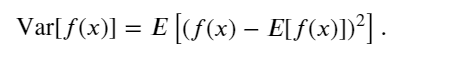学习参考:
- 动手学深度学习2.0
- Deep-Learning-with-TensorFlow-book
- pytorchlightning
①如有冒犯、请联系侵删。
②已写完的笔记文章会不定时一直修订修改(删、改、增),以达到集多方教程的精华于一文的目的。
③非常推荐上面(学习参考)的前两个教程,在网上是开源免费的,写的很棒,不管是开始学还是复习巩固都很不错的。
1.导数基本含义
古希腊人把一个多边形分成三角形,并把它们的面积相加,才找到计算多边形面积的方法。 为了求出曲线形状(比如圆)的面积,古希腊人在这样的形状上刻内接多边形。 内接多边形的等长边越多,就越接近圆。 这个过程也被称为逼近法(method of exhaustion)。
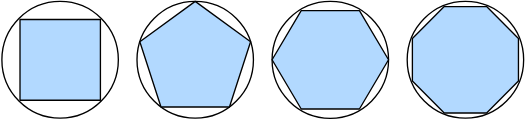
事实上,逼近法就是积分(integral calculus)的起源。 2000多年后,微积分的另一支,微分(differential calculus)被发明出来。 在微分学最重要的应用是优化问题,即考虑如何把事情做到最好。
导数是微积分中的重要概念,它表示函数在某一点处的变化率。具体来说,如果一个函数表示某一物理量随着时间、空间或其他自变量的变化,那么该函数在某一点的导数就表示该物理量在这一点的变化速率。换句话说,导数告诉函数在某一点处是增加还是减少,以及增加或减少的速率有多快。

其中,ℎ是一个无限接近于零的数。这个定义可以理解为,当 ℎ 趋近于零时,函数在点 x 处的导数就是函数在点 x 处的切线的斜率。
导数等价符号:
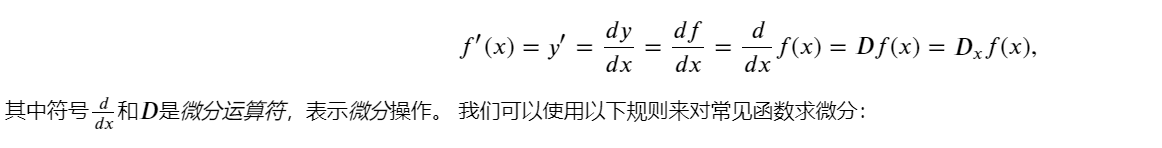
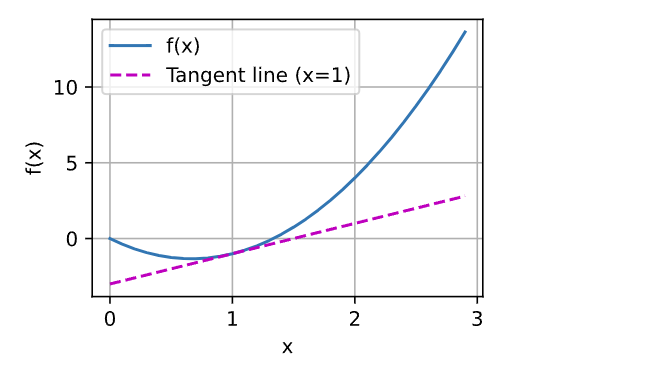
绘制函数 𝑢=𝑓(𝑥) 及其在 𝑥=1处的切线 𝑦=2𝑥−3 ], 其中系数 2是切线的斜率:
2.基本导数公式

3.偏导数
深度学习中,函数通常依赖于许多变量。 因此,需要将微分的思想推广到多元函数(multivariate function)上。
偏导数是多元函数的导数概念的推广,它用于描述一个函数关于其中一个自变量的变化率,而将其他自变量视为常数。对于一个具有多个自变量的函数,其偏导数告诉我们,当其中一个自变量发生变化时,函数值的变化率是多少。

详细一点说明:

4.梯度
可以连结一个多元函数对其所有变量的偏导数,以得到该函数的梯度(gradient)向量。梯度是一个向量,表示多元函数在给定点处的最大变化率和变化的方向。
函数 𝑓(𝐱) 相对于 𝐱 的梯度是一个包含 𝑛 个偏导数的向量:

梯度告诉函数在某一点的变化率最快的方向。在二维空间中,梯度就是函数的偏导数构成的向量,指向函数增长最快的方向,其大小表示增长的速率。在三维空间中,梯度也是类似的概念,它是一个三维向量,指向函数增长最快的方向。
梯度在优化问题中非常有用,因为在最小化或最大化一个函数时,沿着梯度的方向函数值变化最快,可以帮助找到函数的极小值或极大值。
5.链式法则
在深度学习中,多元函数通常是复合(composite)的, 所以难以应用上述任何规则来微分这些函数。 幸运的是,链式法则可以被用来微分复合函数。

6.自动微分
深度学习框架通过自动计算导数,即自动微分(automatic differentiation)来加快求导。 实际中,根据设计好的模型,系统会构建一个计算图(computational graph), 来跟踪计算是哪些数据通过哪些操作组合起来产生输出。 自动微分使系统能够随后反向传播梯度。 这里,反向传播(backpropagate)意味着跟踪整个计算图,填充关于每个参数的偏导数。
自动计算微分的过程示例如下:
