文章目录
- 1、虚拟机栈概述
- 1.1、StackOverflowError
- 1.2、OOM异常
- 2、栈的存储单位
- 3、局部变量表
- 3.1、局部变量表简介
- 3.2、Slot
- 4、操作数栈
- 5、栈顶缓存技术
- 6、动态链接
- 7、方法的调用
- 7.1、方法调用的分类
- 7.2、虚方法与非虚方法
- 7.3、关于invokedynamic指令
- 7.4、方法重写的本质
- 7.5、虚方法表
- 8、方法返回地址
- 8.1、方法正常完成退出
- 8.2、方法执行异常退出
有不少Java开发人员一提到Java内存结构,就会将JVM中的内存区理解为仅有Java堆(heap)和Java栈(stack)。这种划分想法来源于传统的C、C++程序的内存布局结构,但是在Java里有些粗糙了。尽管这种理解和划分非常不全面,但是从某种意义上来说,却恰恰反映出了这两个内存区是绝大多数Java开发人员最关注的,也是程序运行的关键。
众所周知,如果Java程序运行出现异常,程序会打印相应的异常堆栈信息,通过这些堆栈信息可以知道方法的调用链路。那么堆栈本身又是怎样的呢?栈由栈帧组成,每个栈帧又包括局部变量表、操作数栈、动态链接、方法返回地址和一些附加信息。
1、虚拟机栈概述
Java语言具有跨平台性,由于不同平台的CPU架构不同,所以Java的指令不能设计为基于寄存器的,而是设计为基于栈架构的。基于栈架构的优点是可以跨平台,指令集小,编译器容易实现。缺点是性能较低,实现同样的功能需要更多的指令。
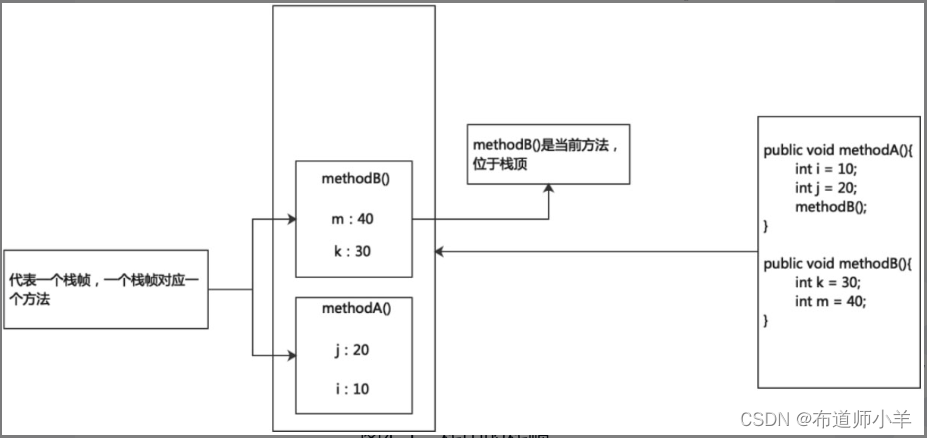
Java虚拟机栈(Java Virtual Machine Stack)早期也叫Java栈。每个线程在创建时都会创建一个虚拟机栈,其内部由许多栈帧(Stack Frame)构成,每个栈帧对应着一个Java方法的调用,如代码清单所示:

每个方法被执行的时候,JVM都会同步创建一个栈帧用于存储局部变量表、操作数栈、动态链接、方法出口等信息。每一个方法被调用直至执行完毕的过程,就对应着一个栈帧在虚拟机栈中从入栈到出栈的过程。如下图所示:
虚拟机栈的作用是主管Java程序的运行,栈解决程序的运行问题,即程序如何执行或者说如何处理数据。
以菜品佛跳墙为例,如下图所示:

在做菜之前,需要准备相应的食材,比如鳐鱼翅、小鲍鱼、瑶柱、广肚等主料,这些食材就相当于Java中的变量。上图中关于佛跳墙的做法列出了9个步骤,每一步负责把对应的食材放入到图4-2中右侧的瓦罐中,比如第一步把姜片铺在罐底,第二步负责铺上冬笋片,后面的步骤不再赘述,这个流程步骤就相当于虚拟机栈,负责处理Java中的相关变量。上图中右侧的瓦罐就相当于堆空间了。
虚拟机栈保存方法的局部变量(8种基本数据类型、对象的引用地址)和部分结果,并参与方法的调用和返回。虚拟机栈有如下几个特点:
- (1)栈是一种快速有效的分配存储方式,访问速度仅次于程序计数器。
- (2)对于栈来说不存在垃圾回收问题,但存在内存溢出。
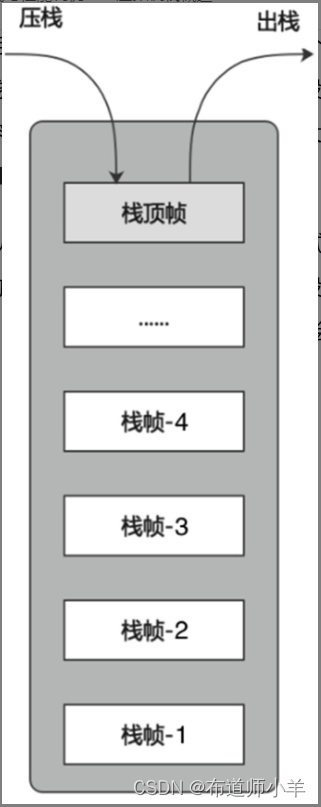
- (3)栈是先进后出的,每个方法执行,伴随着压栈操作;方法执行结束后,伴随着出栈操作,如下图所示:
Java虚拟机规范允许虚拟机栈的大小是可动态扩展的或者是固定不变的(注意:目前HotSpot虚拟机中不支持栈大小动态扩展)。关于虚拟机栈的大小可能出现的异常有以下两种: - (1)如果采用固定大小的Java虚拟机栈,那每一个线程的Java虚拟机栈容量在线程创建的时候按照固定大小来设置。如果线程请求分配的栈容量超过Java虚拟机栈允许的最大容量,JVM将会抛出一个StackOverflowError异常。
- (2)如果Java虚拟机栈可以动态扩展,并且在尝试扩展的时候无法申请到足够的内存,或者在创建新的线程时没有足够的内存去创建对应的虚拟机栈,那JVM将会抛出一个OutOfMemoryError(OOM,内存溢出)异常。
1.1、StackOverflowError
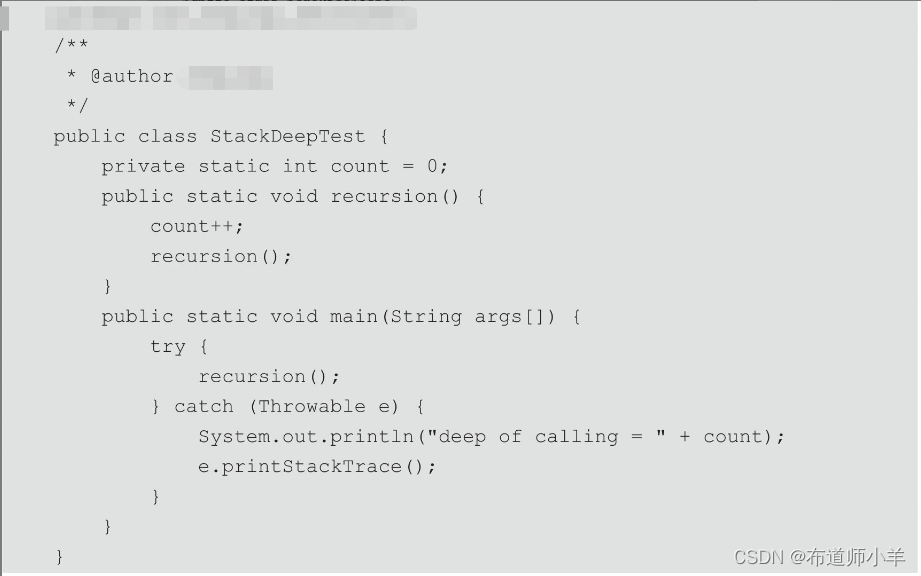
如下代码清单目的是抛出StackOverflowError异常:
我们可以使用参数-Xss选项来设置线程的最大栈空间,栈的大小直接决定了函数调用的最大可达深度。修改方法以IntelliJ IDEA为例。
(1)单击IntelliJ IDEA开发工具的“Run”,再单击“Edit Configurations”,如下图所示:
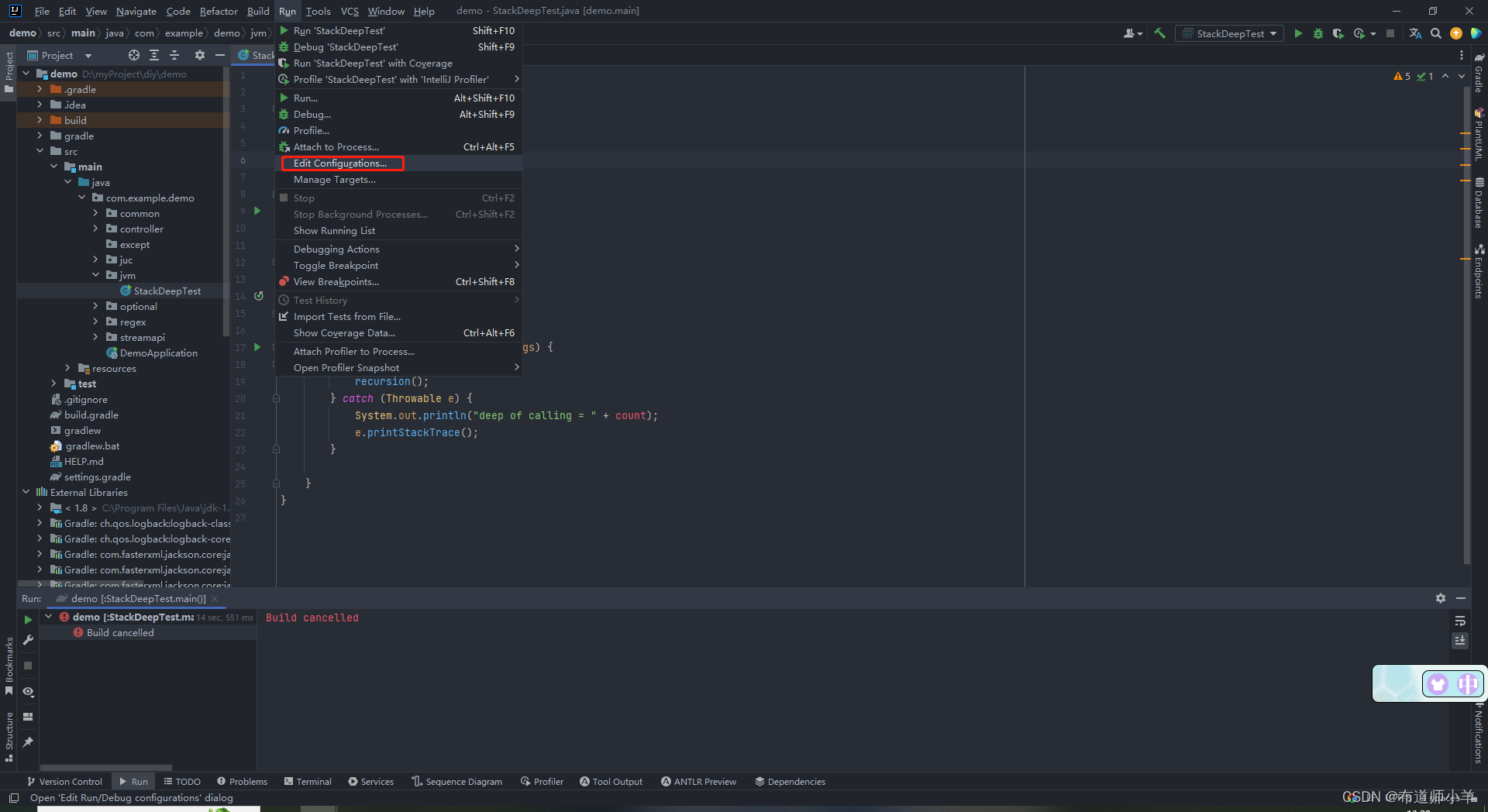
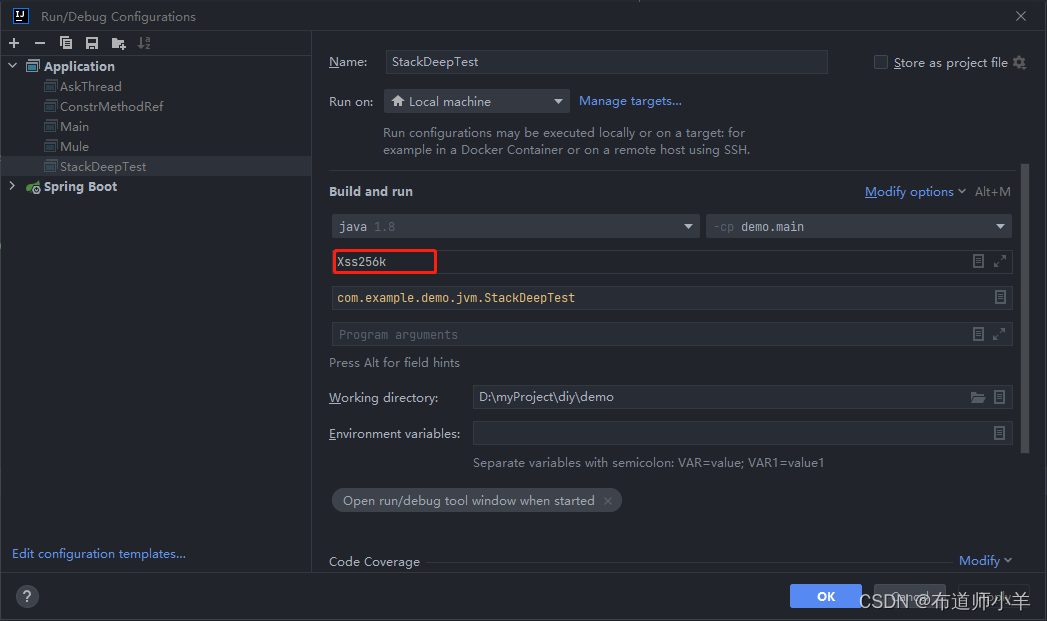
(2)进入“Edit Configurations”界面,修改“VM options”,然后单击“OK”按钮即可,如下图所示:
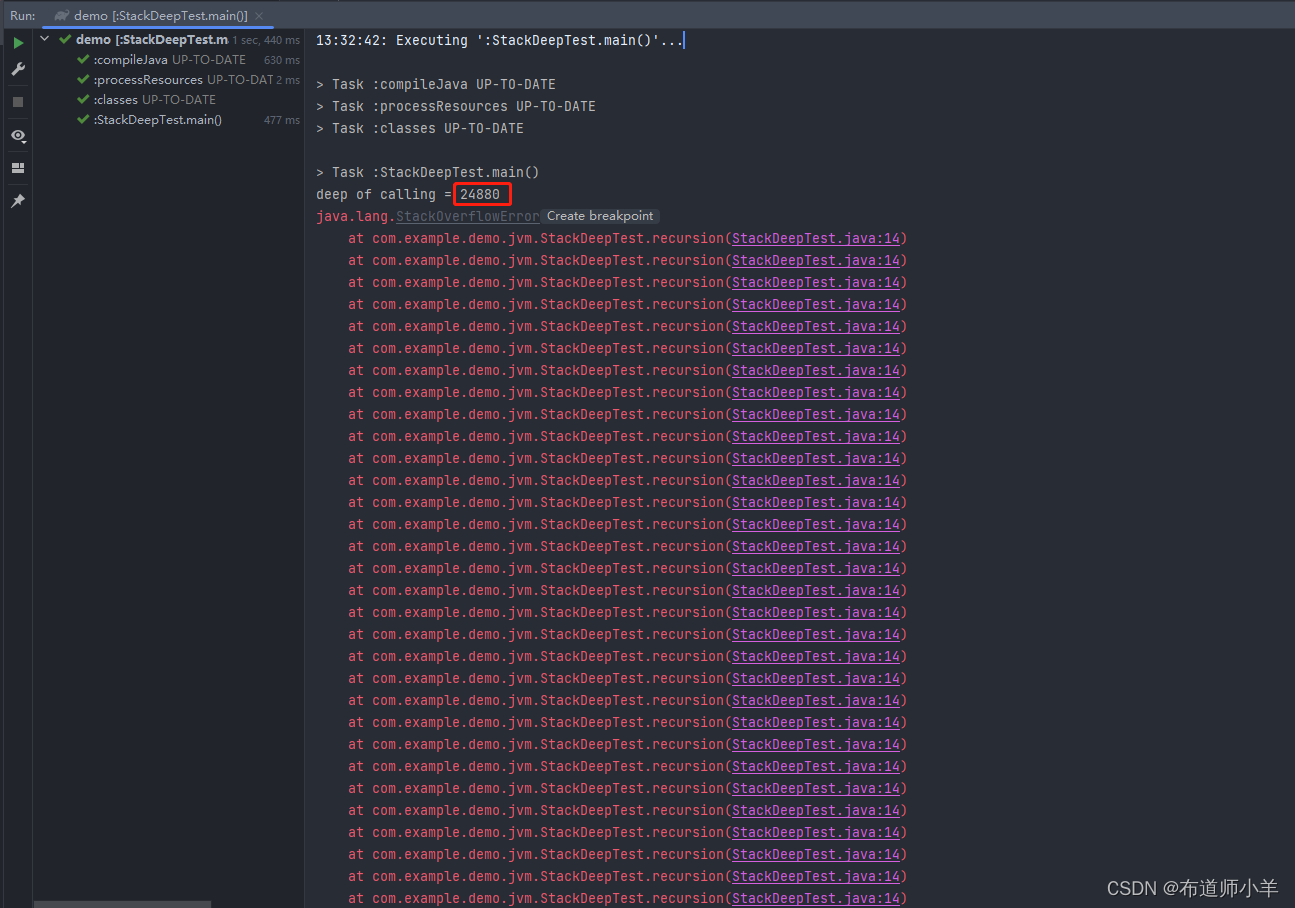
在没有设置栈大小的时候输出结果,栈大小默认为1M,如下图所示:
设置栈大小为256K之后的结果,如下图所示:
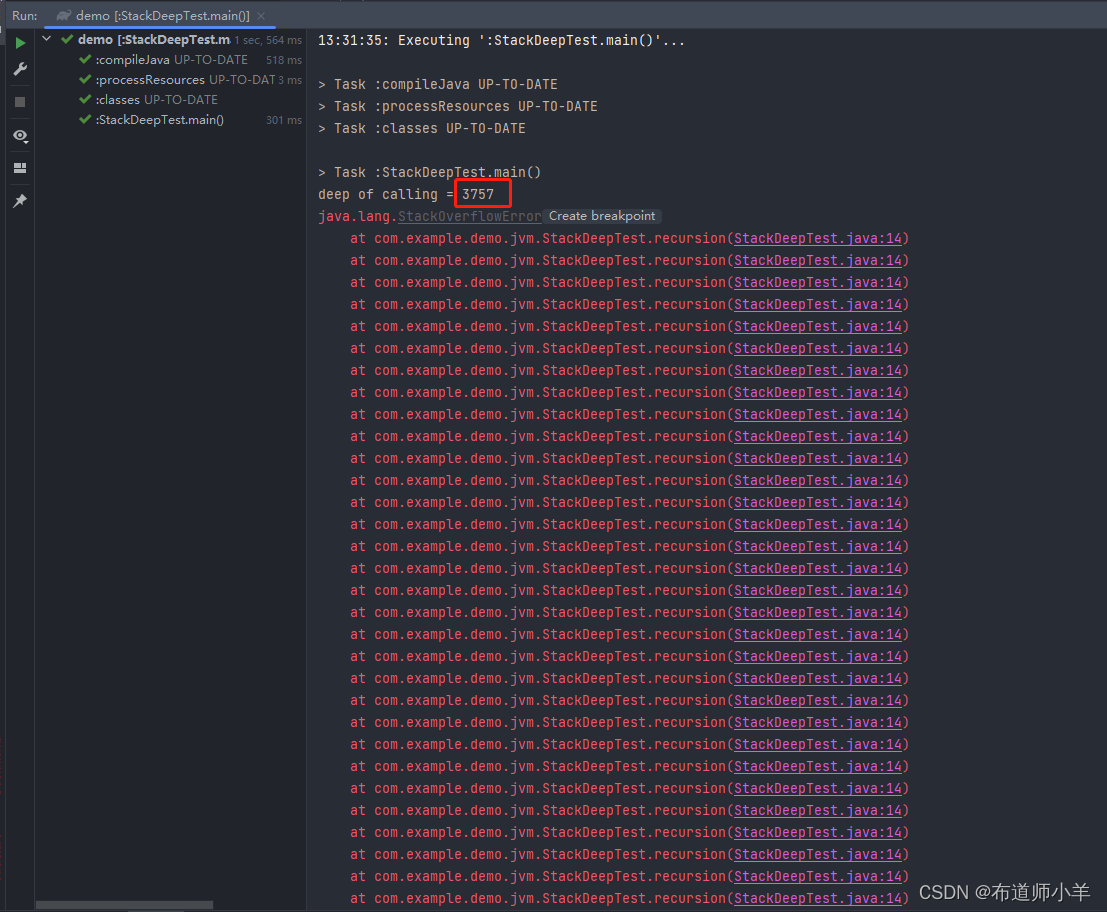
可以看到,当栈大小从默认的1M减小为256K之后,栈调用深度从22558变为了3561。这直接证明了栈的大小决定了函数调用的最大可达深度,即栈空间越大,函数调用深度越深,反之亦然。
1.2、OOM异常
import java.util.concurrent.CountDownLatch;/*** @title StackOutOfMemoryError* @description OOM异常* @author: yangyongbing* @date: 2024/2/29 19:05*/
public class StackOutOfMemoryError {public void main(String[] args) {for (int i = 0; ; i++) {System.out.println("i = " + i);new Thread(new HoldThread()).start();}}class HoldThread extends Thread {CountDownLatch countDownLatch = new CountDownLatch(1);@Overridepublic void run() {try {countDownLatch.await();} catch (InterruptedException e) {}}}
}运行结果如下:

需要注意的是案例2运行环境要求32位操作系统。
2、栈的存储单位
每个线程都有自己的栈,栈中的数据都是以栈帧(Stack Frame)的形式存在。在这个线程上正在执行的每个方法都各自对应一个栈帧,也就是说栈帧是Java中方法的执行环境。栈帧是一个内存区块,是一个数据集,维系着方法执行过程中的各种数据信息。
在一条活动线程中,一个时间点上只会有一个活动的栈帧,即只有当前正在执行的方法的栈帧(栈顶栈帧)是有效的,这个栈帧被称为当前栈帧,与当前栈帧相对应的方法就是当前方法,定义这个方法的类就是当前类。如下图所示:
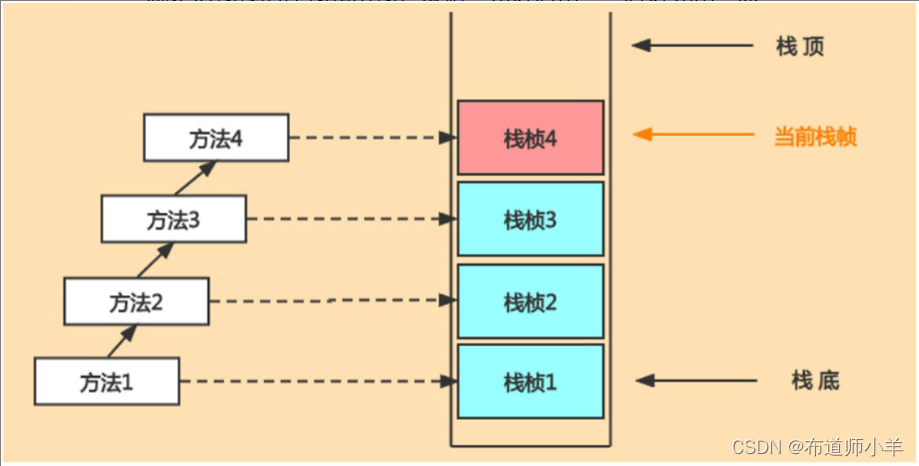
执行引擎运行的所有字节码指令只针对当前栈帧进行操作。如果在该方法中调用了其他方法,对应的新的栈帧会被创建出来,放在栈的顶端,成为新的当前帧。JVM直接对Java栈的操作只有两个,就是对栈帧的压栈和出栈,遵循“先进后出”“后进先出”原则。
代码清单:
/*** @title CurrentFrameTest* @description 当前栈帧* @author: yangyongbing* @date: 2024/2/29 19:21*/
public class CurrentFrameTest {public static void methodA() {System.out.println("当前栈帧对应的方法->methodA");methodB();System.out.println("当前栈帧对应的方法->methodA");}public static void methodB() {System.out.println("当前栈帧对应的方法->methodB");}public static void main(String[] args) {methodA();}
}演示了在一条活动线程中,一个时间点上只会有一个活动的栈帧。可以看到在main()方法中调用了methodA(),methodA()中调用完methodB()之后又输出了一条语句。
输出结果如下图所示:
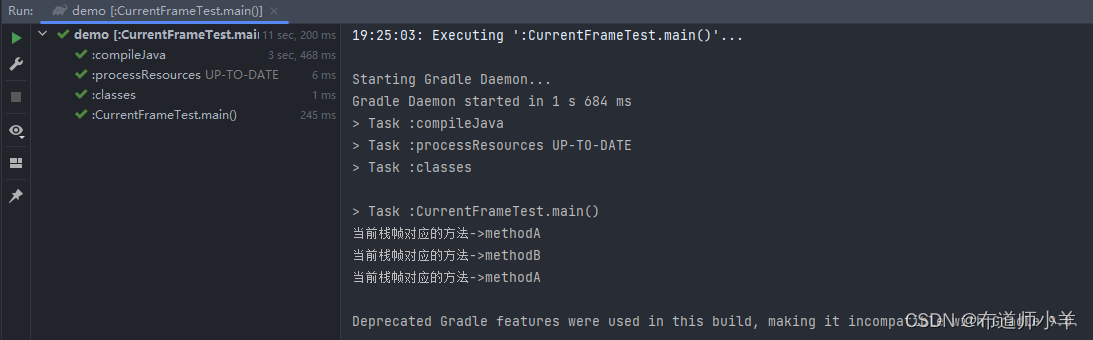
可以看到先执行了methodA()中的第一条输出语句,接着又执行了methodB(),之后又返回执行了methodA()中的第二条输出语句,证明了当执行某一个方法的时候其他方法是没有在执行的,即一个时间点上,只会有一个活动的栈帧。
代码清单:

演示了栈帧遵循“先进后出”“后进先出”原则。

下面介绍每个栈帧中存储的内容,如下图所示:
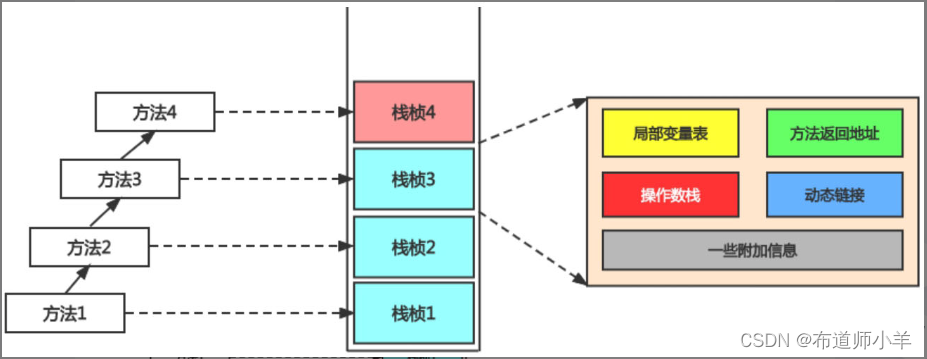
- 局部变量表(Local Variables)。
- 操作数栈(Operand Stack)(或表达式栈)。
- 动态链接(Dynamic Linking)(或指向运行时常量池的方法引用)。
- 方法返回地址(Return Address)(或方法正常退出或异常退出的定义)。
- 一些附加信息。例如,对程序调试提供支持的信息。
在多线程环境中,当前线程和当前栈帧如下图所示:
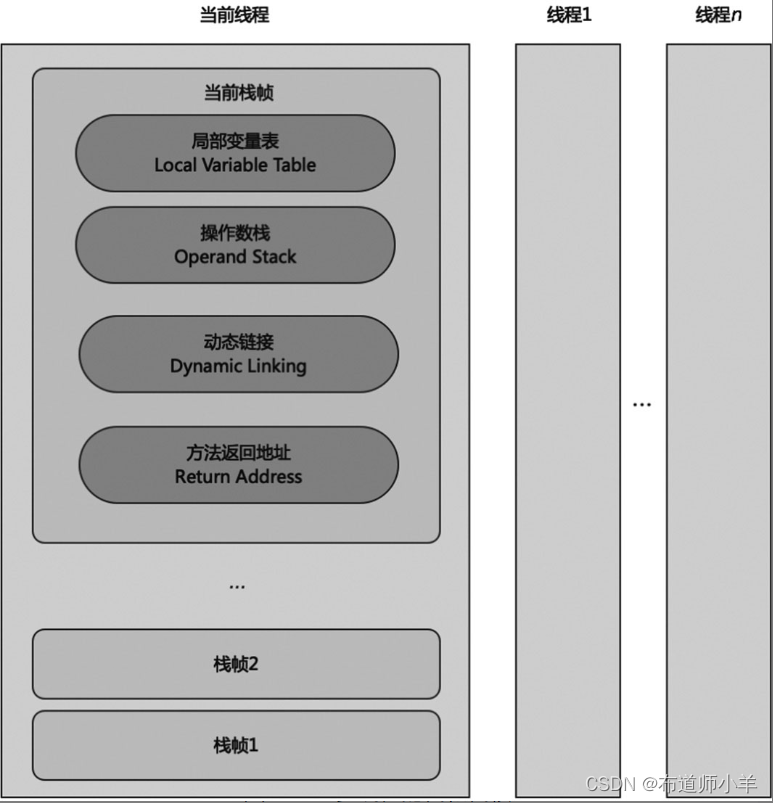
下面的小节分别介绍栈帧中存储的内容。
3、局部变量表
3.1、局部变量表简介
局部变量表也称为局部变量数组或本地变量表。局部变量表定义为一个数字数组,主要用于存储方法参数和定义在方法体内的局部变量,这些数据类型包括各类基本数据类型、对象引用(reference)以及returnAddress类型。对于基本数据类型的变量,则直接存储它的值,对于引用类型的变量,则存的是指向对象的引用。
