文章目录
- 1. 本周计划
- 2. 完成情况
- 2.1 DCGANS网络架构
- 2.2 SRGAN网络架构
- 3. 总结及收获
- 4.下周计划
1. 本周计划
学习网络架构DCGANS和SRGAN
2. 完成情况
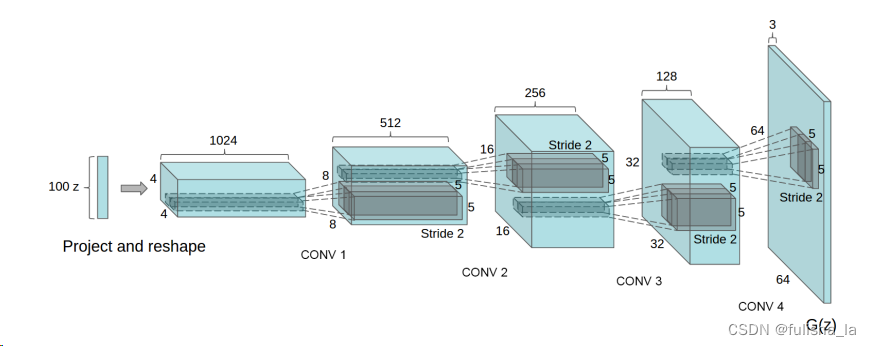
2.1 DCGANS网络架构
模型的核心:(论文链接)
- 取消池化层,使用带步长(stride)的卷积层来缩小图像。在生产器中,在提取特征的同时进行下采样;在鉴别器中,在提取特征的同时进行向上采样
- 去除全连接层,引入全局平均池化,全局平均池化提高了模型稳定性,但损害了收敛速度。将最高卷积特征分别直接连接到生成器和鉴别器的输入和输出效果会很好。 GAN的第一层以均匀噪声分布Z作为输入,可以称为全连接,因为它只是一个矩阵乘法,但结果被重新整形为4维张量并用作卷积堆栈的开始。对于鉴别器,最后一个卷积层被展平,然后输入单个 sigmoid 输出。
- 批量标准化:将每个单元的输入标准化为均值和单位方差为零来稳定学习。这有助于处理由于初始化不良而出现的训练问题,并有助于梯度在更深的模型中流动。直接将批归一化应用于所有层会导致样本振荡和模型不稳定。通过不对生成器输出层和鉴别器输入层应用批归一化可以避免这种情况
生成器最后一层激活函数使用tanh(用有界激活可以让模型更快地学习饱和并覆盖训练分布的颜色空间),其余都使用relu激活函数(可用于更高分辨率的建模);鉴别器使用LeakyReLU激活函数,最后一层使用Sigmoid
- 生成器代码
class Generator(nn.Module):def __init__(self, nz=100, ngf=64, nc=3):super(Generator, self).__init__()self.ngf = ngf # 生成器特征图通道数量单位self.nz = nz # z维度self.nc = nc # 图片的通道self.main = nn.Sequential(# 输入噪声向量Z,(ngf*8) x 4 x 4特征图nn.ConvTranspose2d( nz, ngf * 8, 4, 1, 0, bias=False),nn.BatchNorm2d(ngf * 8),nn.ReLU(True),# 输入(ngf*8) x 4 x 4特征图,输出(ngf*4) x 8 x 8nn.ConvTranspose2d(ngf * 8, ngf * 4, 4, 2, 1, bias=False),nn.BatchNorm2d(ngf * 4),nn.ReLU(True),# 输入(ngf*4) x 8 x 8,输出(ngf*2) x 16 x 16nn.ConvTranspose2d( ngf * 4, ngf * 2, 4, 2, 1, bias=False),nn.BatchNorm2d(ngf * 2),nn.ReLU(True),# 输入(ngf*2) x 16 x 16,输出(ngf) x 32 x 32nn.ConvTranspose2d( ngf * 2, ngf, 4, 2, 1, bias=False),nn.BatchNorm2d(ngf),nn.ReLU(True),# 输入(ngf) x 32 x 32,输出(nc) x 64 x 64nn.ConvTranspose2d( ngf, nc, 4, 2, 1, bias=False),nn.Tanh())def forward(self, input):return self.main(input)
- 判别器代码
class Discriminator(nn.Module):def __init__(self, ndf=64, nc=3):super(Discriminator, self).__init__()self.ndf = ndf # 判别器特征图通道数量单位self.nc = nc # 图片的通道数self.main = nn.Sequential(# 输入图片大小 (nc) x 64 x 64,输出 (ndf) x 32 x 32nn.Conv2d(nc, ndf, 4, 2, 1, bias=False),nn.LeakyReLU(0.2, inplace=True),# 输入(ndf) x 32 x 32,输出(ndf*2) x 16 x 16nn.Conv2d(ndf, ndf * 2, 4, 2, 1, bias=False),nn.BatchNorm2d(ndf * 2),nn.LeakyReLU(0.2, inplace=True),# 输入(ndf*2) x 16 x 16,输出 (ndf*4) x 8 x 8nn.Conv2d(ndf * 2, ndf * 4, 4, 2, 1, bias=False),nn.BatchNorm2d(ndf * 4),nn.LeakyReLU(0.2, inplace=True),# 输入(ndf*4) x 8 x 8,输出(ndf*8) x 4 x 4nn.Conv2d(ndf * 4, ndf * 8, 4, 2, 1, bias=False),nn.BatchNorm2d(ndf * 8),nn.LeakyReLU(0.2, inplace=True),# 输入(ndf*8) x 4 x 4,输出1 x 1 x 1nn.Conv2d(ndf * 8, 1, 4, 1, 0, bias=False),nn.Sigmoid())def forward(self, input):return self.main(input)
