论文名称: LongLoRA: Efficient Fine-tuning of Long-Context Large Language Models
文章链接:https://arxiv.org/abs/2309.12307
代码仓库: https://github.com/dvlab-research/LongLoRA
现阶段,上下文窗口长度基本上成为了评估LLM能力的硬性指标,上下文的长度越长,代表大模型能够接受的用户要求越复杂,近期OpenAI刚发布的GPT-4 Turbo模型甚至直接支持到128K的上下文窗口,相当于用户可以直接喂给模型一部长达300页的小说。但是从模型实现角度来看,训练具有长上下文大小的LLM的成本很高。例如在8192的上下文长度上训练参数规模相同的模型,自注意力层的计算成本是2048的16倍。
本文介绍一篇来自CUHK和MIT合作完成的工作,本文结合LoRA方法提出了长上下文LLM微调框架LongLoRA,本文从两个方面对LLM的上下文窗口进行了优化,首先提出了shift short attention(S2-Attn)模块替代了原始模型推理过程中的密集全局注意力,可以节省大量的计算量,同时保持了与普通注意力微调相近的性能。此外作者重新审视了LLM上下文窗口参数的高效微调机制,提出了LongLoRA策略,LongLoRA可以在单个8×A100机器上实现LLaMA2-7B模型的上下文从4k扩展到100k,或LLaMA2-70B模型的上下文扩展到32k。LongLoRA具有很强的普适性,其可以保持LLM的原始架构,并且与大多数现有技术兼容,例如FlashAttention-2等,此外,为了让LongLoRA的模型具有对话能力,作者团队专门收集了一个LongAlpaca数据集(包含9k长上下文问答对和3k短问答对),用于监督微调。
