文章目录
- 一、前言
- 二、实验环境
- 三、PyTorch数据结构
- 1、Tensor(张量)
- 1. 维度(Dimensions)
- 2. 数据类型(Data Types)
- 3. GPU加速(GPU Acceleration)
- 2、张量的数学运算
- 1. 向量运算
- 2. 矩阵运算
- 3. 向量范数、矩阵范数、与谱半径详解
- 4. 一维卷积运算
- 5. 二维卷积运算
- 6. 高维张量
- 3、张量的统计计算
- 4、张量操作
- 1. 张量变形
- 2. 索引
- 3. 切片
- 4. 张量修改
- 5、张量的梯度计算
- 0. 变量(Variable)
- 1. 自动微分
- a. 单参数
- b. 多参数
- 2. 计算图
- 3. 神经网络模型
- 4. 可视化计算图结构
一、前言
本文将介绍张量的梯度计算,包括变量(Variable)、自动微分、计算图及其可视化等
二、实验环境
本系列实验使用如下环境
conda create -n DL python==3.11
conda activate DL
conda install pytorch torchvision torchaudio pytorch-cuda=12.1 -c pytorch -c nvidia
conda install pydot
三、PyTorch数据结构
1、Tensor(张量)
Tensor(张量)是PyTorch中用于表示多维数据的主要数据结构,类似于多维数组,可以存储和操作数字数据。
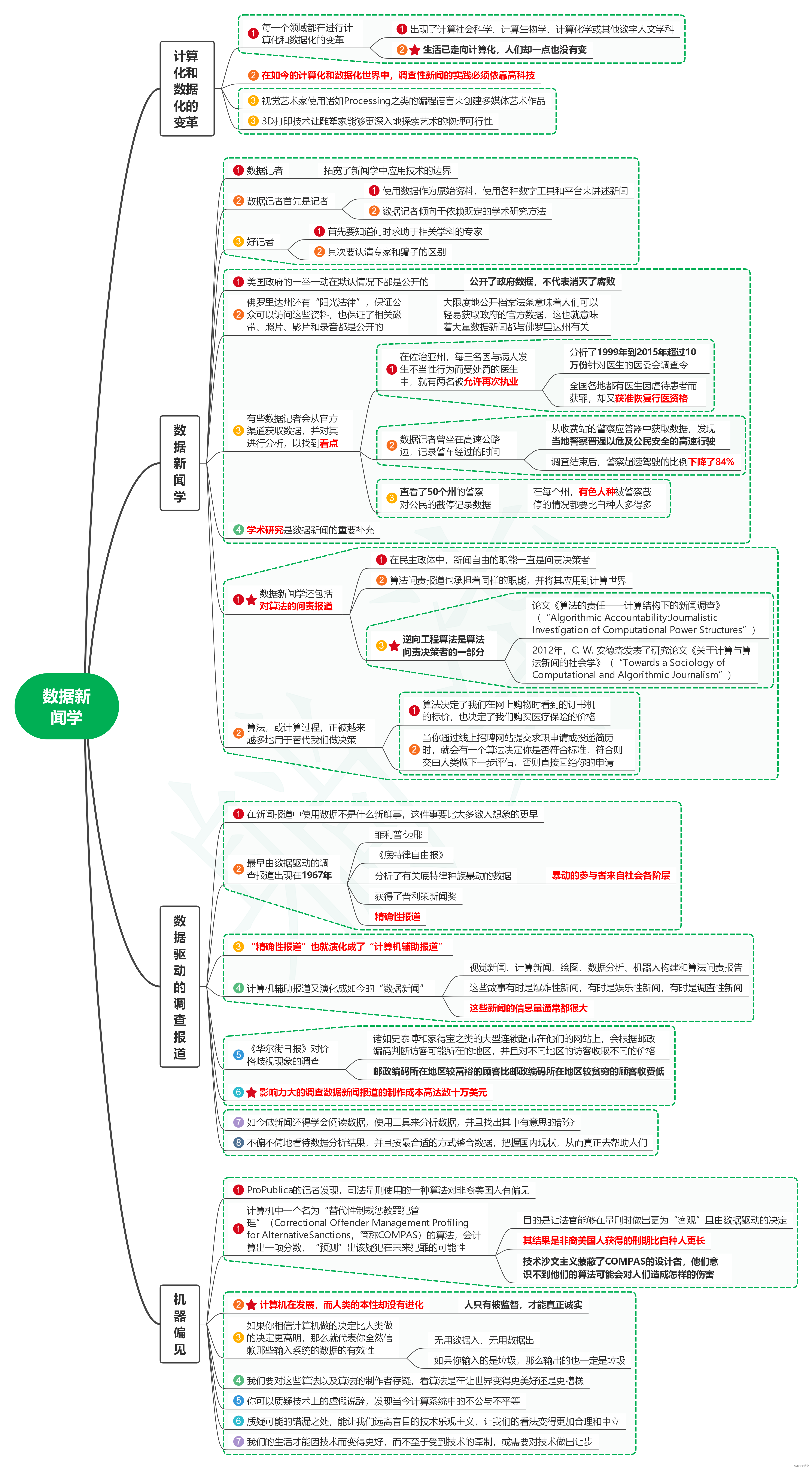
1. 维度(Dimensions)
Tensor(张量)的维度(Dimensions)是指张量的轴数或阶数。在PyTorch中,可以使用size()方法获取张量的维度信息,使用dim()方法获取张量的轴数。
2. 数据类型(Data Types)
PyTorch中的张量可以具有不同的数据类型:
- torch.float32或torch.float:32位浮点数张量。
- torch.float64或torch.double:64位浮点数张量。
- torch.float16或torch.half:16位浮点数张量。
- torch.int8:8位整数张量。
- torch.int16或torch.short:16位整数张量。
- torch.int32或torch.int:32位整数张量。
- torch.int64或torch.long:64位整数张量。
- torch.bool:布尔张量,存储True或False。
【深度学习】Pytorch 系列教程(一):PyTorch数据结构:1、Tensor(张量)及其维度(Dimensions)、数据类型(Data Types)
3. GPU加速(GPU Acceleration)
【深度学习】Pytorch 系列教程(二):PyTorch数据结构:1、Tensor(张量): GPU加速(GPU Acceleration)
2、张量的数学运算