import tensorflow as tf# 变量x赋值初始值
x = tf.range(4, dtype=tf.float32)
# 存放梯度的变量,将x转换为Variable张量,方便更新。
x = tf.Variable(x)
print(x)
# 把所有计算记录在磁带上
with tf.GradientTape() as t:# 计算y=计算x和x的点积y = 2 * tf.tensordot(x, x, axes=1)
# 调用磁带的反向传播函数自动计算y关于x的每个梯度
x_grad = t.gradient(y, x)
x_grad,y,x
<tf.Variable 'Variable:0' shape=(4,) dtype=float32, numpy=array([0., 1., 2., 3.], dtype=float32)>
(<tf.Tensor: shape=(4,), dtype=float32, numpy=array([ 0., 4., 8., 12.], dtype=float32)>,<tf.Tensor: shape=(), dtype=float32, numpy=28.0>,<tf.Variable 'Variable:0' shape=(4,) dtype=float32, numpy=array([0., 1., 2., 3.], dtype=float32)>)
6.1非标量变量的反向传播
当y不是标量时,向量y关于向量x的导数的最自然解释是一个矩阵。 对于高阶和高维的y和x,求导的结果可以是一个高阶张量。
然而,虽然这些更奇特的对象确实出现在高级机器学习中(包括[深度学习中]), 但当调用向量的反向计算时,我们通常会试图计算一批训练样本中每个组成部分的损失函数的导数。
# 变量x赋值初始值
x = tf.range(4, dtype=tf.float32)
# 存放梯度的变量,将x转换为Variable张量,方便更新。
x = tf.Variable(x)
print(x)
with tf.GradientTape() as t:y = x * x
t.gradient(y, x) # 等价于y=tf.reduce_sum(x*x)
6.2分离计算
有时,希望将某些计算移动到记录的计算图之外。 例如,假设y是作为x的函数计算的,而z则是作为y和x的函数计算的。 想计算z关于x的梯度,但由于某种原因,希望将y视为一个常数, 并且只考虑到x在y被计算后发挥的作用。
这里可以分离y来返回一个新变量u,该变量与y具有相同的值, 但丢弃计算图中如何计算y的任何信息。 换句话说,梯度不会向后流经u到x。 因此,下面的反向传播函数计算z=ux关于x的偏导数,同时将u作为常数处理, 而不是z=xx*x关于x的偏导数。
# 变量x赋值初始值
x = tf.range(4, dtype=tf.float32)
# 存放梯度的变量,将x转换为Variable张量,方便更新。
x = tf.Variable(x)
print(x)
# 设置persistent=True来运行t.gradient多次
with tf.GradientTape(persistent=True) as t:y = x * xu = tf.stop_gradient(y)z = u * xx_grad = t.gradient(z, x)
print(x_grad)
x_grad == u
<tf.Variable 'Variable:0' shape=(4,) dtype=float32, numpy=array([0., 1., 2., 3.], dtype=float32)>
tf.Tensor([0. 1. 4. 9.], shape=(4,), dtype=float32)