由于局部变量表是建立在线程的栈上,是线程的私有数据,因此不存在数据安全问题。
由于局部变量表是建立在线程的栈上,是线程的私有数据,因此不存在数据安全问题。
局部变量表所需的容量大小是在编译期确定下来的,并保存在方法的Code属性的maximum local variables数据项中。在方法运行期间是不会改变局部变量表的大小的。
方法嵌套调用的次数由栈的大小决定。一般来说,栈越大,方法嵌套调用次数越多。对一个方法而言,它的参数和局部变量越多,使得局部变量表越膨胀,它的栈帧就越大,以满足方法调用所需传递的信息增大的需求。进而调用方法就会占用更多的栈空间,导致其嵌套调用次数就会减少。
局部变量表中的变量只在当前方法调用中有效。在方法执行时,虚拟机通过使用局部变量表完成参数值到参数变量列表的传递过程。当方法调用结束后,随着方法栈帧的销毁,局部变量表也会销毁。
下面通过代码清单:
/*** @title LocalVariableTest* @description 查看局部变量表* @author: yangyongbing* @date: 2024/2/29 19:43*/
public class LocalVariableTest {public static void main(String[] args) {LocalVariableTest localVariableTest = new LocalVariableTest();int num=10;long num1=12;}
}演示局部变量表,注意,在查看局部变量表之前需要编译好代码,即编译为class文件。
通过IntelliJ IDEA安装Jclasslib Bytecode Viewer插件可以查看局部变量表。安装好插件以后,单击“View”选项,选择“Show Bytecode With Jclasslib”选项,如下图所示:
上面的操作结果如下图所示:
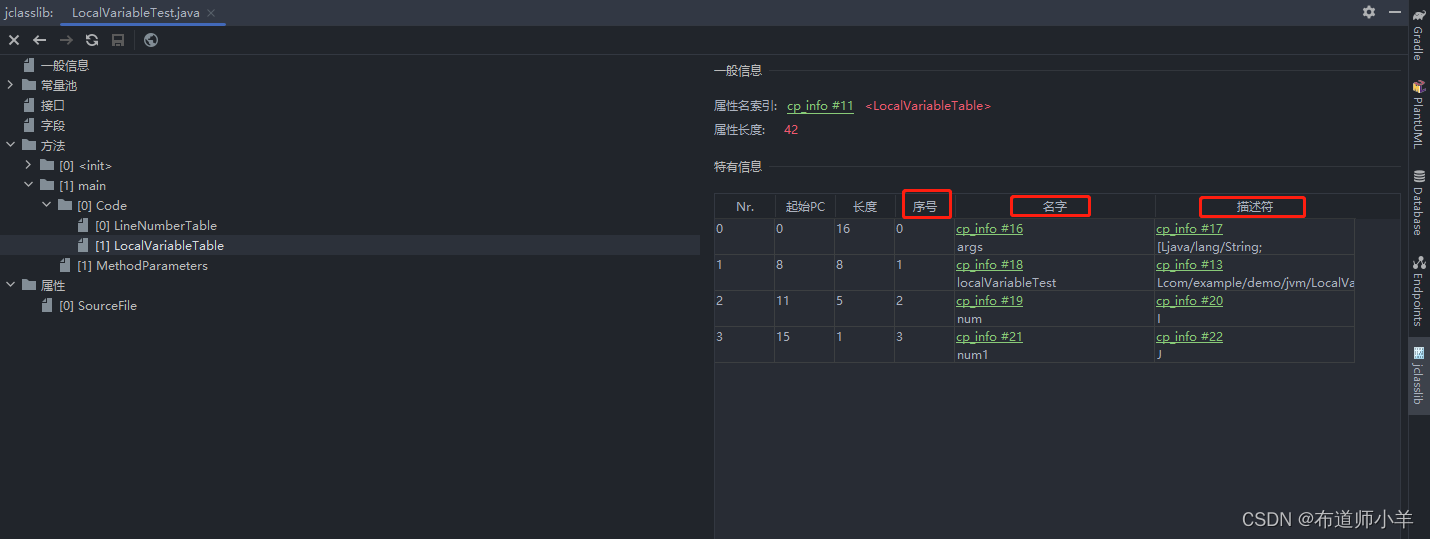
LocalVariableTable用来描述方法的局部变量表,在class文件的局部变量表中,显示了每个局部变量的作用域范围、所在槽位的索引(Index列)、变量名(Name列)和数据类型(J表示long型)。参数值的存放总是从局部变量表的索引(Index)为0开始,到变量总个数减1的索引结束,可以看到,main()方法中总共存在4个变量,分别是args、test、num和num1,Index的初始值为0,最终值为3。
如下图所示:
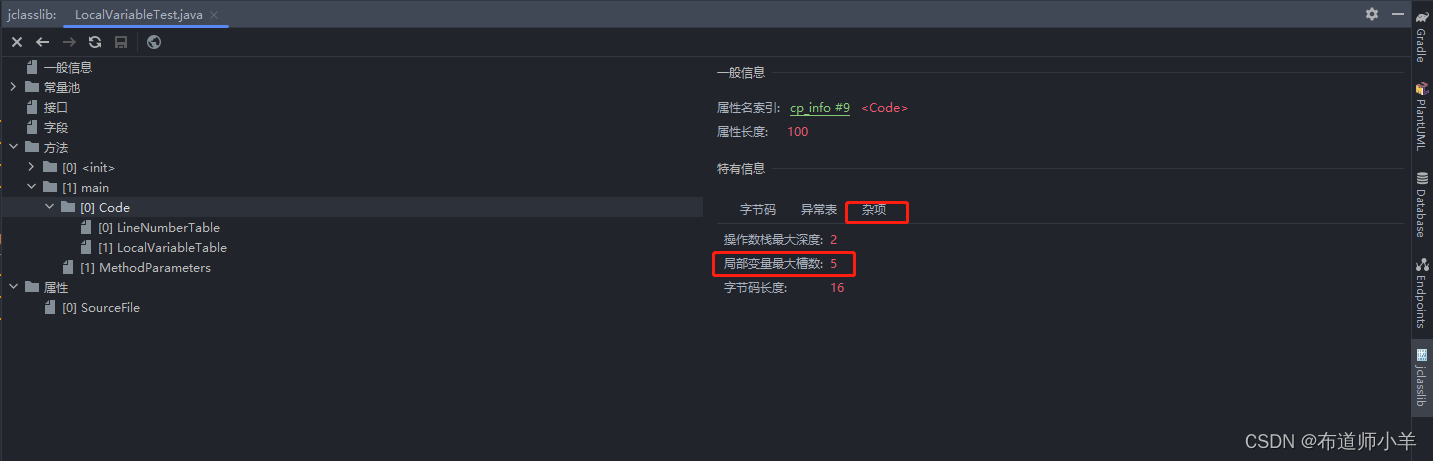
在“Code”选项下的“Misc”列中Maximum local variables值为5,可是明明局部变量表中变量的数量只有4个,为什么局部变量表大小是5呢?这是因为局部变量表最基本的存储单元是slot,long类型的数据占两个slot,所以需要加1。
3.2、Slot
局部变量表最基本的存储单元是slot(变量槽)。局部变量表中存放编译期可知的各种基本数据类型(8种)、引用(reference)类型、return Address类型的变量。
在局部变量表里,32位以内的类型(包括reference、returnAddress类型)只占用一个slot,64位的类型(long和double)占用两个slot。
byte、short、char在存储前被转换为int,boolean也被转换为int,0表示false,非0表示true。
long和double则占据两个slot。
JVM会为局部变量表中的每一个slot都分配一个访问索引,通过这个索引即可成功访问到局部变量表中指定的局部变量值。
如下图所示:
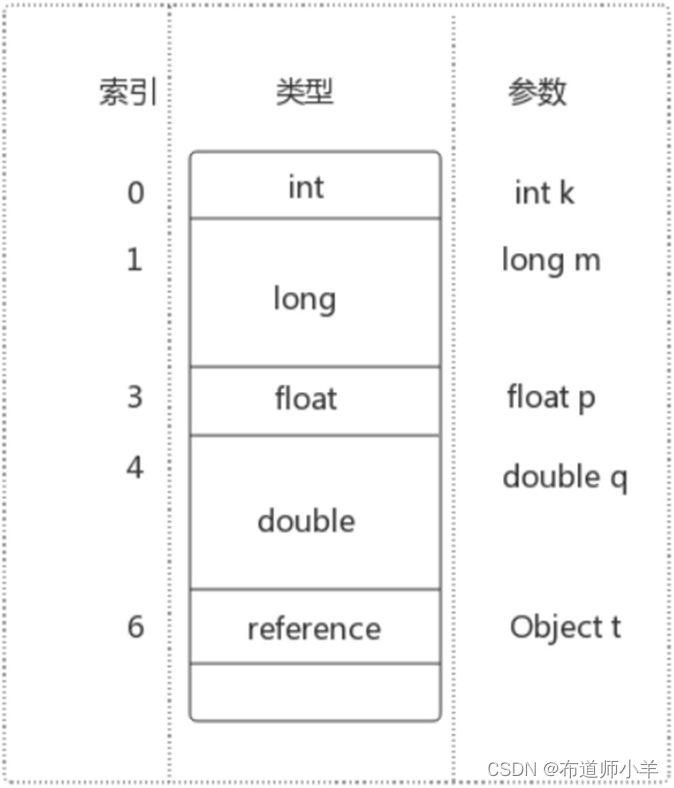
long类型和double类型的占两个slot,当调用long类型或double类型的变量时用它的起始索引。即调用long类型的m时需要用索引“1”,调用double类型的q时需要用索引“4”。
当一个实例方法被调用的时候,它的方法参数和方法体内部定义的局部变量将会按照顺序被复制到局部变量表中的每一个slot上。如果需要访问局部变量表中一个64位的局部变量值,只需要使用该变量占用的两个slot中的第一个slot的索引即可。比如,访问long类型或double类型变量,如果当前帧是由构造方法或者实例方法创建的,那么该对象引用this将会存放在index为0的slot处,其余的参数按照参数表顺序继续排列。
栈帧中的局部变量表中的slot是可以重用的,如果一个局部变量过了其作用域,那么在其作用域之后申明的新的局部变量就很有可能会复用过期局部变量的slot,从而达到节省资源的目的。
代码清单:

演示了局部变量表中变量对slot的占用。
localVarl()方法局部变量表的长度为3,变量的个数为3个,局部变量分别是this、a、b,没有重复利用的slot,如下图所示:
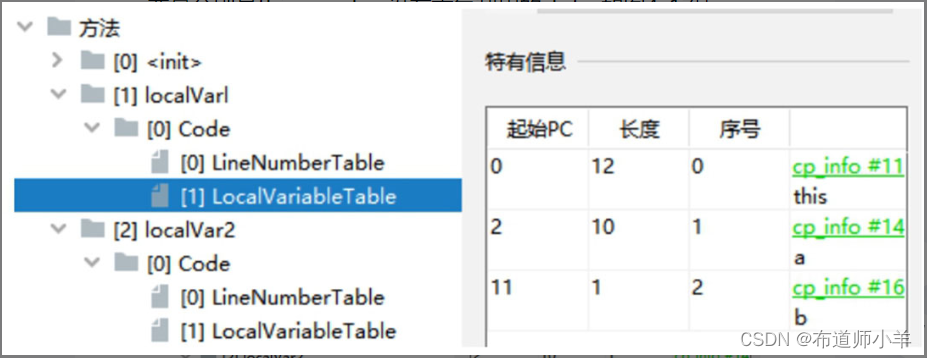
