目录
前言
一、概述
二、本地知识库需求分析
1. 知识库场景分析
2. 知识库应用特点
3. 知识库核心功能
三、本地知识库架构设计
1. RAG架构分析
2. 大模型方案选型
3. 应用技术架构选型
4. 向量数据库选型
5. 模型选型
三、本地知识库RAG评估
四、本地知识库代码落地
1. 文件解析函数
2. 定义文件内容分割函数
3. 数据库操作函数
4.定义一个对话链
5. 模型定义
6. 知识库导入更新处理
7. 对话聊天处理
8. LangSmith监控配置
五、本地知识库项目上线
1. 项目启动运行
2. 知识库导入更新
3. 聊天对话测试
4. 查看运行监控
总结
前言
在当今信息时代,企业的知识管理变得日益重要。随着人工智能技术的飞速发展,企业知识库的构建和维护已经从传统的文档存储和关键词检索演变为更加智能化、高效化的知识服务。CVP架构模式,作为一种结合了强大的语言理解和快速信息检索能力的先进框架,为企业提供了一个实现这一目标的有效途径。本文将深入探讨如何基于CVP(ChatGPT + VectorDB + Prompt)架构实现企业级知识库项目的落地,以及在实际过程中的应用特点和技术细节。
一、概述
CVP架构模式的优势在于其将强大的语言理解与快速的信息检索能力相结合,使得AI应用在企业环境中更加高效和智能。本章将重点讲解如何利用CVP架构(RAG架构的一种实践)来实现企业级知识库项目的落地。这涉及到大模型的自然语言理解能力、向量化存储技术,以及RAG对问题的检索增强技术的综合运用,以完成整个技术方案的实施。

二、本地知识库需求分析
1. 知识库场景分析
对于企业而言,构建一个符合自身业务需求的知识库是至关重要的。通过RAG、微调等技术手段,我们可以将通用的大模型转变为对特定行业有着深度理解的“行业专家”,从而更好地服务于企业的具体业务需求。这样的知识库基本上适用于每个公司各行各业,包括但不限于:
1)市场调研知识库:收集和整理市场调研数据,包括竞争对手分析、消费者洞察、行业趋势等。这有助于企业制定更有效的市场策略。
2)人力资源知识库:存储和管理与人力资源管理相关的信息,包括员工手册、培训资料、绩效评估等。这有助于人力资源部门更好地进行人才管理和激励。
3)项目管理知识库:存储和管理与项目管理相关的信息,包括项目计划、进度跟踪、风险管理等。这有助于项目经理更好地进行项目管理和控制。
4)技术文档知识库:用于存储和管理企业的技术文档,如用户手册、产品说明书、维修指南等。这些文档对于技术人员来说是宝贵的资源,可以帮助他们快速解决问题或学习新的技术信息。
5)项目流程知识库:包含项目管理的最佳实践、流程图、模板和其他相关文档。它可以帮助团队成员理解项目的各个阶段,以及如何有效地协作和沟通。
6)招标投标知识库:集中存储与企业参与招标投标活动相关的所有信息,如招标文件、历史投标案例、市场分析报告等。这有助于企业提高投标的成功率和效率。
7)方案资料知识库:用于管理和分享企业的商业方案、市场策略和其他相关的商业情报。这可以帮助决策者制定更加明智的战略决策。
2. 知识库应用特点
在当今这个数据驱动的商业环境中,企业对知识库的依赖日益加深。一个高效、可靠的知识库系统是企业资产管理中不可或缺的组成部分。同时知识库包括以下关键特点:
1)数据隐私性强
企业的知识库包含了大量敏感信息和核心机密,如商业策略、客户数据、研究结果等。它们不仅是公司资产的一部分,更是竞争优势的重要来源。因此,维护数据的隐私性和安全性是知识库系统的头等大事。
2)准确性要求高
当员工或客户在查询知识库时,他们期待得到的不仅仅是答案,而是准确无误、切实可行的解决方案。知识库的准确性直接影响到用户的体验和企业决策的质量。因此,构建一个能够提供精确信息和数据的知识库系统,对于提高企业运营效率和增强用户信任具有不可估量的价值。
3. 知识库核心功能
1)知识库更新与导入功能
为了保持知识库的时效性和准确性,必须定期进行内容更新和数据导入。系统应提供一个直观易用的界面,让授权人员能够方便地上传和更新文件,不论是初始化知识库还是后续的维护阶段。
2)知识库检索与增强功能
面对用户的咨询,系统需要快速而准确地提供答案。利用RAG(Retrieval-Augmented Generation)机制,即将自然语言处理技术和向量搜索结合使用,可以显著提升答案的质量。通过理解用户提问的上下文,系统先从本地知识库中检索相关信息,然后利用这些信息来增强生成模型的答案,从而产生更为全面和精确的回复。通过这种机制提高答案的相关性和信息丰富度,同时大大增强了用户体验。
三、本地知识库架构设计
1. RAG架构分析
1)知识数据向量化
加载:通过文档加载器(DocumentLoaders)加载我们的数据(本地知识库)。
拆分:文本拆分器将大型文档拆分为较小的块。便于向量或和后续检索。
向量:对拆分的数据块,进行Embedding向量化处理。
存储:将向量化的数据块存储到向量数据库VectorDB 中,方便进行搜索。

