R语言数学建模(一)—— 基础知识
文章目录
- R语言数学建模(一)—— 基础知识
- 前言
- 一、建模软件
- 1.1 软件建模的基础
- 1.2 模型的分类
- 1.3 不同类型模型间的联系
- 1.4 一些术语
- 1.5 建模如何适应数据分析过程
- 二、Tidyverse基础
- 2.1 tidyverse的原则
- 2.1.1 为人类设计
- 2.1.2 重现现有的数据结构
- 2.1.3 管道设计与函数编程
- 2.2 tidyverse语法示例
- 三、R建模基础
- 3.1 一个例子
- 3.2 R公式的作用
- 3.3 为什么整洁(tidy)对于建模很重要
- 3.4 Base R和tidyverse的结合
- 3.5 tidymodels元包(metapackage)
- 总结
前言
这一节开始,我们来学习R语言的又一大功能——数学建模。这是数据分析常用到的数学知识。R提供了一些简洁好用的包,让这一过程变得更加简单易懂。在学习这部分内容的同时,强烈建议自行学习关于统计学的相关知识点,这样在学习到相关内容时才会有更加深刻的理解与收获。
一、建模软件
模型的效用取决于其还原能力,或者将复杂的关系简化为简单术语的能力。
1.1 软件建模的基础
首先,重点在于使用建模软件要易于正确操作。其次,建模软件应该推广良好的科学方法论,软件应该尽可能保护用户避免犯错。(R:yyds。R包tidyverse:牛。)
1.2 模型的分类
按建模目的分的话:
-
描述模型:目的时描述说明数据的特征,在视觉上强调数据中的一些趋势等。比如平滑器模拟数据趋势等。
-
推理模型:为问题提供一个解决方案或特定的假设。例如临床上判断某种决定的所带来的影响。
-
预测模型:对新数据做出尽可能准确的预测。这种模型的重点在于不同方法都可以创建预测模型,到底应该如何开发是重点。
1.3 不同类型模型间的联系
注意我们是根据模型目的来定义其类型的,不是根据其数学性质。
1.4 一些术语
首先,许多模型都可以分为有监督模型和无监督模型。无监督模型就是那些学习模式,聚类,或者数据的其他特征但是缺乏结果的模型。PCA、聚类或者自动编码器都是这个类型的例子,他们用于理解预测因子和结果的关系,而预测因子与结果间没有明确的关系。监督模型是那些有结果变量的模型,线性回归,神经网络和许多其他方法都是这一类的。
监督模型中,有两个主要的子类别:
-
回归预测一个数字结果
-
分类预测的结果是一组有序或无序的定性值
不同的变量有不同的角色,特别是监督分析中。输出结果(也可叫labels,终点或因变量)是监督模型中预测的值。独立变量是预测结果的基础,也被称为预测因子,特征或协变量。
1.5 建模如何适应数据分析过程
建模之前还有一些步骤。首先,数据清理(tidy data)过程是一个重要的程序。无论什么情况,都应该调查数据,确保其适用于你的项目目标,准确和适合。这些步骤往往花费的时间更久(即是数据预处理过程)。
数据清理可以与理解数据的第二阶段重叠,该阶段称为探索性数据分析(EDA)。EDA揭示了不同变量之间的相互关系、他们的分布、典型范围和其他属性。这个阶段一个很好的问题是"我是怎么得到这些数据的"这个问题可以帮你了解数据如何采样和过滤的,从而确定这些操作是否合适。另一个问题是这些数据是否与研究相关。
最后,开始数据分析过程前,应该对模型的目标及如何判断性能有一个明确的预期。至少应该确定一个性能度量的标准,并确定可以实现的现实目标。常见的统计度量包括准确率、真阳性率和假阳性率、均方根误差等。
确定合适模型的典型过程如下:
-
EDA:在数值分析和可视化之间有一个来回的过程来发现导致更多问题和数据分析的任务。
-