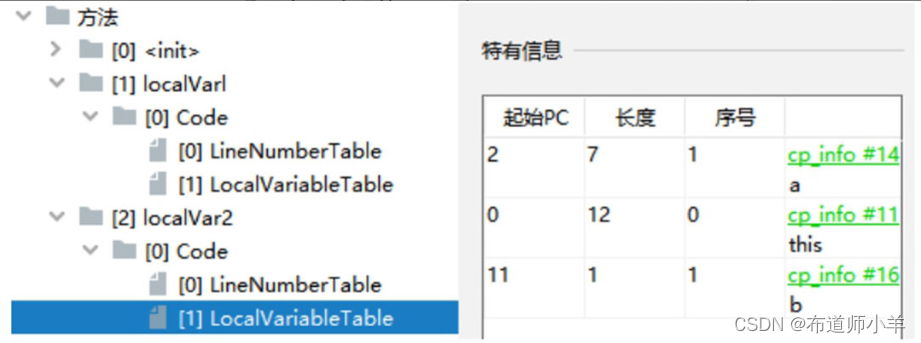
localVar2()方法局部变量表的长度为2,变量的个数为2个,局部变量分别是this、b。a的作用域在大括号内,当出了a的作用域后b复用了a的slot,如下图所示:
参数表分配完毕之后,再根据方法体内定义的变量的顺序和作用域分配。上面说了局部变量的存储位置,局部变量的值是怎么初始化的呢?我们知道静态变量有两次初始化的机会:第一次是在“准备阶段”,执行系统初始化,对静态变量设置零值;另一次则是在“初始化”阶段,赋予程序员在代码中定义的初始值。和静态变量初始化不同的是,局部变量表不存在系统初始化的过程,这意味着一旦定义了局部变量则必须手动初始化,否则无法使用,如代码清单如下所示:

值得注意的是,在栈帧中,与性能调优关系最为密切的部分就是前面提到的局部变量表。在方法执行时,虚拟机使用局部变量表完成方法的传递。
局部变量表中的变量也是重要的垃圾回收根节点,只要被局部变量表中直接或间接引用的对象都不会被回收。
4、操作数栈
每一个独立的栈帧中除了包含局部变量表以外,还包含一个后进先出的操作数栈,也可以称为表达式栈(Expression Stack)。
操作数栈也是栈帧中重要的内容之一,它主要用于保存计算过程的中间结果,同时作为计算过程中变量临时的存储空间。
操作数栈在方法执行过程中,根据字节码指令往栈中写入数据或提取数据,即入栈(push)/出栈(pop)。
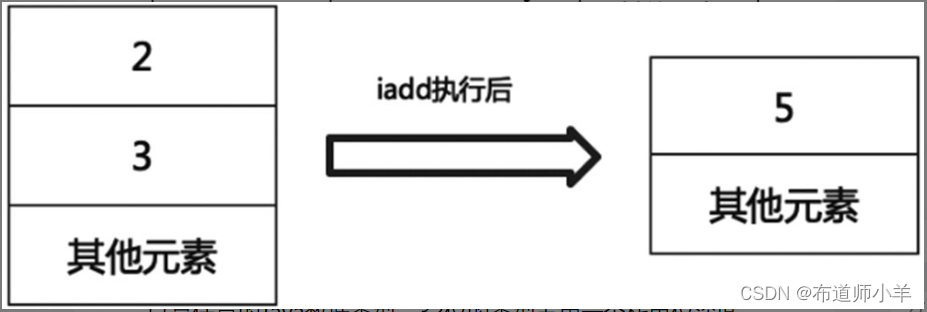
某些字节码指令将值压入操作数栈,其余的字节码指令将操作数从栈中取出,比如,执行复制、交换、求和等操作。使用它们后再把结果压入栈,如下图所示:
每一个操作数栈都会拥有一个明确的栈深度用于存储数值,其所需的最大深度在编译期就定义好了,保存在方法的Code属性中的Maximum stack size数据项中。栈中的任何一个元素都可以是任意的Java数据类型。32位的类型占用一个栈单位深度,64位的类型占用两个栈单位深度。
操作数栈并非采用访问索引的方式来进行数据访问的,而是只能通过标准的入栈(push)和出栈(pop)操作来完成一次数据访问。如果被调用的方法带有返回值的话,其返回值将会被压入当前栈帧的操作数栈中,并更新程序计数器中下一条需要执行的字节码指令。
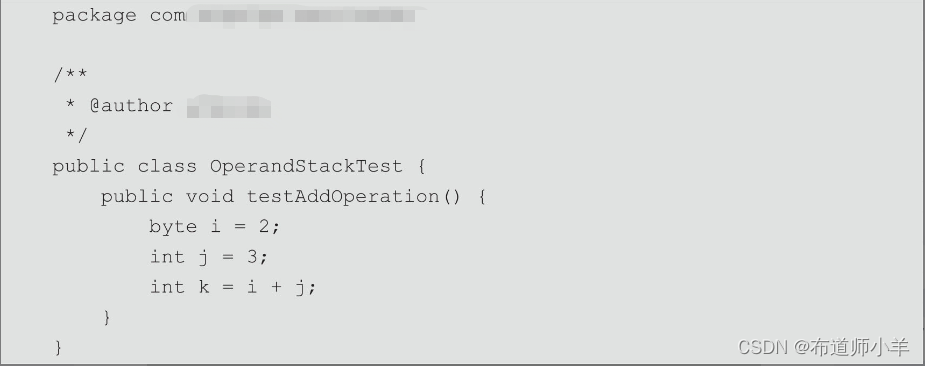
操作数栈中元素的数据类型必须与字节码指令的序列严格匹配,这由编译器在编译期间进行验证,同时在类加载过程中的类检验阶段的数据流分析阶段要再次验证。另外,我们说JVM的解释引擎是基于栈的执行引擎,其中的栈指的就是操作数栈,如代码清单如下所示:
使用javap命令反编译class文件:javap -v类名.class,部分结果如下:
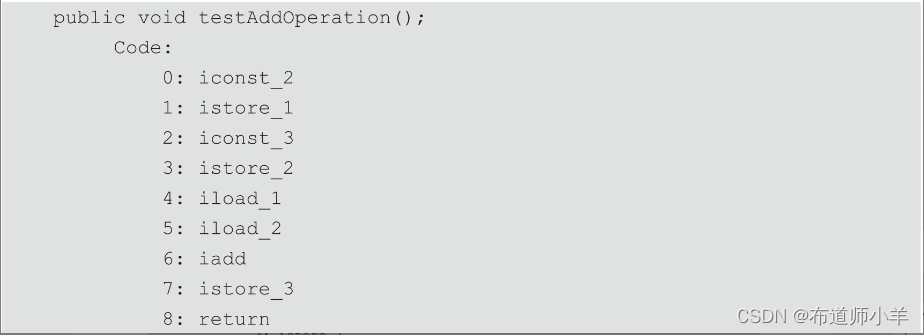
字节码执行步骤追踪如下所示:
(1)由“iconst_2”指令将数值2从byte类型转换为int类型后压入操作数栈的栈顶(对于byte、short和char类型的值在入栈之前,会被转换为int类型),如下图所示:
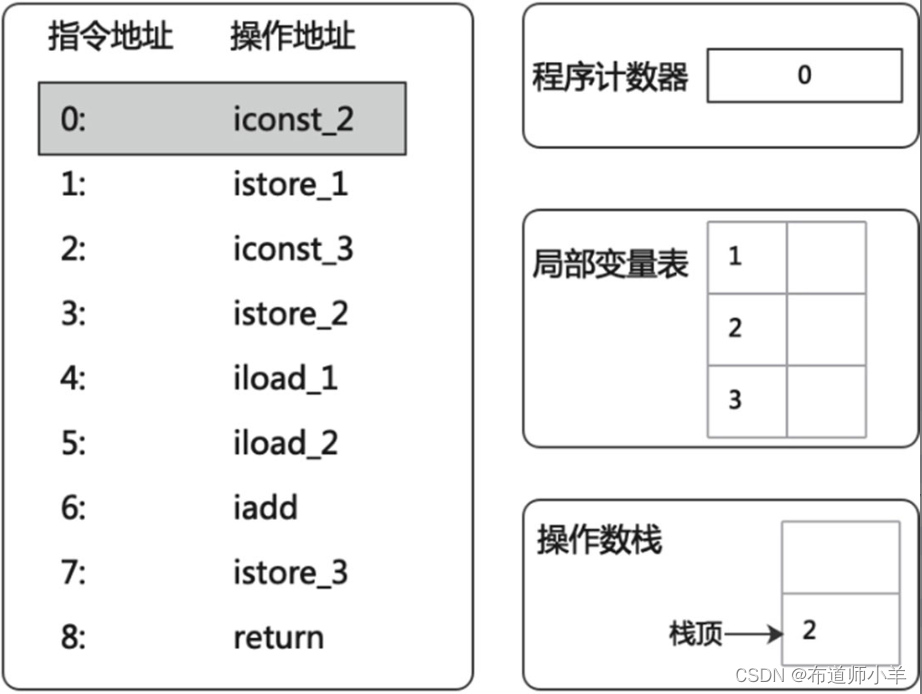
(2)当成功入栈后,“istore_1”指令便会负责将栈顶元素出栈并存储在局部变量表中访问索引为1的slot上,如下图所示:
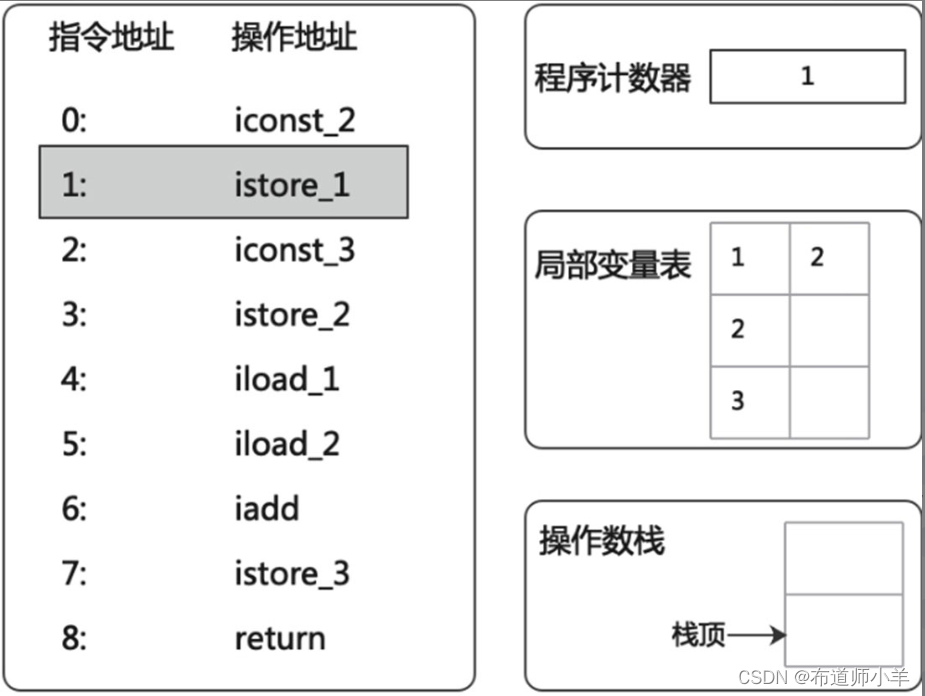
(3)接下来执行“iconst_3”指令将数值3压入栈顶,如下图所示:
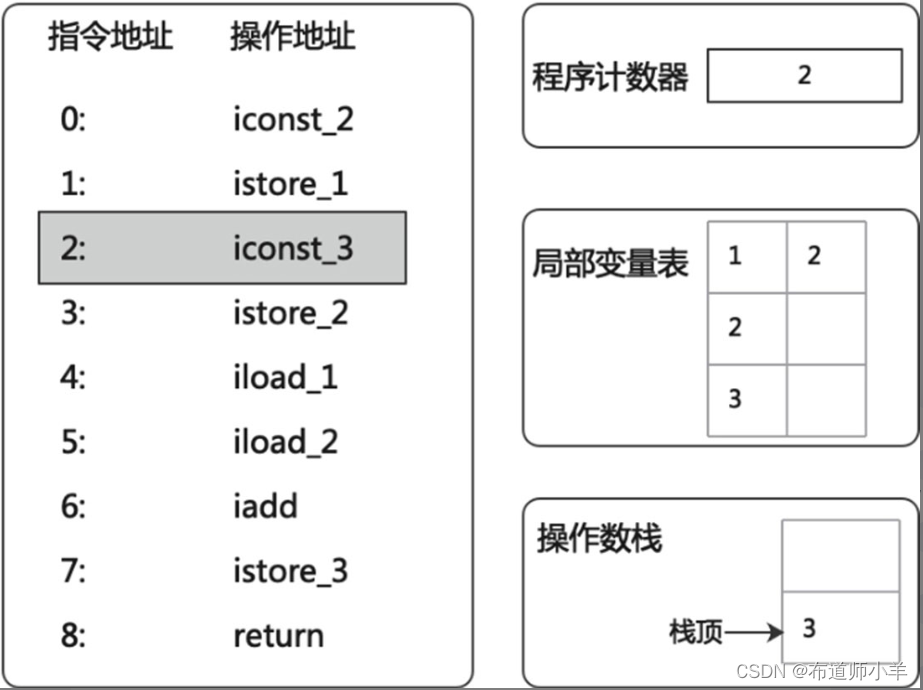
(4)通过“istore_2”指令将栈顶元素出栈,并存储在局部变量表中索引为2的slot上,如下图所示:
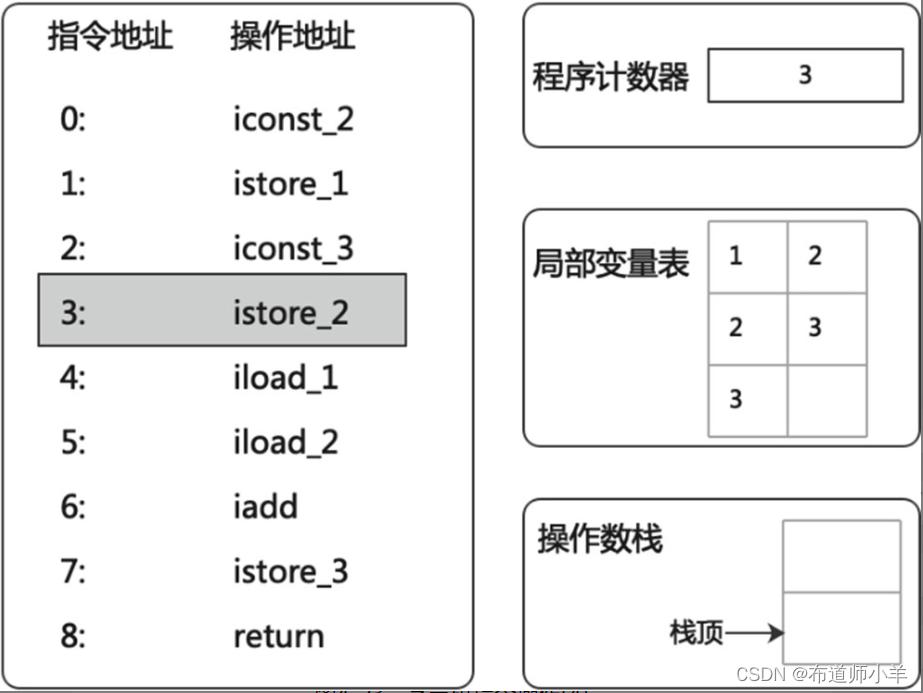
(5)“iload_1”指令会将局部变量表中访问索引为1的slot上的数值2重新压入操作数栈的栈顶,如下图所示:
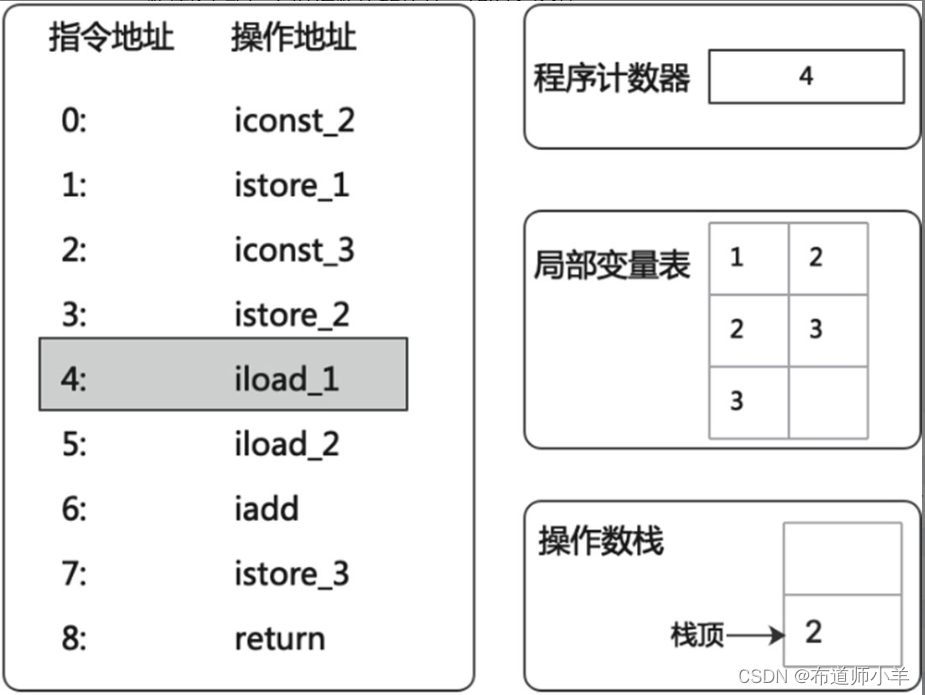
(6)“iload_2”指令会将局部变量表中访问索引为2的slot上的数值3重新压入操作数栈的栈顶,如下图所示:
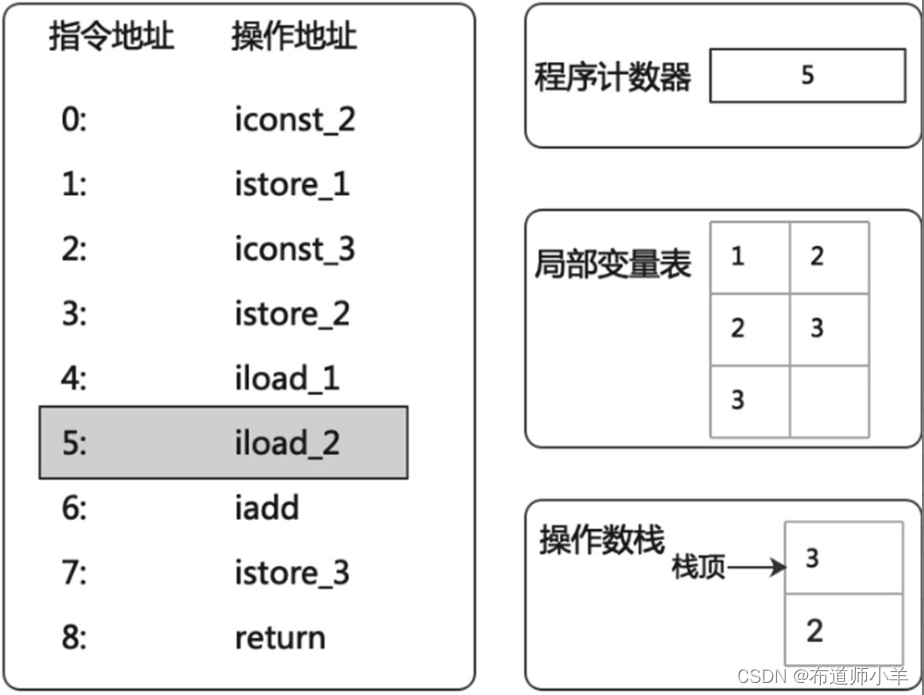
(7)紧接着“iadd”指令便会将这两个数值出栈,执行加法运算后再将运行结果重新压入栈顶,如下图所示:
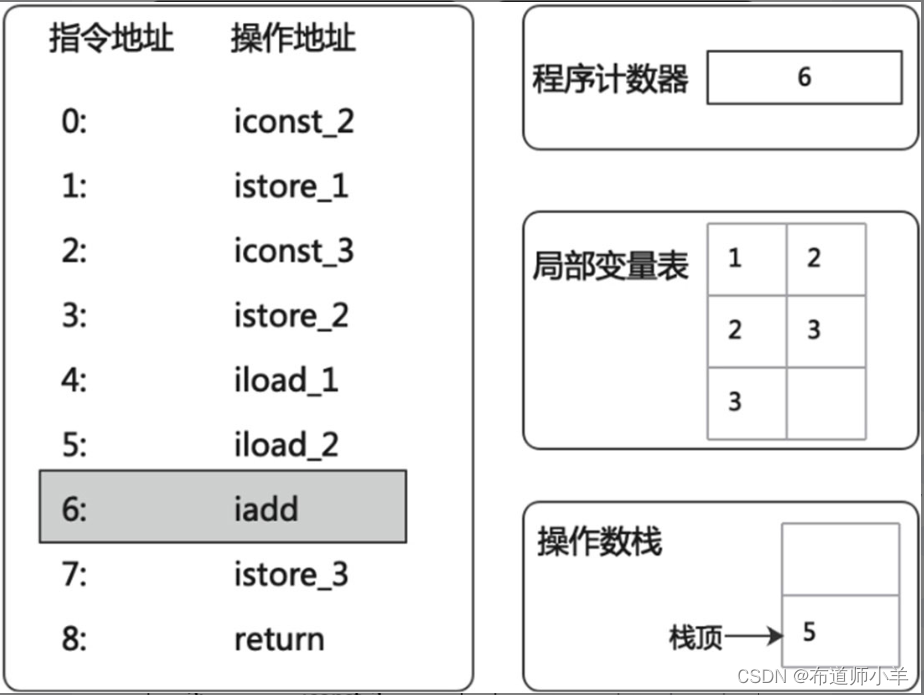
(8)“istore_3”会将运行结果出栈并存储在局部变量表中访问索引为3的slot上,如下图所示:
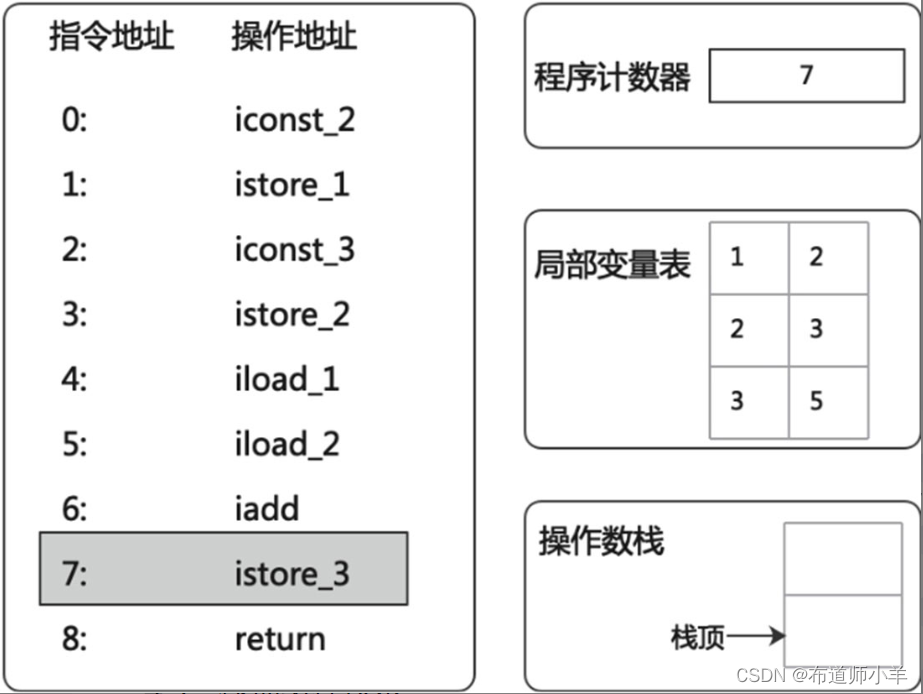
最后“return”指令的作用就是方法执行完成之后的返回操作。
5、栈顶缓存技术
前面讲过,目前主流的JVM基本都是基于栈式架构的虚拟机,此外还有一种架构是基于寄存器的。基于栈式架构的虚拟机和基于寄存器架构的虚拟机在完成同一逻辑的时候,前者使用到的字节码指令比后者需要的字节码指令更多,这也就意味着将需要更多的指令分派(Instruction Dispatch)次数和内存读、写次数。