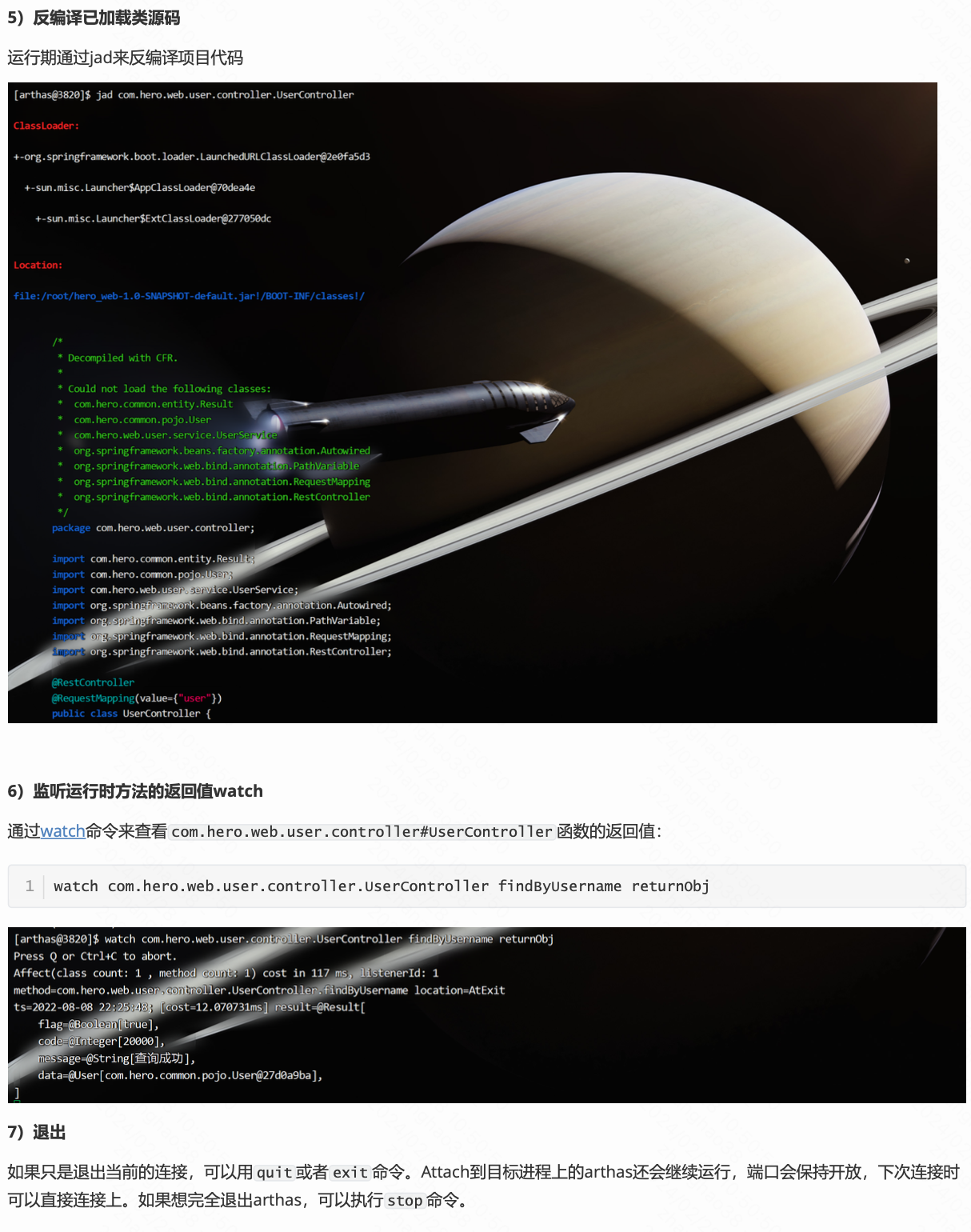
01. 引言
训练或微调一个LLM所需的计算资源对于普通的研究人员来说通常难以承受,因此研究更轻量的模型微调方案已经成为学术界的热点话题,目前最直接的手段是使用微软提出的低秩适应方法(LoRA)[1],LoRA可以通过学习一个低秩矩阵来修改自注意力块中的线性投影层,达到高效减少模型可训练参数规模的效果。

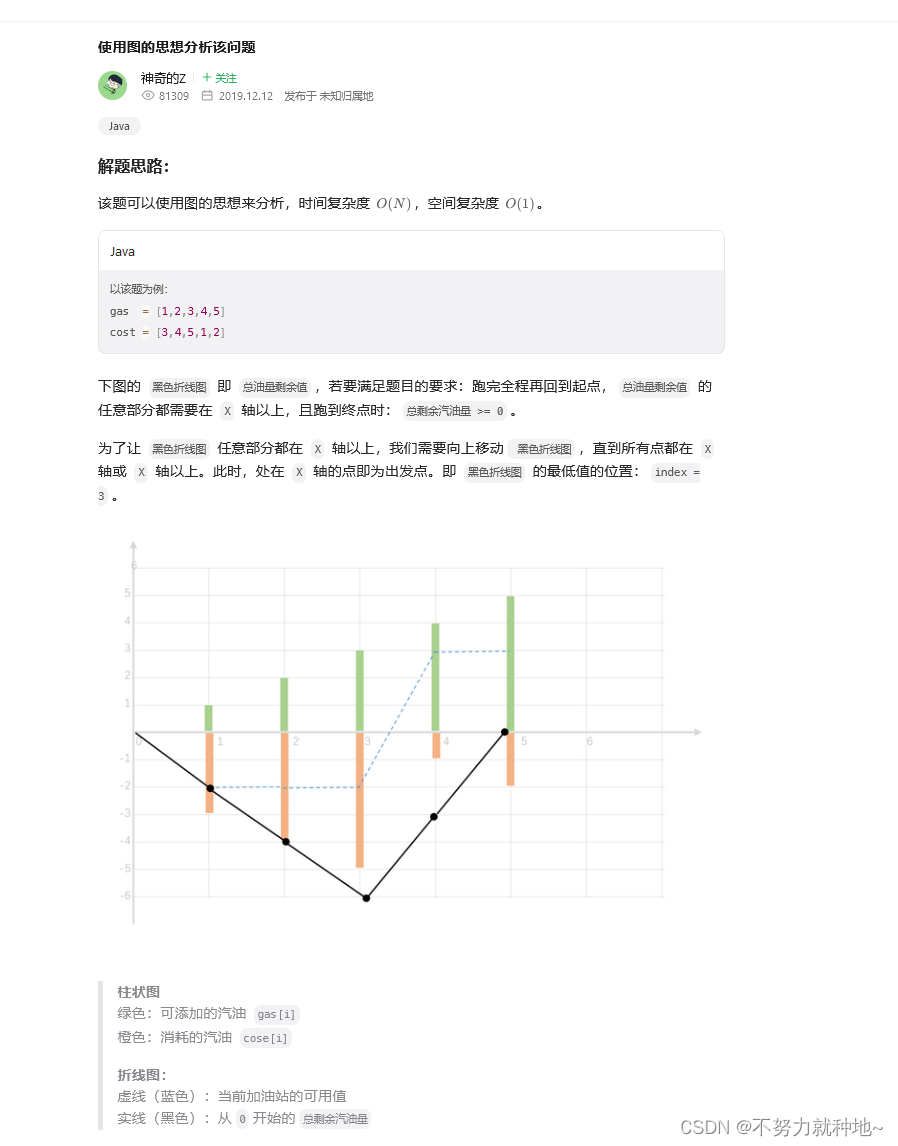
但是LoRA在遇到超长上下文的查询时,提升效果不够明显,并且会带来模型困惑度增加的问题,本文作者以LLaMA2-7B模型进行了模型困惑度实验,实验结果如上表所示,可以看到,LoRA方法相比完整微调方法(Full FT)会带来更明显的困惑现象,即使将LoRA矩阵的秩提升到256也不能缓解这种问题。此外在模型效率方面,无论是否采用LoRA,随着上下文窗口长度的扩展,模型的计算成本都会急剧增加,这主要是由于自注意力机制的计算量导致的,如下图所示,作者展示了三种不同方法在训练相同的LLaMA2模型时,模型的训练复杂度、GPU占用和训练时间随着上下文窗口长度增加的变化情况。
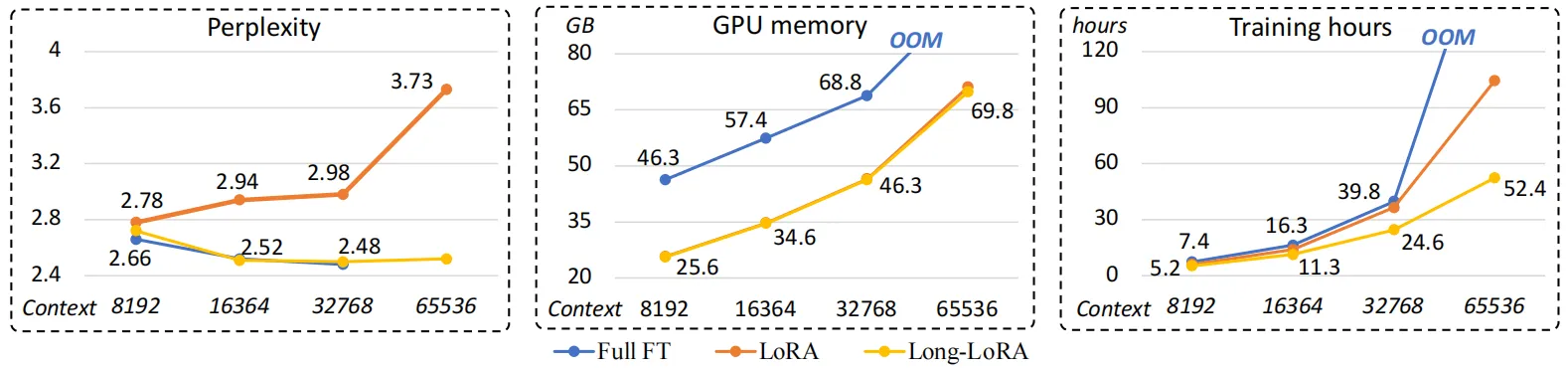
为了解决上述问题,本文引入了一种专门解决长上下文训练难题的LongLoRA微调方法,同时为了应对标准自注意力机制庞大的计算量,作者提出了一种短时注意力S2-Attn来减少计算成本,从上面三个图中的结果来看,LongLoRA可以有效的提升模型各方面的微调性能。
02. 本文方法
2.1 shift short attention(S2-Attn)


