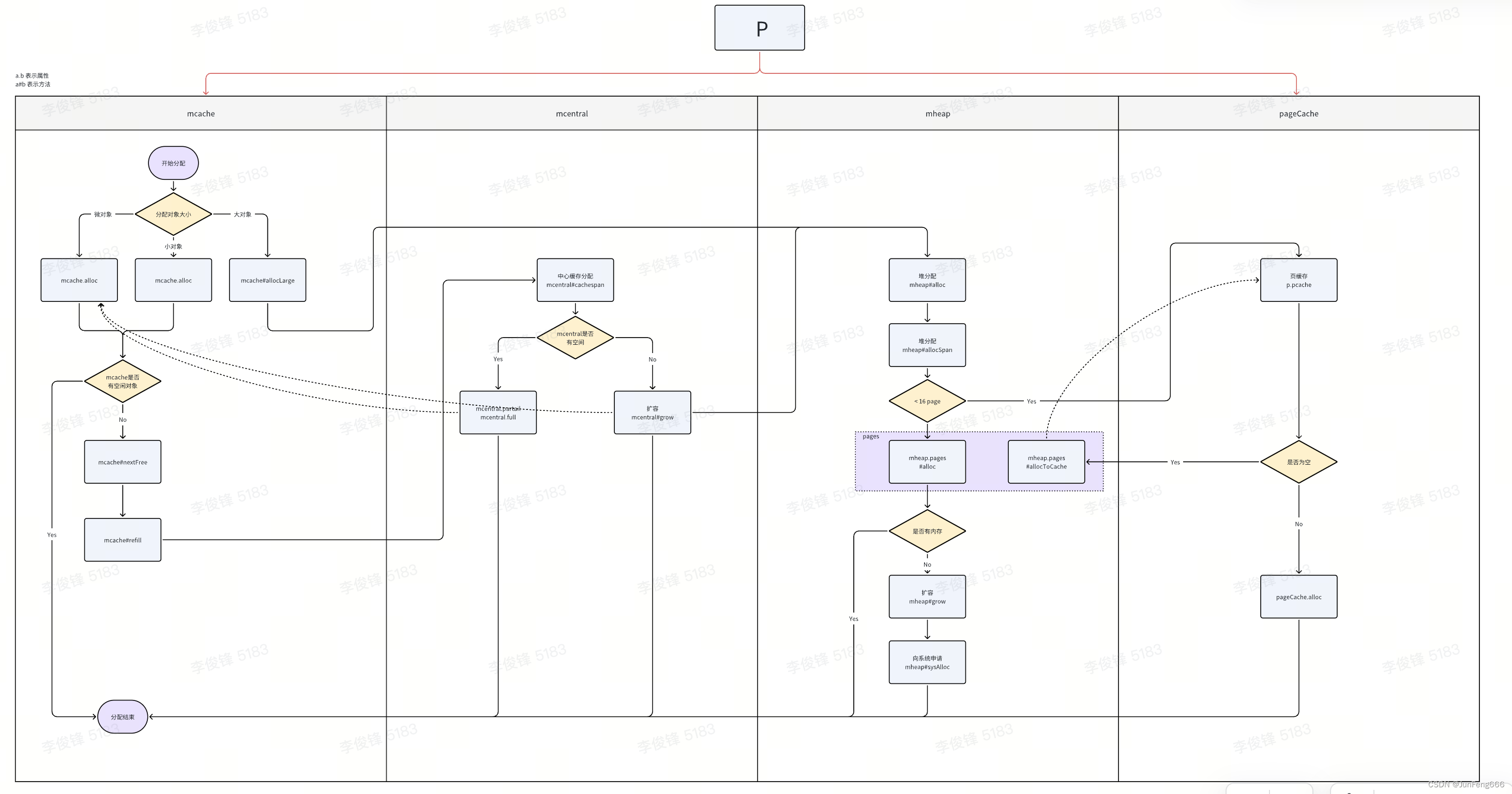
内存管理组件
page
内存页,一块 8KB 大小的内存空间,也是最小粒度的内存空间单元。Go 与操作系统之间的内存申请和释放,都是以 page 为单位的。注意这里的page不是操作系统的page
mspan
// runtime/sizeclasses.go
const (_NumSizeClasses = 68
)
var class_to_size = [_NumSizeClasses]uint16{0, 8, 16, 24, 32, 48, 64, 80, 96, 112, 128, 144, 160, 176, 192, 208, 224, 240, 256, 288, 320, 352, 384, 416, 448, 480, 512, 576, 640, 704, 768, 896, 1024, 1152, 1280, 1408, 1536, 1792, 2048, 2304, 2688, 3072, 3200, 3456, 4096, 4864, 5376, 6144, 6528, 6784, 6912, 8192, 9472, 9728, 10240, 10880, 12288, 13568, 14336, 16384, 18432, 19072, 20480, 21760, 24576, 27264, 28672, 32768}//go:notinheap
type mspan struct {next *mspanprev *mspanstartAddr uintptr // mspan起始地址npages uintptr // 记录mspan中page的数量freeindex uintptr // 空闲对象索引nelems uintptr // 记录这个mspan中object的数量allocCache uint64 // bitmap,记录对象是否被分配allocCount uint16 // 已分配对象个数spanclass spanClass // 规格,表示size_class和是否包含指针
}
mspan是内存管理的基本单元,是由一串连续page组成的大块内存单元;每个mspan会根据自身size class的大小将内存分割成对应大小的若干个object,每个object可存储一个对象。
举例来说,一个page大小是8k,如果按照size
class=2来分割,一个object大小就是8个字节,那么一个page会被分割成1024个object。
为了提高内存分配效率,降低内存分配过程中锁冲突,go将size class规格划分为68个,对象会被分配在相匹配的size class的对象上,相同规格的mspan之间用链表管理,例如一个12字节的对象,会四舍五入被分配在16字节的size class上。
spanClass是一个8位的数据,前7位存储size class的值,即68个size
class的一个,第八位存储是否包含指针,比如size
class=2,那么前7位就是0000010,如果不存在指针,那么最后一位就是1,所以spanClass的值就是00000101,即5。
下面附上size class不同规格的数据:
- tail waste: 由于每个span的大小并不一定能整除单个object大小,所以在mspan末尾会有一定的浪费,以class=5举例,8192-48*170=32,32即是tail waste。
- max waste:该class的mspan最大有多少的浪费,同样以class=5举例,该class每个对象48b,总共170个对象,按照所有申请的内存大小都是33b来算,((48-33)*170+32)/8192=0.3152。
- min align 最小对齐,表示分配给该size class的对象,内存对齐必须满足这个要求。例如,如果某个class=5的最小对齐为 16 字节,那么分配给该类的对象的起始地址必须是 16 的倍数。
// runtime/sizeclasses.go// class bytes/obj bytes/span objects tail waste max waste min align
// 1 8 8192 1024 0 87.50% 8
// 2 16 8192 512 0 43.75% 16
// 3 24 8192 341 8 29.24% 8
// 4 32 8192 256 0 21.88% 32
// 5 48 8192 170 32 31.52% 16
// 6 64 8192 128 0 23.44% 64
// 7 80 8192 102 32 19.07% 16
// 8 96 8192 85 32 15.95% 32
// 9 112 8192 73 16 13.56% 16
// 10 128 8192 64 0 11.72% 128
// 11 144 8192 56 128 11.82% 16
// 12 160 8192 51 32 9.73% 32
// 13 176 8192 46 96 9.59% 16
// 14 192 8192 42 128 9.25% 64
// 15 208 8192 39 80 8.12% 16
// 16 224 8192 36 128 8.15% 32
...
// 61 19072 57344 3 128 3.57% 128
// 62 20480 40960 2 0 6.87% 4096