由于操作数是存储在内存中的,因此频繁地执行内存读、写操作必然会影响执行速度。为了提升性能,HotSpot虚拟机的设计者提出了栈顶缓存(Top-of-Stack Cashing,ToS)技术。所谓栈顶缓存技术就是当一个栈的栈顶或栈顶附近元素被频繁访问,就会将栈顶或栈顶附近的元素缓存到物理CPU的寄存器中,将原本应该在内存中的读、写操作分别变成了寄存器中的读、写操作,从而降低对内存的读、写次数,提升执行引擎的执行效率。要理解这一点,需要了解计算机的硬件知识,对于CPU而言,从读取速度上来说,CPU从寄存器中读取速度最快,其次是内存,最后是磁盘。CPU从寄存器中读取数据的速度往往比从内存中读取要快好几个数量级,这种速度差异非常大,达百倍以上。那么为什么不把数据全部放入寄存器呢?这是因为一个CPU能够集成的寄存器数量极其有限,相比于内存空间简直就是沧海一粟,所以性能和空间两者始终不能两全。栈顶缓存正是针对CPU这种在时间和空间上不能两全的遗憾而进行的改进措施。就好比我们在系统设计时,都会加入缓存这种中间件,首先系统从缓存中查询数据,如果缓存存在则返回,否则查询DB,两者设计思想有异曲同工之妙。
6、动态链接
每一个栈帧内部都包含一个指向运行时常量池中该栈帧所属方法的引用。包含这个引用的目的就是为了支持当前方法的代码能够实现动态链接(Dynamic Linking)。
在Java源文件被编译成字节码文件时,所有的变量和方法引用都作为符号引用(Symbolic Reference)保存在class文件的常量池里。比如,描述一个方法调用了另外的其他方法时,就是通过常量池中指向方法的符号引用来表示的。动态链接的目的就是在JVM加载了字节码文件,将类数据加载到内存以后,当前栈帧能够清楚记录此方法的来源。将字节码文件中记录的符号引用转换为调用方法的直接引用,直接引用就是程序运行时方法在内存中的具体地址。
如下图所示:
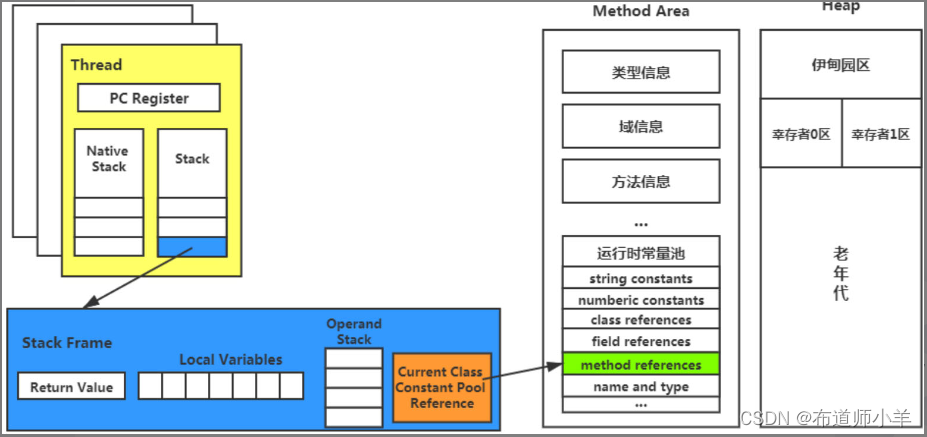
图中Thread区域代表着一个个的线程,Stack Frame区域代表着栈中的一个栈帧,Current Class Constant Pool Reference区域为动态链接,method references区域代表着方法的引用地址,即直接引用。动态链接指向运行时常量池中的方法的引用地址,运行时常量池指的是class文件中常量池表在程序运行时在内存中的形式。
7、方法的调用
7.1、方法调用的分类
前面说了动态链接的作用就是将符号引用转换为调用方法的直接引用。在JVM中,将符号引用转换为调用方法的直接引用与方法的绑定机制相关,方法的绑定机制有两种,分别是静态链接和动态链接。
- 静态链接:当一个字节码文件被装载进JVM内部时,如果被调用的目标方法在编译期可知,且运行期保持不变时。这种情况下,将调用方法的符号引用转换为直接引用的过程称为静态链接。
- 动态链接:如果被调用的方法在编译期无法被确定下来,也就是说,只能够在程序运行期将调用方法的符号引用转换为直接引用,由于这种引用转换过程具备动态性,因此也就被称为动态链接。
静态链接和动态链接一般还会被称为早期绑定(Early Binding)和晚期绑定(Late Binding)。绑定的意思就是一个字段、方法或者类的符号引用被转换为直接引用的过程,这仅仅发生一次。
静态链接和动态链接的代码示例如下:
/*** @title Animal* @description 静态链接和动态链接* @author: yangyongbing* @date: 2024/3/1 12:14*/
public class Animal {public void sound(){System.out.println(" 动物发发声 ");}interface Huntable{void hunt();}class Dog extends Animal implements Huntable{@Overridepublic void sound() {System.out.println(" 汪汪汪 ");}@Overridepublic void hunt() {System.out.println(" 捕食耗子,多管闲事 ");}}class Cat extends Animal implements Huntable{public Cat() {super(); // 表现为: 静态链接}public Cat(String name) {this(); // 表现为: 静态链接}@Overridepublic void sound() {super.sound(); // 表现为: 静态链接System.out.println(" 喵喵喵 ");}@Overridepublic void hunt() {System.out.println(" 捕食耗子,天经地义 ");}}public class AnimalTest{public void showAnimal(Animal animal){animal.sound(); // 表现为: 静态链接}public void showHunt(Huntable h){h.hunt(); // 表现为: 静态链接}}