- 模型训练
生成器尽可能将生成真的图片来迷惑判别器。
import argparse
import os
import random
import torch
import torch.nn as nn
import torch.nn.parallel
import torch.backends.cudnn as cudnn
import torch.optim as optim
import torch.utils.data
import torchvision.datasets as dset
import torchvision.transforms as transforms
import torchvision.utils as vutils
import numpy as np
import matplotlib.pyplot as plt
import matplotlib.animation as animation
from net import Generator
from net import Discriminator
import os, sys
import shutil
import os
os.environ["KMP_DUPLICATE_LIB_OK"]="TRUE"from tensorboardX import SummaryWriter
writer = SummaryWriter('logs') ## 创建一个SummaryWriter的示例,默认目录名字为runsif os.path.exists("out"):print("删除 out 文件夹!")if sys.platform.startswith("win"):shutil.rmtree("./out")else:os.system("rm -r ./out") print("创建 out 文件夹!")
os.mkdir("./out")# 设置一个随机种子,方便进行可重复性实验
manualSeed = 999
print("Random Seed: ", manualSeed)
random.seed(manualSeed)
torch.manual_seed(manualSeed)## 基本参数配置
# 数据集所在路径
dataroot = "E:\pythonCode\DCGGAN\dataset\mouth"
# 数据加载的进程数
workers = 0
# Batch size 大小
batch_size = 64
# 图片大小
image_size = 64
# 图片的通道数
nc = 3
# 噪声向量维度
nz = 100
# 生成器特征图通道数量单位
ngf = 64
# 判别器特征图通道数量单位
ndf = 64# 损失函数
criterion = nn.BCELoss()
# 真假标签
real_label = 1.0
fake_label = 0.0
# 是否使用GPU训练
ngpu = 1
device = torch.device("cuda:0" if (torch.cuda.is_available() and ngpu > 0) else "cpu")
# 创建生成器与判别器
netG = Generator().to(device)
netD = Discriminator().to(device)
# G和D的优化器,使用Adam
# Adam学习率与动量参数
lr = 0.0003
beta1 = 0.5
optimizerD = optim.Adam(netD.parameters(), lr=lr, betas=(beta1, 0.999))
optimizerG = optim.Adam(netG.parameters(), lr=lr, betas=(beta1, 0.999))# 缓存生成结果
img_list = []
# 损失变量
G_losses = []
D_losses = []# batch变量
iters = 0## 读取数据
dataset = dset.ImageFolder(root=dataroot,transform=transforms.Compose([transforms.Resize(image_size),transforms.CenterCrop(image_size),transforms.ToTensor(),transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)),]))
dataloader = torch.utils.data.DataLoader(dataset, batch_size=batch_size,shuffle=True, num_workers=workers)# 多GPU训练
if (device.type == 'cuda') and (ngpu > 1):netG = nn.DataParallel(netG, list(range(ngpu)))
if (device.type == 'cuda') and (ngpu > 1):netD = nn.DataParallel(netD, list(range(ngpu)))# 总epochs
num_epochs = 500
## 模型缓存接口
if not os.path.exists('models'):os.mkdir('models')
print("Starting Training Loop...")
