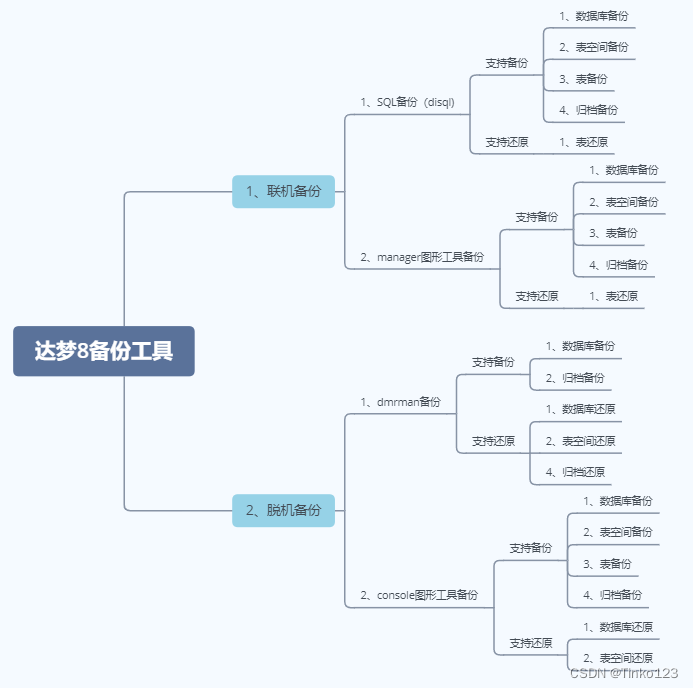
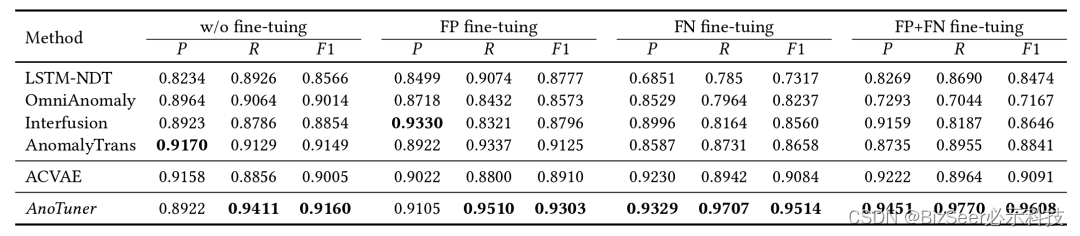
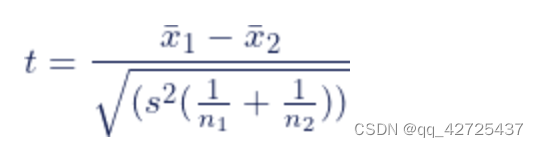1.图片标签
img是图片标签;alt是对图片标签的描述
2.获取网页内容
接下来,使用requests模块和BeautifulSoup模块请求并解析网页内容。
在爬取新的网页内容前,我们需要导入requests模块,请求并查看状态码。
拿到网页源代码后,使用解析库BeautifulSoup对网页进行解析,提取网页节点内容。

3.复习之前的导入模块,传入User-Agent

4.单个网页图片的获取
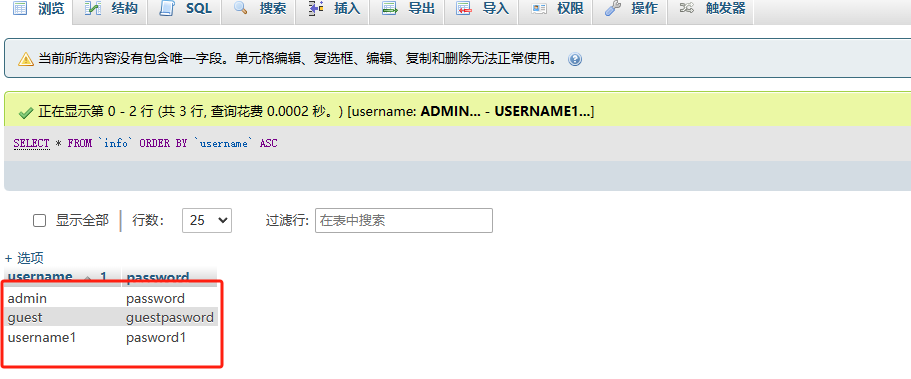
通过对网页进行观察,我们发现图片的都是class="pic",利用这个属性找到图片
通过遍历,就拿到了每张图片的源代码,这里的每个URL都放在<img>标签中。

5.<div></div>标签中提取<img>
find()和find_all()的区别是,find()用于查找单个元素,返回字符串。
find_all()用于查找多个元素,返回一个列表,获取find_all()查找后的元素必须遍历,不然会报错。

打印结果

6.获得属性值
对<img>标签中的src和alt属性使用.attrs,就可以获取属性值。
例如获取图片标签中的图片描述就可以使用,attrs["alt"],获取图片标签中的链接就可以使用attrs["src"]。

7.获取图片并保存到本地


这个就代表成功了!!!!
8.完整代码
import requestsfrom bs4 import BeautifulSoupurl = "https://movie.douban.com/top250"headers = {"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.89 Safari/537.36"}response = requests.get(url, headers=headers)html = response.textsoup = BeautifulSoup(html, "lxml")content_all = soup.find_all(class_="pic")
l
for content in content_all:imgContent=content.find(name="img")imgName=imgContent.attrs["alt"]imgUrl = imgContent.attrs["src"]imgResponse = requests.get(imgUrl)img = imgResponse.contentwith open(f"D:\网络爬虫\patu\{imgName}.jpg", "wb") as f:f.write(img)