Feature engineering:从EDA中获得的结果导致创建特定的模型术语,从而更为容易准确的为观察到的数据建模。
-
模型交替和选择:生成多种模型对其性能进行比较。
-
模型评估:检查模型的性能指标
二、Tidyverse基础
tidyverse包是一个用于数据分析的R包集合,这些包是根据共同的思想和规范开发的。
2.1 tidyverse的原则
http://design.tidyverse.org可以找到全套的使用策略,下面简要介绍几个通用的原则。也可以在R语言数据分析专栏对其进行了解。
2.1.1 为人类设计
tidyverse专注于设计易于理解和广泛使用的R包和函数。
为了将数据框中的某一或多列进行排序,使用R核心语言,我们可以通过order()实现。你不能使用一个函数来进行该功能,比如sort()。要对mtcars其中的两列进行排序,可能要这样调用:
mtcars[order(mtcars$gear, mtcars$mpg), ]
当你使用dplyr包时,就只需要:
library(dplyr)
arrange(.data = mtcars, gear, mpg)
2.1.2 重现现有的数据结构
有可能的话,函数应该尽可能避免返回新的数据结构。这将减少使用软件时的认知负荷。
tidyverse和tidymodels包中,使用的数据结构是数据框。具体来讲,他们支持一种叫tibble的格式。
2.1.3 管道设计与函数编程
magrittr中的管道函数(%>%)是一个在函数间传参的工具(或R原生中的|>)。函数式编程应该尽量使输出只依赖于输入。
2.2 tidyverse语法示例
tibble与R中的基本data.frame有所不同。例如,tibble可以使用在语法上无效的列名:
# 想要的无效名称(空格)
data.frame(`v 1` = 1:2, `two` = 3:4)
#> v.1 two
#> 1 1 3
#> 2 2 4
# 空格转换为了.,但也可以这样:
df <- data.frame(`v 1` = 1:2, `two` = 3:4, check.names = FALSE)
df
#> v 1 two
#> 1 1 3
#> 2 2 4# 但是tibble直接:
tbbl <- tibble(`v 1` = 1:2, `two` = 3:4)
tbbl
#> # A tibble: 2 × 2
#> `v 1` two
#> <int> <int>
#> 1 1 3
#> 2 2 4
标准数据框支持参数的部分匹配,tibble防止了这种情况:
df$tw
#> [1] 3 4tbbl$tw
#> Warning: Unknown or uninitialised column: `tw`.
#> NULL
tibble还避免了维度下降的可能。
。。。
三、R建模基础
本节简要说明如何使用R核心进行创建、训练和使用模型。
3.1 一个例子
为了了解R的基础建模功能,我们使用使用两个物种的数据,这些物种包含在crickets的数据框中,包含31个数据点:
library(tidyverse)data(crickets, package = "modeldata")
names(crickets)
#> [1] "species" "temp" "rate"ggplot(crickets, aes(x = temp, y = rate, color = species, pch = species, lty = species)) + geom_point(size = 2) +geom_smooth(method = lm, se = FALSE, alpha = 0.5) +scale_color_brewer(palette = "Paired") +labs(x = "Temperature (C)", y = "Chirp Rate (per minute)")
