决策树(Decision Tree)是一种基本的分类与回归方法,它呈现出一种树形结构,可以直观地展示决策的过程和结果。在决策树中,每个内部节点表示一个属性上的判断条件,每个分支代表一个可能的属性值,每个叶节点代表一个类别或者具体的数值。决策树的主要优点是模型具有可读性,分类速度快。
主要算法
构建决策树的主要算法有ID3、C4.5、CART等。这些算法的主要区别在于如何选择最优划分属性。
ID3算法
以信息增益为准则来选择划分属性。信息增益表示得知特征A的信息而使得类Y的信息不确定性减少的程度。
C4.5算法
是ID3算法的改进,采用信息增益比来选择划分属性,克服了ID3算法偏向选择取值多的属性的缺点。
CART算法
既可以用于分类也可以用于回归。CART分类时,使用基尼指数(Gini index)最小化准则来选择划分属性;CART回归时,使用平方误差最小化准则来选择划分属性。
算法公式
信息熵(Entropy)
信息熵是度量样本集合纯度最常用的一种指标。它表示随机变量不确定性的度量,也就是数据的混乱程度。信息熵越大,数据的混乱程度越高;信息熵越小,数据的纯度越高。
公式:
是当前样本集合。
是集合中第 k类样本所占的比例。
是类别的总数。
信息熵是通过计算每个类别的概率与其对应的信息量的加权和来得到的。如果所有样本都属于同一类别,则信息熵为0,表示数据完全纯净。
信息增益(Information Gain)
信息增益表示在得知特征的信息后,使得类
的信息不确定性减少的程度,它衡量了使用某个特征进行划分后,数据的混乱程度降低了多少,正确的信息增益基于特征
对数据集
进行划分后,集合
的信息熵与划分后各子集信息熵的加权和之差。
公式:
是待考察的特征。
是特征 A所有可能取值的集合。
是集合 S 中特征 A 取值为 v 的子集。
|| 和 |S|分别表示集合 S_v 和 S 的元素数量。
信息增益比(Information Gain Ratio)
信息增益比是为了校正信息增益容易偏向于选择取值较多的特征的问题而提出的。它通过引入一个称为分裂信息熵的项来惩罚取值较多的特征。
信息增益比则是信息增益与分裂信息熵的比值:
分裂信息熵衡量了按照特征 进行划分时产生的信息量的多少。将其与信息增益结合使用,可以平衡特征取值多少对选择的影响。
基尼指数(Gini Index)
基尼指数是另一种度量数据混乱程度的指标。与信息熵类似,基尼指数越小,数据的纯度越高。
基尼指数通过从1中减去每个类别的概率的平方和来计算。当所有样本都属于同一类别时,基尼指数为0。当类别分布均匀时,基尼指数达到最大值对于 n个类。因此,基尼指数越小,表示集合中被选中的样本被分错的概率越小,即集合的纯度越高。
构建决策树
决策树的构建通常包括以下几个步骤:
特征选择
从训练数据的特征集合中选择一个特征作为当前节点的划分标准。按照所选特征的每一个取值,将训练数据集划分为若干子集,使得每个子集在当前特征上具有相同的取值。
决策树生成
根据所选特征评估标准(如信息增益、信息增益比、基尼指数等),从根节点开始,递归地生成子节点。直到满足停止条件(如达到最大深度、所有样本属于同一类别、划分后的样本数小于预设阈值等)。
决策树剪枝
为了避免过拟合,可以对决策树进行剪枝。剪枝分为预剪枝(在决策树生成过程中进行)和后剪枝(在决策树生成后进行)。通过剪枝,可以删除一些不必要的分支,使决策树更加简洁和高效。
分类与回归
使用生成的决策树对新的数据进行分类或回归预测。从根节点开始,根据新数据的特征值,沿着决策树向下遍历,直到到达某个叶节点,该叶节点所代表的类别或数值即为预测结果。
使用Julia语言实现
以下代码于 DecisionTree包 官方示例有进行修改,在使用前需安装DecisionTree包和ScikitLearn包、KnetMetrics包:
# 加载 DecisionTree 软件包
using DecisionTree分离 Fisher 的 Iris 数据集要素和标注
features, labels = load_data("iris") # 同样可以查看 "adult" 和 "digits" 数据集 # 加载的数据类型是 Array{Any}
# 为了获得更好的性能,将它们转换为具体的类型
features = float.(features)
labels = string.(labels)修剪树分类器
# 训练一个深度受限的分类器
model = DecisionTreeClassifier(max_depth=2)
fit!(model, features, labels)
# 以美观的格式打印决策树,深度为 5 个节点(可选)
print_tree(model, 5)
# 应用已训练的模型
predict(model, [5.9,3.0,5.1,1.9])
