我们将数据处理的方式,最开始csv文件

再到与数据库建立联系

代码:
Spider:
import scrapyclass ShuangseqiuSpider(scrapy.Spider):name = "shuangseqiu"allowed_domains = ["sina.com.cn"]start_urls = ["https://view.lottery.sina.com.cn/lotto/pc_zst/index?lottoType=ssq&actionType=chzs&type=50&dpc=1"]def parse(self, resp,**kwargs):#提取trs = resp.xpath("//tbody[@id='cpdata']/tr")for tr in trs: #每一行qi = tr.xpath("./td[1]/text()").extract_first()hong = tr.xpath("./td[@class='chartball01' or @class='chartball20']/text()").extract()lan = tr.xpath("./td[@class='chartball02']/text()").extract()#存储yield {"qi":qi,"hong":hong,"lan":lan}Pipelines:
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html# useful for handling different item types with a single interface
from itemadapter import ItemAdapter
#1.建立联系#弄个坐标#写入数据#提交事务#如果报错,回滚
import pymysql
class Caipiao2Pipeline:def open_spider(self,spider):#开启文件#打开self.f = open("data2.csv",mode='a',encoding="utf-8") #self====>在这个class中定义一个对象def close_spider(self,spider):#关闭文件self.f.close()def process_item(self, item, spider):self.f.write(f"{item['qi']}")self.f.write(',')self.f.write(f"{item['hong']}")self.f.write(',')self.f.write(f"{item['lan']}")self.f.write("\n")# with open("data.csv",mode='a',encoding="utf-8") as f:# f.write(f"{item['qi']}")# f.write(',')# f.write(f"{item['hong']}")# f.write(',')# f.write(f"{item['lan']}")# f.write("\n")return item# 1.建立联系# 弄个坐标# 写入数据# 提交事务# 如果报错,回滚#数据库
class CaipiaoPipeline_MySQL:def open_spider(self, spider): # 开启文件self.conn = pymysql.connect(host="localhost",port=3306,user="root",password="root",database="caipiao")#1.建立联系def close_spider(self, spider): # 关闭文件self.conn.close()def process_item(self, item, spider):try:#弄个坐标cursor = self.conn.cursor()#写入数据sql = "insert into shuangseqiu(qi,lan,hong)values(%s,%s,%s)"cursor.execute(sql,(item['qi'],item['lan'],"_".join(item['hong'])))#提交事务self.conn.commit()#如果报错,回滚except Exception as e:print(e)self.conn.rollback()print("wanbi")return itemsettings:
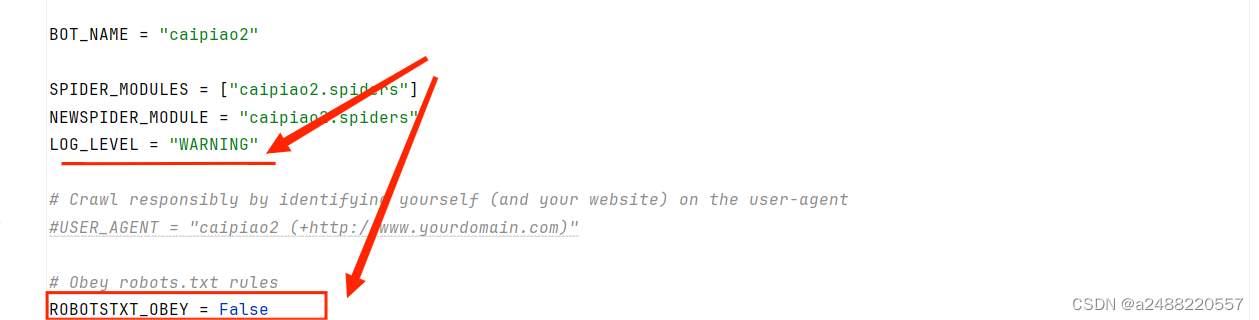


做这些修改 :
上面的思路就是:
1.在spider里找到,qi,hong,lan的对应的信息。
然后用yield(字典)进行返回到pipelines,给到item。
def process_item(self, item, spider):
2.然后写入到文件csv文件里
两种方法:1.
with open("data.csv",mode='a',encoding="utf-8") as f:f.write(f"{item['qi']}")f.write(',')f.write(f"{item['hong']}")f.write(',')f.write(f"{item['lan']}")f.write("\n")2.
def open_spider(self,spider):#开启文件#打开self.f = open("data2.csv",mode='a',encoding="utf-8") #self====>在这个class中定义一个对象def close_spider(self,spider):#关闭文件self.f.close()这两个就是,在执行管道的时候会在最开始打开,和最后关闭。
self.f = open("data2.csv",mode='a',encoding="utf-8"
用这个打开文件。
3.这个是加入到Mysql中:
# 1.建立联系 # 弄个坐标 # 写入数据 # 提交事务 # 如果报错,回滚
这是思路。
class CaipiaoPipeline_MySQL:def open_spider(self, spider): # 开启文件self.conn = pymysql.connect(host="localhost",port=3306,user="root",password="root",database="caipiao")#1.建立联系def close_spider(self, spider): # 关闭文件self.conn.close()def process_item(self, item, spider):try:#弄个坐标cursor = self.conn.cursor()#写入数据sql = "insert into shuangseqiu(qi,lan,hong)values(%s,%s,%s)"cursor.execute(sql,(item['qi'],item['lan'],"_".join(item['hong'])))#提交事务self.conn.commit()#如果报错,回滚except Exception as e:print(e)self.conn.rollback()在第二个管道里,在最开始建立联系,然后正常走。
![[NOIP2011 普及组] 数字反转](https://img-blog.csdnimg.cn/direct/29abc83666914b5f8579b24fc746fbc9.png)