fixed_noise = torch.randn(64, nz, 1, 1, device=device)for epoch in range(num_epochs):lossG = 0.0lossD = 0.0for i, data in enumerate(dataloader, 0):############################# (1) Update D network: maximize log(D(x)) + log(1 - D(G(z)))############################# 训练真实图片netD.zero_grad()real_data = data[0].to(device)b_size = real_data.size(0)label = torch.full((b_size,), real_label, device=device)output = netD(real_data).view(-1)# 计算真实图片损失,梯度反向传播errD_real = criterion(output, label)errD_real.backward()D_x = output.mean().item()## 训练生成图片# 产生latent vectorsnoise = torch.randn(b_size, nz, 1, 1, device=device)# 使用G生成图片fake = netG(noise)label.fill_(fake_label)output = netD(fake.detach()).view(-1)# 计算生成图片损失,梯度反向传播errD_fake = criterion(output, label)errD_fake.backward()D_G_z1 = output.mean().item()# 累加误差,参数更新errD = errD_real + errD_fakeoptimizerD.step()############################# (2) Update G network: maximize log(D(G(z)))###########################netG.zero_grad()label.fill_(real_label) # 给生成图赋标签# 对生成图再进行一次判别output = netD(fake).view(-1)# 计算生成图片损失,梯度反向传播errG = criterion(output, label)errG.backward()D_G_z2 = output.mean().item()optimizerG.step()# 输出训练状态if i % 50 == 0:print('[%d/%d][%d/%d]\tLoss_D: %.4f\tLoss_G: %.4f\tD(x): %.4f\tD(G(z)): %.4f / %.4f'% (epoch, num_epochs, i, len(dataloader),errD.item(), errG.item(), D_x, D_G_z1, D_G_z2))# 存储损失lossG = lossG + errG.item() ## 累加batch损失lossD = lossD + errD.item() ## 累加batch损失# 对固定的噪声向量,存储生成的结果if (iters % 20 == 0) or ((epoch == num_epochs-1) and (i == len(dataloader)-1)):with