// 63 21760 65536 3 256 6.25% 256
// 64 24576 24576 1 0 11.45% 8192
// 65 27264 81920 3 128 10.00% 128
// 66 28672 57344 2 0 4.91% 4096
// 67 32768 32768 1 0 12.50% 8192
mcache
mcache是线程缓存,运行时每个P都会单独绑定一个mcache,每个mcache中包括所有size class的mspan,这样在不同goroutine并发申请内存的时候,分别从自己的P对象中分配对应规格的内存即可,不需要加锁,可以有效减少竞争带来的性能损耗。
P初始化的时候调用runtime/mcache.go#allocmcache()给mcache赋值,从函数中可以看出,实际上mcache在初始化的时候是没有实际分配mspan资源的,之后会在使用过程中动态申请。
allocmcache在两个地方调用,一个是系统初始化,另一个是创建P对象
// runtime/mcache.go//go:notinheap
type mcache struct {scanAlloc uintptr // bytes of scannable heap allocated// 微对象内存分配器使用,见后面微对象内存分配tiny uintptrtinyoffset uintptrtinyAllocs uintptr// 相同size class的mspan放在一起,这里numSpanClasses=136,为什么不等于68呢,原因是mcache上每个size class都包括一个scan对象和一个noscan对象,noscan对象没有指针,因此不需要被垃圾回收扫描,可以提高GC效率,同时复制对象的时候,也不需要考虑指针,在栈扩容的时候直接复制然后迁移即可// 所有规格的mspan,分配内存的时候就是从这里分配alloc [numSpanClasses]*mspan // 线程级栈缓存,栈内存分配时使用stackcache [_NumStackOrders]stackfreelist
}
mcentral
mcentral是中心缓存,对上负责从mheap中申请内存,对下负责管理mcache,其中mcentral对所有goroutine都可见,所以会通过加锁的方式解决多个goroutine竞争问题。同时mcentral也对应不同size class规格,每种规格的mcentral负责对应规格的mcache分配。
// runtime/mcentral.gotype mcentral struct {spanclass spanClasspartial [2]spanSet // list of spans with a free objectfull [2]spanSet // list of spans with no free objects
}
mcentral通过两个spanset(partial和full)来管理span,一个维护空闲的span,当mcache需要申请新的span的时候,直接从partial中获取,当span中object被用光之后,会将对应的span转移到full中,回收后再次放到partial。
其中每个spanset数组长度都是2,其中一个spanSet存放被GC清扫过的span,另一个存放未被清扫的span
内存分配
func (c *mcentral) cacheSpan() *mspan {... sg := mheap_.sweepgen// 从仍有空闲空间的且已清扫过的spanSet中获取mspanif s = c.partialSwept(sg).pop(); s != nil {goto havespan}sl = sweep.active.begin()if sl.valid {// spanBudget=100,最多寻找100次for ; spanBudget >= 0; spanBudget-- {// 从仍有空闲空间的且未清扫过的spanSet中获取mspans = c.partialUnswept(sg).pop()if s == nil {break}if s, ok := sl.tryAcquire(s); ok {// We got ownership of the span, so let's sweep it and use it.s.sweep(true)sweep.active.end(sl)goto havespan}}for ; spanBudget >= 0; spanBudget-- {// 从没有空闲空间且未被清扫过的spanSet中获取mspans = c.fullUnswept(sg).pop()if s == nil {break}if s, ok := sl.tryAcquire(s); ok {// We got ownership of the span, so let's sweep it.s.sweep(true)// Check if there's any free space.freeIndex := s.nextFreeIndex()if freeIndex != s.nelems {s.freeindex = freeIndexsweep.active.end(sl)goto havespan}// 如果清扫过后仍然没有空闲空间,就放到fullSwept中c.fullSwept(sg).push(s.mspan)}}sweep.active.end(sl)}...// 如果走到此处,说明mcentral中也没有空闲内存了,接下来就从mheap中申请新的内存s = c.grow()if s == nil {return nil}
