2024年2月16日,OpenAI发布Sora文生视频模型,一石激起千层浪,迅速刷屏爆火于整个AI圈。一方面,Sora从文本、图像迈向视频大模型,这可以说是通向通用人工智能的里程碑事件;另一方面,训练和推理需求从文本、图像又增加一个视频维度,将拉动AI芯片、AI应用雨后春笋般的持续增长。
本文尝试在这里探讨、解读Sora背后的技术。下图是Sora算法脉络图,咱们沿着这张图介绍。
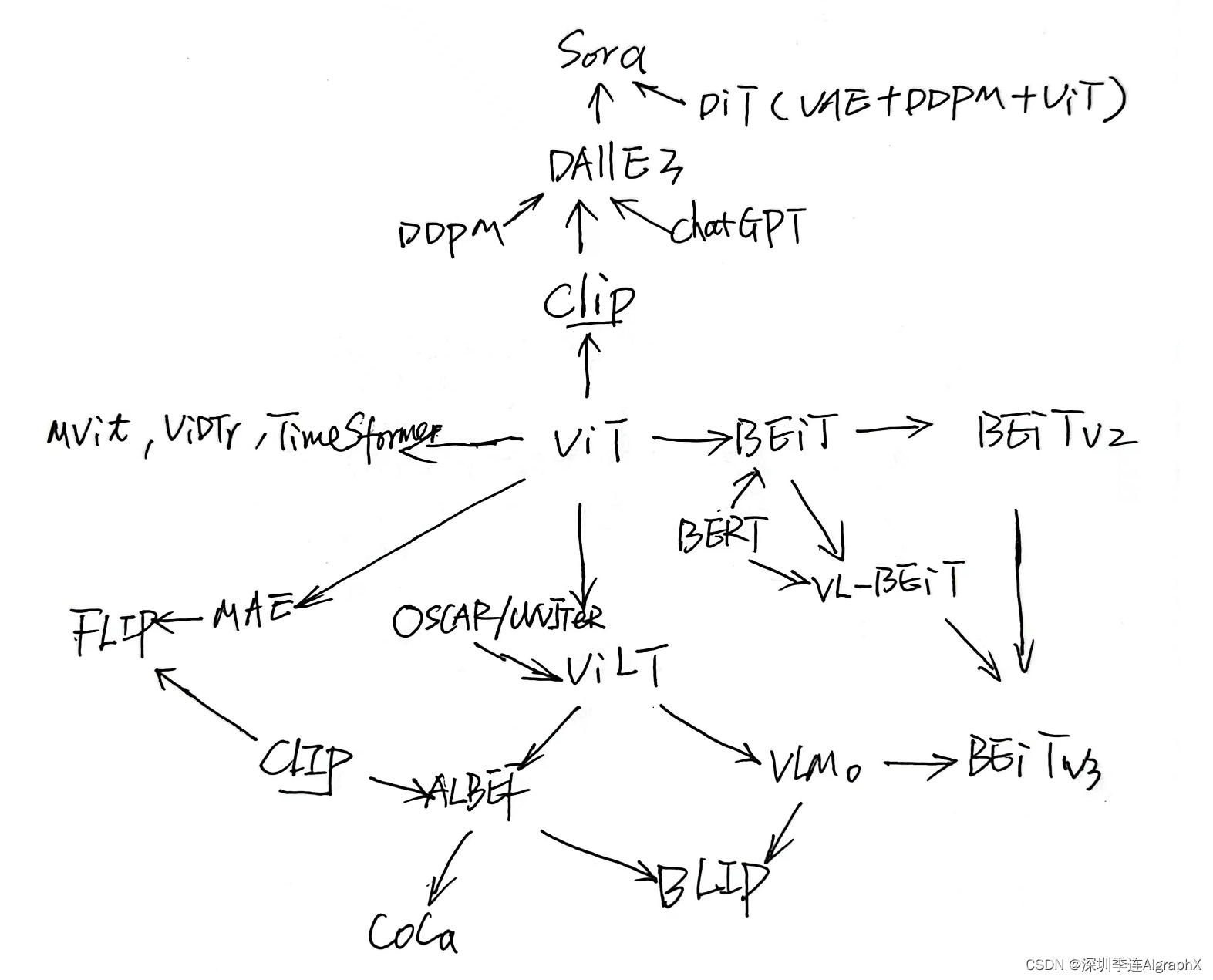
在这个万模都Transformer的时代,谷歌提出的Attention Is All You Need论文,是Transformer encoder-decoder架构的开山之作。读者一看这名字就感觉有梗。事实上这篇文章可以认为是最近几年以来深度学习里面最重要的文章之一,开创了继NLP、CNN和RNN之后的第四大类模型。Transformer最早运用在NLP领域,论文中提出的编码器、解码器、多头自注意和自回归等核心技术影响深远。
谷歌提出的ViT(An image is worth 16 x16 words: transformers for image recognition at scale)取代了CNN,打通了CV和NLP之间的鸿沟,而且挖了一个更大的多模态的坑。Vision Transformer,ViT未来有可能真就是一个简洁、高效、通用的视觉骨干网络,正如上图大家看到的一样。其实现原理是将NLP领域的Transformer借鉴到CV领域。原始输入图像作切块处理,每一个小方块就是一个patch。Patch Embedding编码就是将一个CV问题通过切块和展平转化为一个NLP问题。
OpenAI一提出CLIP(Contrastive Language-Image Pre-training)就立马火爆全场,CLIP预训练好后,能够在任意一个视觉分类数据集上取得不错的效果,而且更炸裂的是Zero-Shot,意思就是说它完全没有在目标数据集上做训练,就能得到很高的效果。最后还顺带产生了一个4亿图像-文本对WebImageText,WIT数据集。CLIP是一种基于对比文本-图像对的预训练方法或者模型。与CV中的一些对比学习方法如MoCo不同的是,CLIP的训练数据是文本-图像对,即一张图像和它对应的文本描述。通过对比学习,模型能够学习到文本-图像对的匹配关系。
OpenAI提出的DALL·E(Zero-Shot Text-to-Image Generation)文生图模型目标是把文本token和图像token当成一个数据序列,通过Transformer进行自回归。由于图片的分辨率很大,如果把单个pixel当成一个token处理,会导致计算量过于庞大,于是DALLE引入了一个dVAE降噪变分自编码模型来降低图片的分辨率。随后OpenAI把该模型升级到DALLE2,结合预训练CLIP和DDPM:Denoising Diffusion Probabiblistic Model扩散模型实现文本到对应图像生成。生成对抗网络GAN、变分自编码器VAE、扩散模型Diffusion models都具有强大的图像生成能力,DALLE和DALLE2分别用了不同的技术。其中,DDPM通过逐步添加噪声来模拟数据分布,然后学习逆向过程去除噪声,以生成新的数据。最后,DALLE3把chatGPT也引入了进来,让模型更理解上下文、关注更多细微差别。用户参与度高,能轻松地将想法(文本)转化为更加准确、丝滑的图像。以致相关应用火爆全球。