其首先将模型的输入分为几组,并在每个组中分别进行注意力计算,同时在每个组中,将原有的token移动组大小的一半来保证相邻注意力头之间的信息交互,作者进行了如下的实验来观察S2-Attn在不同上下文窗口中的性能变化,其中参与实验的baseline方法还包括一些无需进行微调的位置编码优化方法。可以看到,微调对于模型处理长上下文输入的效果起到了非常重要的作用。
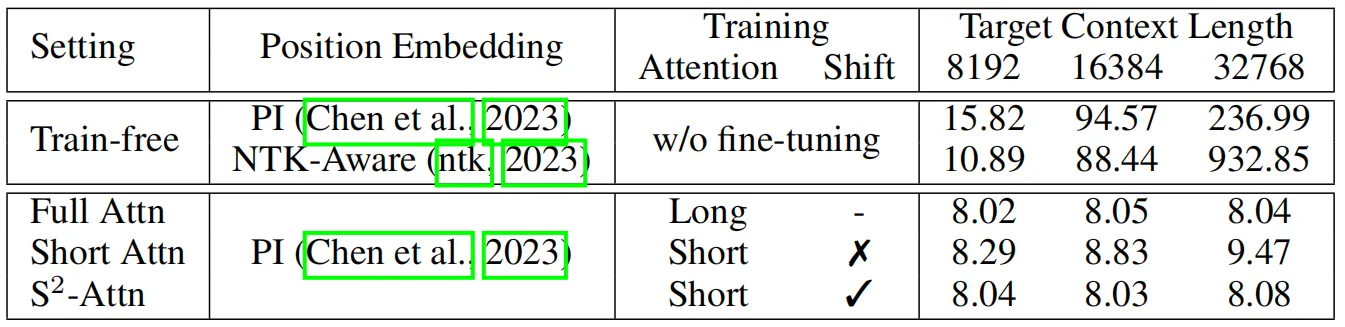
上表中的第一种注意力模式是只使用短时注意力进行训练(Pattern 1),由于对于长上下文,模型的计算成本主要来自自注意力模块。因此,在这个试验中,作者将自注意力模块分为4组。例如,在模型的训练和测试阶段均采用8192个token作为输入,而每个组中的注意力计算的token大小为2048,如上表所示,这种模式相比普通方法已经能够提升模型性能,但是随着上下文长度的增加,模型的困惑程度变得更严重,作者分析造成这种情况的原因是不同的组之间没有信息交互。
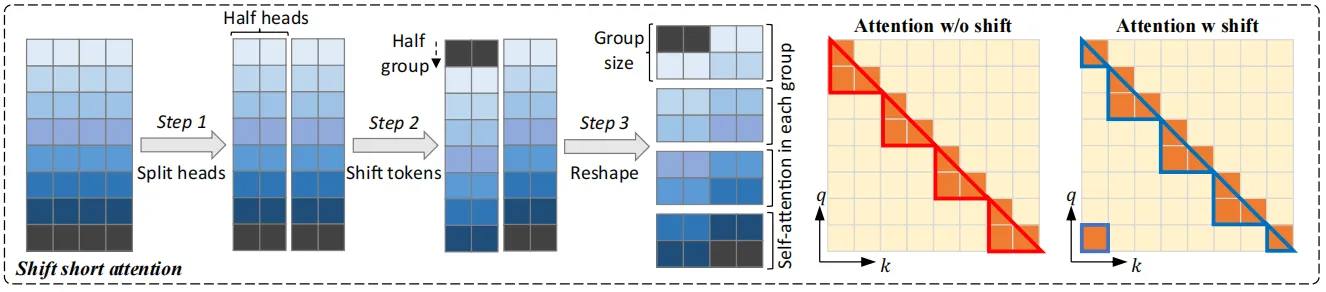
为了促进不同注意力组之间的信息交互,作者提出了一种shift模式,如上图所示,即在进行组划分时将注意力头移动组长度的一半距离,以上下文窗口长度8192为例,在Pattern 1中,第一组从第1个到第2048 个token进行自注意力计算。在Pattern 2中,组划分移动长度为1024,这样就导致另一个注意力组从第1025个token开始,到第3072个token结束,而第一个和最后1024个token属于同一组,这种方式不会增加额外的计算成本,但可以实现不同组之间的信息流动。

此外,shift short attention非常容易在代码中实现,上图展示了其在注意力块计算时的伪代码,只需要在原始自注意力计算的基础上添加两行代码。