havespan:...// 判断是否仍有空闲的spann := int(s.nelems) - int(s.allocCount)if n == 0 || s.freeindex == s.nelems || uintptr(s.allocCount) == s.nelems {throw("span has no free objects")}freeByteBase := s.freeindex &^ (64 - 1)whichByte := freeByteBase / 8// 初始化allocCaches.refillAllocCache(whichByte)// Adjust the allocCache so that s.freeindex corresponds to the low bit in// s.allocCache.s.allocCache >>= s.freeindex % 64return s
}
扩容
可以看到如果mcentral中内存也不够,就会通过grow来向mheap申请内存,接下来再看grow函数
func (c *mcentral) grow() *mspan {// 快速索引到对应的sizeClass需要分配几个pagenpages := uintptr(class_to_allocnpages[c.spanclass.sizeclass()])// 快速索引,对应的sizeClass一个object大小是多少size := uintptr(class_to_size[c.spanclass.sizeclass()])// 从mheap中获取新的spans := mheap_.alloc(npages, c.spanclass)if s == nil {return nil}// Use division by multiplication and shifts to quickly compute:// n := (npages << _PageShift) / size// 计算可以分成多少对象,_PageShift=13,即n页*8kb*1024n := s.divideByElemSize(npages << _PageShift)// 更新mspan的边界位置s.limit = s.base() + size*nheapBitsForAddr(s.base()).initSpan(s)return s
}
mheap
mheap负责管理整个go程序的内存,在程序初始化的时候分配内存,可以看到,go程序使用mheap_全局变量来管理所有堆内存,也即意味着,在程序向meap_申请内存的时候,需要加锁
mheap中同样存在68*2个size class的mcentral,同样规格的mcache会从同样规格的mcentral中申请内存,这样也可以免于不同规格的mcache申请内存时互相竞争,只需要在相同规格的mcentral中加锁即可
type mheap struct {// lock must only be acquired on the system stack, otherwise a g// could self-deadlock if its stack grows with the lock held.lock mutexallspans []*mspan // 存储所有的mspanarenas [1 << arenaL1Bits]*[1 << arenaL2Bits]*heapArena// central is indexed by spanClass.central [numSpanClasses]struct {mcentral mcentralpad [cpu.CacheLinePadSize-unsafe.Sizeof(mcentral{})%cpu.CacheLinePadSize]byte}
}
heapArena
什么是arena呢?通常来说,arena包含两个部分:
- 一个大的连续内存块,该内存块只需要预先分配一次
- 上述内存块的管理策略(包括内存的分配和回收)
可以认为arena是抽象出来的对系统内存的管理层,而heapArena则表示稀疏内存的arena
在 Go 语言 1.10 以前的版本,堆区的内存空间都是连续的;但是在 1.11 版本,Go 团队使用稀疏的堆内存空间替代了连续的内存,解决了连续内存带来的限制以及在特殊场景下可能出现的问题。
稀疏内存
稀疏内存是 Go 语言在 1.11 中提出的方案,使用稀疏的内存布局不仅能移除堆大小的上限,还能解决 C 和 Go 混合使用时的地址空间冲突问题。不过因为基于稀疏内存的内存管理失去了内存的连续性这一假设,这也使内存管理变得更加复杂:
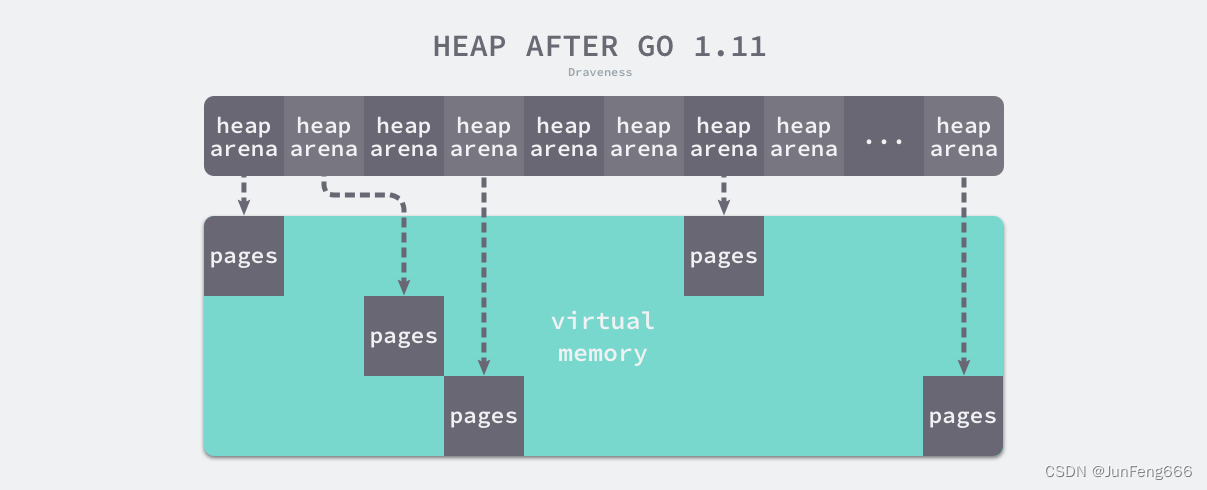
如上图所示,运行时使用二维的 runtime.heapArena 数组管理所有的内存,每个单元都会管理 64MB 的内存空间
// A heapArena stores metadata for a heap arena. heapArenas are stored
// outside of the Go heap and accessed via the mheap_.arenas index.