torch.no_grad():fake = netG(fixed_noise).detach().cpu()img_list.append(vutils.make_grid(fake, padding=2, normalize=True))i = vutils.make_grid(fake, padding=2, normalize=True)fig = plt.figure(figsize=(8, 8))plt.imshow(np.transpose(i, (1, 2, 0)))plt.axis('off') # 关闭坐标轴plt.savefig("out/%d_%d.png" % (epoch, iters))plt.close(fig)iters += 1 ## nbatch+1writer.add_scalar('data/lossG', lossG, epoch)writer.add_scalar('data/lossD', lossD, epoch)torch.save(netG,'models/netG.pth')
torch.save(netD,'models/netD.pth')
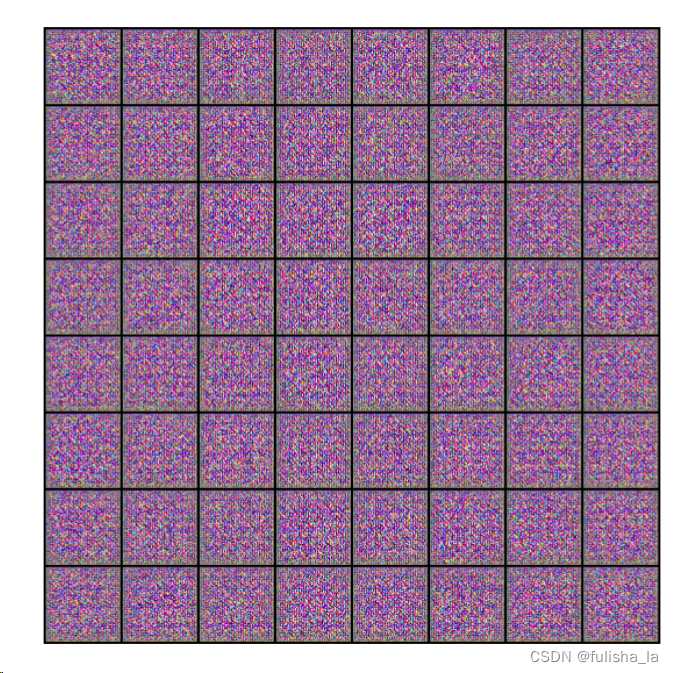
在开始的时候输入的固定噪声,生成器最开始生成的图像
进行了100次训练,最后生成器生成的图像(已经越来越那么回事了)

在这里改了一下优化器,原用的优化器为Adam,改为AdamW后,也是进行100次训练,发现第100次的输出精度有所变化。

2.2 SRGAN网络架构
网络架构
- 生成器
生成器的目标是将低分辨率的输入图像变换为高分辨率图像
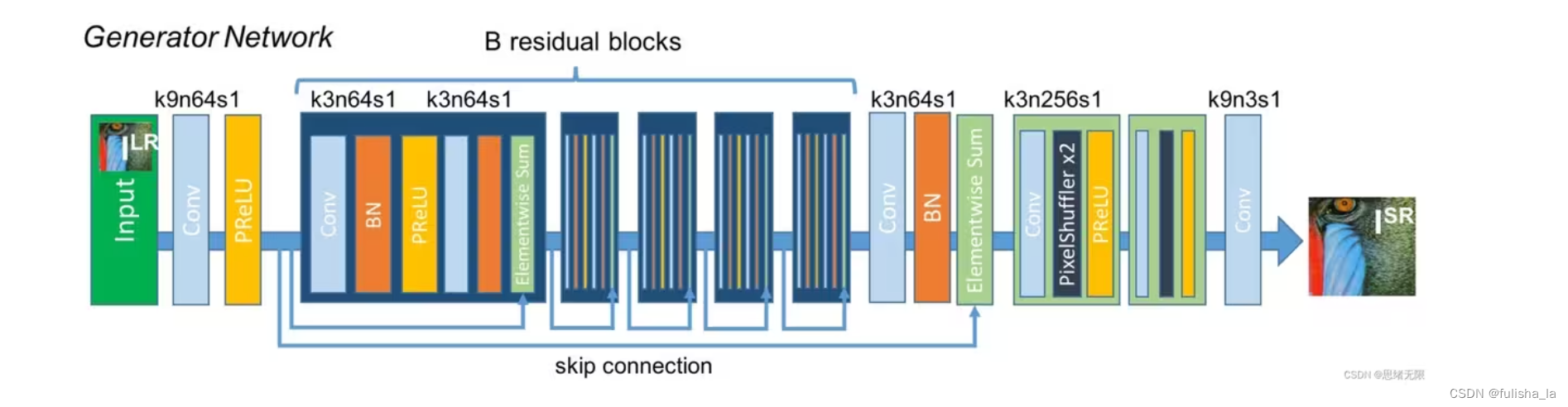
Elementwise Sum就是残差中相加的操作; PixelShuffle(像素重组): 像素级卷积层
class Generator(nn.Module):def __init__(self, scale_factor): # 上采样因子upsample_block_num = int(math.log(scale_factor, 2)) #上采样数量super(Generator, self).__init__()self.block1 = nn.Sequential(nn.Conv2d(3, 64, kernel_size=9, padding=4),nn.PReLU())# 五个残差块 不改变通道数和分辨率self.block2 = ResidualBlock(64)self.block3 = ResidualBlock(64)self.block4 = ResidualBlock(64)self.block5 = ResidualBlock(64)self.block6 = ResidualBlock(64)#卷积self.block7 = nn.Sequential(nn.Conv2d(64, 64, kernel_size=3, padding=1),nn.BatchNorm2d(64))block8 = [UpsampleBLock(64, 2) for _ in range(upsample_block_num)] #上采样模块 提升分辨率block8.append(nn.Conv2d(64, 3, kernel_size=9, padding=4))self.block8 = nn.Sequential(*block8)def