UC Berkeley和New York University联合提出的DIT: Scalable Diffusion Models with Transformers,是一种基于Transformer架构的新型扩散模型。它用Transformer替换常用的U-Net主干网络,训练了图像的潜在扩散模型Latent Diffusion Models。24年1月,团队二作谢赛宁团队推出了升级版SiT,Scalable Interpolant Transformer,相同的骨干实现了更好的质量、速度和灵活性。
至此,介绍了公认的Sora核心技术。当然要实现Sora,不可能就这么顺溜,就这样一步登天。笔者认为平常还得积累一些基础工作。
视频理解领域,Facebook AI Research提出了一种称为TimeSformer视频理解的新架构,这个架构完全基于Transformer,不使用卷积层。它通过分别对视频的时间和空间维度应用自注意力机制,有效地捕捉动作的时空特征。
多模态领域,来自Salesforce团队提出的BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation,引导文本图像预训练,以实现统一的视觉语言理解和生成。BLIP是一个新的Vision Language Pre-training,VLP框架,与现有方法相比,它可以实现更广泛的下游任务。通过BLIP的CapFilter/Filter数据增强,得到了比WIT噪声更少的数据集。用户可以拿这个数据去训练VLMo,训练CoCa,训练BEiT系列,去训练各种各样的多模态大模型。BLIP未来可能是一个非常通用的工具。
当然,要复现论文,就不得不提到微软。这个团队最近几年出了很多大名鼎鼎的工作,比如说DeepSpeed基础大模型、BEiT系列和LayoutLM系列等等。感觉其工作思路的核心特色是开源,并努力降低模型的算力需求,以期匹配更多的玩家。其中,BEiTv3的核心思想是将图像建模为一种语言,这样用户就可以对图像、文本以及图像-文本对进行统一的Mask Modeling。Multi-Way Transformer模型可以有效地完成不同的视觉和视觉语言任务,使其成为通用建模的一个有效选择。另外,如果要做提示、微调或者说蒸馏大模型的话,InstructGPT、InstructBLIP是不错的两篇论文。由此延展,可以挖掘出很多工程技术来。






![project.config.json 文件内容错误] project.config.json: libVersion 字段需为 string, string](https://img-blog.csdnimg.cn/direct/08ea24dcd8f84ee592ae0aafada6d241.png)