//
//go:notinheap
// notinheap标记表示一个类型不能从GC堆上申请内存,在运行时长用于实现低层次的内部结构,以避免调度器和内存分配中的写屏障,从而提高性能
// 通常两种情况下会使用:
// 1. 内存管理:用于声明内存管理结构体,确保这些结构不会逃逸到堆上,并在内存管理中正确处理
// 2. 逃逸分析:用于跳过编译器的逃逸检测,以便在运行时实现更高效的内存分配和管理
type heapArena struct {bitmap [heapArenaBitmapBytes]bytespans [pagesPerArena]*mspanzeroedBase uintptr // 指针,指向该heapArena管理的内存基地址
}
上述设计将原有的连续大内存切分成稀疏的小内存,而用于管理这些内存的元信息也被切成了小块。
不同平台和架构的二维数组大小可能完全不同,如果我们的 Go 语言服务在 Linux 的 x86-64 架构上运行,二维数组的一维大小会是 1,而二维大小是 4,194,304,因为每一个指针占用 8 字节的内存空间,所以元信息的总大小为 32MB。由于每个 runtime.heapArena 都会管理 64MB 的内存,整个堆区最多可以管理 256TB 的内存,这比之前的 512GB 多好几个数量级。
内存分配
func (h *mheap) alloc(npages uintptr, spanclass spanClass) *mspan {// Don't do any operations that lock the heap on the G stack.// It might trigger stack growth, and the stack growth code needs// to be able to allocate heap.var s *mspan// 系统栈上运行systemstack(func() {// To prevent excessive heap growth, before allocating n pages// we need to sweep and reclaim at least n pages.if !isSweepDone() {// 先回收一部分内存,主要是为了阻止内存的大量占用和堆的增长,所以在分配对应页数的内存前需要先回收h.reclaim(npages)}// 分配内存s = h.allocSpan(npages, spanAllocHeap, spanclass)})return s
}
可以看到重点逻辑在allocSpan函数中
func (h *mheap) allocSpan(npages uintptr, typ spanAllocType, spanclass spanClass) (s *mspan) {gp := getg()base, scav := uintptr(0), uintptr(0)growth := uintptr(0)...pp := gp.m.p.ptr()// 如果申请的内存比较小,则直接从pcache中分配// pageCachePages在64位系统中是64,所以申请的内存小于16页,则直接从pcache中申请// needPhysPageAlign只在openbsd系统上才为trueif !needPhysPageAlign && pp != nil && npages < pageCachePages/4 {c := &pp.pcache// 如果pcache为空,则申请新内存并赋值给pcacheif c.empty() {lock(&h.lock)*c = h.pages.allocToCache()unlock(&h.lock)}// 执行分配动作base, scav = c.alloc(npages)if base != 0 {s = h.tryAllocMSpan()if s != nil {goto HaveSpan}// We have a base but no mspan, so we need// to lock the heap.}}// 如果申请的内存比较大,或线程的也缓存内存也不够,就从heap的pages上获取内存if base == 0 {// Try to acquire a base address.base, scav = h.pages.alloc(npages)if base == 0 {var ok bool// 如果mheap内存也不够,就从系统申请内存growth, ok = h.grow(npages)if !ok {unlock(&h.lock)return nil}// 从pages上重新申请base, scav = h.pages.alloc(npages)if base == 0 {throw("grew heap, but no adequate free space found")}}}if s == nil {// 分配一个mspans = h.allocMSpanLocked()}...HaveSpan:// 初始化mspan的参数s.init(base, npages)...// 手动分配内存,只要不是通过heap来管理都可以认为是手动管理内存if typ.manual() {...} else {// 给span各项参数赋值s.spanclass = spanclasss.freeindex = 0s.allocCache = ^uint64(0) // all 1s indicating all free.... }...// 建立mspan和mheap的联系h.setSpans(s.base(), npages, s)
}
总结一下mheap的内存分配流程
- 如果申请的内存比较小,那么就从
pcache中分配 - 如果申请的内存比较大或
pcache中也没有空闲内存,那么就从页堆上分配 - 如果页堆上内存也不够,就调用
grow从系统申请,然后再进行分配
扩容
接下来再看看如果mheap内存不够,是怎么从系统申请内存的:
// 申请新内存并返回申请内存的大小和是否成功申请
func (h *mheap) grow(npage uintptr) (uintptr, bool) {// We must grow the heap in whole palloc chunks.ask := alignUp(npage, pallocChunkPages) * pageSizetotalGrowth := uintptr(0)end := h.curArena.base + asknBase := alignUp(end, physPageSize)// 如果内存不够,则调用sysAlloc向系统申请内存if nBase > h.curArena.end || /* overflow */ end < h.curArena.base {av, asize := h.sysAlloc(ask)if av == nil {print("runtime: out of memory: cannot allocate ", ask, "-byte block (", memstats.heap_sys, " in use)\n")return 0, false}if uintptr(av) == h.curArena.end {// 和上一次申请的空间是连续空间,则直接把end延伸即可h.curArena.end = uintptr(av) + asize} else {// 空间不连续if size := h.curArena.end - h.curArena.base; size != 0 {h.pages.grow(h.curArena.base, size)}// Switch to the new space.h.curArena.base = uintptr(av)h.curArena.end = uintptr(av) + asize}}// Grow into the current arena.v := h.curArena.baseh.curArena.base = nBase...h.pages.grow(v, nBase-v)totalGrowth += nBase - vreturn totalGrowth, true