2)知识数据检索返回
检索:根据用户输入,使用检索器从存储中检索相关的拆分。
生成:使用包含问题和检索到的数据的提示,交给ChatModel / LLM(聊天模型/语言生成模型)生成答案。

2. 大模型方案选型
| 技术方案 | 模型选择 | 调试方式 | 周期 | 数据类型 | 开发门槛 | 技术门槛 |
| 微调Fine-tuning | 相关开源模型,比如:GLM,Llama等 | 通过微调更新积累知识 | 调试 时间长 | 敏感的数据(私有部署) | 需要GPU算力环境支持 | 需要比较深AI算法知识储备 |
| Embedding | 通常选择闭源模型 | 通过更新迭代向量数据库 | 调试 时间短 | 通用可公开 | 基于第三方API | 相对较少的AI知识技能储备 |
| GPT助手 | OpenAI或者其他大模型 | 通过Prompt更新知识 | 调试 时间短 | 通用可公开 | 无 | 非常少量的AI知识技能储备 |
1)方案三相当于我们常用的很多GPT助手工具,不需要开发,直接通过prompt,将背景知识库给到通用大模型,个人使用比较多。
2)通常企业级落地方案一般都会采用微调+Embedding 两者结合的方案实现,主要保证数据的私有性;
3)如果没有算力环境支撑,同时又是可公开数据则可采用Embedding方案。
本次项目实践主要采用Embedding方案,借用向量数据库实现。
3. 应用技术架构选型
LLM+VectorDB+Prompt+LanChain
用户提问后,问题信息由LangChain调用嵌入模型向量化,再查询向量数据库获取结果;
接着在由LangChain将向量数据库返回的内容给到LLM,由LLM处理整合出最终答案给到用户。

4. 向量数据库选型
在上一篇《AI大模型探索之路-应用篇12:AI大模型应用之向量数据库选型》我们有探讨相关的向量数据库选型。
本项目这次实践过程中,先采用轻量级的适合个人开发调试的向量数据库Faiss。
5. 模型选型
1. Embedding Model(嵌入模型):OpenAI 的text-embedding-3-small
2. LLM模型选择: 同样的统一采用OpenAI
主要是目前使用的是OpenAI的API KEY,先把羊毛撸到底,后续篇章再考虑其他大模型的学习使用
三、本地知识库RAG评估
在前面系列文章中Ragas篇章《AI大模型探索之路-应用篇11:AI大模型应用智能评估(Ragas)》
有详细介绍说明关于AI大模型智能评估相关,本章节不再另作说明。
四、本地知识库代码落地
1. 文件解析
定义PDF文件解析函数extract_text_from_PDF;用于解析知识库文档(后续可以扩展支持多个文件格式)
from langchain.text_splitter import CharacterTextSplitter
from langchain.vectorstores import FAISS#, Milvus, Pinecone, Chroma
from langchain.memory import ConversationBufferMemory
from langchain.chains import ConversationalRetrievalChain
from models.llm_model import get_openai_model
import streamlit as st
from config.keys import Keys
from PyPDF2 import PdfReader
from prompt.prompt_templates import bot_template, user_templatedef extract_text_from_PDF(files):text = ""for pdf in files:pdf_reader = PdfReader(pdf)for page in pdf_reader.pages:text += page.extract_text()return text2. 文件分割
需要基于token阀值和文档结构考虑分割大小;
叠加冗余:进行分割时,要避免知识切片导致信息丢失,要保持上下文的连贯;
数据结构整理:本地知识库需要提前整理成结构清晰,且语义化的数据结构。
def split_content_into_chunks(text):text_spliter = CharacterTextSplitter(separator="\n", # 指定分隔符为换行符("\n")将根据换行符进行分割。chunk_size=500, # 指定每个分割后的文本块的大小为500个字符chunk_overlap=50, # 指定分割后的文本块之间的重叠大小为50个字符length_function=len)chunks = text_spliter.split_text(text)return chunks3. 数据库操作
基于数据库选型,操作不同的数据库服务
def save_chunks_into_vectorstore(content_chunks, embedding_model):# ① FAISS# pip install faiss-gpu (如果没有GPU,那么 pip install faiss-cpu)vectorstore = FAISS.from_texts(texts=content_chunks,embedding=embedding_model)# ② Pinecone 待扩展# ③ Milvus 待扩展return vectorstore4.Chain对话链
用于调用langchain提供的对话检索链,将向量数据库中检索到结果给到LLM,再由LLM调用大模型整合之后返回对话答案
def get_chat_chain(vector_store):# ① 获取 LLM model(核心优化地方)llm = get_openai_model()# 用于缓存或者保存对话历史记录的对象memory = ConversationBufferMemory(memory_key='chat_history', return_messages=True)# ③ 对话链conversation_chain = ConversationalRetrievalChain.from_llm(llm=llm,retriever=vector_store.as_retriever(),memory=memory)return conversation_chain5. 模型调用封装
定义一个LLM模型和一个嵌入模型
核心关注点temperature=0;对于知识库我们要求内容要尽量保持严谨。
def get_openai_model():llm_model = ChatOpenAI(openai_api_key=Keys.OPENAI_API_KEY,model_name=Keys.MODEL_NAME,temperature=0)return llm_modeldef get_openaiEmbedding_model():return OpenAIEmbeddings(openai_api_key=Keys.OPENAI_API_KEY)6. 知识库导入更新
对知识库进行解析、分割、嵌入向量化、存储到向量数据库
# 1.上传PDF文件
files = st.file_uploader("上传知识文档,然后点击'提交并处理'", accept_multiple_files=True)# 2. 获取文档内容(文本)
texts = extract_text_from_PDF(files)# 3. 将获取到的文档内容进行切分
content_chunks = split_content_into_chunks(texts)# 4. 向量化并且存储数据
embedding_model = get_openaiEmbedding_model()
vector_store = save_chunks_into_vectorstore(content_chunks, embedding_model)# 5. 创建对话chain
conversation= get_chat_chain(vector_store)7. 对话聊天处理
接收用户传入的问题,并调用Chain链进行处理后,返回结果
conversation({'question': user_input})8. LangSmith监控配置
可以提前将下面配置设置在环境变量中
os.environ["LANGCHAIN_TRACING_V2"]= "true"
os.environ["LANGCHAIN_ENDPOINT"]= "https://api.smith.langchain.com"
os.environ["LANGCHAIN_API_KEY"]= os.getenv("LANGCHAIN_API_KEY")
os.environ["LANGCHAIN_PROJECT"]="langsmith02"
五、本地知识库项目上线
1. 项目启动运行
streamlit run knowledge_chatbot.py