}
上面代码中有类Animal和接口Huntable,Dog类和Cat类继承了Animal类和实现了Huntable接口,并且重写了sound()方法和hunt()方法。在测试类AnimalTest编写showAnimal(Animal animal)方法,此时是无法在编译期可知的,因为该方法是可以传入Dog类和Cat类的,无法确定,同理showHunt(Huntable h)方法也是一样的道理,本身传入的就是接口,更无法确定了,所以这两个方法都是动态链接。
Cat类中的构造方法Cat()则可以在编译期确定,因为该方法就是针对Cat类的实例调用的,所以是静态链接,Dog类同理。
随着高级语言的横空出世,类似于Java的面向对象的编程语言越来越多,尽管这类编程语言在语法风格上存在一定的差别,但是它们彼此之间始终保持着一个共性,那就是都支持封装、继承和多态等面向对象特性。既然这一类的编程语言具备多态特性,那么自然也就具备静态链接和动态链接两种绑定方式。
7.2、虚方法与非虚方法
前面说了方法绑定分为静态链接和动态链接,静态链接是指方法在编译期就确定了具体的调用版本,这个版本在运行时是不可变的,一般称这样的方法为非虚方法。除去非虚方法的都叫作虚方法。一般来说,静态方法、私有方法、final方法、实例构造器、父类方法都是非虚方法。在代码清单:
/*** @title Animal* @description 静态链接和动态链接* @author: yangyongbing* @date: 2024/3/1 12:14*/
public class Animal {public void sound(){System.out.println(" 动物发发声 ");}interface Huntable{void hunt();}class Dog extends Animal implements Huntable{@Overridepublic void sound() {System.out.println(" 汪汪汪 ");}@Overridepublic void hunt() {System.out.println(" 捕食耗子,多管闲事 ");}}class Cat extends Animal implements Huntable{public Cat() {super(); // 表现为: 静态链接}public Cat(String name) {this(); // 表现为: 静态链接}@Overridepublic void sound() {super.sound(); // 表现为: 静态链接System.out.println(" 喵喵喵 ");}@Overridepublic void hunt() {System.out.println(" 捕食耗子,天经地义 ");}}public class AnimalTest{public void showAnimal(Animal animal){animal.sound(); // 表现为: 静态链接}public void showHunt(Huntable h){h.hunt(); // 表现为: 静态链接}}
}
中showHunt(Huntable h)和showAnimal(Animal animal)是虚方法,而Cat类中的构造方法Cat()是非虚方法。
有时候如果不能很好地区分虚方法和非虚方法,可以通过字节码文件的方法调用指令来区分。虚拟机中提供了以下5条方法调用指令:
- (1)invokestatic:调用静态方法,解析阶段确定唯一方法版本。
- (2)invokespecial:调用方法、私有及父类方法,解析阶段确定唯一方法版本。
- (3)invokevirtual:调用所有虚方法。
- (4)invokeinterface:调用接口方法。
- (5)invokedynamic:动态解析出需要调用的方法,然后执行。
方法调用指令可以分为普通调用指令和动态调用指令,前四条指令是普通调用指令,它们固化在虚拟机内部,方法的调用执行不可人为干预。第五条指令是动态调用指令,invokedynamic指令支持由用户确定方法版本。其中invokestatic指令和invokespecial指令调用的方法称为非虚方法,其余的(final修饰的除外)称为虚方法。解析调用中的非虚方法和虚方法,如代码清单所示:


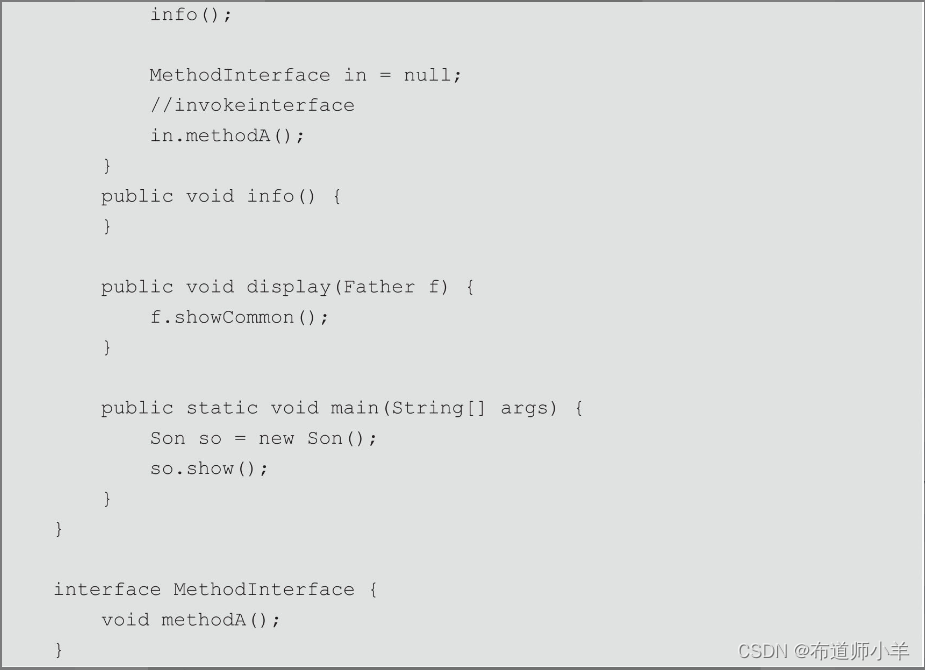
通过jclasslib工具查看该类的字节码文件,可以发现在show()方法中各个方法对应的字节码指令如下表所示:

从上表中可以看出,前四个方法都是由字节码指令invokestatic和invokespecial调用,所以这四种方法属于非虚方法。第五个方法由字节码指令invokevirtual调用,但是该方法是由final关键字修饰的,所以该方法也是非虚方法。后面的方法都是虚方法。