}
如果内存不够则调用sysAlloc向系统申请内存
func (h *mheap) sysAlloc(n uintptr) (v unsafe.Pointer, size uintptr) {n = alignUp(n, heapArenaBytes)// 首先从预先保留的区域中申请内存v = h.arena.alloc(n, heapArenaBytes, &memstats.heap_sys)if v != nil {size = ngoto mapped}// 根据arenaHints再目标地址上扩容,arenaHints用来记录heapArena的地址,是一个单向链表for h.arenaHints != nil {hint := h.arenaHintsp := hint.addr...h.arenaHints = hint.nexth.arenaHintAlloc.free(unsafe.Pointer(hint))}...if size == 0 {// All of the hints failed, so we'll take any// (sufficiently aligned) address the kernel will give// us.v, size = sysReserveAligned(nil, n, heapArenaBytes)if v == nil {return nil, 0}// Create new hints for extending this region.hint := (*arenaHint)(h.arenaHintAlloc.alloc())hint.addr, hint.down = uintptr(v), truehint.next, mheap_.arenaHints = mheap_.arenaHints, hinthint = (*arenaHint)(h.arenaHintAlloc.alloc())hint.addr = uintptr(v) + sizehint.next, mheap_.arenaHints = mheap_.arenaHints, hint}...mapped:// 初始化heapArena来管理新申请的内存for ri := arenaIndex(uintptr(v)); ri <= arenaIndex(uintptr(v)+size-1); ri++ {l2 := h.arenas[ri.l1()]if l2 == nil {// Allocate an L2 arena map.l2 = (*[1 << arenaL2Bits]*heapArena)(persistentalloc(unsafe.Sizeof(*l2), goarch.PtrSize, nil))if l2 == nil {throw("out of memory allocating heap arena map")}atomic.StorepNoWB(unsafe.Pointer(&h.arenas[ri.l1()]), unsafe.Pointer(l2))}if l2[ri.l2()] != nil {throw("arena already initialized")}var r *heapArenar = (*heapArena)(h.heapArenaAlloc.alloc(unsafe.Sizeof(*r), goarch.PtrSize, &memstats.gcMiscSys))if r == nil {r = (*heapArena)(persistentalloc(unsafe.Sizeof(*r), goarch.PtrSize, &memstats.gcMiscSys))if r == nil {throw("out of memory allocating heap arena metadata")}}// Add the arena to the arenas list.if len(h.allArenas) == cap(h.allArenas) {size := 2 * uintptr(cap(h.allArenas)) * goarch.PtrSizeif size == 0 {size = physPageSize}newArray := (*notInHeap)(persistentalloc(size, goarch.PtrSize, &memstats.gcMiscSys))if newArray == nil {throw("out of memory allocating allArenas")}oldSlice := h.allArenas*(*notInHeapSlice)(unsafe.Pointer(&h.allArenas)) = notInHeapSlice{newArray, len(h.allArenas), int(size / goarch.PtrSize)}copy(h.allArenas, oldSlice)// Do not free the old backing array because// there may be concurrent readers. Since we// double the array each time, this can lead// to at most 2x waste.}// 扩容并把新的heapArena放到allArenas中h.allArenas = h.allArenas[:len(h.allArenas)+1]h.allArenas[len(h.allArenas)-1] = ri// Store atomically just in case an object from the// new heap arena becomes visible before the heap lock// is released (which shouldn't happen, but there's// little downside to this).atomic.StorepNoWB(unsafe.Pointer(&l2[ri.l2()]), unsafe.Pointer(r))}
}
总结一下系统分配内存的步骤:
sysAlloc方法会调用runtime.linearAlloc.alloc预先保留的内存中申请一块可以使用的空间- 如果没有会调用
sysReserve方法会从操作系统中申请内存 - 最后初始化一个heapArena来管理刚刚申请的内存,然后将创建
heapArena放入到arenas列表中。
内存分配
堆内存初始化
- go tool compile -N -l -S xxx.go执行后会生成xxx.o文件
- go tool objdump xxx.o 即可反汇编出代码 比较简单的代码可以用https://go.godbolt.org/
可实时生成汇编代码
// runtime/proc.go注意此处调用顺序,后面的init函数会对前面init有数据依赖,调用顺序可参考汇编命令
CALL runtime·args(SB)
CALL runtime·osinit(SB)
CALL runtime·schedinit(SB)// The bootstrap sequence is:
//
// call osinit
// call schedinit
// make & queue new G 初始化G对象
// call runtime·mstart 用来初始化M对象,在汇编命令中实际调用的方法是mstart0()
//
// The new G calls runtime·main.