PyTorch提供了丰富的操作函数,用于对Tensor进行各种操作,如数学运算、统计计算、张量变形、索引和切片等。这些操作函数能够高效地利用GPU进行并行计算,加速模型训练过程。
1. 向量运算
【深度学习】Pytorch 系列教程(三):PyTorch数据结构:2、张量的数学运算(1):向量运算(加减乘除、数乘、内积、外积、范数、广播机制)
2. 矩阵运算
【深度学习】Pytorch 系列教程(四):PyTorch数据结构:2、张量的数学运算(2):矩阵运算及其数学原理(基础运算、转置、行列式、迹、伴随矩阵、逆、特征值和特征向量)
3. 向量范数、矩阵范数、与谱半径详解
【深度学习】Pytorch 系列教程(五):PyTorch数据结构:2、张量的数学运算(3):向量范数(0、1、2、p、无穷)、矩阵范数(弗罗贝尼乌斯、列和、行和、谱范数、核范数)与谱半径详解
4. 一维卷积运算
【深度学习】Pytorch 系列教程(六):PyTorch数据结构:2、张量的数学运算(4):一维卷积及其数学原理(步长stride、零填充pad;宽卷积、窄卷积、等宽卷积;卷积运算与互相关运算)
5. 二维卷积运算
【深度学习】Pytorch 系列教程(七):PyTorch数据结构:2、张量的数学运算(5):二维卷积及其数学原理
6. 高维张量
3、张量的统计计算
【深度学习】Pytorch教程(九):PyTorch数据结构:3、张量的统计计算详解
4、张量操作
1. 张量变形
【深度学习】Pytorch教程(十):PyTorch数据结构:4、张量操作(1):张量变形操作
2. 索引
3. 切片
【深度学习】Pytorch 教程(十一):PyTorch数据结构:4、张量操作(2):索引和切片操作
4. 张量修改
【深度学习】Pytorch 教程(十二):PyTorch数据结构:4、张量操作(3):张量修改操作(拆分、拓展、修改)
5、张量的梯度计算
0. 变量(Variable)
Variable(变量)是早期版本中的一种概念,用于自动求导(autograd)。从PyTorch 0.4.0版本开始,Variable已经被弃用,自动求导功能直接集成在张量(Tensor)中,因此不再需要显式地使用Variable。
在早期版本的PyTorch中,Variable是一种包装张量的方式,它包含了张量的数据、梯度和其他与自动求导相关的信息。可以对Variable进行各种操作,就像操作张量一样,而且它会自动记录梯度信息。然后,通过调用.backward()方法,可以对Variable进行反向传播,计算梯度,并将梯度传播到相关的变量。
import torch
from torch.autograd import Variable# 创建一个Variable
x = Variable(torch.tensor([2.0]), requires_grad=True)# 定义一个计算图
y = x ** 2 + 3 * x + 1# 进行反向传播
y.backward()# 获取梯度
gradient = x.grad
print("梯度:", gradient) # 输出: tensor([7.])