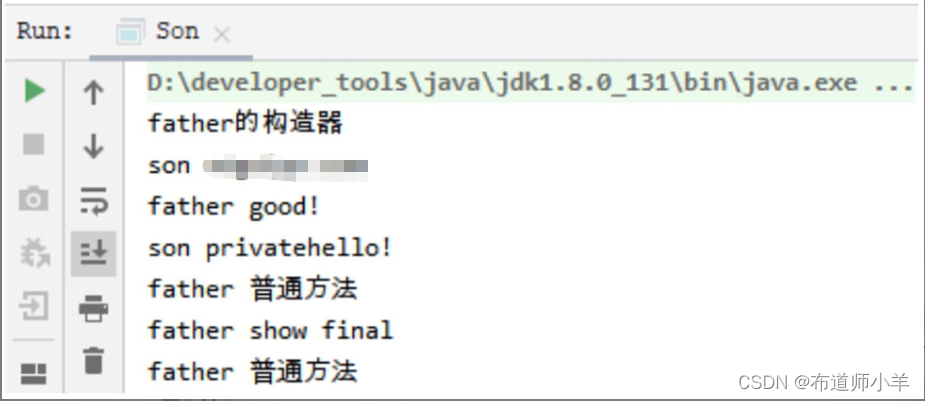
运行结果如下图所示:
7.3、关于invokedynamic指令
JVM字节码指令集一直比较稳定,一直到Java 7中才增加了一个invokedynamic指令,这是Java为了支持“动态类型语言”而做的一种改进。
动态类型语言和静态类型语言的区别就在于对类型的检查是在编译期还是在运行期,满足前者就是静态类型语言,满足后者是动态类型语言。举例如下:
静态类型语言Java:String info =“yyb”;//info = yyb。
动态类型语言JavaScript:var name =“yyb”;var name = 10。
动态类型语言Python:info = 130.5。
在Java语言中,如果定义了info变量,但是不指定数据类型,那么在编译期间会报错,所以Java语言属于静态类型语言。在JavaScript和Python语言中则不需要指定对应的数据类型,在程序运行期间根据变量值去指定类型信息。
但是在Java 7中并没有提供直接生成invokedynamic指令的方法,需要借助ASM这种底层字节码工具来产生invokedynamic指令。直到Java 8的Lambda表达式出现,invokedynamic指令在Java中才有了直接的生成方式。
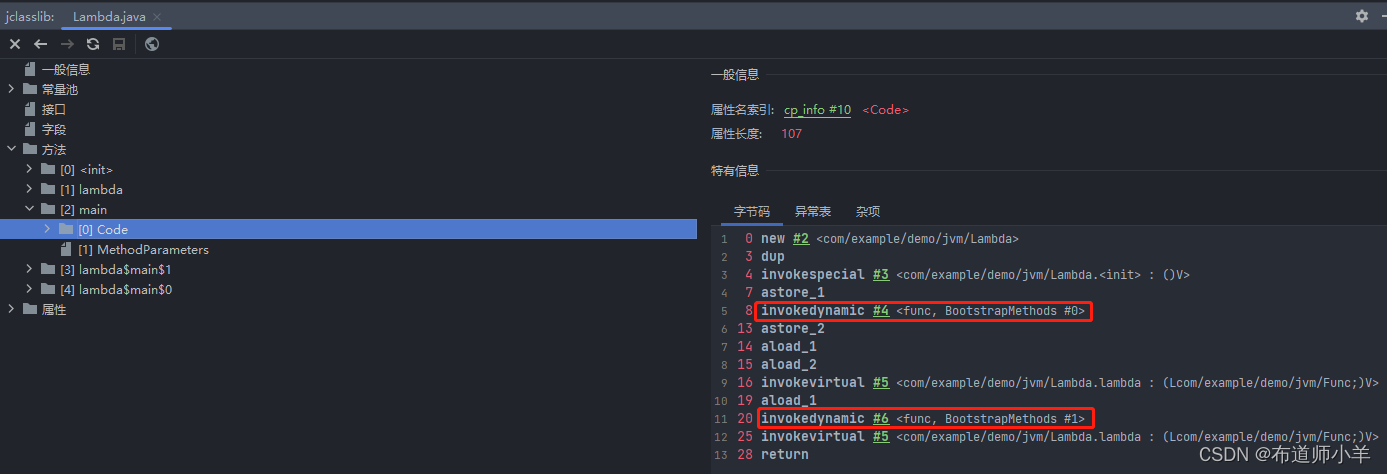
Java 7中增加的动态语言类型支持的本质是对Java虚拟机规范的修改,而不是对Java语言规则的修改。增加新的虚拟机指令,最直接的受益者就是运行在Java平台的动态语言的编译器。通过以下代码清单可以在字节码指令中查看invokedynamic指令:
package com.example.demo.jvm;/*** @title Lamba* @description 体会 invokedynamic* @author: yangyongbing* @date: 2024/3/1 12:51*/@FunctionalInterface
interface Func{public boolean func(String str);
}public class Lambda {public void lambda(Func func){return;}public static void main(String[] args) {Lambda lambda = new Lambda();// invokedynamicFunc func=s->{return true;};lambda.lambda(func);// invokedynamiclambda.lambda(s->{return true;});}
}通过下图可以看出:
7.4、方法重写的本质
虚方法的多态性的前提是建立在方法的重写和类的继承的基础上,Java语言中方法重写的本质如下:
- (1)找到操作数栈顶的第一个元素所指向的对象的实际类型,记作C。
- (2)如果在类型C中找到与常量中的描述符和简单名称都相符的方法,则进行访问权限校验,如果通过则返回这个方法的直接引用,查找过程结束;如果不通过,则返回java.lang.IllegalAccessError异常。IllegalAccessError异常表示程序试图访问或修改一个属性或调用一个方法,但是没有对应的权限。一般来说,IllegalAccessError异常会引起编译器异常。这个错误如果发生在运行时,就说明一个类发生了不兼容的改变。例如,Maven的jar包冲突。
- (3)如果在类型C中找不到与常量中的描述符和简单名称都相符的方法,按照继承关系从下往上依次对C的各个父类进行第2步的搜索和验证过程。
- (4)如果始终没有找到合适的方法,则抛出java.lang.AbstractMethodError异常。
7.5、虚方法表
在面向对象的编程中,会频繁使用动态分派,即在运行期根据实际变量类型确定方法执行版本。方法执行版本的选择需要在类的方法元数据中搜索合适的目标方法,所以频繁地搜索会影响JVM的性能。因此JVM通过在类的方法区建立一个虚方法表(Virtual Method Table)来提高性能,使用虚方法表索引表来代替查找。
每个类中都有一个虚方法表,表中存放着各个方法的实际入口。那么虚方法表什么时候被创建?虚方法表会在类加载的链接阶段被创建并开始初始化,类的变量初始值准备完成之后,JVM会把该类的虚方法表也初始化完毕。
如下图所示:
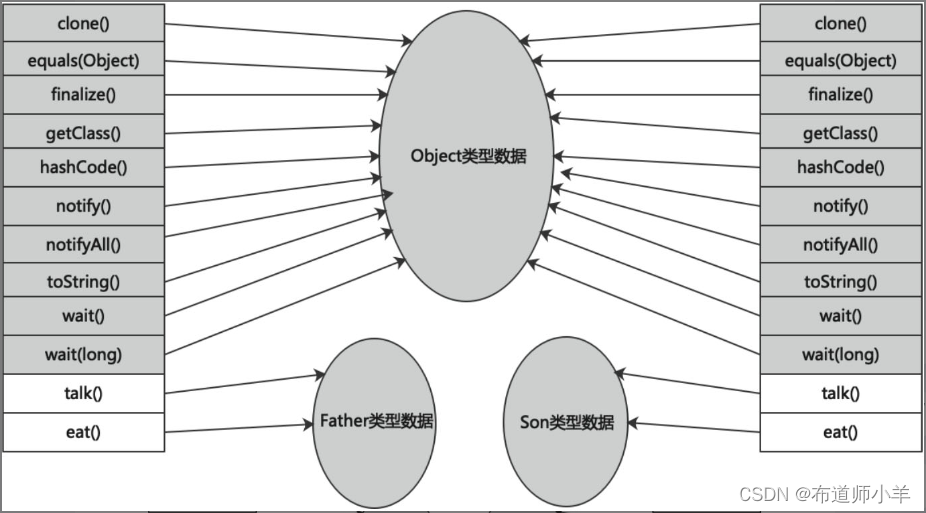
Son类继承于Father类,Father类包含talk()和eat()两个方法,Son类重写了Father类的talk()方法和eat()方法。当在Son类调用toString()等方法时直接找到Object类,不用再经过Father类,虚方法表的作用就是可以直接调用Object类中的方法,从而提高效率。
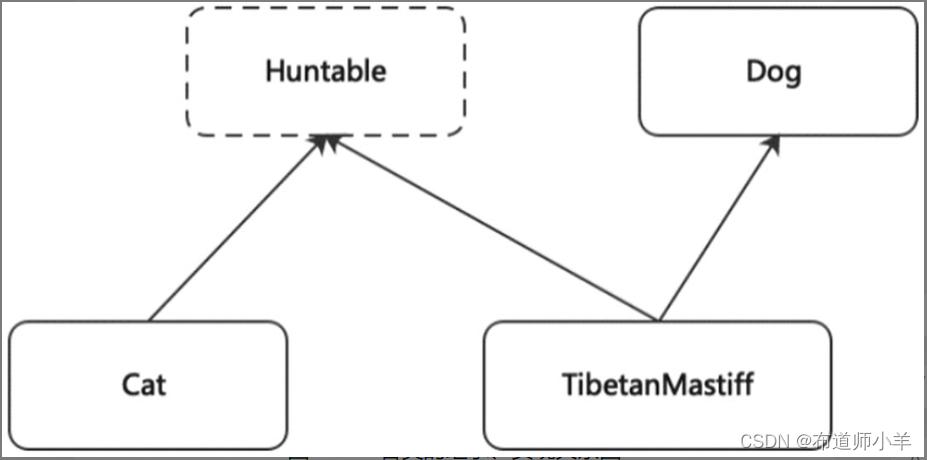
如下代码清单所示,查看不同类的虚方法表:

Cat类实现了Huntable接口,TibetanMastiff(藏獒)类继承了Dog类并实现了Huntable接口,如下图所示:
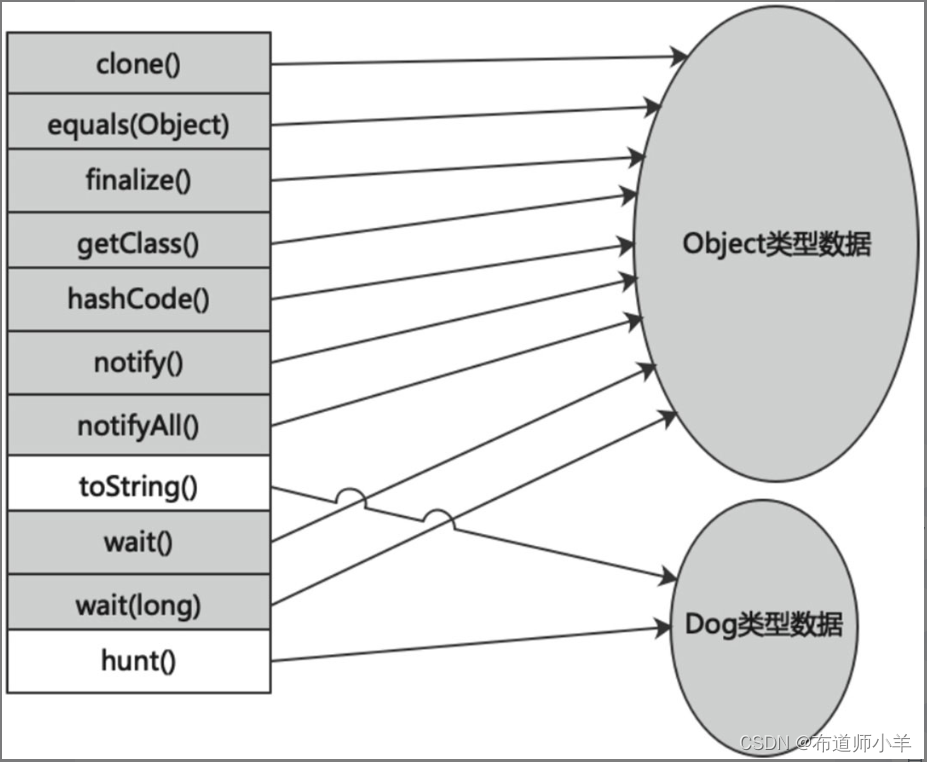
- Dog类虚方法表:Dog类声明了hunt()方法、重写了toString()方法,没有重写的方法指向Object类。当Dog类对象调用toString()方法、hunt()方法时调用自己本身的方法,除此之外,Dog类对象调用equals()、finalize()等方法时,则是直接调用Object类中的方法,如下图所示:
- TibetanMastiff类虚方法表:TibetanMastiff类调用hunt()方法直接调用自己的,TibetanMastiff类没有重写toString()方法,所以调用的是父类Dog类的toString()方法,其他方法直接调用Object类的,如下图所示:
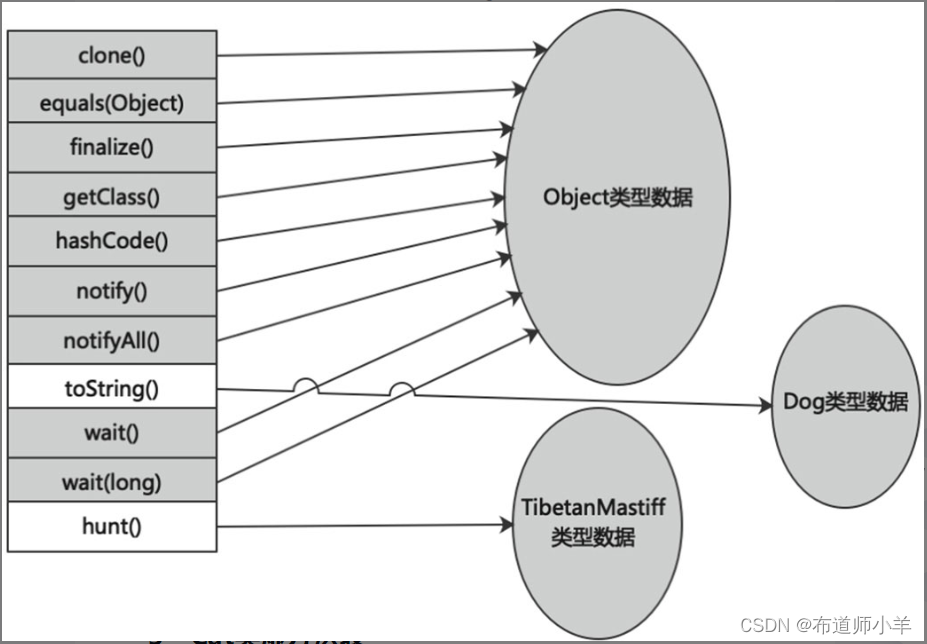
- Cat类虚方法表:Cat类重写了finalize()方法、toString()方法,当调用finalize()、toString()、eat()、hunt()方法时直接调用自己的,调用其他方法时直接调用Object类的,如下图所示:
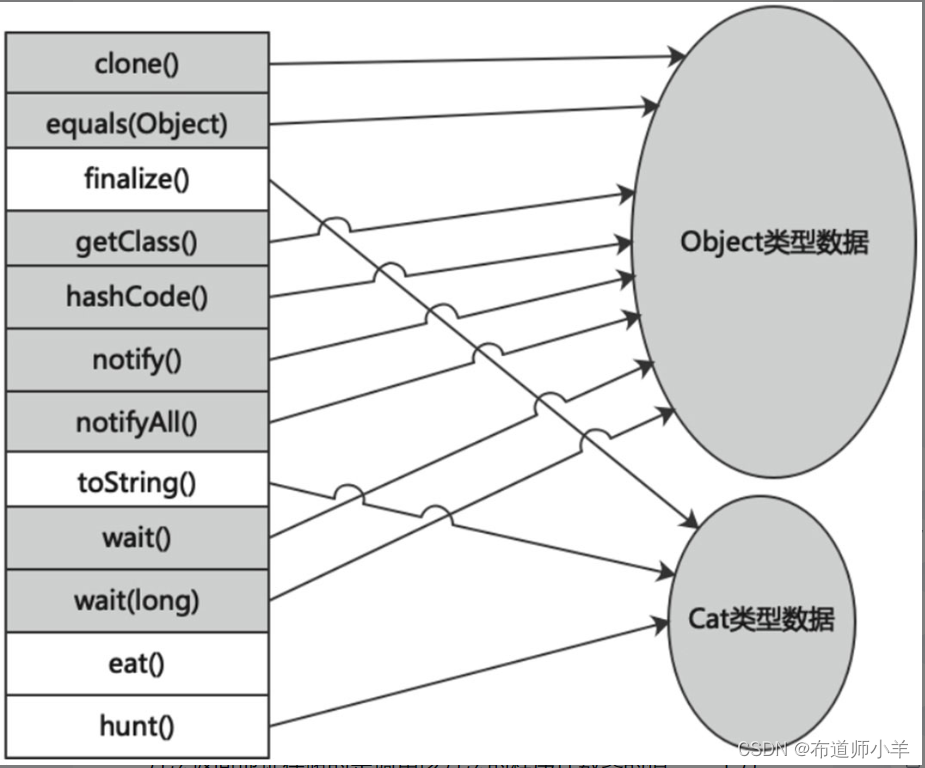
8、方法返回地址
方法返回地址存储的是调用该方法的程序计数器的值。一个方法的结束有两种可能,分别是正常执行完成结束和出现异常导致非正常结束。
无论通过哪种方式退出,在方法退出后都返回到该方法被调用的位置。方法正常退出时,调用者的程序计数器的值作为返回地址,即调用该方法的指令的下一条指令的地址。而通过异常退出的,返回地址是要通过异常表来确定,栈帧中一般不会保存这部分信息。
8.1、方法正常完成退出
执行引擎遇到任意一个方法返回的字节码指令(return),会有返回值传递给上层的方法调用者,简称正常完成出口。一个方法在正常调用完成之后,究竟需要使用哪一个返回指令,还需要根据方法返回值的实际数据类型而定。
在字节码指令中,返回指令包含ireturn(当返回值是boolean、byte、char、short和int类型时使用)、lreturn(当返回值是long类型时使用)、freturn(当返回值是float类型时使用)、dreturn(当返回值是double类型时使用)以及areturn(当返回值是引用类型时使用),另外还有一个return指令供声明为void的方法、实例初始化方法、类和接口的初始化方法使用。
如下代码清单所示,演示了方法返回指令:


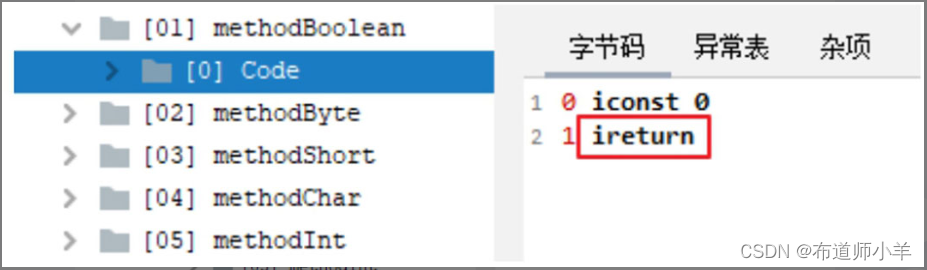
当返回值为boolean、byte、short、char、int类型时,字节码中返回指令为ireturn,如下图所示:
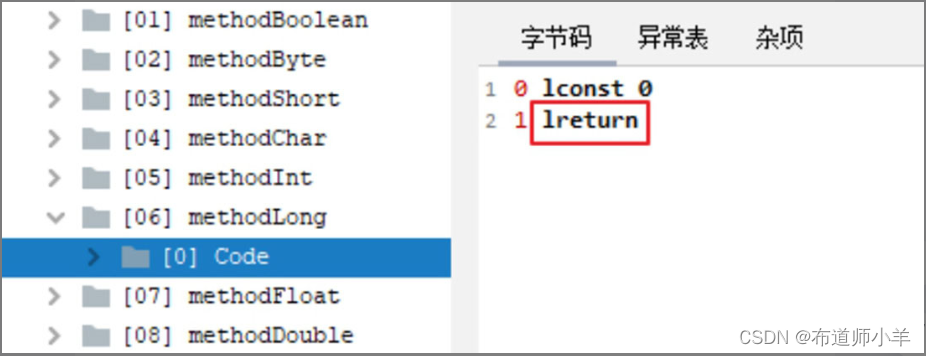
当返回值为long类型时,字节码中返回指令为lreturn,如下图所示:
当返回值为float类型时,字节码中返回指令为freturn,如下图所示:
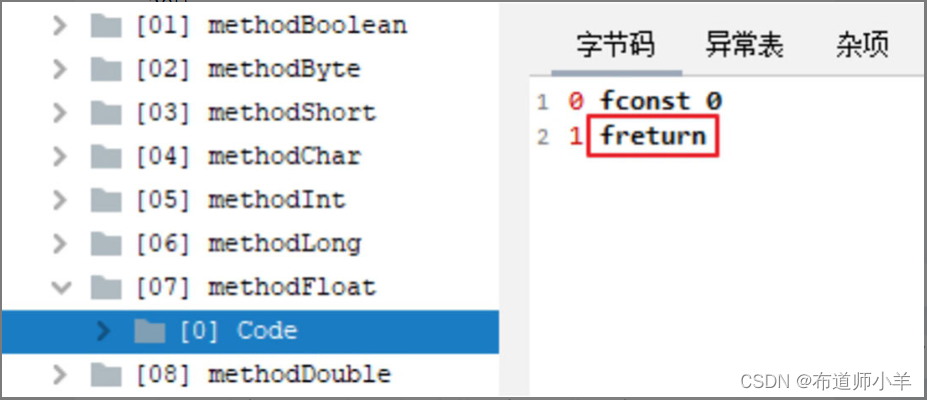
当返回值为double类型时,字节码中返回指令为dreturn,如下图所示:
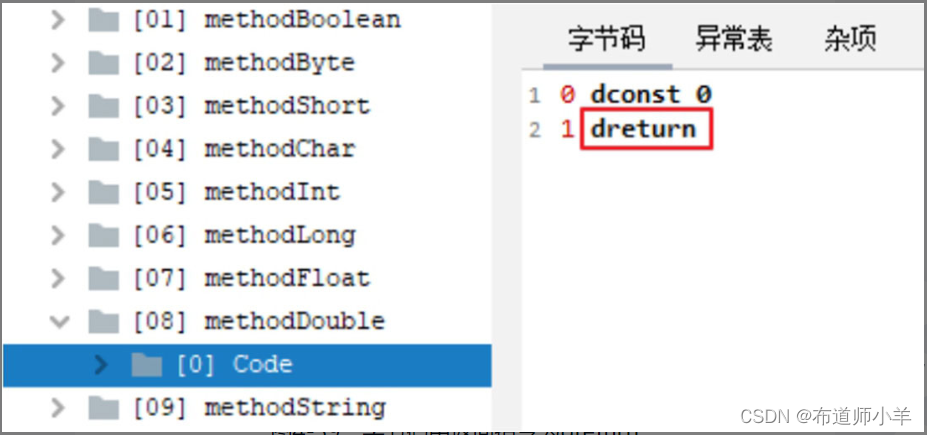
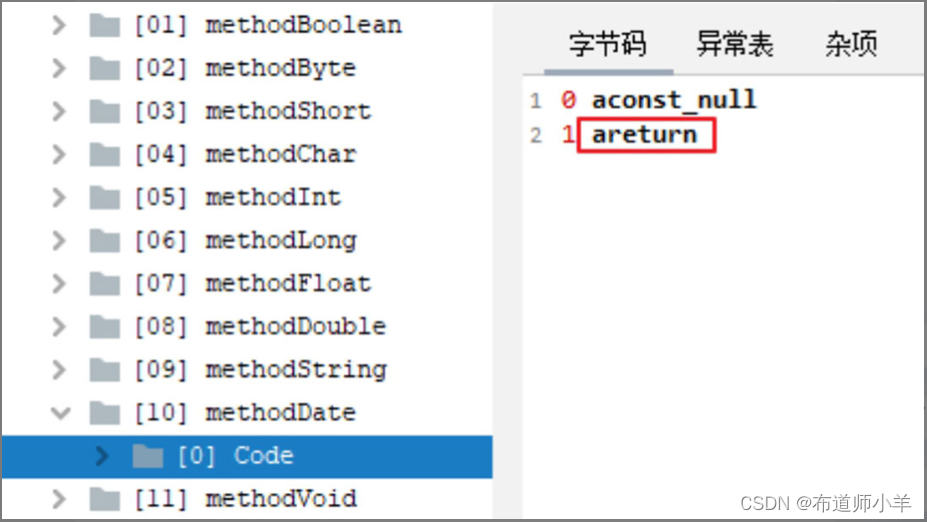
当返回值为引用类型时,字节码中返回指令为areturn,如下图所示:
当返回值为void或代码块或构造方法时,字节码中返回指令为return,如下图所示:

8.2、方法执行异常退出
在方法执行的过程中遇到了异常(Exception),并且这个异常没有在方法内进行处理(没有使用try-catch语句或者try-finally语句处理异常),也就是只要在本方法的异常表中没有搜索到匹配的异常处理器,就会导致方法退出,简称异常完成出口。
如果方法执行过程中抛出异常时,使用try-catch语句或者try-finally语句处理异常,异常处理会存储在一个异常表中,如下表所示:
 方便在发生异常的时候快速找到处理异常的代码。
方便在发生异常的时候快速找到处理异常的代码。
本质上,方法的退出就是当前栈帧出栈的过程。此时,需要恢复上层方法的局部变量表、操作数栈、将返回值压入调用者栈帧的操作数栈、设置程序计数器值等,让调用者的方法继续执行下去。
正常完成出口和异常完成出口的区别在于,通过异常完成出口退出的方法不会给上层调用者产生任何的返回值。








![代码随想录算法训练营第三十二天 | 122.买卖股票的最佳时机 II,55. 跳跃游戏, 45.跳跃游戏 II[贪心算法篇]](https://img-blog.csdnimg.cn/direct/9545038056fb415f8560577fc80e05d7.png)