天府杯免费分享资料(A题论文代码)链接:https://pan.baidu.com/s/17QtYt036ORk1xGIDi0JSew
提取码:sxjm
摘要
在近年来,随着科技的快速发展和社会经济的不断进步,科学研究的作用和地位日益凸显。本文基于给出的数据对科研绩效分配方案设计与优化进行研究。
对于题目给出的数据集首先进行数据预处理,利用matlab的find函数判定缺失值。再利用q-q图以及K-S检验判定分布方式,判定数据分布方式。利用箱型图判定异常值,对判定结果进行人为判定。对于数据降维需要进行KMO检验判定指标之间关系,对于通过检验的具有线性关系即可以使用主成分分析等线性降维,对于未通过检验可以使用t-SNE进行非线性降维。
对于问题一,其一对科研成果进行评价,其二分配奖金。第一小问,对科研成果进行评价,利用数据预处理结果构建基于熵权法的理想解法,对20位科研岗职工的 2023 年度科研成果奖励进行评价。根据最终排名结果利用二八定律分配奖金。
对于问题二,需要进行两次排序,一对四个团队进行排序确定每个团队的排名;二对每个团队内每一个个体进行排名,按劳动贡献进行排名最终确定每位成员的绩效分配结果。为每个成果确定其权重,对每个团队进行迭代,选择得分最高的20项成果,以优化其总得分。确定每个团队的得分排名。根据团队内部成员的贡献度分配各自的奖金。
最优,极值问题的求解,确定每个成员的年度个人到账经费,计算每个成员的个人绩效基数。确定年度个人成果得分,计算全体科技成果总分。使用公式计算每个成员的绩效分配。构建以总绩效为目标函数,成果贡献公正性、均衡性为约束条件的优化模型进行求解即可。
关键词:评价模型、优化模型、方案设计、科研绩效
下面为成品论文 正文
后续问题答疑、结果解释等问题关注公众号 BZD数模社 进行答疑
本次竞赛助攻主要内容有 (全网首发、质量超高、性价比第一{欢迎比较})
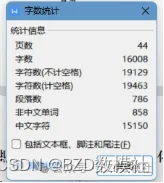
44页论文 正文16000字(无附录)
二等奖奖层次,每个问题上中下三册,可保奖,可稳二,可冲一。三种方式供君选择

两套解题代码(python以及matlab) 完全可运行代码+B站全部讲解

一、模型的建立与求解
5.1 数据清洗
5.1.1 缺失值、异常值判定与处理
我们利用matlab的find函数对数据集的缺失值进行查找,得到题目给出数据并没有存在缺失值。对于异常值的判定,首先对数据进行正态分布的检验。
我们需要对题目给出的数据判定其分布方式,这里使用Kolmogorov-Smirnov检验。Kolmogorov-Smirnov检验是一种非参数的统计检验方法,是一种用于检验数据集是否服从某种分布的统计方法,其中最常用的是检验数据集是否服从正态分布。其基本原理是将数据集的累积分布函数与理论分布函数进行比较,通过计算两者之间的最大差距来判断数据集是否符合该理论分布。如果最大差距小于某个临界值,则认为数据集服从该理论分布,单样本的K-S检验是用来检验一个数据的观测经验分布是否是已知的理论分布。当两者间的差距很小时,推断该样本取自已知的理论分布。作为零假设的理论分布一般是一维连续分布F(如正态分布、均匀分布、指数分布等),有时也用于离散分布(如Poisson分布)[1]。即H:总体X服从某种一维连续分布F。检验统计量为:
H真,Z依分布收敛于Kolmogorov-Smirnov分布。即,当样本取自一维连续分布F时:
注:当F是连续分布时,随机变量K的分布不依赖于F。
KS检验的结果通常是一个p值,如果p值小于显著性水平(一般为0.05),则拒绝原假设,即认为两个样本来自不同的分布。