<tf.Tensor: shape=(4,), dtype=bool, numpy=array([ True, True, True, True])>
由于记录了y的计算结果,可以随后在y上调用反向传播, 得到y=x*x关于的x的导数结果查看或者用作其它用途:
t.gradient(y, x)
<tf.Tensor: shape=(4,), dtype=float32, numpy=array([0., 2., 4., 6.], dtype=float32)>
6.3控制流的梯度计算
即使构建函数的计算图需要通过Python控制流(例如,条件、循环或任意函数调用),仍然可以计算得到的变量的梯度:
def f(a):b = a * 2while tf.norm(b) < 1000:b = b * 2if tf.reduce_sum(b) > 0:c = belse:c = 100 * breturn ca = tf.Variable(tf.random.normal(shape=()))
print(a)
with tf.GradientTape() as t:d = f(a)
d_grad = t.gradient(d, a)
print(d)
d_grad
7.概率
概率是描述随机事件发生可能性的量度。在数学上,概率通常用一个介于 0 到 1 之间的实数来表示,其中 0 表示不可能事件,1 表示必然事件。例如,掷一枚公正硬币出现正面的概率为 0.5,即 50% 的可能性。
概率可以通过频率或基于理论模型来确定。频率概率是通过观察事件发生的次数来计算的,当试验次数趋于无穷时,频率概率会趋近于一个固定值。理论概率是基于事件的可能性和相关因素来计算的,常用的方法包括古典概率、几何概率和条件概率等。
概率可以分为几种不同的类型,主要包括以下几种:
- 古典概率:也称为等可能概率,指的是在有限个等可能结果的随机试验中,某个事件发生的概率等于该事件发生的可能性除以总的可能性个数。例如,掷一个公正骰子,出现任意一个点数的概率为1/6。
- 几何概率:几何概率是指根据几何形状和尺寸计算概率的方法,通常用于连续型随机变量。例如,在一个正方形区域内随机抛一点,落在某个子区域内的概率与该子区域的面积成正比。
- 条件概率:条件概率是指在给定某个条件下事件发生的概率。如果事件 A 和事件 B 都是随机事件,且事件 B 的概率大于 0,则事件 A在事件 B 已经发生的条件下发生的概率称为事件 A 在事件 B 条件下的概率,记作 P(A|B)。
- 贝叶斯概率:贝叶斯概率是指根据先验概率和新的证据来计算更新后的概率,常用于统计推断和机器学习中。
- 频率概率:频率概率是指根据大量重复实验中事件发生的相对频率来计算概率的方法。例如,掷一枚硬币出现正面的概率可以通过大量重复掷硬币实验来估计。
把从概率分布中抽取样本的过程称为抽样(sampling)。 笼统来说,可以把分布(distribution)看作对事件的概率分配。 将概率分配给一些离散选择的分布称为多项分布(multinomial distribution)。
7.1基本概率论
检查骰子的唯一方法是多次投掷并记录结果, 对于每个骰子,我们将观察到 {1,…,6} 中的一个值。 对于每个值,一种自然的方法是将它出现的次数除以投掷的总次数, 即此事件(event)概率的估计值。 大数定律(law of large numbers)告诉我们: 随着投掷次数的增加,这个估计值会越来越接近真实的潜在概率。
%matplotlib inline
import numpy as np
import tensorflow as tf
import tensorflow_probability as tfp
from d2l import tensorflow as d2lfair_probs = tf.ones(6) / 6