# 获取每个标签的概率
predict_proba(model, [5.9,3.0,5.1,1.9])
println(get_classes(model)) # 返回 predict_proba 输出中的列顺序
# 在 3 折交叉验证上运行
# 请查看 ScikitLearn.jl 了解安装说明
using ScikitLearn.CrossValidation: cross_val_score
accuracy = cross_val_score(model, features, labels, cv=3)输出决策树
原生API
决策树分类器
using KnetMetrics
using DecisionTreefeatures, labels = load_data("iris") # 同样可以查看 "adult" 和 "digits" 数据集 # 加载的数据类型是 Array{Any}
# 为了获得更好的性能,将它们转换为具体的类型
features = float.(features)
labels = string.(labels)# 训练完整的决策树分类器
model = build_tree(labels, features) # 修剪决策树:合并纯度大于等于90%的叶子节点(默认值为100%)
# 这里的纯度指的是节点中样本属于同一类别的比例
model = prune_tree(model, 0.9) # 以美观的格式打印决策树,深度为5个节点(可选)
# 这有助于我们可视化决策树的结构和决策过程
print_tree(model, 5) # 应用已训练的模型进行预测
apply_tree(model, [5.9,3.0,5.1,1.9]) # 将模型应用于所有样本,得到预测结果
preds = apply_tree(model, features) # 生成混淆矩阵,以及准确率和Kappa分数
# 混淆矩阵可以帮助我们了解模型的分类性能
confusion_matrix(labels, preds) # 获取每个标签的概率
# 这对于需要了解分类置信度的场景很有用
apply_tree_proba(model, [5.9,3.0,5.1,1.9], ["Iris-setosa", "Iris-versicolor", "Iris-virginica"]) # 对修剪后的决策树进行3折交叉验证
# 交叉验证是一种评估模型性能的方法,可以帮助我们了解模型在未知数据上的表现
n_folds = 3
accuracy = nfoldCV_tree(labels, features, n_folds) # 设置分类参数及其默认值
# 这些参数可以控制决策树的构建和修剪过程,从而影响模型的性能
# pruning_purity: 用于后修剪的纯度阈值(默认值:1.0,不进行修剪)
# max_depth: 决策树的最大深度(默认值:-1,没有最大深度限制)
# min_samples_leaf: 每个叶子节点所需的最小样本数(默认值:1)
# min_samples_split: 进行分裂所需的最小样本数(默认值:2)
# min_purity_increase: 分裂所需的最小纯度增加量(默认值:0.0)
# n_subfeatures: 随机选择的特征数(默认值:0,保留所有特征)
# rng: 使用的随机数生成器或种子(默认值:Random.GLOBAL_RNG)
n_subfeatures = 0; max_depth = -1; min_samples_leaf = 1; min_samples_split = 2
min_purity_increase = 0.0; pruning_purity = 1.0; seed = 3 # 使用指定的参数构建决策树分类器
model = build_tree(labels, features, n_subfeatures, max_depth, min_samples_leaf, min_samples_split, min_purity_increase; rng = seed) # 使用指定的参数进行n折交叉验证,并返回准确率
# verbose参数设置为true可以打印出详细的验证过程信息
accuracy = nfoldCV_tree(labels, features, n_folds, pruning_purity, max_depth, min_samples_leaf, min_samples_split, min_purity_increase; verbose = true, rng = seed)输出模型
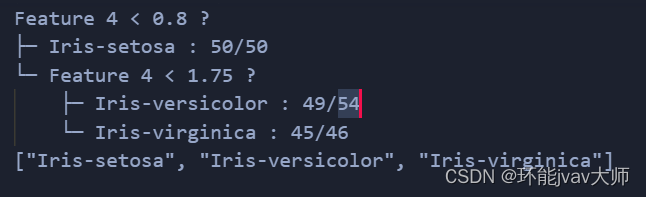
Feature 3 < 2.45 ?
├─ Iris-setosa : 50/50
└─ Feature 4 < 1.75 ?├─ Feature 3 < 4.95 ?├─ Iris-versicolor : 47/48└─ Feature 4 < 1.55 ?├─ Iris-virginica : 3/3└─ Feature 1 < 6.95 ?├─ Iris-versicolor : 2/2└─ Iris-virginica : 1/1└─ Feature 3 < 4.85 ?├─ Feature 1 < 5.95 ?├─ Iris-versicolor : 1/1└─ Iris-virginica : 2/2└─ Iris-virginica : 43/43
Fold 1
Classes: ["Iris-setosa", "Iris-versicolor", "Iris-virginica"]
Matrix: 3×3 Matrix{Int64}:16 0 00 14 00 1 19
Accuracy: 0.98
Kappa: 0.9697702539298669Fold 2
Classes: ["Iris-setosa", "Iris-versicolor", "Iris-virginica"]
Matrix: 3×3 Matrix{Int64}:18 0 00 12 30 3 14
Accuracy: 0.88
Kappa: 0.819494584837545Fold 3
Classes: ["Iris-setosa", "Iris-versicolor", "Iris-virginica"]
Matrix: 3×3 Matrix{Int64}:16 0 00 19 20 0 13
Accuracy: 0.96
Kappa: 0.9393939393939393Mean Accuracy: 0.94Fold 1
Classes: ["Iris-setosa", "Iris-versicolor", "Iris-virginica"]
Matrix: 3×3 Matrix{Int64}:19 0 00 15 20 2 12
Accuracy: 0.92
Kappa: 0.8790810157194682Fold 2
Classes: ["Iris-setosa", "Iris-versicolor", "Iris-virginica"]
Matrix: 3×3 Matrix{Int64}:16 0 00 14 20 1 17
Accuracy: 0.94
Kappa: 0.9097472924187725Fold 3
Classes: ["Iris-setosa", "Iris-versicolor", "Iris-virginica"]
Matrix: 3×3 Matrix{Int64}:15 0 00 17 00 0 18
Accuracy: 1.0
Kappa: 1.0Mean Accuracy: 0.9533333333333333随机森林分类器
# 训练随机森林分类器
# 使用2个随机特征,10棵树,每棵树使用0.5的样本比例,最大树深度为6
model = build_forest(labels, features, 2, 10, 0.5, 6) # 应用已学习的模型
apply_forest(model, [5.9,3.0,5.1,1.9]) # 获取每个标签的概率
apply_forest_proba(model, [5.9,3.0,5.1,1.9], ["Iris-setosa", "Iris-versicolor", "Iris-virginica"]) # 对森林进行3折交叉验证,每次分割使用2个随机特征
n_folds=3; n_subfeatures=2
accuracy = nfoldCV_forest(labels, features, n_folds, n_subfeatures) # 分类参数及其默认值设置
# n_subfeatures: 每次分割要考虑的随机特征数(默认值:-1,即特征数的平方根)
# n_trees: 要训练的树的数量(默认值:10)
# partial_sampling: 每棵树训练所需的样本比例(默认值:0.7)
# max_depth: 决策树的最大深度(默认值:无最大限制)
# min_samples_leaf: 每个叶子节点所需的最小样本数(默认值:5)
# min_samples_split: 分割所需的最小样本数(默认值:2)
# min_purity_increase: 分割所需的最小纯度增加量(默认值:0.0)
# 关键字 rng: 使用的随机数生成器或种子(默认值:Random.GLOBAL_RNG)
# 多线程森林必须使用Int类型的种子
n_subfeatures=-1; n_trees=10; partial_sampling=0.7; max_depth=-1
min_samples_leaf=5; min_samples_split=2; min_purity_increase=0.0; seed=3 model = build_forest(labels, features, n_subfeatures, n_trees, partial_sampling, max_depth, min_samples_leaf, min_samples_split, min_purity_increase; rng = seed) accuracy = nfoldCV_forest(labels, features, n_folds, n_subfeatures, n_trees, partial_sampling, max_depth, min_samples_leaf, min_samples_split, min_purity_increase; verbose = true, rng = seed)输出结果
Fold 1
Classes: ["Iris-setosa", "Iris-versicolor", "Iris-virginica"]
Matrix: 3×3 Matrix{Int64}:15 0 00 18 10 1 15
Accuracy: 0.96
Kappa: 0.9396863691194209Fold 2
Classes: ["Iris-setosa", "Iris-versicolor", "Iris-virginica"]
Matrix: 3×3 Matrix{Int64}:15 0 00 12 20 2 19
Accuracy: 0.92
Kappa: 0.877899877899878Fold 3
Classes: ["Iris-setosa", "Iris-versicolor", "Iris-virginica"]