func schedinit() {...// 内存初始化mallocinit() ...// 在procresize函数中对mcache0回收,mcache0用于辅助初始化,完成初始化后就会被回收if procresize(procs) != nil {throw("unknown runnable goroutine during bootstrap")}
}
// runtime/memalloc.go// 重点是对全局变量mheap_的初始化
func mallocinit() {// 微对象检查if class_to_size[_TinySizeClass] != _TinySize {throw("bad TinySizeClass")}if heapArenaBitmapBytes&(heapArenaBitmapBytes-1) != 0 {// heapBits expects modular arithmetic on bitmap// addresses to work.throw("heapArenaBitmapBytes not a power of 2")}// Copy class sizes out for statistics table.// memstats 用来统计和记录内存分配情况,这里是初始化,复制size class,后来分别统计不同size class的数据for i := range class_to_size {memstats.by_size[i].size = uint32(class_to_size[i])}// 各种校验逻辑,部分参数通过osinit()赋值后在此校验...// Initialize the heap.// 对全局的mheap进行初始化mheap_.init()// 在程序初始化的时候供第一个P对象使用,完成初始化后会进行回收,回收动作见schedinitmcache0 = allocmcache()lockInit(&gcBitsArenas.lock, lockRankGcBitsArenas)lockInit(&proflock, lockRankProf)lockInit(&globalAlloc.mutex, lockRankGlobalAlloc)// Create initial arena growth hints.// 初始化arena区的基地址,分为32位机器和64位机器if goarch.PtrSize == 8 {for i := 0x7f; i >= 0; i-- {var p uintptr...hint := (*arenaHint)(mheap_.arenaHintAlloc.alloc())hint.addr = phint.next, mheap_.arenaHints = mheap_.arenaHints, hint}} else {...}
}
// runtime/mheap.go// Initialize the heap.
func (h *mheap) init() {// 初始化锁,mcentral从mheap中申请内存时需要加锁lockInit(&h.lock, lockRankMheap)lockInit(&h.speciallock, lockRankMheapSpecial)// 初始化空闲链表分配器h.spanalloc.init(unsafe.Sizeof(mspan{}), recordspan, unsafe.Pointer(h), &memstats.mspan_sys)h.cachealloc.init(unsafe.Sizeof(mcache{}), nil, nil, &memstats.mcache_sys)h.specialfinalizeralloc.init(unsafe.Sizeof(specialfinalizer{}), nil, nil, &memstats.other_sys)h.specialprofilealloc.init(unsafe.Sizeof(specialprofile{}), nil, nil, &memstats.other_sys)h.specialReachableAlloc.init(unsafe.Sizeof(specialReachable{}), nil, nil, &memstats.other_sys)h.arenaHintAlloc.init(unsafe.Sizeof(arenaHint{}), nil, nil, &memstats.other_sys)// h->mapcache needs no init// 初始化mcentral中心缓存,mcentral的初始化主要是两个部分,一个是对spanclass赋值,相关概念中提到mheap中包括68*2个mcentral,这这里会对每个mcentral的spanclass进行赋值,第二个是初始化锁,mcache从mcentral中申请内存的时候需要加锁for i := range h.central {h.central[i].mcentral.init(spanClass(i))}h.pages.init(&h.lock, &memstats.gcMiscSys)
}
其中spanalloc,cachealloc,arenaHintAlloc等都是都是runtime.fixalloc类型的空闲链表分配器
当我们调用 runtime.fixalloc.init 初始化分配器时,需要传入待初始化的结构体大小等信息,这会帮助分配器分割待分配的内存,它提供了以下两个用于分配和释放内存的方法:
runtime.fixalloc.alloc— 获取下一个空闲的内存空间;runtime.fixalloc.free— 释放指针指向的内存空间;
堆内存分配
func main() {// go tool compile -S -l -N main.govar str [5200000]stringstr[0] = "www"fmt.Println(str)
}对应第2行的汇编命令是: CALL runtime.newobject(SB)
可以看到是调用runtime.newobject来分配内存
// runtime/malloc.go// implementation of new builtin
// compiler (both frontend and SSA backend) knows the signature
// of this function
func newobject(typ *_type) unsafe.Pointer {return mallocgc(typ.size, typ, true)
}
接下来看mallocgc的实现,由于代码比较长,这里只看重点逻辑,首先需要先了解一下go内存分配的三种情况
- 微对象 (0, 16B) — 先使用微内存分配器,再依次尝试线程缓存、中心缓存和堆分配内存;
- 小对象 [16B, 32KB] — 依次尝试使用线程缓存、中心缓存和堆分配内存;
- 大对象 (32KB, +∞) — 直接在堆上分配内存;
// Allocate an object of size bytes.
// Small objects are allocated from the per-P cache's free lists.
// Large objects (> 32 kB) are allocated straight from the heap.
func mallocgc(size uintptr, typ *_type, needzero bool) unsafe.Pointer {// assistG is the G to charge for this allocation, or nil if// GC is not currently active.// 获取当前goroutine,负责分配内存var assistG *gif gcBlackenEnabled != 0 {// Charge the current user G for this allocation.assistG = getg()if assistG.m.curg != nil {assistG = assistG.m.curg}// Charge the allocation against the G. We'll account// for internal fragmentation at the end of mallocgc.assistG.gcAssistBytes -= int64(size)if assistG.gcAssistBytes < 0 {// This G is in debt. Assist the GC to correct// this before allocating. This must happen// before disabling preemption.gcAssistAlloc(assistG)}}// 获取M对象,同时mallocing置为1,防止被GC抢占mp := acquirem()mp.mallocing = 1// 获取线程缓存mcachec := getMCache(mp)// 判断申请的类型是否是指针noscan := typ == nil || typ.ptrdata == 0// 接下来会分成微对象/小对象/大对象内存分配if size <= maxSmallSize {if noscan && size < maxTinySize {... // 微对象} else {... // 小对象}} else {... // 大对象}
}
微对象内存分配
小于16个字节,且不是指针类型,就是微对象,单独使用微对象内存分配器。
微对象内存分配器会把多个小的内存分配请求合并到一整个内存块中,只有当内存块中所有对象都被释放后,内存块才会被回收,这样做是为了确保内存浪费是有限的(如果是指针类型,如果一直不释放,就会导致整个内存块被浪费)。
微对象内存分配器和小对象/大对象内存分配器策略是不一样的,微对象类似线性内存分配,维护一个空闲对象指针,每次分配新的对象,只需要移动指针即可实现内存的快速分配,可以有效提高内存分配效率,同时由于都是微对象,线性内存分配不能重用已释放内存的这个缺点也可以控制在可接受范围。有公司统计显示:绝大多数内存分配大小都是<128b的,因此针对性的做了优化,把微对象由16b扩大到了128b,如此提高了小对象的内存分配效率,降低了GC的压力,在cpu上取得了不错的收益,代价是内存利用率会比较高。
内存块的大小是可以配置的,默认是16个字节,越大可以存储的对象就越多,但是浪费也会更严重,越小内存浪费也越少,原因是下面11行的内存对齐逻辑,最佳实践是8的倍数。原因是预分配的size_class对象大小都是8的倍数,微对象同样符合,8的倍数可以保证每个size_class的对象最大程度的利用率。
微对象内存分配器主要目标是小字符串和逃逸的临时变量(这里对内存分配的效率有很好的优化,可以参考思路)。
// Allocate an object of size bytes.