counts = tfp.distributions.Multinomial(10, fair_probs).sample(500)
cum_counts = tf.cumsum(counts, axis=0)
estimates = cum_counts / tf.reduce_sum(cum_counts, axis=1, keepdims=True)d2l.set_figsize((6, 4.5))
for i in range(6):d2l.plt.plot(estimates[:, i].numpy(),label=("P(die=" + str(i + 1) + ")"))
d2l.plt.axhline(y=0.167, color='black', linestyle='dashed')
d2l.plt.gca().set_xlabel('Groups of experiments')
d2l.plt.gca().set_ylabel('Estimated probability')
d2l.plt.legend();
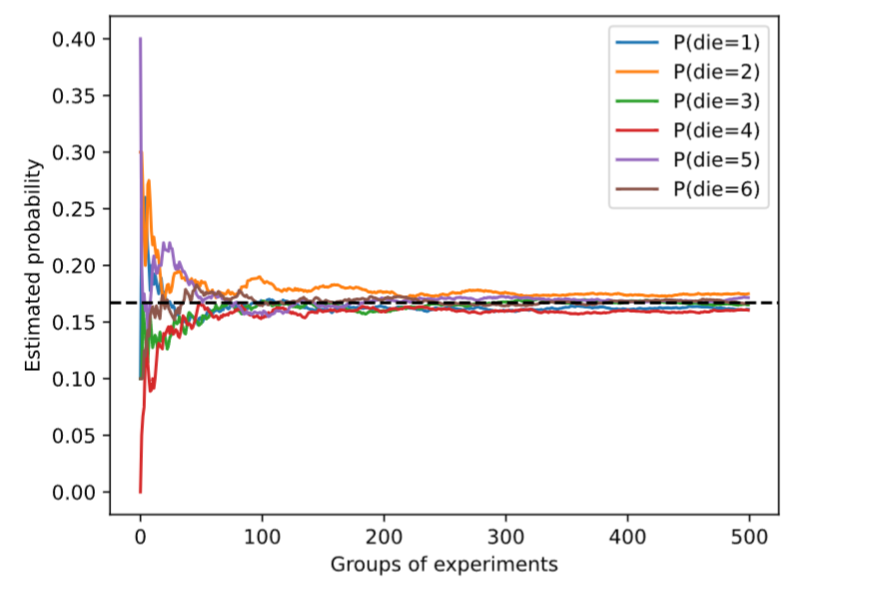
每条实线对应于骰子的6个值中的一个,并给出骰子在每组实验后出现值的估计概率。 当我们通过更多的实验获得更多的数据时,这 6条实体曲线向真实概率收敛。
对骰子进行采样,可以模拟1000次投掷。 然后,可以统计1000次投掷后,每个数字被投中了多少次。 具体来说,计算相对频率,以作为真实概率的估计。
counts = tfp.distributions.Multinomial(1000, fair_probs).sample()
counts / 1000
<tf.Tensor: shape=(6,), dtype=float32, numpy=array([0.167, 0.175, 0.143, 0.164, 0.182, 0.169], dtype=float32)>
因为是从一个公平的骰子中生成的数据,每个结果都有真实的概率 1/6 , 大约是 0.167 ,所以上面输出的估计值看起来不错。这也反映了大数定律的有效性。
概率论公理
在处理骰子掷出时,我们将集合 S={1,2,3,4,5,6} 称为样本空间(sample space)或结果空间(outcome space), 其中每个元素都是结果(outcome)。 事件(event)是一组给定样本空间的随机结果。
概率(probability)可以被认为是将集合映射到真实值的函数。 在给定的样本空间 S 中,事件 A 的概率, 表示为 𝑃(A) ,满足以下属性:

随机变量
在概率论和统计学中,随机变量是一个用来描述随机现象结果的变量,它可以取多个可能的取值,每个取值对应着一种可能的结果。随机变量可以是离散的,也可以是连续的。
- 离散随机变量:离散随机变量的取值是可数的,通常是整数。例如,抛一次硬币正面出现的次数就是一个离散随机变量,可能的取值为 0 或 1。
- 连续随机变量:连续随机变量的取值是在一个区间内的实数,取值是不可数的。例如,一个人身高就是一个连续随机变量,可以在某个范围内取任意实数值。
请注意,离散(discrete)随机变量(如骰子的每一面) 和连续(continuous)随机变量(如人的体重和身高)之间存在微妙的区别。 现实生活中,测量两个人是否具有完全相同的身高没有太大意义。 如果我们进行足够精确的测量,最终会发现这个星球上没有两个人具有完全相同的身高。 在这种情况下,询问某人的身高是否落入给定的区间,比如是否在1.79米和1.81米之间更有意义。 在这些情况下,我们将这个看到某个数值的可能性量化为密度(density)。 高度恰好为1.80米的概率为0,但密度不是0。 在任何两个不同高度之间的区间,我们都有非零的概率。
7.2处理多个随机变量