2.2 面向长上下文改进LoRA算法到LongLoRA
LoRA算法是目前LLM社区中非常常用的微调方法,几乎是微调一个基座模型到下游垂直领域中的首选算法,与完全微调相比,它节省了大量可训练参数和显存占用的成本。然而,使用LoRA算法在较长上下文的场景中进行训练仍然存在一些问题,微调后的模型性能会略逊色于完全微调方法,这种性能差距会随着目标上下文长度变大而增大。
为了弥补这一差距,作者在训练时允许模型嵌入层和归一化层的参数进行更新。最终效果如上表所示,虽然这些层只占用少量的参数(特别是归一化层的参数量占比在整个LLaMA2-7B模型中仅为0.004%),但它们却对模型在长上下文场景中的适应起到有益帮助,上表中的LoRA+Norm+Embed获得了最佳性能,作者在后续的实验中将这种LoRA的改进版本表示为LoRA+。
03. 实验效果
本文的实验基座模型选用了预训练的LLaMA2模型,分别包含7B、13B和70B的版本,其中7B版本的最大上下文窗口大小为100k,13B版本为65536,70B版本为32768。对于实验数据集,作者使用Redpajama数据集进行训练,随后使用图书语料库数据集PG19和Arxiv Math数据集来评估微调模型的长序列语言建模性能,还使用PG19的测试集专门评估模型的困惑度。此外,作者团队还提出了一个用于监督微调长上下文模型的数据集LongAlpaca,LongAlpaca包含了9k个长问题和相应的答案,以及3k短问答,共计12k问答数据。
3.1 长序列语言建模性能
下表中展示了本文方法在LLaMA2-7B和LLaMA2-13B模型上的长序列建模实验结果,模型的性能通过困惑度指标来体现,可以看到,对于相同的训练和评估上下文长度的情况,随着上下文窗口长度的增加,模型的困惑度会降低。通过将LLaMA2-7B模型的上下文窗口大小从8192增加到32768时,模型困惑度从2.72降低到2.50,降低了0.22。对于LLaMA2-13B模型,可以观察到困惑度从2.60降低到2.32,降低了0.28。