#> `geom_smooth()` using formula = 'y ~ x'

数据显示,每个物种都呈现线性的趋势。对于一个给定的温度,数据显示O.e似乎比另一个物种每分钟鸣叫的次数更多。但其实对于这个推论模型来说,研究者可能在看到数据前就指定了以下原假设(H0):
-
温度对于鸣叫速率没有影响
-
不同物种鸣叫速率没有差异
为了在R中拟合普通线性模型,最常用的是lm()函数。此函数重要参数是模型公式和包含的数据框。可以使用以下公式来指定:
rate~temp
左侧是输出,右侧是预测因子。假设数据包含一天内的时间,其中测量值是在名为time的列中,这个公式表示为:
rate~temp + time
这里并不会将temp和time相加,而只是象征性的表示温度和时间应该作为单独的主效应添加至模型中。如果某个预测因子是一个分类变量,R会将其转换为数值向量进行模型的预测。比如两个分类变量是上述所示的两个物种,将会使用0,1代替。如果变量个数是5个而不是两个,这时会创建四个二进制列作为四个物种的二元指示器。
创建两个具有交互作用的预测因子的模型的方式如下:
rate~temp + species + temp:species# 有以下快捷方式进行展示
# 这就表示了两种预测因子的相互作用:
rate~(temp + species)^2#另一种快捷表示方式如下:
rate~temp * species
创建预测因子还有以下的形式:
-
公式中可以使用内联函数。比如
rate~log(temp)使用temp的自然对数值。如果想要使用一些特殊的公式可以用到I()函数。比如华氏温度的转换:rate~I((temp * 9/5) + 32) -
R有许多在公式中都很有用的函数。比如,
poly(x, 3)添加了线性、二次、三次的x在模型的主要效应中。 -
对于有多个预测因子的数据集,可以使用一些快捷方式表示。比如使用
~(.)^3表示在模型中添加所有两个和三个变量交互的主效应值
回到我们的实例中,使用双因素交互模型:
intercation_fit <- lm(rate ~ (temp + species)^2, data = crickets)intercation_fit
#>
#> Call:
#> lm(formula = rate ~ (temp + species)^2, data = crickets)
#>
#> Coefficients:
#> (Intercept) temp speciesO. niveus
#> -11.041 3.751 -4.348
#> temp:speciesO. niveus
#> -0.234
输出结果有些难读,因为R将物种指示变量的变量名于因子级别混在一起显示了,中间并没有分割符。
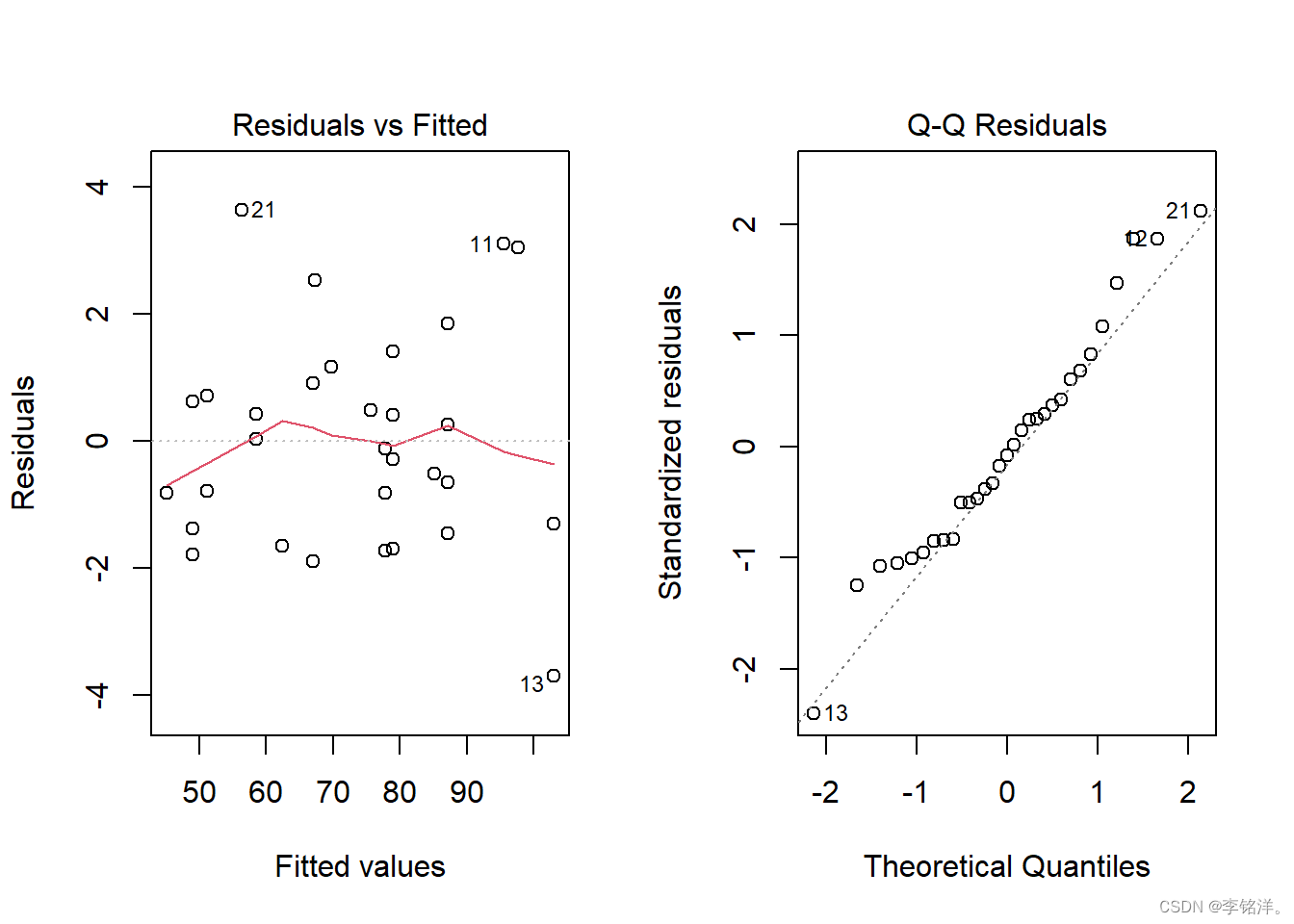
在对于该模型的任何推断结果之前,都应该使用诊断图来评估其合理性。我们可以使用plot()方法对于lm对象作图。该方法为对象生成四个图,每个图显示拟合的不同方面。
# 相邻放置两个plots
par(mfrow = c(1,2))# 显示残差与预测值
plot(intercation_fit, which = 1)# 残差上正常分位数的曲线图
plot(intercation_fit, which = 2)