很多时候,会考虑多个随机变量。 比如,可能需要对疾病和症状之间的关系进行建模。 给定一个疾病和一个症状,比如“流感”和“咳嗽”,以某个概率存在或不存在于某个患者身上。 需要估计这些概率以及概率之间的关系,以便可以运用推断来实现更好的医疗服务。
(1)联合概率
联合概率(joint probability) 𝑃(𝐴=𝑎,𝐵=𝑏)。 给定任意值 𝑎 和 𝑏 ,联合概率可以回答: 𝐴=𝑎 和 𝐵=𝑏 同时满足的概率是多少? 请注意,对于任何 𝑎 和 𝑏 的取值, 𝑃(𝐴=𝑎,𝐵=𝑏)≤𝑃(𝐴=𝑎)。 这点是确定的,因为要同时发生 𝐴=𝑎 和 𝐵=𝑏 , 𝐴=𝑎 就必须发生, 𝐵=𝑏 也必须发生(反之亦然)。因此, 𝐴=𝑎 和 𝐵=𝑏同时发生的可能性不大于 𝐴=𝑎 或是 𝐵=𝑏 单独发生的可能性。
(2)条件概率
联合概率的不等式带来一个有趣的比率: 0≤𝑃(𝐴=𝑎,𝐵=𝑏)𝑃(𝐴=𝑎)≤1 。 我们称这个比率为条件概率(conditional probability), 并用 𝑃(𝐵=𝑏∣𝐴=𝑎) 表示它:它是 𝐵=𝑏 的概率,前提是 𝐴=𝑎已发生。
(3)贝叶斯定理
使用条件概率的定义,我们可以得出统计学中最有用的方程之一: Bayes定理(Bayes’ theorem)。 根据乘法法则(multiplication rule )可得到 𝑃(𝐴,𝐵)=𝑃(𝐵∣𝐴)𝑃(𝐴) 。 根据对称性,可得到 𝑃(𝐴,𝐵)=𝑃(𝐴∣𝐵)𝑃(𝐵) 。 假设 𝑃(𝐵)>0,求解其中一个条件变量,得到:
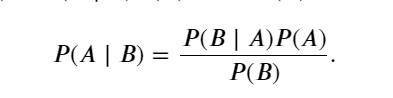
请注意,这里使用紧凑的表示法: 其中 𝑃(𝐴,𝐵) 是一个联合分布(joint distribution), 𝑃(𝐴∣𝐵)
是一个条件分布(conditional distribution)。 这种分布可以在给定值 𝐴=𝑎,𝐵=𝑏 上进行求值。
(4)边际化(边际概率)
为了能进行事件概率求和,需要求和法则(sum rule), 即 𝐵 的概率相当于计算 𝐴 的所有可能选择,并将所有选择的联合概率聚合在一起,这也称为边际化(marginalization)。 边际化结果的概率或分布称为边际概率(marginal probability) 或边际分布(marginal distribution)。:
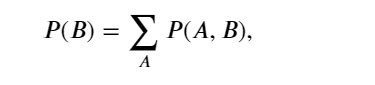
(5)独立性
依赖(dependence)与独立(independence)。 如果两个随机变量 𝐴 和 𝐵 是独立的,意味着事件 𝐴
的发生跟 𝐵 事件的发生无关。 在这种情况下,统计学家通常将这一点表述为 𝐴⊥𝐵 。 根据贝叶斯定理,马上就能同样得到 𝑃(𝐴∣𝐵)=𝑃(𝐴) 。在所有其他情况下,我们称 𝐴 和 𝐵 依赖。 比如,两次连续抛出一个骰子的事件是相互独立的。 相比之下,灯开关的位置和房间的亮度并不是依赖关系(因为可能存在灯泡坏掉、电源故障,或者开关故障)。
7.3期望与方差
为了概括概率分布的关键特征,需要一些测量方法。 一个随机变量 𝑋的期望(expectation,或平均值(average))表示为
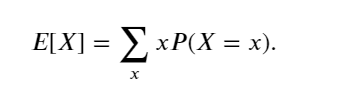
当函数 𝑓(𝑥) 的输入是从分布 𝑃 中抽取的随机变量时, 𝑓(𝑥) 的期望值为
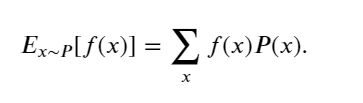
在许多情况下,希望衡量随机变量 𝑋 与其期望值的偏置。这可以通过方差来量化
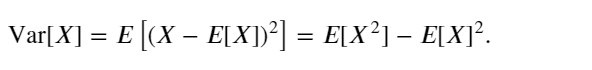
方差的平方根被称为标准差(standard deviation)。 随机变量函数的方差衡量的是:当从该随机变量分布中采样不同值 𝑥时, 函数值偏离该函数的期望的程度: