Glue 最重要的部分,
ETL:用于从 A 点(我们的源数据)提取、转换和加载数据到 B 点(目标文件或数据存储库)。 AWS Glue 会为您执行大量此类工作。 转换通常是更繁重的工作,需要从各种来源进行组合、清理数据、正确映射到目标、形成新模式、聚合或分解等等。
AWS Glue 的优势:
AWS Glue 中的 ETL 代码可以轻松运行无服务器。 AWS Glue 有一个爬网程序,可以推断源数据、工作数据和目标数据的架构,爬网程序可以按计划运行以检测更改。
使用 AWS Glue 的功能创建爬网程序来生成源文件的元数据,这有助于我们从源到目标的映射。
现在 ETL 代表提取转换负载。 这是将来自多个系统的数据组合到单个数据库、数据存储或仓库以进行遗留存储或分析的常见范例。
提取是从一个或多个来源(在线、实体、遗留数据、Salesforce 数据等)检索数据的过程。 检索数据后,ETL 将计算工作,将其加载到暂存区域并为下一阶段做好准备。 转换是映射、重新格式化、一致、添加含义等以更容易使用的方式准备数据的过程。 。 所有这些工作都在业务智能开发人员所谓的 ETL 作业中进行处理。
云、SaaS 和大数据的出现导致新数据源和数据流的数量激增。 此外,数据源种类更多、数据量更大,并且需要在世界各地的系统之间更快地移动数据。 因此,对更复杂的数据集成工具的需求激增,这些工具可以处理更大的数据量、更高的速度以及更多的种类。 此外,随着时间的推移,技术不断发展,以帮助解决数据集成问题并提高为决策支持准备数据的速度。 除了能够连接云资源之外,其中许多改进都是在本地工具上进行的。 另一方面,ETL工具也在云端开发,在某些情况下,除了连接云资源之外,它还能更好地处理大数据问题。
ETL 技术的改进之一是提供实时或近实时分析。 另一个改进是简化并降低ETL工作的成本。 这可以通过提供或维护运行 ETL 作业的基础设施来部分实现。 在代码中运行且对所配置的内容知之甚少或一无所知的代码的名称是无服务器 ETL。
无服务器 ETL 的参与具有简化 ETL 流程的好处,例如允许数据开发人员有更多时间专注于准备数据和构建数据管道,而不是考虑与 ETL 作业和运行一致的本地软件。 另一个好处是可以更无缝地交换云中已有的异构数据源和数据目的地。下面的表格有助于显示无服务器 ETL 和传统 ETL 之间的差异。 这些差异包括在 AWS 服务上运行的无服务器代码的优势。 AWS Glue 提供了一个 UI,允许您构建 ETL 作业的源和目标,并自动为您生成无服务器代码。
1.AWS Glue 爬网程序连接到数据存储,同时处理分类器列表,帮助确定数据架构并为 AWS Glue 数据目录创建元数据。 虽然爬虫会发现表方案,但它不会发现表之间的关系。 元数据存储在数据目录中,用于帮助为您的 ETL 作业提供流程。 您可以根据需要从选项菜单中按计划运行爬网程序,或者在基于 Linux 的操作系统中创建自定义 cron 作业,并根据事件(例如交付新数据文件)触发。 通过运行爬网程序,存储在数据目录表中的元数据将随着架构更改(例如数据源中的新列)等项目进行更新。 您可以按照向导并执行以下步骤,以最简单的方式创建 AWS Glue 爬网程序。 首先,为您的爬虫命名。 然后,您必须选择一个数据存储并包含它的路径,在这里您可能会包含 ace 粘合图案。 (可选)添加另一个数据存储、选择 IAM 行或创建一个新行。 为此爬网程序创建计划,配置爬网程序的输出,在此步骤中,您必须添加或选择包含由您正在创建的爬网程序创建的表的现有数据库。
可以在数据目录中添加爬网程序以实现数据存储的多样化。 爬网程序的输出由数据目录中定义的一个或多个元数据表组成。 请注意,您的爬网程序使用 AWS Identity and Access Management by IAM 角色来获取访问数据存储和数据目录的权限。
-
分类器Classifiers.。 分类器读取数据存储中的数据并给出输出以包括指示文件的分类或格式的字符串。 例如 JSON 和文件的架构。 AWS Glue 提供各种格式的内置分类器,包括 JSON、CSV、Web 日志和许多数据库系统。 CSV 分类器检查以下分隔符:逗号、竖线、制表符和分号。 您可以包含或排除模式来管理爬网程序将搜索的内容。 例如,您可以排除以 CSV 文件扩展名结尾的所有对象,或排除 S3 存储桶中的特定文件夹。 正则表达式也可用于排除模式。 对于自定义分类器,您可以根据分类器的类型定义创建架构的逻辑。 如果您的数据与任何内置分类器都不匹配或者您想要自定义爬网程序创建的表,则您可能需要确定自定义分类器。
-
连接。 连接创建连接到数据所需的属性。 AWS Glue 作业中的爬网程序使用连接来访问某些类型的数据存储。 AWS Glue 可以使用 JDBC 协议、Amazon Redshift 和 Amazon RDS 连接到以下数据存储,包括 Amazon Aurora、MariaDB、Microsoft SQL Server、MySQL、Oracle 和 PostgreSQL。 可以在创建爬网程序时选择的数据存储将推断架构,从而推断收集并存储在数据目录中的元数据。
-
数据目录。 AWS Glue 数据目录是在您运行爬网程序时创建的。 它是数据资产的持久元数据存储,包含表定义、作业定义和其他控制信息,可帮助您管理 AWS Glue 环境。 保留目标数据存储的架构版本历史记录,以便您可以查看数据随时间的变化情况。 当您完成创建作业的 UI 指南时,AWS Glue 会自动生成 ETL 作业的提取、转换和加载步骤的代码。 代码是根据您在 Scala 和 Python 之间的选择生成的,并且是为 Apache Spark 编写的。 提供开发端点供您编辑、调试和测试它为 ETL 作业生成的代码。 您可以使用您的首选 IDE 编写自定义读取器、写入器或转换,以作为客户库包含在您的 AWS Glue ETL 作业中。
AWS Glue 作业可以计划运行、按需运行或通过事件触发运行。 您可以启动多个作业并行运行,或者指定作业之间的依赖关系以构建更复杂的 ETL 管道。 日志和通知被推送到 Amazon CloudWatch,以便您可以监视、收到警报并对已运行的作业进行故障排除。
现在让我们看一下有关如何创建 AWS Glue 作业的图表。 首先,您为您的工作选择一个数据源。 表示数据源的表必须已在数据目录中定义。 如果源需要连接,则您的作业中也会引用该连接。 请记住,连接包含连接到数据所需的属性。 如果您的作业需要多个数据源,您可以稍后通过编辑脚本来添加它们。 该脚本是自动生成的,在完成作业创建向导后立即可用。 接下来,您选择作业的数据目标。 表示数据目标的表可以在您的数据目录中定义,或者您的作业可以在运行时创建目标表。 您可以在创作作业时选择目标位置,如果目标需要连接,则作业中也会引用该连接。 如果您的作业需要多个数据目标,您可以稍后通过再次编辑脚本来添加它们。 接下来,您通过为作业和生成的脚本提供参数来自定义作业处理环境。 我们将在下一讲中添加一个带有演示的作业。 最初,AWS Glue 会生成一个脚本,但您也可以编辑该脚本以添加源、目标和转换。 您指定如何通过基于吨的计划或事件按需调用您的作业。 有关更多信息,请参阅接下来的演示,其中包括在 AWS Glue 中创建触发器并将其应用到作业。
根据您的输入,AWS Glue 生成 Pyspark 或 Scala 脚本。 您可以根据您的业务需求定制脚本。 如果您无权访问数据存储,您将被阻止,因此您必须使用以下任意类型的具有加密权限的身份、IAM 用户或 IAM 角色。 除了使用名称和密码之外,您还可以为每个用户生成访问密钥。 作为最佳实践,您不希望使用 root 用户访问数据源,但应努力限制仅访问所需的数据源,并维护对敏感数据的某些治理。 那么 AWS Glue 有什么好处呢? 无服务器。 您只需在 AWS Glue 运行时为资源付费。 爬网程序只需很少的配置即可从数据源检测并推断模式,并且可以安排爬网,还可以触发作业运行以执行 ETL。 自动代码生成为您提供了在 Python 或 Scala 代码中运行简单作业或在您自己的代码添加中进行扩展所需的功能。 该代码通过自定义端点与外部工具链集成。
使用 AWS Glue,您可以为发现数据的爬网程序以及处理和加载数据的 ETL 作业按秒计费。 对于 AWS Glue 数据目录,您只需支付简单的月费即可存储和访问元数据。 存储的前一百万个对象是免费的,前一百万个访问也是免费的。 如果您配置开发端点来交互式开发 ETL 代码,则您需要按每秒计费的小时费率付费。 在 US East-One 中,每个 DPU 小时的成本为 0.44 美元,单个 DPU 提供四个虚拟 CPU 和 16 GB 内存。 那么您什么时候会选择不使用 AWS Glue? 与许多技术一样,如何执行 ETL 也是有争议的。 还有许多其他本地和云中的 ETL 方法可以满足开发人员和组织的需求。 您的公司或团队可能已经在使用本地部署或其他 ETL 管道技术方面进行了大量投资,并且大多数 ETL 工具仍然是本地部署的,并且管道是通过 UI 可视化创建的。 语言仅限于 Python 和 Scala,并且更新架构时必须编辑作业。 如果您已经进行了开发,您的团队可能会对 Java 或其他语言进行投资。 AWS Glue 仍然是一个相对年轻的产品,目前没有第三方开箱即用的连接器,例如sales force 和其他您可以在更成熟的 ETL 工具集中期待的连接器。