// Small objects are allocated from the per-P cache's free lists.
// Large objects (> 32 kB) are allocated straight from the heap.
func mallocgc(size uintptr, typ *_type, needzero bool) unsafe.Pointer {if size <= maxSmallSize {if noscan && size < maxTinySize {off := c.tinyoffset// 根据申请的内存大小,计算偏移量,off分别对8/4/2的倍数向上取整// 比如当前size=8,off=13,即对8的倍数向上取整,8,16,24,那么13偏移off=16// 指针内存对齐,分别到2/4/8的倍数if size&7 == 0 {off = alignUp(off, 8)} else if goarch.PtrSize == 4 && size == 12 { // 兼容某些issueoff = alignUp(off, 8)} else if size&3 == 0 {off = alignUp(off, 4)} else if size&1 == 0 {off = alignUp(off, 2)}// 如果内存块剩余的内存可以存放本次申请的内存,且微对象内存分配器已初始化,则直接分配// maxTinySize=16if off+size <= maxTinySize && c.tiny != 0 {// The object fits into existing tiny block.x = unsafe.Pointer(c.tiny + off)// 记录微对象内存分配器的偏移量,往左是已经使用过的内存c.tinyoffset = off + size c.tinyAllocs++ // 记录分配次数mp.mallocing = 0 releasem(mp) return x}// 如果微对象内存分配器还未初始化或空间不够,则从mcahe中获取对应size class的span,然后快速获取空闲object,注意这里的span是链表,每个该size class规格的span都存放在alloc中,使用时从其中获取对应的span即可// tinySpanClass的size_class=2,且不包含指针span = c.alloc[tinySpanClass]// runtime.nextFreeFast 会利用内存管理单元中的 allocCache 字段,快速找到该字段为 1 的位数,1 表示该位对应的内存空间是空闲的对象v := nextFreeFast(span)// 如果mcache中也没有空闲的span,则会调用nextFree从mcentral或者mheap中申请新的可分配的内存块,nextFree中会调用mcache.refill从mcentral获取新内存,refill会调用mcentral.grow分配新的内存,grow()调用mheap.alloc,最终返回新申请的span和空闲对象if v == 0 {v, span, shouldhelpgc = c.nextFree(tinySpanClass)}// 将新申请的内存块重置x = unsafe.Pointer(v)(*[2]uint64)(x)[0] = 0(*[2]uint64)(x)[1] = 0// See if we need to replace the existing tiny block with the new one// based on amount of remaining free space.// size < c.tinyoffset:此处有个前提条件是off+size <= maxTinySize,即微对象内存分配器已经快要使用完一个object的内存 或 当前size比较大,如果是前者,那么就需要把为内存分配器的指针和偏移量转移到新申请的object上,如果是后者,说明当前object的内存还有剩余,则不必替换微对象内存指针,需要分配的size也基本可以用光一个object的大小// c.tiny == 0:表示微内存分配器还未初始化// 满足以上两个条件,就会把微内存分配器的指针指向新的object// raceenabled:是否开启竞态检测,此处默认不开启if !raceenabled && (size < c.tinyoffset || c.tiny == 0) {c.tiny = uintptr(x)c.tinyoffset = size}}}
}
下面再重点看一下nextFreeFast和nextFre方法,下面小对象分配同样是调用该方法实现内存申请和分配。
// 快速索引,返回可用的对象地址
func nextFreeFast(s *mspan) gclinkptr {// 获取allocCache二进制数中末尾为0的个数,0表示已分配对象,如果都是0则返回64// allocCache会初始化成^uint64(0)theBit := sys.Ctz64(s.allocCache) // Is there a free object in the allocCache?// < 64表示还有空闲对象if theBit < 64 {// 计算本次空闲对象的索引位置,freeindex表示空闲对象的起始位置result := s.freeindex + uintptr(theBit)// 如果相等,表示mspan已用完空闲对象if result < s.nelems {freeidx := result + 1if freeidx%64 == 0 && freeidx != s.nelems {return 0}// 右移theBit + 1位,如下示意图,左侧位置分配后置0s.allocCache >>= uint(theBit + 1)// 更新本次索引位置s.freeindex = freeidx// 已分配对象+1s.allocCount++// 索引位置*对象大小+基指针位置,返回本次分配对象的位置return gclinkptr(result*s.elemsize + s.base())}}return 0
}
附上示意图,obj表示已分配对象,free表示未分配对象

如果nextFreeFast没有找到可分配对象,那么再调用nextFree。
func (c *mcache) nextFree(spc spanClass) (v gclinkptr, s *mspan, shouldhelpgc bool) {// 取出该spanClass的mspans = c.alloc[spc]shouldhelpgc = false// 找到空闲对象索引freeIndex := s.nextFreeIndex()// mspan满了if freeIndex == s.nelems {// The span is full.if uintptr(s.allocCount) != s.nelems {println("runtime: s.allocCount=", s.allocCount, "s.nelems=", s.nelems)throw("s.allocCount != s.nelems && freeIndex == s.nelems")}// 从mcentral中获取新的mspan,并替换掉该mcache的spanc.refill(spc)// 由调用方来决定是否需要触发垃圾回收shouldhelpgc = trues = c.alloc[spc]// 找到空闲对象索引freeIndex = s.nextFreeIndex()}if freeIndex >= s.nelems {throw("freeIndex is not valid")}// 计算空闲对象的位置v = gclinkptr(freeIndex*s.elemsize + s.base())s.allocCount++if uintptr(s.allocCount) > s.nelems {println("s.allocCount=", s.allocCount, "s.nelems=", s.nelems)throw("s.allocCount > s.nelems")}return
