一RT-DETR

官方论文地址:https://arxiv.org/pdf/2304.08069.pdf
因为YOLO的合理速度和准确性之间的权衡, 这一系列已成为最流行的实时目标检测框架。然而,观察到nms对yolo的速度和准确性产生了负面影响。最近,基于端到端变换器的检测器(DETRs)消除了传统实时检测器中的非最大抑制(NMS)等后处理步骤的需要,这些步骤一直是传统实时检测器中的瓶颈,提供了一种替代方案。然而,高昂的计算成本限制了它们的实用性,阻碍了它们充分发挥不用NMS的优势。
在本文中,提出了实时检测变换器(RT-DETR),这是我们所知的第一个解决上述困境的实时端到端目标检测器。在先进的DETR基础上分两步构建RT-DETR:首先专注于在提高速度的同时保持精度,其次是在提高精度的同时保持速度。具体而言,设计了一种高效的混合编码器,通过解耦尺度内相互作用和跨尺度融合来快速处理多尺度特征,以提高速度。然后,提出了不确定性最小的查询选择,为解码器提供高质量的初始查询,从而提高准确率。此外,RT-DETR支持灵活的速度调整,通过调整解码器层的数量,以适应各种场景,而无需重新训练。
RT-DETR-R50/ R101在COCO上实现53.1% / 54.3%的AP,在T4 GPU上实现108 / 74 FPS,在速度和精度方面都优于以前先进的yolo。此外,RT-DETR-R50在精度上比DINO-R50高出2.2%,在FPS上高出约21倍。RT - DETR - R50 / R101经过Objects365预训练,AP达到55.3% / 56.2%。
官方代码地址:DETRs Beat YOLOs on Real-time Object Detection
综上,RT-DETR模型建立在于两个关键创新:
① 高效混合编码器:通过解耦内部尺度交互和跨尺度融合来处理多尺度特征。这种设计显著降低了计算负担,同时保持了高性能,实现了实时目标检测。
② 提出了不确定性最小的查询选择,为解码器提供高质量的初始查询,从而提高准确率。
1 编码器结构
下图是每个变体的编码器结构。SSE表示单尺度Transformer编码器,MSE表示多尺度Transformer编码器,CSF表示跨尺度融合。AIFI和CCFF是我们设计的混合编码器的两个模块。

2 RT-DETR
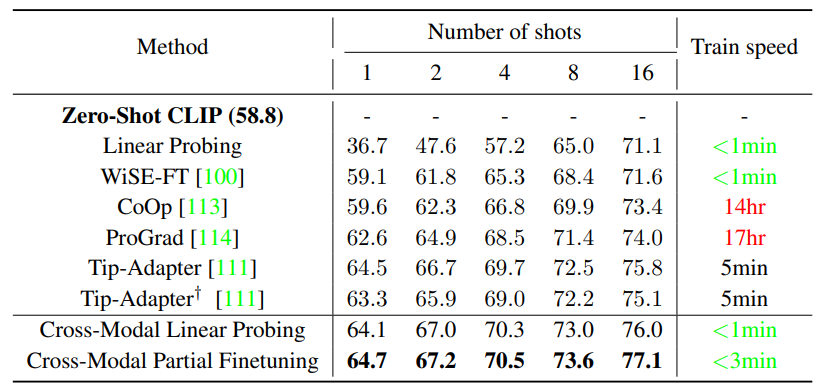
下图为RT-DETR概述。将主干最后三个阶段的特征输入到编码器中。高效混合编码器通过基于注意力的尺度内特征交互(AIFI)和基于cnn的跨尺度特征融合(CCFF)将多尺度特征转化为图像特征序列。然后,最小不确定性查询选择固定数量的编码器特征作为解码器的初始对象查询。最后,具有辅助预测头的解码器迭代优化对象查询以生成类别和框。
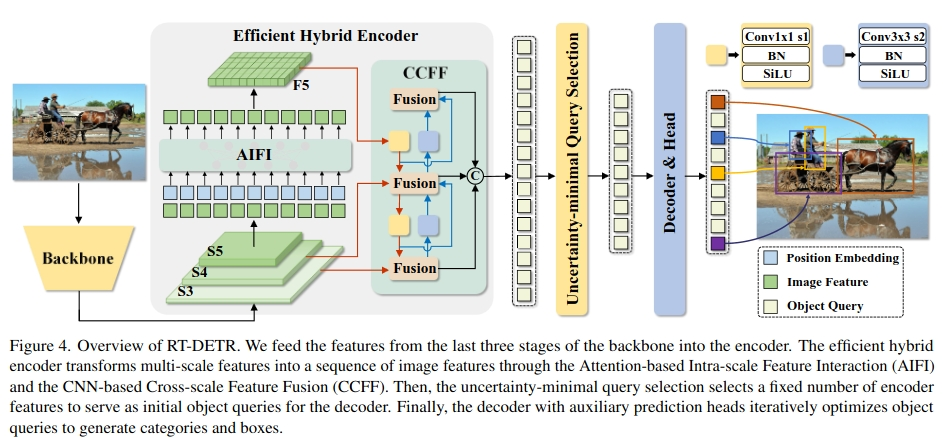
3 CCFF中的融合块
下图为 CCFF中的融合块。
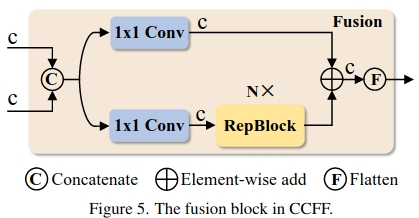
实验结果:


二 RT-DETR检测头的代码
RT-DETR检测头的代码如下所示:
class RTDETRDecoder(nn.Module):"""Real-Time Deformable Transformer Decoder (RTDETRDecoder) module for object detection.This decoder module utilizes Transformer architecture along with deformable convolutions to predict bounding boxesand class labels for objects in an image. It integrates features from multiple layers and runs through a series ofTransformer decoder layers to output the final predictions."""export = False # export modedef __init__(self,nc=80,ch=(512, 1024, 2048),hd=256, # hidden dimnq=300, # num queriesndp=4, # num decoder pointsnh=8, # num headndl=6, # num decoder layersd_ffn=1024, # dim of feedforwarddropout=0.0,act=nn.ReLU(),eval_idx=-1,# Training argsnd=100, # num denoisinglabel_noise_ratio=0.5,box_noise_scale=1.0,learnt_init_query=False,):"""Initializes the RTDETRDecoder module with the given parameters.Args:nc (int): Number of classes. Default is 80.ch (tuple): Channels in the backbone feature maps. Default is (512, 1024, 2048).hd (int): Dimension of hidden layers. Default is 256.nq (int): Number of query points. Default is 300.ndp (int): Number of decoder points. Default is 4.nh (int): Number of heads in multi-head attention. Default is 8.ndl (int): Number of decoder layers. Default is 6.d_ffn (int): Dimension of the feed-forward networks. Default is 1024.dropout (float): Dropout rate. Default is 0.act (nn.Module): Activation function. Default is nn.ReLU.eval_idx (int): Evaluation index. Default is -1.nd (int): Number of denoising. Default is 100.label_noise_ratio (float): Label noise ratio. Default is 0.5.box_noise_scale (float): Box noise scale. Default is 1.0.learnt_init_query (bool): Whether to learn initial query embeddings. Default is False."""super().__init__()self.hidden_dim = hdself.nhead = nhself.nl = len(ch) # num levelself.nc = ncself.num_queries = nqself.num_decoder_layers = ndl# Backbone feature projectionself.input_proj = nn.ModuleList(nn.Sequential(nn.Conv2d(x, hd, 1, bias=False), nn.BatchNorm2d(hd)) for x in ch)# NOTE: simplified version but it's not consistent with .pt weights.# self.input_proj = nn.ModuleList(Conv(x, hd, act=False) for x in ch)# Transformer moduledecoder_layer = DeformableTransformerDecoderLayer(hd, nh, d_ffn, dropout, act, self.nl, ndp)self.decoder = DeformableTransformerDecoder(hd, decoder_layer, ndl, eval_idx)# Denoising partself.denoising_class_embed = nn.Embedding(nc, hd)self.num_denoising = ndself.label_noise_ratio = label_noise_ratioself.box_noise_scale = box_noise_scale# Decoder embeddingself.learnt_init_query = learnt_init_queryif learnt_init_query:self.tgt_embed = nn.Embedding(nq, hd)self.query_pos_head = MLP(4, 2 * hd, hd, num_layers=2)# Encoder headself.enc_output = nn.Sequential(nn.Linear(hd, hd), nn.LayerNorm(hd))self.enc_score_head = nn.Linear(hd, nc)self.enc_bbox_head = MLP(hd, hd, 4, num_layers=3)# Decoder headself.dec_score_head = nn.ModuleList([nn.Linear(hd, nc) for _ in range(ndl)])self.dec_bbox_head = nn.ModuleList([MLP(hd, hd, 4, num_layers=3) for _ in range(ndl)])self._reset_parameters()def forward(self, x, batch=None):"""Runs the forward pass of the module, returning bounding box and classification scores for the input."""from ultralytics.models.utils.ops import get_cdn_group# Input projection and embeddingfeats, shapes = self._get_encoder_input(x)# Prepare denoising trainingdn_embed, dn_bbox, attn_mask, dn_meta = get_cdn_group(batch,self.nc,self.num_queries,self.denoising_class_embed.weight,self.num_denoising,self.label_noise_ratio,self.box_noise_scale,self.training,)embed, refer_bbox, enc_bboxes, enc_scores = self._get_decoder_input(feats, shapes, dn_embed, dn_bbox)# Decoderdec_bboxes, dec_scores = self.decoder(embed,refer_bbox,feats,shapes,self.dec_bbox_head,self.dec_score_head,self.query_pos_head,attn_mask=attn_mask,)x = dec_bboxes, dec_scores, enc_bboxes, enc_scores, dn_metaif self.training:return x# (bs, 300, 4+nc)y = torch.cat((dec_bboxes.squeeze(0), dec_scores.squeeze(0).sigmoid()), -1)return y if self.export else (y, x)def _generate_anchors(self, shapes, grid_size=0.05, dtype=torch.float32, device="cpu", eps=1e-2):"""Generates anchor bounding boxes for given shapes with specific grid size and validates them."""anchors = []for i, (h, w) in enumerate(shapes):sy = torch.arange(end=h, dtype=dtype, device=device)sx = torch.arange(end=w, dtype=dtype, device=device)grid_y, grid_x = torch.meshgrid(sy, sx, indexing="ij") if TORCH_1_10 else torch.meshgrid(sy, sx)grid_xy = torch.stack([grid_x, grid_y], -1) # (h, w, 2)valid_WH = torch.tensor([w, h], dtype=dtype, device=device)grid_xy = (grid_xy.unsqueeze(0) + 0.5) / valid_WH # (1, h, w, 2)wh = torch.ones_like(grid_xy, dtype=dtype, device=device) * grid_size * (2.0**i)anchors.append(torch.cat([grid_xy, wh], -1).view(-1, h * w, 4)) # (1, h*w, 4)anchors = torch.cat(anchors, 1) # (1, h*w*nl, 4)valid_mask = ((anchors > eps) & (anchors < 1 - eps)).all(-1, keepdim=True) # 1, h*w*nl, 1anchors = torch.log(anchors / (1 - anchors))anchors = anchors.masked_fill(~valid_mask, float("inf"))return anchors, valid_maskdef _get_encoder_input(self, x):"""Processes and returns encoder inputs by getting projection features from input and concatenating them."""# Get projection featuresx = [self.input_proj[i](feat) for i, feat in enumerate(x)]# Get encoder inputsfeats = []shapes = []for feat in x:h, w = feat.shape[2:]# [b, c, h, w] -> [b, h*w, c]feats.append(feat.flatten(2).permute(0, 2, 1))# [nl, 2]shapes.append([h, w])# [b, h*w, c]feats = torch.cat(feats, 1)return feats, shapesdef _get_decoder_input(self, feats, shapes, dn_embed=None, dn_bbox=None):"""Generates and prepares the input required for the decoder from the provided features and shapes."""bs = feats.shape[0]# Prepare input for decoderanchors, valid_mask = self._generate_anchors(shapes, dtype=feats.dtype, device=feats.device)features = self.enc_output(valid_mask * feats) # bs, h*w, 256enc_outputs_scores = self.enc_score_head(features) # (bs, h*w, nc)# Query selection# (bs, num_queries)topk_ind = torch.topk(enc_outputs_scores.max(-1).values, self.num_queries, dim=1).indices.view(-1)# (bs, num_queries)batch_ind = torch.arange(end=bs, dtype=topk_ind.dtype).unsqueeze(-1).repeat(1, self.num_queries).view(-1)# (bs, num_queries, 256)top_k_features = features[batch_ind, topk_ind].view(bs, self.num_queries, -1)# (bs, num_queries, 4)top_k_anchors = anchors[:, topk_ind].view(bs, self.num_queries, -1)# Dynamic anchors + static contentrefer_bbox = self.enc_bbox_head(top_k_features) + top_k_anchorsenc_bboxes = refer_bbox.sigmoid()if dn_bbox is not None:refer_bbox = torch.cat([dn_bbox, refer_bbox], 1)enc_scores = enc_outputs_scores[batch_ind, topk_ind].view(bs, self.num_queries, -1)embeddings = self.tgt_embed.weight.unsqueeze(0).repeat(bs, 1, 1) if self.learnt_init_query else top_k_featuresif self.training:refer_bbox = refer_bbox.detach()if not self.learnt_init_query:embeddings = embeddings.detach()if dn_embed is not None:embeddings = torch.cat([dn_embed, embeddings], 1)return embeddings, refer_bbox, enc_bboxes, enc_scores# TODOdef _reset_parameters(self):"""Initializes or resets the parameters of the model's various components with predefined weights and biases."""# Class and bbox head initbias_cls = bias_init_with_prob(0.01) / 80 * self.nc# NOTE: the weight initialization in `linear_init` would cause NaN when training with custom datasets.# linear_init(self.enc_score_head)constant_(self.enc_score_head.bias, bias_cls)constant_(self.enc_bbox_head.layers[-1].weight, 0.0)constant_(self.enc_bbox_head.layers[-1].bias, 0.0)for cls_, reg_ in zip(self.dec_score_head, self.dec_bbox_head):# linear_init(cls_)constant_(cls_.bias, bias_cls)constant_(reg_.layers[-1].weight, 0.0)constant_(reg_.layers[-1].bias, 0.0)linear_init(self.enc_output[0])xavier_uniform_(self.enc_output[0].weight)if self.learnt_init_query:xavier_uniform_(self.tgt_embed.weight)xavier_uniform_(self.query_pos_head.layers[0].weight)xavier_uniform_(self.query_pos_head.layers[1].weight)for layer in self.input_proj:xavier_uniform_(layer[0].weight)三 YOLOv8换个RT-DETR head
ultralytics的版本为8.1.47,如下图所示:

1 总体修改
RT-DETR检测头已经集成在YOLOv8的项目里面了,我们可以直接使用。
注意:使用了RT-DETR检测头后,需要增加epoch。
2 配置文件
yolov8_RT-DETR.yaml的内容如下所示:
# Ultralytics YOLO 🚀, AGPL-3.0 license
# YOLOv8 object detection model with P3-P5 outputs. For Usage examples see https://docs.ultralytics.com/tasks/detect# Parameters
nc: 80 # number of classes, 类别数目
scales: # 模型复合缩放常数,'model=yolov8n.yaml' 将调用带有 'n' 缩放的 yolov8.yaml# [depth, width, max_channels]n: [0.33, 0.25, 1024] # YOLOv8n summary: 225 layers, 3157200 parameters, 3157184 gradients, 8.9 GFLOPss: [0.33, 0.50, 1024] # YOLOv8s summary: 225 layers, 11166560 parameters, 11166544 gradients, 28.8 GFLOPsm: [0.67, 0.75, 768] # YOLOv8m summary: 295 layers, 25902640 parameters, 25902624 gradients, 79.3 GFLOPsl: [1.00, 1.00, 512] # YOLOv8l summary: 365 layers, 43691520 parameters, 43691504 gradients, 165.7 GFLOPsx: [1.00, 1.25, 512] # YOLOv8x summary: 365 layers, 68229648 parameters, 68229632 gradients, 258.5 GFLOPs# YOLOv8.0n backbone 骨干层
backbone:# [from, repeats, module, args]# from:表示该模块的输入来源,如果为-1则表示来自于上一层的输出,如果为其他具体的值则表示从特定的模块中得到输入信息# repeats: 用于指定一个模块或层应该重复的次数# module: 用于指定要添加的模块或层的类型# args: 用于传递给模块或层的特定参数- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2 Conv表示卷积层,其参数指定了输出通道数、卷积核大小和步长- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4 - [-1, 3, C2f, [128, True]] # C2f模块- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8- [-1, 6, C2f, [256, True]]- [-1, 1, Conv, [512, 3, 2]] # 5-P4/16- [-1, 6, C2f, [512, True]]- [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32- [-1, 3, C2f, [1024, True]]- [-1, 1, SPPF, [1024, 5]] # 9 SPPF是空间金字塔池化层,用于在多个尺度上聚合特征。# YOLOv8.0n head
head:- [-1, 1, nn.Upsample, [None, 2, "nearest"]] # nn.Upsample表示上采样层- [[-1, 6], 1, Concat, [1]] # cat backbone P4 Concat表示连接层,用于合并来自不同层的特征- [-1, 3, C2f, [512]] # 12- [-1, 1, nn.Upsample, [None, 2, "nearest"]]- [[-1, 4], 1, Concat, [1]] # cat backbone P3- [-1, 3, C2f, [256]] # 15 (P3/8-small)- [-1, 1, Conv, [256, 3, 2]]- [[-1, 12], 1, Concat, [1]] # cat head P4- [-1, 3, C2f, [512]] # 18 (P4/16-medium)- [-1, 1, Conv, [512, 3, 2]]- [[-1, 9], 1, Concat, [1]] # cat head P5- [-1, 3, C2f, [1024]] # 21 (P5/32-large)- [[15, 18, 21], 1, RTDETRDecoder, [nc]] # Detect(P3, P4, P5) # 检测层,负责输出检测结果3 训练
新建rtDetr_run.py文件,内容如下所示:
from ultralytics import RTDETRif __name__ == '__main__':model = RTDETR('cfg/models/v8/yolov8_RT-DETR.yaml ')model.train(data='cfg/datasets/coco128.yaml',imgsz=640,epochs=300,batch=16,workers=0,device="cpu",optimizer='SGD', # 可以使用的优化器:SGD和AdamWproject="yolov8")开始训练:
python3 rtDetr_run.py
到此,本文分享的内容就结束啦!遇见便是缘,感恩遇见!!!💛 💙 💜 ❤️ 💚