1. 自动微分
PyTorch 使用自动微分机制来计算梯度,当定义一个 Tensor 对象时,可以通过设置 requires_grad=True 来告诉 PyTorch 跟踪相关的计算,并使用 backward() 方法来计算梯度:
a. 单参数
import torchx = torch.tensor([2.0], requires_grad=True)def f(x):return 5 * x ** 2 + 2 * x - 1# 计算函数的输出
y = f(x)# 使用backward()方法计算梯度
y.backward()# 获取梯度值
gradient = x.grad
print(gradient)
输出:
tensor([22.])
y ′ = 10 x + 2 22 = 10 ∗ 2 + 2 y'=10x+2\\22=10*2+2 y′=10x+222=10∗2+2
b. 多参数
import torchdef f(x, w, b):return 1 / (torch.exp(-(w * x + b)) + 1)# 设置输入参数
x = torch.tensor(1.0, requires_grad=True)
w = torch.tensor(0.0, requires_grad=True)
b = torch.tensor(0.0, requires_grad=True)# 计算函数f(x;w,b)的值
result = f(x, w, b)# 使用自动微分计算梯度
result.backward()
print(x.grad) # 求关于x的梯度
print(w.grad) # 求关于w的梯度
print(b.grad) # 求关于b的梯度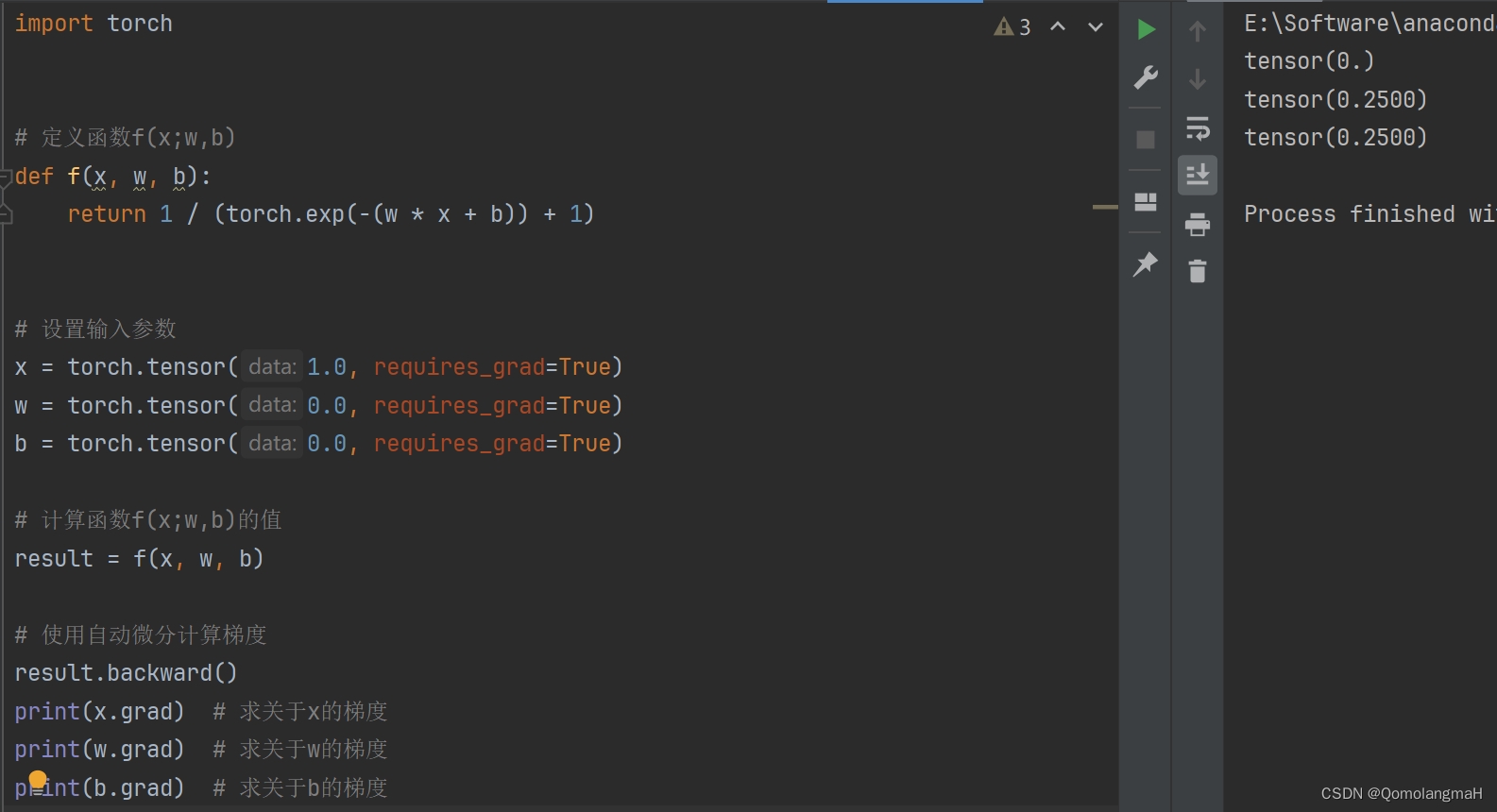
2. 计算图
计算图是一种用来表示数学运算过程的图形化结构,它将数学计算表达为节点和边的关系,提供了一种直观的方式来理解和推导复杂的数学运算过程。在深度学习中,计算图帮助我们理解模型的训练过程,直观地把握损失函数对模型参数的影响,同时为反向传播算法提供了理论基础。现代深度学习框架如 PyTorch 和 TensorFlow 都是基于计算图的理论基础构建出来的。