我们需要对部分数据利用SPSS绘制Q-Q图以及进行 Kolmogorov-Smirnov 检验判定其分布方式,Kolmogorov-Smirnov 检验分析结果如下图所示:

通过q-q图,我们可以看出在这种情况下,大多数点似乎遵循趋势线,尤其是在中间分位数,这表明大部分数据的分布有些程度上是正常的。然而,尤其是在两端,存在一些偏差,这在实际数据中是常见的。为了更加客观的判定,我们使用matlab的ks函数进行判定,得出结果如下所示
表1:正态分布判定结果
1:正态分布判定结果
| 名称 | Statistic | P-Value |
| SCI | 0.184047595 | 0.453442835 |
| EI | 0.152662929 | 0.684347751 |
| 中文核心 | 0.263201681 | 0.103461513 |
| 发明专利 | 0.280306444 | 0.069879523 |
| 其他知识产权 | 0.218766486 | 0.25433914 |
| 国家级科技奖励 | 0.486991197 | 0.00006827 |
| 省部级科技奖励 | 0.382383891 | 0.003861852 |
| 著作出版 | 0.347358352 | 0.011640428 |
| 国家标准/规范 | 0.374628193 | 0.004981288 |
| 省级或行业标准/规范 | 0.388288374 | 0.00316894 |
| 新批国家级项目 | 0.311011732 | 0.032360095 |
| 新批省部级项目 | 0.283718123 | 0.064418713 |
| 在读研究生数量 | 0.297418588 | 0.045978846 |
遵循正态分布假设(P值 > 0.05):对于“SCI”、“EI”、“中文核心”、“发明专利”、“其他知识产权”、“横向到账经费/万元”、“人才计划”和“学术兼职”,P值大于0.05,意味着没有足够的证据拒绝这些列数据遵循正态分布的假设。这并不表明数据绝对是正态分布的,但在统计意义上,我们没有足够的证据证明它们偏离正态分布。
不遵循正态分布假设(P值 < 0.05):对于“国家级科技奖励”、“省部级科技奖励”、“著作出版”、“国家标准/规范”、“省级或行业标准/规范”、“新批国家级项目”、“新批省部级项目”和“在读研究生数量”,P值小于0.05,表明这些列的数据与正态分布存在显著差异,因此拒绝这些数据遵循正态分布的假设。
结论:大部分变量的分布不能断定为正态分布,尤其是那些P值远小于0.05的变量,如“国家级科技奖励”(P值接近0),这意味着其分布与正态分布存在明显的差异。因此,对于服从正态分布的数据,我们使用我们引入了箱型图。
问题二 第二种解法
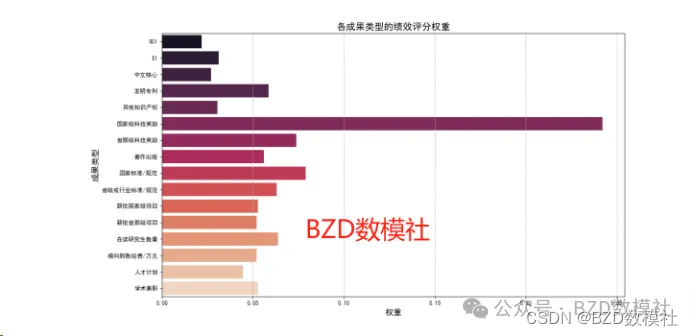
利用熵权法计算每种成果类型对应的绩效评分
标准化处理:将原始数据转换为无量纲的相对数值,以消除不同指标量纲和数量级的影响。
计算指标熵值:通过各指标的概率分布来计算熵值,以反映指标信息的离散程度。
计算指标权重:利用指标熵值,计算每个指标的权重,熵值越小的指标,其所含信息量越大,权重也就越大。
根据熵权法计算得出的权重以及每个团队的可用成果,我们确定了每个团队应提交的成果组合以最大化绩效奖励分配。
定义了一个计算每个团队基于可用成果及其权重获得的最大绩效得分的函数(calculate_maximum_performance):
参数team_data是包含团队可用成果的DataFrame。