2. 知识库导入更新
访问上面8501端口地址;通过左侧栏“知识文档”处,进行上传导入知识库文件

3. 聊天对话测试
通过对话窗口,提问知识库中的内容

继续提问测试

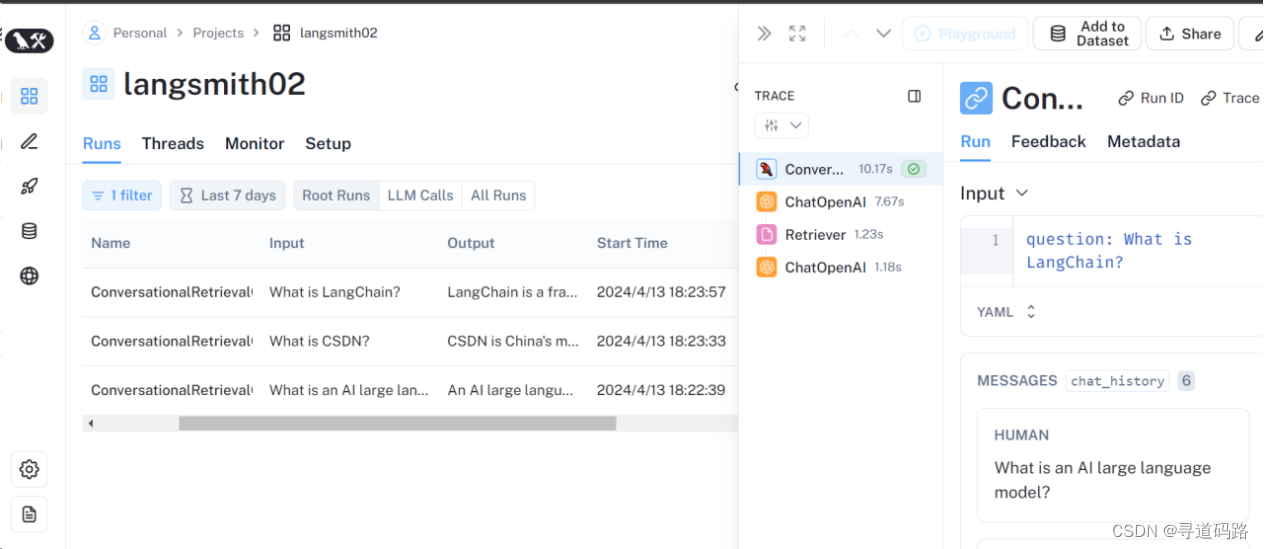
4. 查看运行监控
登录到LangSmith平台可以查看到对话聊天过程中的整个Agent调用链路
总结
通过CVP架构的实践,我们成功地实现了一个企业级的知识库项目落地。这一过程中不仅涵盖了从需求分析到架构设计,再到代码落地和项目上线的全方位技术实施,还特别强调了数据的安全性、准确性和核心功能的实现。最终,通过精心设计的技术堆栈和细致的开发过程,我们构建了一个既安全又高效的企业知识库,它不仅能够响应用户的精准查询,还能够作为一个强大的知识中心,为企业带来信息时代的竞争优势。
🔖更多专栏系列文章:AIGC-AI大模型探索之路
文章若有瑕疵,恳请不吝赐教;若有所触动或助益,敬请关注并给予支持。
期待各位老铁多多支持,高质量互三!!!