Matrix: 3×3 Matrix{Int64}:20 0 00 14 30 1 12
Accuracy: 0.92
Kappa: 0.878787878787879Mean Accuracy: 0.9333333333333332Fold 1
Classes: ["Iris-setosa", "Iris-versicolor", "Iris-virginica"]
Matrix: 3×3 Matrix{Int64}:19 0 00 15 20 2 12
Accuracy: 0.92
Kappa: 0.8790810157194682Fold 2
Classes: ["Iris-setosa", "Iris-versicolor", "Iris-virginica"]
Matrix: 3×3 Matrix{Int64}:16 0 00 13 30 1 17
Accuracy: 0.92
Kappa: 0.8795180722891568Fold 3
Classes: ["Iris-setosa", "Iris-versicolor", "Iris-virginica"]
Matrix: 3×3 Matrix{Int64}:15 0 00 17 00 3 15
Accuracy: 0.94
Kappa: 0.9099099099099098Mean Accuracy: 0.9266666666666667自适应增强决策树桩分类器
# train adaptive-boosted stumps, using 7 iterations
model, coeffs = build_adaboost_stumps(labels, features, 7);
# apply learned model
apply_adaboost_stumps(model, coeffs, [5.9,3.0,5.1,1.9])
# get the probability of each label
apply_adaboost_stumps_proba(model, coeffs, [5.9,3.0,5.1,1.9], ["Iris-setosa", "Iris-versicolor", "Iris-virginica"])
# 对boosted stumps进行3折交叉验证,使用7次迭代
n_iterations=7; n_folds=3
accuracy = nfoldCV_stumps(labels, features,n_folds,n_iterations;verbose = true)输出结果
old 1
Classes: ["Iris-setosa", "Iris-versicolor", "Iris-virginica"]
Matrix: 3×3 Matrix{Int64}:18 0 00 15 00 4 13
Accuracy: 0.92
Kappa: 0.880239520958084Fold 2
Classes: ["Iris-setosa", "Iris-versicolor", "Iris-virginica"]
Matrix: 3×3 Matrix{Int64}:17 0 00 17 20 0 14
Accuracy: 0.96
Kappa: 0.9399038461538461Fold 3
Classes: ["Iris-setosa", "Iris-versicolor", "Iris-virginica"]
Matrix: 3×3 Matrix{Int64}:15 0 00 15 10 4 15
Accuracy: 0.9
Kappa: 0.8500299940011996Mean Accuracy: 0.9266666666666666
回归示例
n, m = 10^3, 5
features = randn(n, m)
weights = rand(-2:2, m)
labels = features * weights回归树
using DecisionTreefeatures, labels = load_data("iris") # also see "adult" and "digits" datasetsn, m = 10^3, 5
features = randn(n, m)
weights = rand(-2:2, m)
labels = features * weights# 训练回归树
model = build_tree(labels, features)
# 应用已学习的模型
apply_tree(model, [-0.9,3.0,5.1,1.9,0.0])
# 运行3折交叉验证,返回决定系数(R^2)的数组
n_folds = 3
r2 = nfoldCV_tree(labels, features, n_folds) # 回归参数集及其相应的默认值
# pruning_purity: 用于后剪枝的纯度阈值(默认:1.0,不剪枝)
# max_depth: 决策树的最大深度(默认:-1,无最大值)
# min_samples_leaf: 每个叶子所需的最小样本数(默认:5)
# min_samples_split: 分裂所需的最小样本数(默认:2)
# min_purity_increase: 分裂所需的最小纯度(默认:0.0)
# n_subfeatures: 随机选择的特征数(默认:0,保留所有)
# 关键字 rng: 要使用的随机数生成器或种子(默认 Random.GLOBAL_RNG)
n_subfeatures = 0; max_depth = -1; min_samples_leaf = 5
min_samples_split = 2; min_purity_increase = 0.0; pruning_purity = 1.0 ; seed=3 model = build_tree(labels, features, n_subfeatures, max_depth, min_samples_leaf, min_samples_split, min_purity_increase; rng = seed) r2 = nfoldCV_tree(labels, features, n_folds, pruning_purity, max_depth, min_samples_leaf, min_samples_split, min_purity_increase; verbose = true, rng = seed)输出结果
Fold 1
Mean Squared Error: 1.1192402911257475