f ( x ; w , b ) = 1 e − ( w x + b ) + 1 f(x;w,b)=\frac{1}{e^{-(wx+b)}+1} f(x;w,b)=e−(wx+b)+11当 x = 1 , w = 0 , b = 0 x=1,w=0,b=0 x=1,w=0,b=0时
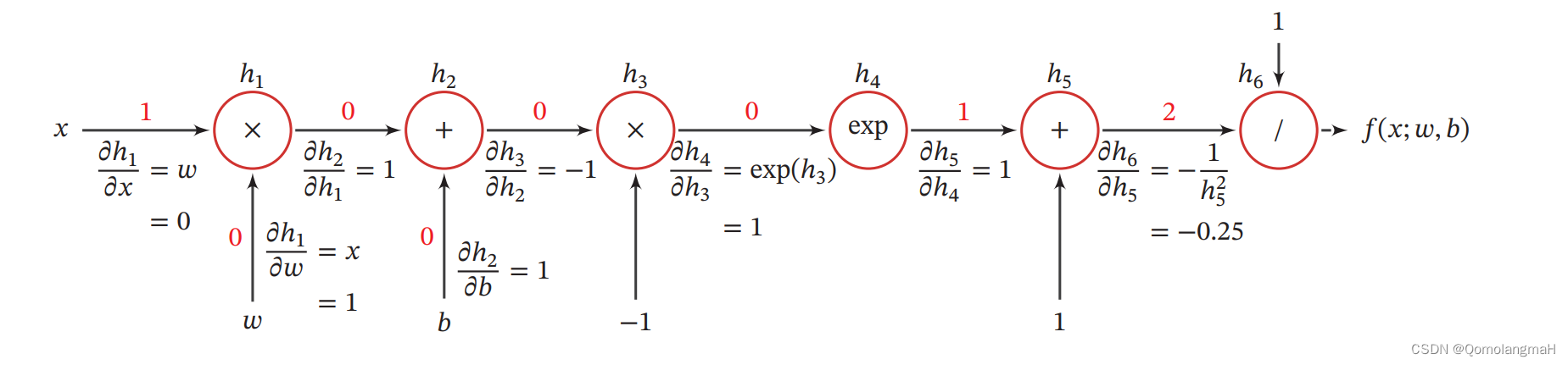

计算图包括两种节点:计算节点(Compute Node)和数据节点(Data Node)。
-
数据节点:表示输入数据、参数或中间变量,在计算图中通常用圆形结点表示。数据节点始终是叶节点,它们没有任何输入,仅表示数据。
-
计算节点:表示数学运算过程,它将输入的数据节点进行数学运算后输出结果。在计算图中通常用方形结点表示。计算节点可以有多个输入和一个输出。反向传播算法中的梯度计算正是通过计算节点来实现的。
一个完整的计算图可以分为正向传播和反向传播两个阶段:
-
正向传播(Forward Propagation):输入数据经过计算节点逐层传播,最终得到输出结果。
-
反向传播(Backward Propagation):首先根据损失函数计算输出结果与真实标签之间的误差,然后利用链式法则,逐个计算每个计算节点对应的输入的梯度,最终得到参数的梯度信息。
3. 神经网络模型
略~详见后文模块(Module) 部分
import torchclass MyModel(torch.nn.Module):def __init__(self):super(MyModel, self).__init__()def forward(self, x, w, b):return 1 / (torch.exp(-(w * x + b)) + 1)model = MyModel()# 设置输入参数
x = torch.tensor(1.0, requires_grad=True)
w = torch.tensor(0.0, requires_grad=True)
b = torch.tensor(0.0, requires_grad=True)# Forward pass
output = model(x, w, b)# Backward pass
output.backward()# Access the gradients
print(x.grad) # Gradient with respect to x