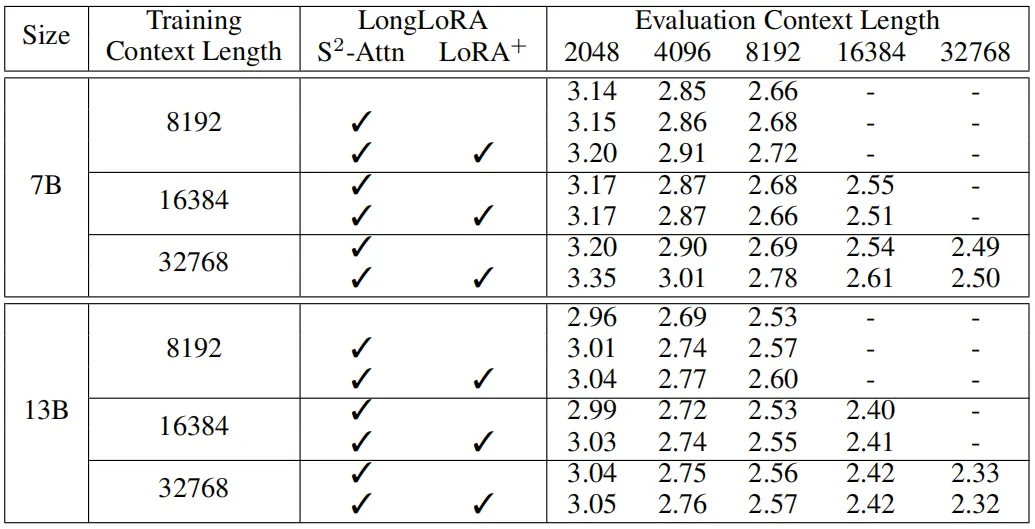
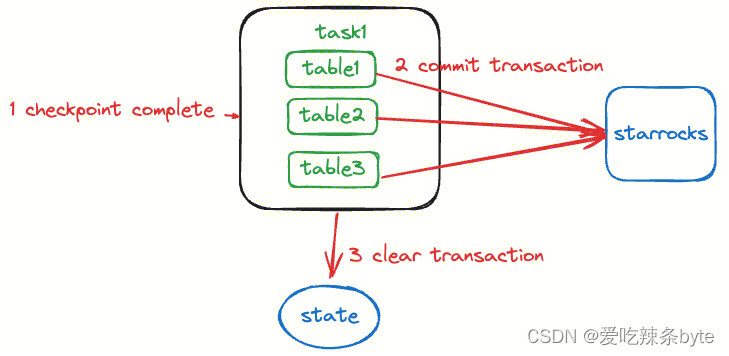
在下表中,作者进一步探索了LongLoRA可以在单个 8 x A100 机器上微调的最大上下文窗口长度。这里将LLaMA2 7B、13B 和 70B 的上下文长度分别扩展到 100k、65536、32768,可以看到,LongLoRA在这些极端的设置上仍然取得了较好的结果,此外也可以观察到,扩展模型的上下文窗口大小会导致模型的困惑度下降。

3.2 基于检索的性能评估
为了保证实验的完整性,作者在长序列语言建模性能评估之外还引入了基于长上下文检索的实验。在下表中,作者将本文方法与其他开源LLMs在LongChat[2]中设置的主题检索任务上进行了对比实验。该任务要求模型从很长的对话数据中检索到目标主题,长度从 3k、6k、10k、13k 到 16k 不等。由于数据集中的一些问题的长度超过了16k,因此作者选择对LLaMA2-13B模型进行微调,上下文窗口长度为18k。
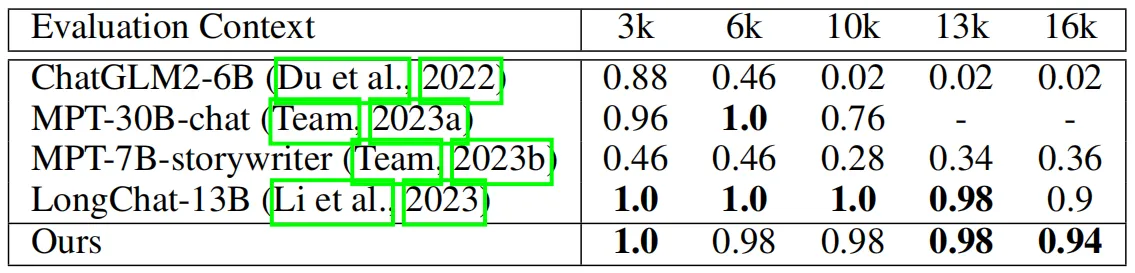
从上表中可以看出,本文方法实现了与该任务中SOTA方法LongChat-13B相当的性能,甚至在极端长度16k的场景评估中性能超过了LongChat-13B。
04. 总结