Correlation Coeff: 0.9472838062763782
Coeff of Determination: 0.8971356247350447Fold 2
Mean Squared Error: 1.111874839232273
Correlation Coeff: 0.9348375925443003
Coeff of Determination: 0.8736744843129887Fold 3
Mean Squared Error: 1.183298319862818
Correlation Coeff: 0.9341422313248625
Coeff of Determination: 0.8705440012888646Mean Coeff of Determination: 0.8804513701122992Fold 1
Mean Squared Error: 1.0323579387631954
Correlation Coeff: 0.9422656678561453
Coeff of Determination: 0.8862358467110852Fold 2
Mean Squared Error: 1.0151297530543415
Correlation Coeff: 0.9447969369155476
Coeff of Determination: 0.8926327449004646Fold 3
Mean Squared Error: 1.085847261851617
Correlation Coeff: 0.9460144474841884
Coeff of Determination: 0.894208955983675Mean Coeff of Determination: 0.8910258491984083回归随机森林
# 训练回归森林,使用2个随机特征,10棵树,
# 每个叶子平均5个样本,每棵树使用0.7的样本比例
model = build_forest(labels, features, 2, 10, 0.7, 5)
# apply learned model
apply_forest(model, [-0.9,3.0,5.1,1.9,0.0])
# run 3-fold cross validation on regression forest, using 2 random features per split
n_subfeatures=2; n_folds=3
r2 = nfoldCV_forest(labels, features, n_folds, n_subfeatures)#=
build_forest()函数的回归参数集及其相应的默认值
n_subfeatures: 每次分割要考虑的随机特征数(默认:-1,即特征数的平方根)
n_trees: 要训练的树的数量(默认:10)
partial_sampling: 每棵树训练所需的样本比例(默认:0.7)
max_depth: 决策树的最大深度(默认:无最大值)
min_samples_leaf: 每个叶子所需的最小样本数(默认:5)
min_samples_split: 分裂所需的最小样本数(默认:2)
min_purity_increase: 分裂所需的最小纯度(默认:0.0)
关键字 rng: 要使用的随机数生成器或种子(默认:Random.GLOBAL_RNG)
多线程森林必须使用Int类型的种子
=#n_subfeatures=-1; n_trees=10; partial_sampling=0.7; max_depth=-1
min_samples_leaf=5; min_samples_split=2; min_purity_increase=0.0; seed=3model = build_forest(labels, features,n_subfeatures,n_trees,partial_sampling,max_depth,min_samples_leaf,min_samples_split,min_purity_increase;rng = seed)r2 = nfoldCV_forest(labels, features,n_folds,n_subfeatures,n_trees,partial_sampling,max_depth,min_samples_leaf,min_samples_split,min_purity_increase;verbose = true,rng = seed)输出结果
Fold 1
Mean Squared Error: 1.3599903131498468
Correlation Coeff: 0.9515587356817066
Coeff of Determination: 0.8663047566031118Fold 2
Mean Squared Error: 1.3831299735363378
Correlation Coeff: 0.9477732726231708
Coeff of Determination: 0.8548766665136407Fold 3
Mean Squared Error: 1.3108585932358423
Correlation Coeff: 0.9444344709074005
Coeff of Determination: 0.856713400894658Mean Coeff of Determination: 0.8592982746704702Fold 1
Mean Squared Error: 1.3542680364781128
Correlation Coeff: 0.9470579766572528
Coeff of Determination: 0.8566121773382684Fold 2
Mean Squared Error: 1.3027839706551103
Correlation Coeff: 0.9472514130926669
Coeff of Determination: 0.8685137573058215Fold 3
Mean Squared Error: 1.0809211711553741
Correlation Coeff: 0.9587274410123069
Coeff of Determination: 0.8851291475337838Mean Coeff of Determination: 0.8700850273926246保存模型
模型可以保存到磁盘,并使用 JLD2.jl 包重新加载。
using JLD2
@save "model_file.jld2" model