print(w.grad) # Gradient with respect to w
print(b.grad) # Gradient with respect to b
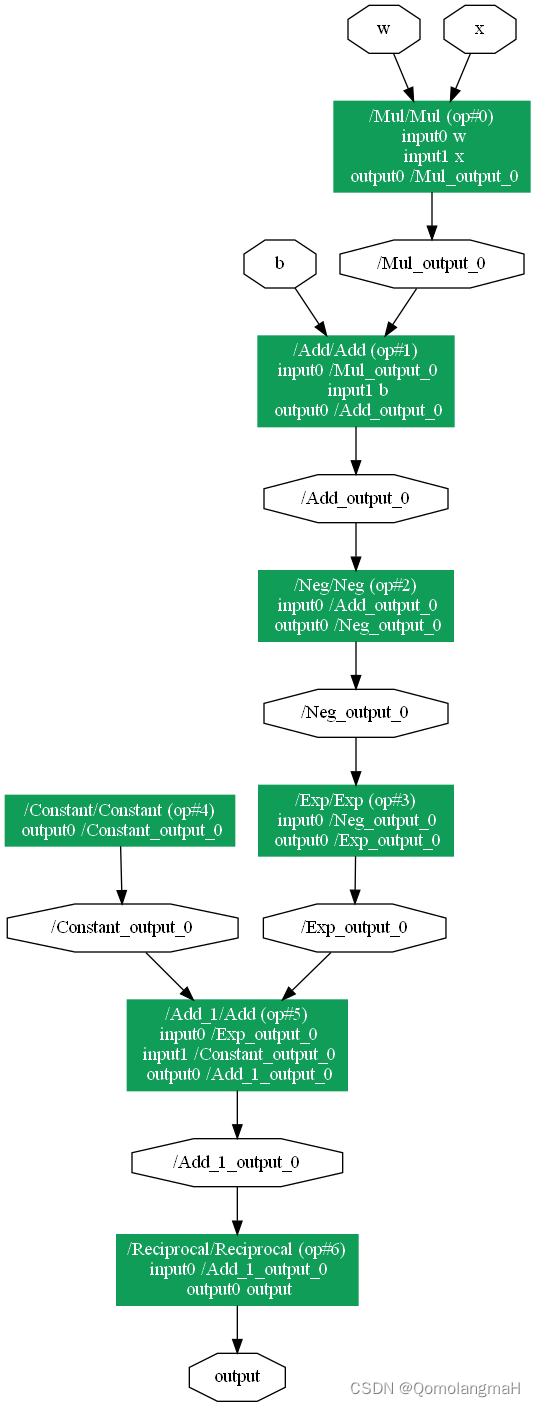
4. 可视化计算图结构
以下内容完全由GPT生成:
import torch
import onnx
from onnx.tools.net_drawer import GetPydotGraph
import pydotclass MyModel(torch.nn.Module):def __init__(self):super(MyModel, self).__init__()def forward(self, x, w, b):return 1 / (torch.exp(-(w * x + b)) + 1)model = MyModel()x = torch.tensor(1.0, requires_grad=True)
w = torch.tensor(0.0, requires_grad=True)
b = torch.tensor(0.0, requires_grad=True)# 导出为ONNX格式
torch.onnx.export(model, (x, w, b), "f.onnx", verbose=True, input_names=["x", "w", "b"], output_names=["output"])# 可视化计算图结构
model = onnx.load("f.onnx")
pydot_graph = GetPydotGraph(model.graph, name=model.graph.name, rankdir="TB"# rankdir="LR") # Set rankdir to "LR" for left to right orientation
pydot_graph.write_dot("f_computation_graph.dot")# 将dot文件转换为PNG格式的图像
(graph,) = pydot.graph_from_dot_file('f_computation_graph.dot')
graph.write_png('f_computation_graph.png')