我们的下一步工作就是评估是否有必要包括相互作用。对于此模型,最合适的方法是重新计算没有交互作用的模型,并使用anova()方法。
main_effect_fit <- lm(rate ~ temp + species, data = crickets)
anova(main_effect_fit, intercation_fit)
#> Analysis of Variance Table
#>
#> Model 1: rate ~ temp + species
#> Model 2: rate ~ (temp + species)^2
#> Res.Df RSS Df Sum of Sq F Pr(>F)
#> 1 28 89.350
#> 2 27 85.074 1 4.2758 1.357 0.2542
p值为0.25,不能拒绝原假设,即模型不需要相互作用项。我们后续使用不包含相互作用项的模型。
我们可以使用summary()来检查每个模型项的系数、标准误和p值:
summary(main_effect_fit)
#>
#> Call:
#> lm(formula = rate ~ temp + species, data = crickets)
#>
#> Residuals:
#> Min 1Q Median 3Q Max
#> -3.0128 -1.1296 -0.3912 0.9650 3.7800
#>
#> Coefficients:
#> Estimate Std. Error t value Pr(>|t|)
#> (Intercept) -7.21091 2.55094 -2.827 0.00858 **
#> temp 3.60275 0.09729 37.032 < 2e-16 ***
#> speciesO. niveus -10.06529 0.73526 -13.689 6.27e-14 ***
#> ---
#> Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
#>
#> Residual standard error: 1.786 on 28 degrees of freedom
#> Multiple R-squared: 0.9896, Adjusted R-squared: 0.9888
#> F-statistic: 1331 on 2 and 28 DF, p-value: < 2.2e-16
这些数据显示,温度每提升一度,rate提升3.6个单位,这里显示出很强的统计学意义,p是证据。对于物种表明,每个温度下O.n都比O.e的rate小10个单位,p也是证据。这里唯一有问题的在于截距(Intercept)表示0度时的rate是负数,这明显不符。但是数据最低温度仅为17.2度,这说明结论在温度值的适用范围内是良好的。
如果我们想要得到在实验中未观察到的温度下的rate,可以使用predict()函数:
new_values <- data.frame(species = "O. exclamationis", temp = 15:20)
predict(main_effect_fit, new_values)
#> 1 2 3 4 5 6
#> 46.83039 50.43314 54.03589 57.63865 61.24140 64.84415
这一例子表明:
-
R有可表达的语法,用于为简单和复杂模型指定术语
-
R公式可以为建模提供许多便利
-
有许多有用的函数可以在模型建立后进行特定的计算(
anova(),summary(),predict()等)
终:R语言,一开始就是为了数据分析而设计的!