参数weights是每种成果类型对应的绩效评分权重,存储在一个Series中。
参数max_submissions是每个团队最多可以提交的成果数量,默认值为20。
函数内部首先将团队的成果数量乘以相应的权重,得到加权得分。
然后,将这些加权得分展平成一个Series,并按照得分从高到低进行排序,以确定最有价值的成果。
选取得分最高的max_submissions个成果来计算团队的总绩效得分,并返回这个总得分及选中的成果。
使用分组操作(groupby)按团队组织数据,并为每个团队计算最大绩效得分:
首先,将原始数据按照团队编号(团队编号列)分组。
对于每个团队,提取除了前三列(非量化信息)以外的成果数据。
调用之前定义的calculate_maximum_performance函数,计算每个团队的最大绩效得分及其最优的成果提交策略。
将每个团队的总得分和最优提交策略存储在字典中,分别用于后续的奖金分配和分析。
最后,展示了各个团队的总绩效得分和团队壹('壹')的最优成果提交示例:
team_scores字典包含了所有团队的绩效得分。
optimal_submissions_by_team字典包含了每个团队的最优成果提交策略。
对于团队壹,通过查看optimal_submissions_by_team['壹']的前几项,我们可以了解到为了达到最高的绩效得分,该团队应优先提交哪些成果。
以下是各个团队的总绩效得分:
团队壹:8.41
团队贰:4.68
团队叁:6.24
团队肆:9.30
以团队壹为例,其最优的提交策略中包括了多项横向到账经费、在读研究生数量和学术兼职等成果,这些成果的选择基于其对总绩效分数的最大贡献。
接下来,我们将根据各团队的得分和学校的奖励方案,计算每个团队及其成员的绩效奖励分配结果。奖励方案如下:排名第一的团队可分配总奖池的35%,其余团队依次是28%、22%、15%。总奖池为100万元。
根据团队内部成员的贡献度分配各自的奖金,我们可以采用以下方法:
使用之前计算的每种成果类型的权重,为每位团队成员计算个人贡献度得分。
根据每位成员的贡献度得分,计算其在团队奖金中的分配比例。
根据分配比例,计算每位成员的奖金。
步骤 1: 计算每位团队成员的个人贡献度得分
定义了一个函数calculate_member_contribution_scores来计算每位团队成员的贡献度得分。
该函数接收团队的成果数据(team_data)和每种成果类型的权重(weights)作为输入。
首先,将团队的每项成果数量乘以对应成果的权重,得到加权得分。
然后,对每位成员的加权得分进行求和,以得到其总贡献度得分。
函数返回一个包含每位成员总贡献度得分的Series。
步骤 2: 根据个人贡献度计算每位成员的奖金
创建一个字典member_prizes_by_team,用于存储每个团队成员的奖金分配。
对于数据中的每个团队,首先排除非量化的列(如团队编号、序号、职称),只保留成果数据。
调用calculate_member_contribution_scores函数计算团队中每位成员的个人贡献度得分。
计算团队的总贡献度得分,并根据每位成员贡献度得分的比例,分配团队获得的总奖金(team_prize_pool)。
将每位成员的奖金存储在member_prizes_by_team字典中,键为团队名称,值为该团队成员的奖金分配。
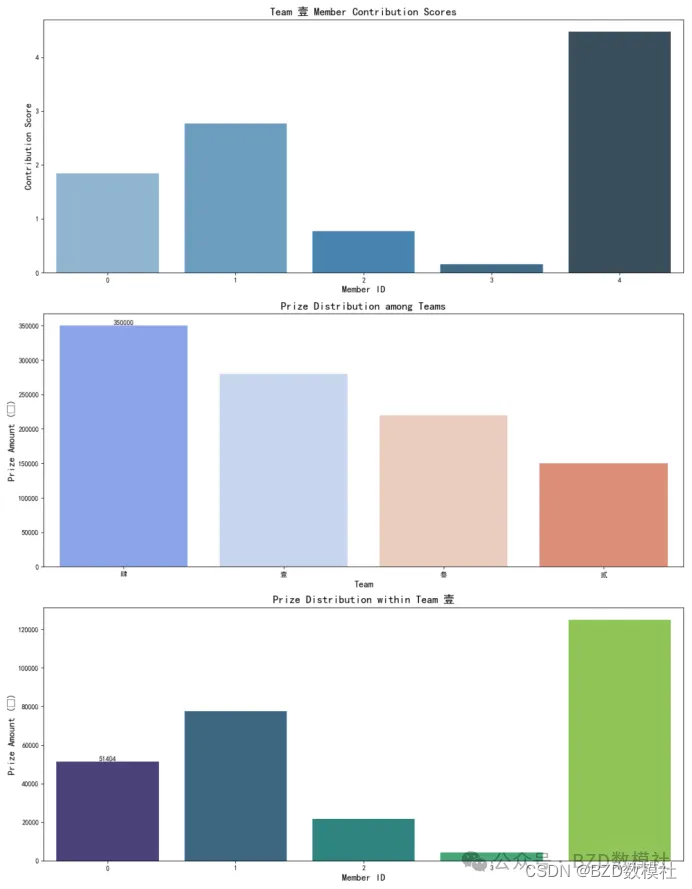
我们以小组壹成员为例进行展示,
天府杯免费分享资料(A题论文代码)链接:https://pan.baidu.com/s/17QtYt036ORk1xGIDi0JSew
提取码:sxjm