YOLO TT100K: 基于YOLO训练的交通标志检测模型

在原始代码基础上:
- 修改数据加载类,支持CoCo格式(使用cocoapi);
- 修改数据增强;
- validation增加mAP计算;
- 修改anchor;
注: 实验开启weight_decay或是 不对conv层和FC层的bias参数,以及BN层的参数进行权重衰减,mAP下降很大,mAP@[.5:.95]=0.244
训练集
[Tsinghua-Tencent 100K]
下载的训练集主要包含train和test两部分,分别为6107和3073张图片。统计标注文件,共221类。详细统计每类标志个数,发现很多类的数量为0,所以清楚了部分数量为0的label,剩下类别为151,其中仍存在很多类数量<5.
TT100k转为CoCo格式:
- 交通标志类别:
数据集中包含数百种不同类型的交通标志实例,例如停止标志、限速标志、方向指示标志等。截至某个时间点,数据集有超过232种不同的交通标志类别,这意味着每种类别都有一定数量的样本图片用于训练和测试模型。 - i2r类别: 这个类别涉及图像到文本的匹配任务,提供一张图像及五个候选文字描述,目标是确定哪一描述最准确地匹配该图像的内容。
- i2 类别: 这个类别代表图像到图像的匹配,给定两张图像,判断这两张图像是否描述的是同一场景或物体,适用于图像检索和匹配任务。
- Other 类别: 可能包括不属于上述特定任务的其他类型的数据,或者是为了填充和扩充数据集而添加的样本 参考 [yolo-v3脚本]
python scripts/tt100k2coco.py
测试
pretrained model
密码: lcou
下载到model_data,运行:python predict.py
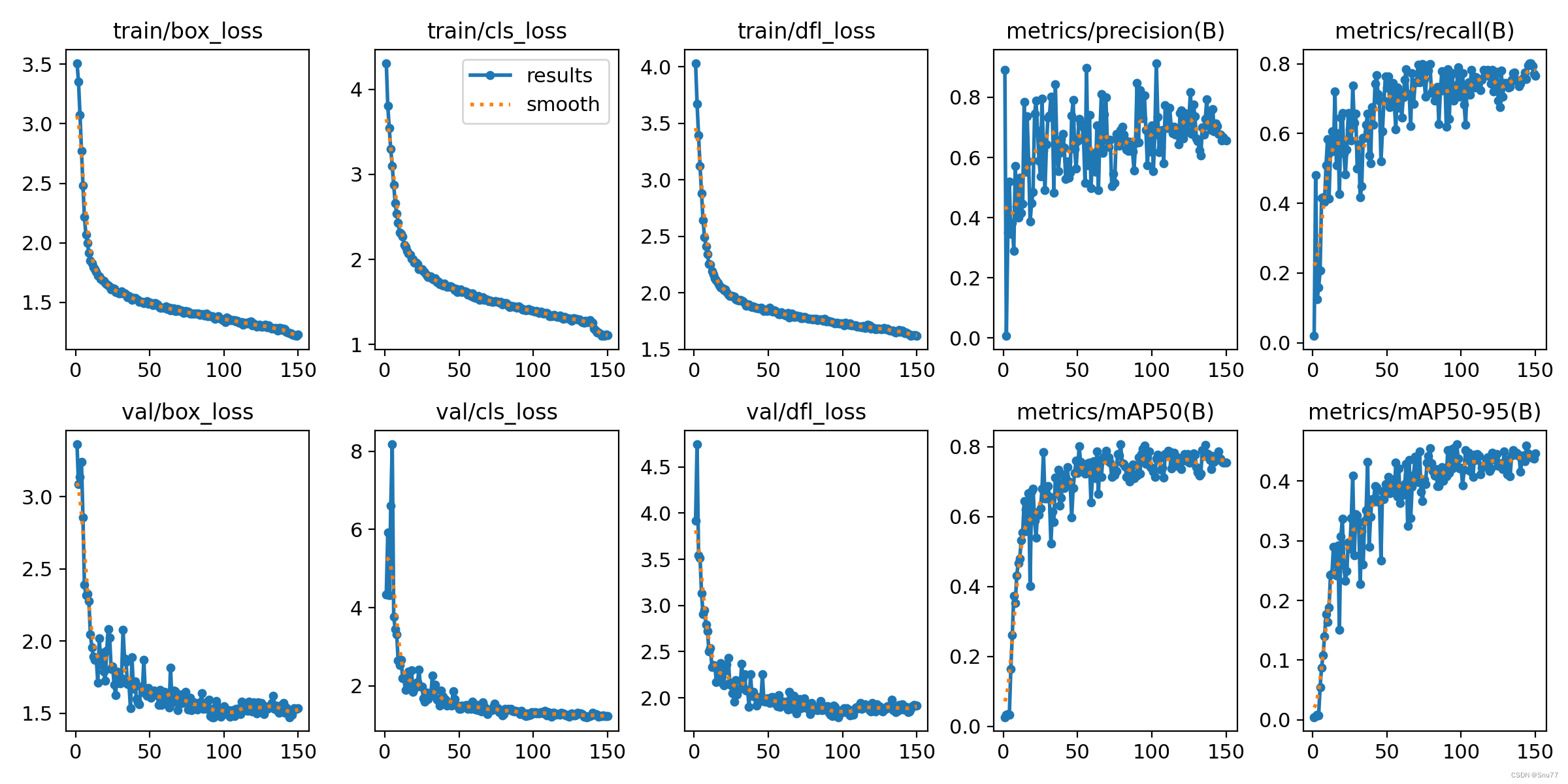
结果

mAP of yolo
对比yolov3:

如上,mAP不高,分析原因,可能如下:
- 数据集分辨率2048x2048,yolov4输入为608,且交通标志中存在很多小物体,原图resize到608,很多目标太小难以检测;
- 某些类别数量过少;
可优化:
- 借鉴YOLT方法检测小物体;
- 数据集扩充/增强;
- 使用更优秀的检测方法;
- 改进loss,解决类别不均衡可参考
主要代码
# ----------------------------------------------------#
# 对视频中的predict.py进行了修改,
# 将单张图片预测、摄像头检测和FPS测试功能
# 整合到了一个py文件中,通过指定mode进行模式的修改。
# ----------------------------------------------------#
import timeimport cv2
import numpy as np
from PIL import Imagefrom yolo import YOLOif __name__ == "__main__":yolo = YOLO()# -------------------------------------------------------------------------## mode用于指定测试的模式:# 'predict'表示单张图片预测# 'video'表示视频检测# 'fps'表示测试fps# -------------------------------------------------------------------------#mode = "predict"# -------------------------------------------------------------------------## video_path用于指定视频的路径,当video_path=0时表示检测摄像头# video_save_path表示视频保存的路径,当video_save_path=""时表示不保存# video_fps用于保存的视频的fps# video_path、video_save_path和video_fps仅在mode='video'时有效# 保存视频时需要ctrl+c退出才会完成完整的保存步骤,不可直接结束程序。# -------------------------------------------------------------------------#video_path = 0video_save_path = ""video_fps = 25.0if mode == "predict":'''1、该代码无法直接进行批量预测,如果想要批量预测,可以利用os.listdir()遍历文件夹,利用Image.open打开图片文件进行预测。具体流程可以参考get_dr_txt.py,在get_dr_txt.py即实现了遍历还实现了目标信息的保存。2、如果想要进行检测完的图片的保存,利用r_image.save("img.jpg")即可保存,直接在predict.py里进行修改即可。 3、如果想要获得预测框的坐标,可以进入yolo.detect_image函数,在绘图部分读取top,left,bottom,right这四个值。4、如果想要利用预测框截取下目标,可以进入yolo.detect_image函数,在绘图部分利用获取到的top,left,bottom,right这四个值在原图上利用矩阵的方式进行截取。5、如果想要在预测图上写额外的字,比如检测到的特定目标的数量,可以进入yolo.detect_image函数,在绘图部分对predicted_class进行判断,比如判断if predicted_class == 'car': 即可判断当前目标是否为车,然后记录数量即可。利用draw.text即可写字。'''while True:img = input('Input image filename:')try:image = Image.open(img)except:print('Open Error! Try again!')continueelse:r_image = yolo.detect_image(image)r_image.save(img.split("/")[-1])r_image.show()elif mode == "video":capture = cv2.VideoCapture(video_path)if video_save_path != "":fourcc = cv2.VideoWriter_fourcc(*'XVID')size = (int(capture.get(cv2.CAP_PROP_FRAME_WIDTH)), int(capture.get(cv2.CAP_PROP_FRAME_HEIGHT)))out = cv2.VideoWriter(video_save_path, fourcc, video_fps, size)fps = 0.0while (True):t1 = time.time()# 读取某一帧ref, frame = capture.read()# 格式转变,BGRtoRGBframe = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)# 转变成Imageframe = Image.fromarray(np.uint8(frame))# 进行检测frame = np.array(yolo.detect_image(frame))# RGBtoBGR满足opencv显示格式frame = cv2.cvtColor(frame, cv2.COLOR_RGB2BGR)fps = (fps + (1. / (time.time() - t1))) / 2print("fps= %.2f" % (fps))frame = cv2.putText(frame, "fps= %.2f" % (fps), (0, 40), cv2.FONT_HERSHEY_SIMPLEX, 1, (0, 255, 0), 2)cv2.imshow("video", frame)c = cv2.waitKey(1) & 0xffif video_save_path != "":out.write(frame)if c == 27:capture.release()breakcapture.release()out.release()cv2.destroyAllWindows()elif mode == "fps":test_interval = 100img = Image.open('img/street.jpg')tact_time = yolo.get_FPS(img, test_interval)print(str(tact_time) + ' seconds, ' + str(1 / tact_time) + 'FPS, @batch_size 1')else:raise AssertionError("Please specify the correct mode: 'predict', 'video' or 'fps'.")