forward(self, x):block1 = self.block1(x)block2 = self.block2(block1)block3 = self.block3(block2)block4 = self.block4(block3)block5 = self.block5(block4)block6 = self.block6(block5)block7 = self.block7(block6)block8 = self.block8(block1 + block7)return (torch.tanh(block8) + 1) / 2class ResidualBlock(nn.Module):def __init__(self, channels):super(ResidualBlock, self).__init__()self.conv1 = nn.Conv2d(channels, channels, kernel_size=3, padding=1)self.bn1 = nn.BatchNorm2d(channels)self.prelu = nn.PReLU()self.conv2 = nn.Conv2d(channels, channels, kernel_size=3, padding=1)self.bn2 = nn.BatchNorm2d(channels)def forward(self, x):residual = self.conv1(x)residual = self.bn1(residual)residual = self.prelu(residual)residual = self.conv2(residual)residual = self.bn2(residual)return x + residualclass UpsampleBLock(nn.Module):def __init__(self, in_channels, up_scale):super(UpsampleBLock, self).__init__()self.conv = nn.Conv2d(in_channels, in_channels * up_scale ** 2, kernel_size=3, padding=1)self.pixel_shuffle = nn.PixelShuffle(up_scale)self.prelu = nn.PReLU()def forward(self, x):x = self.conv(x)x = self.pixel_shuffle(x)x = self.prelu(x)return x补充知识:
- 残差网络
残差网络的特点是容易优化,并且能够通过增加相当的深度来提高准确率。其内部的残差块使用了跳跃连接,缓解了在深度神经网络中增加深度带来的梯度消失问题,
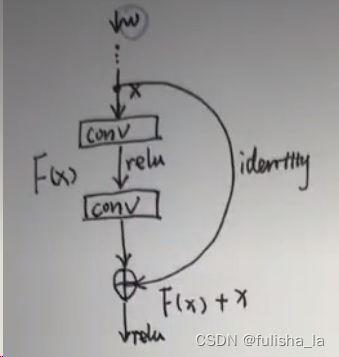
可以对这个公式做一个推导: y = F ( x ) + x y = F(x) + x y=F(x)+x对参数w求梯度