}
nextFreeFast使用了fast path的算法可以快速从该mspan中获取空闲对象,大多数情况都可以用nextFreeFast获取空闲对象,而nextFree处理的情况更复杂,如大对象或更复杂的情况,如果没有空闲对象,则会从mcentral申请新的mspan,并返回空闲对象。
[图片]
在nextFree函数中,判断如果span满了,会调用refill重新从mcentral申请内存,并替换mcache中的span
func (c *mcache) refill(spc spanClass) {// 获取对应spanClass的mspans := c.alloc[spc]...if s != &emptymspan {// Mark this span as no longer cached.if s.sweepgen != mheap_.sweepgen+3 {throw("bad sweepgen in refill")}// 把当前空间已满的mspan放回到mcentral中,在函数中可能会触发清扫动作// 然后根据mspan是否有剩余空间及是否已清扫,决定放回mcentral中partial/full中的已清扫或未清扫链表mheap_.central[spc].mcentral.uncacheSpan(s)}// 从mcentral中申请新的mspans = mheap_.central[spc].mcentral.cacheSpan()if s == nil {throw("out of memory")}...// 清洗微对象分配器字段if spc == tinySpanClass {atomic.Xadduintptr(&stats.tinyAllocCount, c.tinyAllocs)c.tinyAllocs = 0}... // 替换为新的mspanc.alloc[spc] = s
}
小对象内存分配
小对象内存分配,小对象包括所有16个字节到32768个字节,以及所有小于16个字节的指针对象
func mallocgc(size uintptr, typ *_type, needzero bool) unsafe.Pointer {if size <= maxSmallSize {if noscan && size < maxTinySize {...} else {// size_to_class8 size_to_class128 都是用来快速计算size classvar sizeclass uint8if size <= smallSizeMax-8 {sizeclass = size_to_class8[divRoundUp(size, smallSizeDiv)]} else {sizeclass = size_to_class128[divRoundUp(size-smallSizeMax, largeSizeDiv)]}// 根据size class重制本次申请的内存大小size = uintptr(class_to_size[sizeclass])// 由于c.alloc的索引时spanClass,所以次数先根据size class生成spanClass,然后根据spanClass索引到对应规格的span// 此处再复习一下spanClass的定义:是一个8位的数据,前7位表示size class,后1位表示是否是指针类型,c.alloc存储了68个size class,分是否是指针类型共68*2个数据spc := makeSpanClass(sizeclass, noscan)span = c.alloc[spc]// 快速找到可用的对象v := nextFreeFast(span)if v == 0 {// 如果没有空闲的对象则继续向mcentral或mheap申请,如果本次分配的内存比较大,nextFree会返回shouldhelpgc,在后面的代码中触发垃圾回收v, span, shouldhelpgc = c.nextFree(spc)}x = unsafe.Pointer(v)// 该span如果可以清理,则调用memclrNoHeapPointers清理掉该span的起始位置往后size个字节if needzero && span.needzero != 0 {memclrNoHeapPointers(unsafe.Pointer(v), size)}}}
}
大对象内存分配
对于大于32k的对象,将不再从mcache或mcentral中分配,会直接从mheap中分配,如果mheap也不够,则会直接向系统申请
func mallocgc(size uintptr, typ *_type, needzero bool) unsafe.Pointer {if size <= maxSmallSize {if noscan && size < maxTinySize {...} else {...}} else {// 调用allocLarge直接从mheap中分配内存,c.allocLarge会计算分配该对象所需要的页数,通常是8kb的倍数,直接返回对应大小的spanshouldhelpgc = true // 分配大对象内存一定会触发垃圾回收span = c.allocLarge(size, noscan)span.freeindex = 1span.allocCount = 1size = span.elemsizex = unsafe.Pointer(span.base())if needzero && span.needzero != 0 {if noscan {delayedZeroing = true} else {memclrNoHeapPointers(x, size)}}if shouldhelpgc {if t := (gcTrigger{kind: gcTriggerHeap}); t.test() {// 触发垃圾回收gcStart(t)}}
}
参考
https://draveness.me/golang/docs/part3-runtime/ch07-memory/golang-memory-allocator/
https://www.luozhiyun.com/archives/434








![【YOLOv8改进[Head检测头]】YOLOv8换个RT-DETR head助力模型更优秀](https://img-blog.csdnimg.cn/direct/0be32b831d7d42f9b2bf0c7e79706222.png)