爬虫的例子
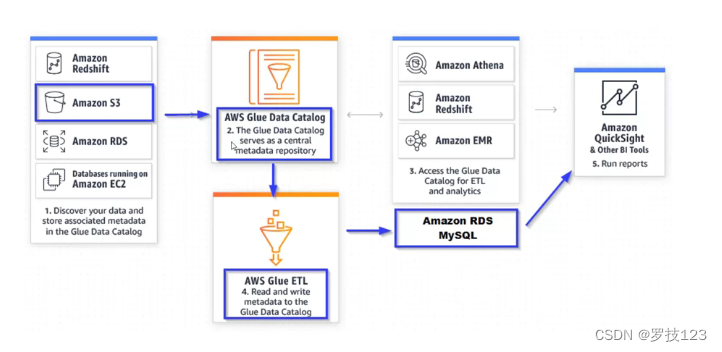
从 AWS S3 移动到 RDS MySQL 数据库所需的生命周期和流程。 此外,您还必须设置一个将与 AWS Glue 以及源数据和目标数据配合使用的安全 IAM 角色。
将使用爬网程序在数据目录中创建一个数据库,然后运行创建并运行 ETL 作业,将数据从 S3 源移动到 MySQL 数据库。 之后,您可以选择使用 Amazon QuickSight 或其他一些 BI 工具来查看可视化效果并分析数据。
我们要做的第一件事是创建一个爬虫。 现在,当我们创建爬虫时,在此过程中,我们将创建数据库和表,该表是数据目录并存储数据源或数据目标的元数据。我们只是为数据源创建一个爬虫。 单击添加爬网程序,然后我将选择我的数据源,即我们再次从交通统计局下载并上传到此处的 S3 存储桶的 CSV 文件。 点击下一步。 现在,如果我们愿意,我们可以添加另一个数据存储,,然后我们可以安排爬网程序每小时、每天或按需运行。 我们只会根据需要保留它,但有时您的存储桶中有新文件,并且您希望更定期地进行爬网。 捕获架构更改。
让我们添加我们的数据库。然后我们就完成了。 我们需要做的就是运行爬虫。 现在,当爬虫运行时,它会生成一些日志,这些日志将告诉我们爬虫是否成功,并且还允许我们排除是否存在任何问题。 这是爬网程序成功运行的日志示例。 除了运行爬虫之外,我们还想创建到数据目的地的连接。 我们知道我们正在连接到 MySQL 数据库。 我们可以单击“完成”。 现在,关于爬虫需要注意的一件事是,我们可以向爬虫添加一个分类器来帮助定义我们的数据源,并且有很多选项,这些是分类器类型。 如果您选择 Grok,那么您可以选择分类或数据格式类型,并且可以提供 Grok 模式。 您还可以选择 XML、JSON 或 CSV,最常见的数据源之一是 CSV 文件,但 CSV 文件有所不同,它们可能以逗号分隔制表符或管道分隔。 在本例中,您需要定义 CSV 文件。 我们的 CSV 文件非常常见,我们不需要使用分类器。 我们实际上使用了默认分类河 看起来我们的爬虫已经完成了。
我们已经创建了一个数据连接,现在我们要做的是创建一个作业,该作业将是 Csv_to_MySql。 同样,我们将使用之前创建的相同 IAM 角色。 我们将保留默认值。 我们将使用 AWS Glue 和 Python 生成脚本。 现在我们可以选择我们的数据源。 现在我们可以选择我们的数据目标。 现在,在本例中,我们要在我们创建的连接上创建表。 我们的数据库名称是destinationdemo。 我们点击“下一步”。 现在您可以看到映射就在这里。 我们可以进行一些编辑。 我们可以添加一列,如果愿意的话也可以添加一个空列。 但一切都已准备就绪,我们可以从数据源(即 CSV 文件)获取数据,对其进行转换并将其映射到目标数据库。 现在,一旦我们单击“保存”,它就会生成 Python 代码,我们可以在此处进行其他自定义。
我们创建的爬虫创建了一个数据库和一个表,当我们打开它时,该表会显示源文件中的元数据或列,我们可以查看以 JSON 形式出现的属性。 我们还可以编辑模式,例如,如果我们希望年份是 int,我们可以将 Bigint 更改为 int 数据类型。 更新并保存。 我们还可以添加一列。 我们还可以比较版本,例如,如果我们的爬虫抓取了两个不同的源,我们可以看到架构如何更改,并将其与一个和另一个之间的元数据定义进行比较。 我想讨论的另一件事是添加触发器。 现在,触发器可以安排我们创建的作业。 它可以按特定顺序或按需运行作业。 因此,如果我想在另一项工作之后运行一项工作,我想为此创建一个触发器。
AWS Glue 的优势,
- AWS Glue 中的 ETL 代码可以轻松运行无服务器。
- AWS Glue 有一个爬网程序,可以推断源数据、工作数据和目标数据的架构,爬网程序可以按计划运行以检测更改,
- AWS Glue 会自动生成 ETL 脚本,作为在 Python 或 Scala 中进行自定义的起点。