∂ y ∂ w = ∂ y ∂ F ( x ) ∂ F ( x ) ∂ x ∂ x ∂ w + ∂ y ∂ x ∂ x ∂ w = ∂ F ( x ) ∂ x ∂ x ∂ w + ∂ x ∂ w \frac{\partial y}{\partial w}=\frac{\partial y}{\partial F(x)}\frac{\partial F(x)}{\partial x}\frac{\partial x}{\partial w} + \frac{\partial y}{\partial x}\frac{\partial x}{\partial w}=\frac{\partial F(x)}{\partial x}\frac{\partial x}{\partial w} + \frac{\partial x}{\partial w} ∂w∂y=∂F(x)∂y∂x∂F(x)∂w∂x+∂x∂y∂w∂x=∂x∂F(x)∂w∂x+∂w∂x
若不加x,则就少了$ \frac{\partial x}{\partial w}$,而通过比较,上面式子更不容易出现梯度消失问题
∂ y ∂ w = ∂ y ∂ F ( x ) ∂ F ( x ) ∂ x ∂ x ∂ w = ∂ F ( x ) ∂ x ∂ x ∂ w \frac{\partial y}{\partial w}=\frac{\partial y}{\partial F(x)}\frac{\partial F(x)}{\partial x}\frac{\partial x}{\partial w} =\frac{\partial F(x)}{\partial x}\frac{\partial x}{\partial w} ∂w∂y=∂F(x)∂y∂x∂F(x)∂w∂x=∂x∂F(x)∂w∂x
2. 基于亚像素级的上采样
亚像素:亚像素,也称为子像素,是指在数字图像处理中,像素之间的细分情况。
亚像素卷积是一种特殊类型的卷积,旨在提高图像处理的精度。一个正常的反卷积操作可以将一个3x3的小图片变成一个5x5的大图片,(主要采用0填充),但在亚像素卷积中,这些白色填0的区域被去除,因为它们被认为是无效信息,甚至可能对求梯度优化有害。亚像素卷积通过直接从原图获取信息,避免了这些无效的操作
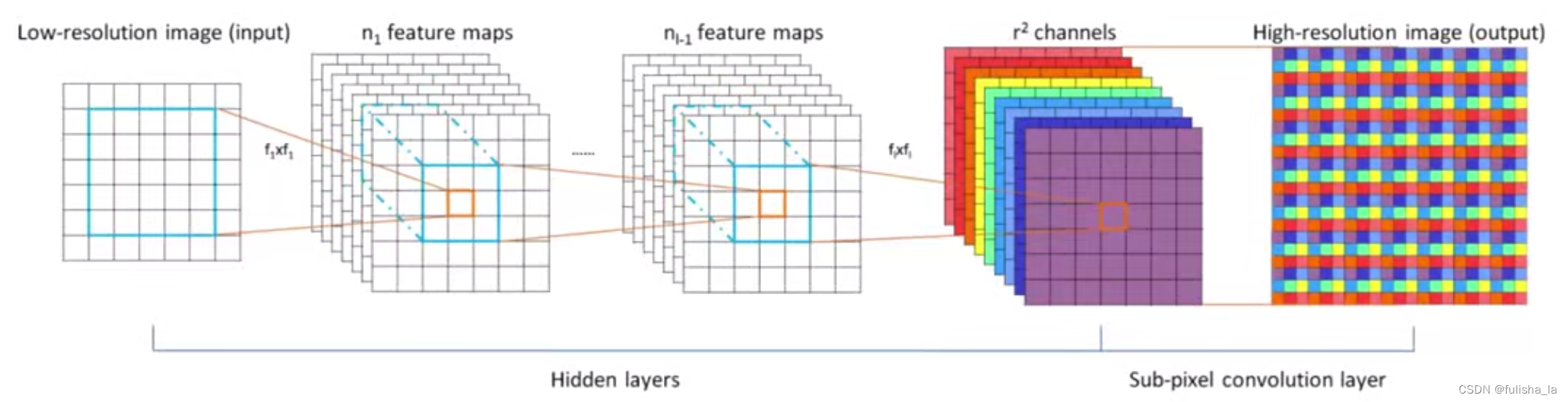 输入 C ∗ H ∗ W C*H*W C∗H∗W, 那经过亚像素卷积层后,输出特征图为 ( C ∗ r 2 ) H ∗ W ∗ (C*r^2)H*W* (C∗r2)H∗W∗, 特图与输入图的尺寸保持一致,但是通道数被扩充为原来的 r 2 r^2 r2倍,通过重新排列得到高分辨率结果。
输入 C ∗ H ∗ W C*H*W C∗H∗W, 那经过亚像素卷积层后,输出特征图为 ( C ∗ r 2 ) H ∗ W ∗ (C*r^2)H*W* (C∗r2)H∗W∗, 特图与输入图的尺寸保持一致,但是通道数被扩充为原来的 r 2 r^2 r2倍,通过重新排列得到高分辨率结果。
class UpsampleBLock(nn.Module):def __init__(self, in_channels, up_scale):super(UpsampleBLock, self).__init__()self.conv = nn.Conv2d(in_channels, in_channels * up_scale ** 2, kernel_size=3, padding=1)self.pixel_shuffle = nn.PixelShuffle(up_scale)self.prelu = nn.PReLU()def forward(self, x):x = self.conv(x)x = self.pixel_shuffle(x)x = self.prelu(x)return x调用PixelShuffle(像素重组)函数,输入: ( ∗ , C i n , H i n , W i n ) (*, C_{in}, H_{in}, W_{in}) (∗,Cin,Hin,Win); 输出: ( ∗ , C o u t , H o u t , W o u t ) (*, C_{out}, H_{out}, W_{out}) (∗,Cout,Hout,Wout)