本文针对LLM微调训练提出了一种名为LongLoRA的方法,它可以有效地将LLM的上下文窗口长度扩展到更长的范围。LongLoRA与标准完全微调方法相比,所使用的GPU显存成本和训练时间更少,并且精度损失也很小。在架构层面,作者将原始笨重的自注意力计算转换为更加轻量的shift short attention(S2-Attn),S2-Attn以独特的注意力头划分模式实现了局部的信息交互,从而带来更高效的性能,更关键的是,S2-Attn只需要两行代码就可以实现。在模型训练层面,作者在传统LoRA微调模式中加入了可训练的标准化和嵌入层参数,这被证明在长上下文场景中是有效的。从实际操作层面来看,LongLoRA是一种通用的方法,可以兼容到更多类型的LLMs中,进一步降低开发者微调LLM的难度和成本。
参考
[1] Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. Lora: Low-rank adaptation of large language models. In ICLR, 2022.
[2] Dacheng Li, Rulin Shao, Anze Xie, Ying Sheng, Lianmin Zheng, Joseph E. Gonzalez, Ion Stoica,Xuezhe Ma, and Hao Zhang. How long can open-source llms truly promise on context length? June 2023.
关于TechBeat人工智能社区
▼
TechBeat(www.techbeat.net)隶属于将门创投,是一个荟聚全球华人AI精英的成长社区。
我们希望为AI人才打造更专业的服务和体验,加速并陪伴其学习成长。
期待这里可以成为你学习AI前沿知识的高地,分享自己最新工作的沃土,在AI进阶之路上的升级打怪的根据地!
更多详细介绍>>TechBeat,一个荟聚全球华人AI精英的学习成长社区