3.2 R公式的作用
R模型的公式(formula)有许多用途:
-
定义模型使用的列
-
使用公式将列编码成为合适的格式
-
列的角色使用公式来定义
最后一个用途的意思就是要告诉模型怎么使用列,比如上述例子中的:
(temp + species)^2
3.3 为什么整洁(tidy)对于建模很重要
R的一个优点在于,它可以让用户选择适合自己的方法来处理数据。比如,下面是在一个数据框内创建图形的三种方式:
plot(plot_data$x, plot_data$y)library(lattice)
xyplot(y ~ x, data = plot_data)library(ggplot2)
ggplot(plot_data, aes(x = x, y = y)) + geom_point()
这里,不同开发成员设计了三个使用界面,格局优劣。在这方面与Python不同,Python推崇一种用户使用形式。虽然这样R可以随着时间发展有不同的应用形式,但是R包之间的差异无疑会加大用户的使用难度。
假如你的建模项目可以使用多种函数进行,为了实现获得每个样本的类概率估计值,不同函数提供了相应的predict()方法。其实这些方法存在显著的异质性,但即使很有经验的人也无法看出:
| Function | Package | Code |
|---|---|---|
| lda() | MASS | predict(object) |
| glm() | stats | predict(object, type = “response”) |
| gbm() | gbm | predict(object, type = “response”, n.trees) |
| mda() | mda | predict(object, type = “posterior”) |
| rpart() | rpart | predict(object, type = “prob”) |
| various | RWeka | predict(object, type = “probability”) |
| logitboost() | LogitBoost | predict(object, type = “raw”, nIter) |
| pamr.train() | pamr | pamr.predict(object, type = “posterior”) |
最后一种甚至没有调用predict(),这些情况就是日常使用R建模时的阻碍。
另一个问题在于缺失值的处理,一个缺失值往往会引起缺失值的传播,比如一个缺失值会引起平均值的缺失。模型预测时会有几个选项加入到na.action()中。一般常用的是na.fail()和na.omit()选项,前者报错,后者删除案例值。
为了解决这些问题,tidyverse包有一大组设计目标,大多数tidymodels设计目标都属于tidyverse的“Design for Humans”:
-
R具有优秀的面向对象的能力,我们使用它来替代创建新的函数名。(比如一个新的
predict_sample()函数) -
合理的默认值很重要。另外如果需要强制用户做出选择,不应该设置默认值。(如
read_csv()) -
类似的,参数的默认值应该来自于数据中。即在数据内部寻找。
-
函数应该采用用户拥有的数据结构。例如,模型的接口不要唯一为矩阵。
我们在这里使用的broom::tidy()函数是另一个R的标准化工具。它可以以更易用的格式返回多种类型的R对象。例如,根据预测值与结果列的相关性来筛选预测值,使用purrr::map(),cor.test()的结果可以在每个预测值的列表中返回:
corr_res <- map(mtcars %>% select(-mpg), cor.test, y = mtcars$mpg)corr_res[[1]]
#>
#> Pearson's product-moment correlation
#>
#> data: .x[[i]] and mtcars$mpg
#> t = -8.9197, df = 30, p-value = 6.113e-10
#> alternative hypothesis: true correlation is not equal to 0
#> 95 percent confidence interval:
#> -0.9257694 -0.7163171
#> sample estimates:
#> cor
#> -0.852162
如果想要在plot中使用该结果,标准格式的假设检验结果并没有什么用。tidy()方法可以将其作为具有标准化的tibble名称返回:
library(broom)tidy(corr_res[[1]])
#> # A tibble: 1 × 8
#> estimate statistic p.value parameter conf.low conf.high method alternative
#> <dbl> <dbl> <dbl> <int> <dbl> <dbl> <chr> <chr>
#> 1 -0.852 -8.92 6.11e-10 30 -0.926 -0.716 Pearson'… two.sided
这结果可以被堆叠在ggplot()中使用:
corr_res |> map_dfr(tidy, .id = "predictor") |> ggplot(aes(x = fct_reorder(predictor, estimate))) +geom_point(aes(y = estimate)) +geom_errorbar(aes(ymin = conf.low, ymax = conf.high), width = .1) +labs(x = NULL, y = "Correlation with mpg")

3.4 Base R和tidyverse的结合
R的核心语言可以或其他R包中的建模函数可以与tidyverse结合使用,特别是dplyr、purrr、tidyr包的结合使用。例如我们想要为每个蟋蟀物种建立不同的模型,我们可以首先使用dplyr::group_nest()按此列分解蟋蟀数据:
split_by_species <- crickets |> group_nest(species)
split_by_species
#> # A tibble: 2 × 2
#> species data
#> <fct> <list<tibble[,2]>>
#> 1 O. exclamationis [14 × 2]
#> 2 O. niveus [17 × 2]
数据包含列表中蟋蟀的rate和temp列。由此,purrr::map()函数可以为每个物种创建单独的模型:
model_by_species <- split_by_species |> mutate(model = map(data, ~ lm(rate ~ temp, data = .x)))
model_by_species
#> # A tibble: 2 × 3
#> species data model
#> <fct> <list<tibble[,2]>> <list>
#> 1 O. exclamationis [14 × 2] <lm>
#> 2 O. niveus [17 × 2] <lm>
要收集每个模型的系数,需要使用broom::tidy()将其转化为一致的数据框格式,以便可以取消嵌套:
model_by_species |> mutate(coef = map(model, tidy)) |> select(species, coef) |> unnest(cols = c(coef))
#> # A tibble: 4 × 6
#> species term estimate std.error statistic p.value
#> <fct> <chr> <dbl> <dbl> <dbl> <dbl>
#> 1 O. exclamationis (Intercept) -11.0 4.77 -2.32 3.90e- 2
#> 2 O. exclamationis temp 3.75 0.184 20.4 1.10e-10
#> 3 O. niveus (Intercept) -15.4 2.35 -6.56 9.07e- 6
#> 4 O. niveus temp 3.52 0.105 33.6 1.57e-15
3.5 tidymodels元包(metapackage)
tidyverse被设计为一组模块化的R包,每个包的范围都非常窄。tidymodels遵循类似的设计,例如,rsample包侧重于数据的拆分和重采样。尽管采样方法对于其他建模活动至关重要,但他们位于单个包中,而性能指标包含在不同的单独yardstick包中。
tidymodels包会加载一系列核心的tidymodels和tidyverse包:
library(tidymodels)
tidymodels包的框架实际上构建在一些基本的tidyverse包上。
加载metapackage会显示函数名与先前加载的包是否冲突。作为一个例子,加载tidymodels之前,调用filter()函数将会执行stats包中的函数。加载后,将会执行同名函数dplyr::filter()。
有几种方法可以处理命名冲突,例如可以使用命名空间(如:stats::filter())。
另一种方法是使用conflicted包。我们可以设置一个在R对话结束前一直有效的规则,以确保在代码没有给出命名空间的情况下始终运行某个函数:
library(conflicted)
conflict_prefer("filter", winner = "dplyr")
为方便起见,tidymodels包含了一个函数,可以捕获我们可能遇到的大多数常见的命名冲突:
tidymodels_prefer(quiet = FALSE)
注意:使用conflicted::conflict_prefer()会让你选择所有命名空间的冲突,迫使你选择所要使用的函数。函数tidymodels::tidymodels_prefer()处理来自tidymodels函数的常见冲突,但R中的其他冲突还需自行处理。
总结
本节介绍了关于R建模的基础知识,算是一个对于R建模的引入。其实关于数学建模的知识,可能我们在学习实践中早有接触,只是在当时并未有深刻体会。比如回归曲线就是使用数学建模来拟合一段数据的趋势。再比如平时可能会使用到的一些数据分类的方法,(随机森林等一系列模型)都是通过建模来解释数据的分类特征。再后面的学习中,我们将会逐步进行学习。(PS:开学了,完全不想干活~)







![[WebUI Forge]ForgeUI的安装与使用 | 相比较于Auto1111 webui 6G显存速度提升60-75%](https://img-blog.csdnimg.cn/direct/64d6dcb44de04a279bac8d0603b16a1a.png)