H o u t = H i n × upscale_factor H_{out} = H_{in} \times \text{upscale\_factor} Hout=Hin×upscale_factor
W o u t = W i n × upscale_factor W_{out} = W_{in} \times \text{upscale\_factor} Wout=Win×upscale_factor
C o u t = C i n ÷ upscale_factor 2 C_{out} = C_{in} \div \text{upscale\_factor}^2 Cout=Cin÷upscale_factor2
pixel_shuffle = nn.PixelShuffle(3) # 3为上采样因子input = torch.randn(1, 9, 4, 4)output = pixel_shuffle(input)print(output.size())torch.Size([1, 1, 12, 12])
- 判别器
一个卷积神经网络,目标是区分生成的图像是否是来自高分辨率图像
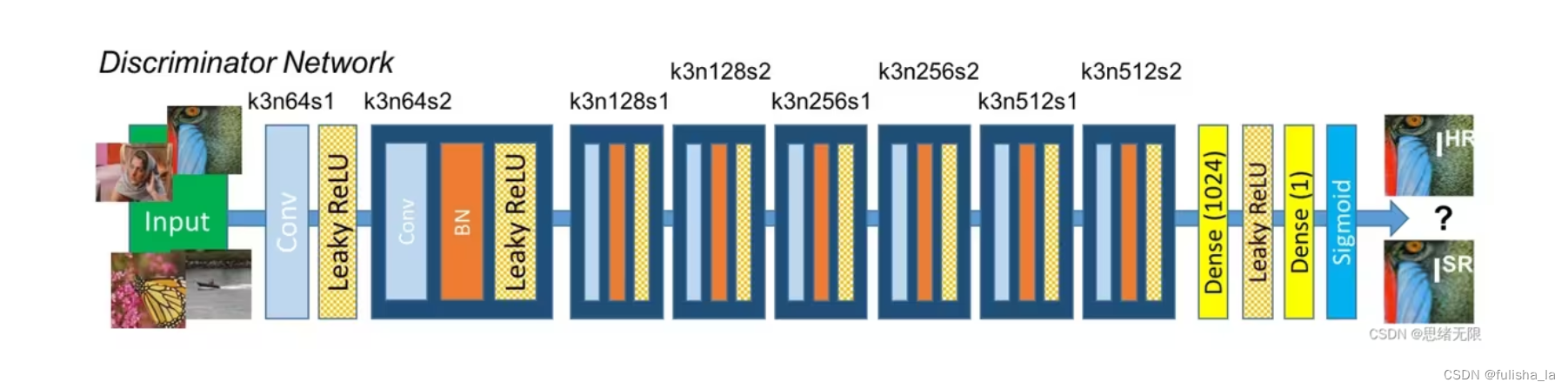
class Discriminator(nn.Module):def __init__(self):super(Discriminator, self).__init__()self.net = nn.Sequential(nn.Conv2d(3, 64, kernel_size=3, padding=1),nn.LeakyReLU(0.2),nn.Conv2d(64, 64, kernel_size=3, stride=2, padding=1),nn.BatchNorm2d(64),nn.LeakyReLU(0.2),nn.Conv2d(64, 128, kernel_size=3, padding=1),nn.BatchNorm2d(128),nn.LeakyReLU(0.2),nn.Conv2d(128, 128, kernel_size=3, stride=2, padding=1),nn.BatchNorm2d(128),nn.LeakyReLU(0.2),nn.Conv2d(128, 256, kernel_size=3, padding=1),nn.BatchNorm2d(256),nn.LeakyReLU(0.2),nn.Conv2d(256, 256, kernel_size=3, stride=2, padding=1),nn.BatchNorm2d(256),nn.LeakyReLU(0.2),nn.Conv2d(256, 512, kernel_size=3, padding=1),nn.BatchNorm2d(512),nn.LeakyReLU(0.2),nn.Conv2d(512, 512, kernel_size=3, stride=2, padding=1),nn.BatchNorm2d(512),nn.LeakyReLU(0.2),nn.AdaptiveAvgPool2d(1),nn.Conv2d(512, 1024, kernel_size=1),nn.LeakyReLU(0.2),nn.Conv2d(1024, 1, kernel_size=1))def forward(self, x):batch_size = x.size(0)return torch.sigmoid(self.net(x).view(batch_size))
- 损失函数
生成器的损失函数
class GeneratorLoss(nn.Module):def __init__(self):super(GeneratorLoss, self).__init__()vgg = vgg16(pretrained=True) # 感知损失计算loss_network = nn.Sequential(*list(vgg.features)[:31]).eval()for param in loss_network.parameters():param.requires_grad = Falseself.loss_network = loss_networkself.mse_loss = nn.MSELoss()self.tv_loss = TVLoss()def forward(self, out_labels, out_images, target_images):# Adversarial Lossadversarial_loss = torch.mean(1 - out_labels)# Perception Lossperception_loss = self.mse_loss(self.loss_network(out_images), self.loss_network(target_images))# Image Lossimage_loss = self.mse_loss(out_images, target_images)# TV Loss 平滑损失tv_loss = self.tv_loss(out_images)return image_loss + 0.001 * adversarial_loss + 0.006 * perception_loss + 2e-8 * tv_loss
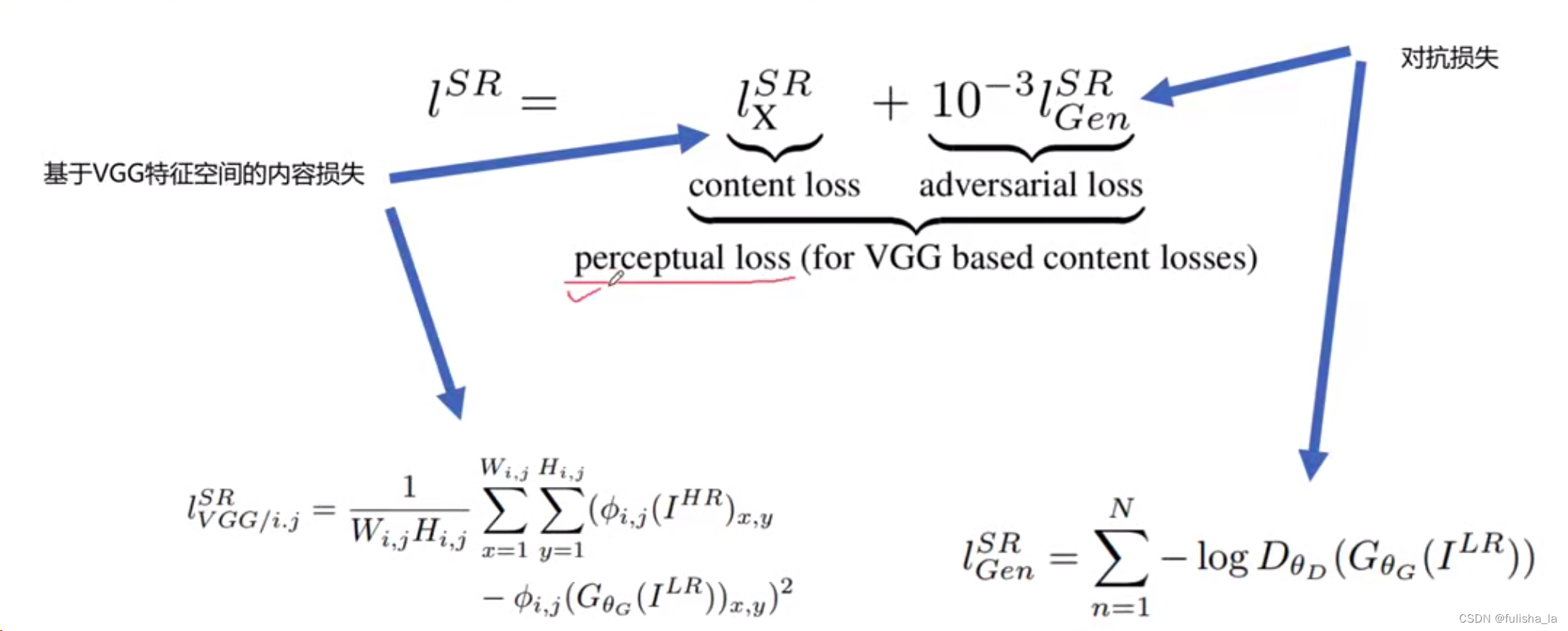 1) I H R I^{HR} IHR代表高分辨率 I L R I^{LR} ILR代表低分辨率图;
1) I H R I^{HR} IHR代表高分辨率 I L R I^{LR} ILR代表低分辨率图;
2)内容损失:基于VGG特空间去计算特征图之间的距离,其中 ϕ i , j ( I H R ) x , y \phi_{i,j}(I^{HR})_{x,y} ϕi,j(IHR)x,y取某一层的特征图
3)对抗损失:生成器生成的图像能够欺骗判别器,所以它的损失函数是判别器判断生成图像为真实图像的概率的负对数。故生成器希望判别器对生成图像的判断越接近于真实图像
- 测试
输入图像

调用训练好的模型后的输出:

3. 总结及收获
学习了基于Gan的两种处理图像的架构,其中DCGANS取消池化层,全连接层,且批量标准化;SRGAN 引入了残差模块,亚像素级卷积,以及损失函数设计,引入了感知损失,采用改进的 VGG 网络作为特征映射,并设计了与判别器匹配的新的感知损失。但是SRGAN后续有许多人在此基础上做了很多改进和创新,后续会继续看一下他们是如何做的改进。我通过这两个网络架构的学习,主要想了解图像增强方面的网络架构,并最后自己能够从中得到启发。
4.下周计划
学习了解图像增强方面网络架构代码