·
目录
- 一、说明
- 二、算法
- 三、准备处理
- 四、高斯核
- 五、带通滤波器
- 六、复杂的可操纵金字塔
- 七、最终预处理步骤
- 八、执行处理
- 九、金字塔的倒塌
- 十、可视化结果
- 十一、结论
一、说明
日常物体会产生人眼无法察觉的微妙运动。在视频中,这些运动的幅度小于一个像素,但是,我们可以使用基于相位的视频放大来揭示这些不可见的运动,在这篇文章中,我们将用 Python 从头开始编码!如果您对理论感兴趣,我们在上一篇文章中对此进行了介绍。结果示例如图 6 所示。
- 第 1 部分:背景和理论
- 第 2 部分:Python 实现(这一部分)

吉列尔莫·费拉 (Guillermo Ferla)在Unsplash上拍摄的照片
二、算法
我们在第 1 部分中介绍了高级算法,但它确实没有提供足够的实现细节。我们将使用的算法如下所示。

运动放大算法。资料来源:作者。
大部分处理发生在步骤 3 中,我们进行实际运动放大的部分是蓝色文本。相位变化对应于视频帧序列中的局部运动。在接下来的三节中,我们将分解该算法并从头开始实现它。
三、准备处理
在本节中,我们将介绍步骤 0-2。
第一个任务是获取视频帧,为了简单起见,我们将它们全部加载到内存中。我们还需要获取视频采样率,这对于 OpenCV 来说相当简单。在本教程中,我们将图像转换为 YIQ 颜色空间并仅处理 Luma 通道,请参阅笔记本以获取完整代码。
scale_factor = 1.0 # 可选:缩放图像,使其适合内存:)bgr_frames = []
frames = [] # 处理
帧 cap = cv2.VideoCapture(video_path) # 视频采样率
fs = cap.get(cv2.CAP_PROP_FPS) idx = 0 while (cap.isOpened()): ret, frame = cap.read() # 如果帧读取正确 ret 为 True if not ret: break if idx == 0 : og_h, og_w, _ = frame.shape w = int (og_w*scale_factor) h = int (og_h*scale_factor) # 存储原始帧bgr_frames.append(frame) # 获取归一化的 YIQ 帧rgb = np.float32(cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)/ 255 ) yiq = rgb2yiq(rgb) # 追加亮度通道frames.append(cv2.resize(yiq[:, :, 0 ], (w, h)) idx += 1
以下是我们将使用的 Luma 通道帧的示例:
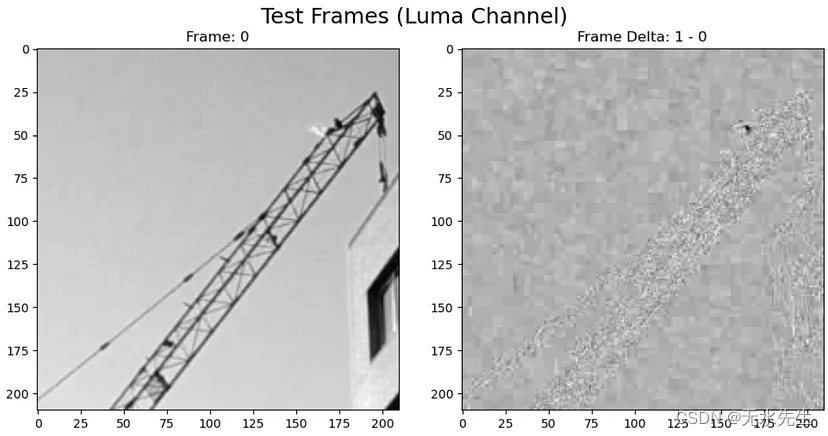
图 1。右:帧 0 的亮度通道。左:帧 1 和 0 的亮度通道之间的差异。来源:作者。
我们可以在图 1 右侧的帧差异中看到起重机的微弱轮廓。这表明这些像素可能会发生一些有趣的事情,但这很可能归因于噪声,因为我们得到了类似的建筑物轮廓移动。该算法能够通过使用许多视频帧来提取小于像素的细微运动。下一个任务是设置超参数:
# 时间带通滤波器频率
f_lo = 0.2 f_hi = 0.25 # 加权幅度模糊强度
sigma = 5.0 # 衰减其他频率
attenuate = True # 相位放大因子
phase_mag = 25.0
四、高斯核
现在让我们继续预处理并获取幅度加权模糊的高斯核。如第 1 部分所述,这是可选的,没有它我们仍然可以获得良好的结果。
# 确保 ksize 为奇数,否则过滤将花费太长时间
# 请参阅以下警告:https://pytorch.org/docs/stable/ generated/torch.nn.function.conv2d.htmlksize = np. max (( 3 , np.ceil( 4 *sigma) - 1 )).astype( int )
if ((ksize % 2 ) != 1 ): ksize += 1 # 获取高斯模糊内核仅供参考
gk = cv2. getGaussianKernel(ksize=ksize, sigma=sigma)
gauss_kernel = torch.tensor(gk @ gk.T). 类型(torch.float32) \ .to(设备) \ .unsqueeze( 0 ) \ .unsqueeze( 0 )
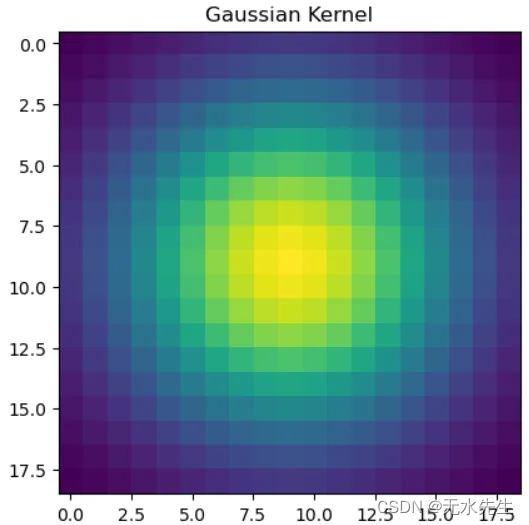
图 2. 用于幅度加权模糊的高斯核。资料来源:作者。
五、带通滤波器
对于带通滤波器,我们将使用scipy.signal构建FIR 滤波器。我们需要做的第一件事是将我们的频率标准化为奈奎斯特速率,这基本上意味着标准化后有效频率的范围将在 [0–1] 之间。任何大于 1 的归一化频率都会出现混叠。
from scipy import signal # 将频率标准化为奈奎斯特速率
norm_f_lo = f_lo / fs * 2norm_f_hi= f_hi / fs * 2 # 获取带通脉冲响应
bandpass = signal.firwin(numtaps= len (frames), cutoff=[norm_f_lo,norm_f_hi] , pass_zero= False ) # 只要包含采样率 fs,我们就可以传递非标准化频率
# bandpass = signal.firwin(numtaps=len(frames),
# cutoff=[f_lo, f_hi],
# pass_zero=False,
# fs =fs) # 获取频域传递函数
transfer_function = torch.fft.fft( torch.fft.ifftshift(torch.tensor(bandpass))).to(device) \ . 类型(torch.complex64)
Transfer_function = torch.tile(transfer_function, [ 1 , 1 , 1 , 1 ]).permute( 0 , 3 , 1 , 2 )
在继续之前,让我们看一下滤波器的频域响应。
norm_freqs, response = signal.freqz(bandpass)
freqs = norm_freqs / np.pi * fs/ 2 _, ax = plt.subplots(2, 1, figsize=(15, 7))
ax[0].plot(freqs, 20*np.log10(np.abs(response)));
ax[0].set_title("Frequency Response");ax[1].plot(freqs, np.angle(response));
ax[1].set_title("Phase Response");
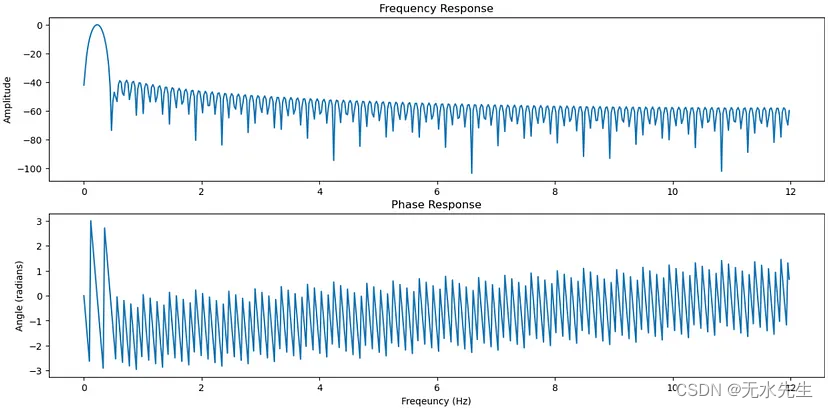
图 3. 带通 FIR 滤波器的频域响应。资料来源:作者。
上图显示了我们的频率响应,我们可以看到该频段大致对应于我们最初设置的 0.2–0.25 频率。
六、复杂的可操纵金字塔
现在我们可以获得复杂的可转向金字塔类,并且如第 1 部分中所述,亚倍频程滤波器可以实现更好的运动放大,因此我们选择半倍频程滤波器。
max_depth = int(np.floor(np.log2(np.min(np.array(ref_frame.shape)))) - 2)
csp = SteerablePyramid(depth=max_depth, orientations=8, filters_per_octave=2, twidth=0.75, complex_pyr=True)
这是频率空间中所有定向子带的划分,红色较高的值是由于滤波器的重叠造成的。可操纵金字塔分解过于完整,这意味着它们包含足够的信息来重建图像。复杂可操纵金字塔仅捕获正频率,因为负频率可以通过复杂共轭获得。
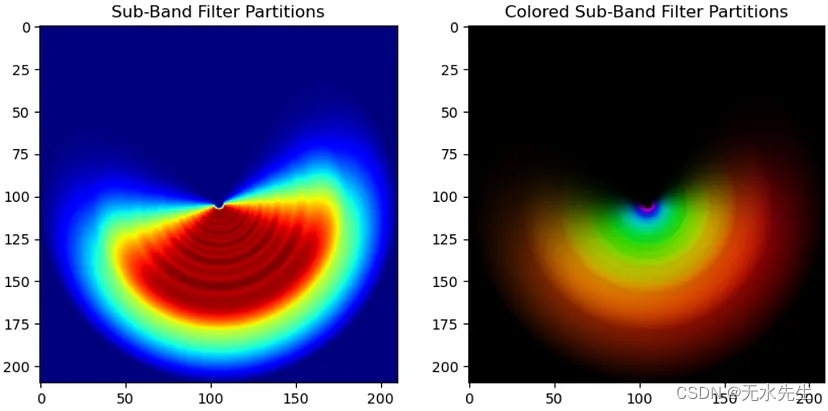
图 4. 频率空间中所有复杂可控滤波器的定向子带划分。左:是所有子带滤波器的总和,以显示重叠的强度。右:颜色编码的子带滤波器。资料来源:作者。
七、最终预处理步骤
接下来我们将过滤器和视频帧转换为 PyTorch 张量:
filters_tensor = torch.tensor(np.array(filters)).type(torch.float32).to(device)
frames_tensor = torch.tensor(np.array(frames)).type(torch.float32).to(device)
然后我们对视频帧进行离散傅里叶变换(DFT):
video_dft = torch.fft.fftshift(torch.fft.fft2(frames_tensor, dim=(1,2))).type(torch.complex64) \.to(device)
最后我们创建一个张量来存储运动放大帧的 DFT。
recon_dft = torch.zeros((len(frames), h, w), dtype=torch.complex64).to(device)
八、执行处理
本节介绍步骤 3
现在我们终于可以开始处理了,我们的外循环将包含金字塔过滤器。由于我们使用 PyTorch,我们可以方便地在 GPU 上并行化。我们要做的第一件事是创建一个张量来存储相位增量,即当前帧和参考帧的相位之间的差异。
Phase_deltas = torch.zeros((batch_size, len (frames), h, w), dtype=torch.complex64).to(device)
滤波器上的循环不包括高通和低通分量,我们将在主处理后将它们添加回来。这是第 3 步的完整代码块:
for level in range(1, len(filters) - 1, batch_size):# get batch indicesidx1 = levelidx2 = level + batch_size# get current filter batchfilter_batch = filters_tensor[idx1:idx2]## get reference frame pyramid and phase (DC)ref_pyr = build_level_batch(video_dft[ref_idx, :, :].unsqueeze(0), filter_batch)ref_phase = torch.angle(ref_pyr)## Get Phase Deltas for each framefor vid_idx in range(num_frames):curr_pyr = build_level_batch(video_dft[vid_idx, :, :].unsqueeze(0), filter_batch)# unwrapped phase delta_delta = torch.angle(curr_pyr) - ref_phase # get phase delta wrapped to [-pi, pi]phase_deltas[:, vid_idx, :, :] = ((torch.pi + _delta) \% 2*torch.pi) - torch.pi## Temporally Filter the phase deltas# Filter in Frequency Domain and convert back to phase spacephase_deltas = torch.fft.ifft(transfer_function \* torch.fft.fft(phase_deltas, dim=1), dim=1).real## Apply Motion Magnificationsfor vid_idx in range(num_frames):curr_pyr = build_level_batch(video_dft[vid_idx, :, :].unsqueeze(0), filter_batch)delta = phase_deltas[:, vid_idx, :, :]## Perform Amplitude Weighted Blurringif sigma != 0:amplitude_weight = torch.abs(curr_pyr) + eps# Torch Functional Approach (faster)weight = F.conv2d(input=amplitude_weight.unsqueeze(1), weight=gauss_kernel, padding='same').squeeze(1)delta = F.conv2d(input=(amplitude_weight * delta).unsqueeze(1), weight=gauss_kernel, padding='same').squeeze(1) # get weighted Phase Deltasdelta /= weight## Modify phase variationmodifed_phase = delta * phase_mag## Attenuate other frequencies by scaling magnitude by reference phaseif attenuate:curr_pyr = torch.abs(curr_pyr) * (ref_pyr/torch.abs(ref_pyr)) ## apply modified phase to current level pyramid decomposition# if modified_phase = 0, then no change!curr_pyr = curr_pyr * torch.exp(1.0j*modifed_phase) # ensures correct type casting## accumulate reconstruced levelsrecon_dft[vid_idx, :, :] += recon_level_batch(curr_pyr, filter_batch).sum(dim=0)
让我们逐步介绍这一点,我们要做的第一件事是获取当前批次的过滤器。所以我们一次只建造金字塔的一部分,而不是一次建造整个金字塔。
# get batch indices
idx1 = level
idx2 = level + batch_size# get current filter batch
filter_batch = filters_tensor[idx1:idx2]
在下一步中,我们将构建参考金字塔并获取滤波器批次的参考相位。
## get reference frame pyramid and phase (DC)
ref_pyr = build_level_batch(video_dft[ref_idx, :, :].unsqueeze(0), filter_batch)
ref_phase = torch.angle(ref_pyr)
在下一步中,我们进入第一个内部循环,迭代所有视频帧。此步骤的主要目的是获取当前滤波器批次的所有帧的相位增量。
## Get Phase Deltas for each frame
for vid_idx in range(num_frames):# compute pyramid decomposition -> OPTIONALLY store in data structurecurr_pyr = build_level_batch(video_dft[vid_idx, :, :].unsqueeze(0), filter_batch)# unwrapped phase delta_delta = torch.angle(curr_pyr) - ref_phase # get phase delta wrapped to [-pi, pi]phase_deltas[:, vid_idx, :, :] = ((torch.pi + _delta) \% 2*torch.pi) - torch.pi
该循环的最后一行确保相位增量被包裹到[-π, π]。下一步是在频域中执行时间带通滤波,我们使用下面的单线来执行此操作,其中我们采用逆 DFT 返回到时域。
## Temporally Filter the phase deltas
# Filter in Frequency Domain and convert back to phase space
phase_deltas = torch.fft.ifft(transfer_function \* torch.fft.fft(phase_deltas, dim=1), dim=1).real
现在我们准备开始修改运动,我们进入第二个循环,再次迭代视频帧。我们要做的第一件事是获取批量的金字塔级别及其相应的过滤相位增量。然后我们可以选择执行幅度加权模糊,这在第 1 部分中进行了解释。
## Apply Motion Magnifications
for vid_idx in range(num_frames):# rebuild level or grab from stored tensorcurr_pyr = build_level_batch(video_dft[vid_idx, :, :].unsqueeze(0), filter_batch)delta = phase_deltas[:, vid_idx, :, :]## Perform Amplitude Weighted Blurringif sigma != 0:amplitude_weight = torch.abs(curr_pyr) + eps# Torch Functional Approach (faster)weight = F.conv2d(input=amplitude_weight.unsqueeze(1), weight=gauss_kernel, padding='same').squeeze(1)delta = F.conv2d(input=(amplitude_weight * delta).unsqueeze(1), weight=gauss_kernel, padding='same').squeeze(1) # get weighted Phase Deltasdelta /= weight
接下来,我们实际上可以修改当前滤镜批次中每一帧的运动。该片段的秒部分有一些我们尚未涉及的内容,那就是频率衰减。
## Modify phase variation
modifed_phase = delta * phase_mag## Attenuate other frequencies by scaling magnitude by reference phase
if attenuate:curr_pyr = torch.abs(curr_pyr) * (ref_pyr/torch.abs(ref_pyr))
频率衰减消除了我们想要修改的频率之外的所有频率,但是如何呢?它通过首先获取当前金字塔分解的幅度来实现这一点,该分解消除了所有相位信息,但我们知道没有相位信息我们无法重建图像。因此,我们需要添加某种相位信息,我们选择添加直流相位(或参考帧相位),这是通过乘以归一化参考帧来完成的。
然后,我们可以将修改后的阶段添加到当前的金字塔批次中。我们通过将相位放入复指数中并将其与当前金字塔相乘来实现此目的。
## apply modified phase to current level pyramid decomposition
# if modified_phase = 0, then no change!
curr_pyr = curr_pyr * torch.exp(1.0j*modifed_phase) # ensures correct type casting
然后,我们重建金字塔以获得修改后的金字塔批次的 DFT 并将其累积到我们的结果张量中。
## accumulate reconstruced levels
recon_dft[vid_idx, :, :] += recon_level_batch(curr_pyr, filter_batch).sum(dim=0)
九、金字塔的倒塌
本节涵盖步骤 4 和 5
现在我们可以讨论重建,我们需要做的第一件事是重新合并高通和低通组件。我发现高通组件对于精确重建并不重要,因此您可以选择将其忽略。
# adding hipass component seems to cause bad artifacts and leaving
# it out doesn't seem to impact the overall quality
hipass = filters_tensor[0]
lopass = filters_tensor[-1]## add back lo and hi pass components
for vid_idx in range(num_frames):# accumulate Lo Pass Componentscurr_pyr_lo = build_level(video_dft[vid_idx, :, :], lopass)dft_lo = torch.fft.fftshift(torch.fft.fft2(curr_pyr_lo))recon_dft[vid_idx, :, :] += dft_lo*lopass# OPTIONAL accumulate Lo Pass Componentscurr_pyr_hi = build_level(video_dft[vid_idx, :, :], hipass)dft_hi = torch.fft.fftshift(torch.fft.fft2(curr_pyr_hi)) recon_dft[vid_idx, :, :] += dft_hi*hipass
现在我们可以在所有帧上执行逆 DFT,这是重建的最后一步。
result_video = torch.fft.ifft2(torch.fft.ifftshift(recon_dft, dim=(1,2)), dim=(1,2)).real
result_video = result_video.cpu() # Remove from CUDA
十、可视化结果
我们可以为每一帧创建并排比较图像。

图 5.每个修改后的视频帧的并排比较。资料来源:作者。
我们甚至可以创建一个 GIF,我们只处理与图像亮度相对应的 Luma 通道。这通常足以提供良好的结果,而不是处理所有通道。

图 6. 基于相位的运动处理结果的 GIF。资料来源:作者。
可视化细节
现在我们已经看到了实际结果,让我们看看到底发生了什么。这是一个执行此操作的图像,生成这些图像的代码位于笔记本的最后部分。
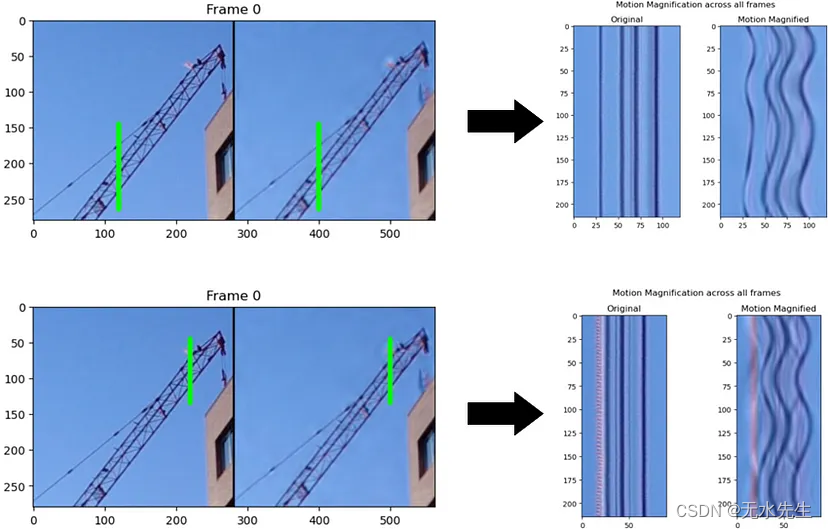
图 6. 所有帧的详细运动放大。资料来源:作者。
绿线显示了我们正在检查的单个像素线,我们可以可视化这些像素线在原始视频和处理后的视频中如何变化,并进行并排比较。在图6的右侧,我们可以看到原始视频中起重机的结构在整个序列中显然没有明显的运动,但放大的一侧确实显示出运动!更好的是,我们可以看到两个不同区域的放大运动是不同的,这表明该技术可以适应局部运动。换句话说,我们不仅仅是应用无意识的放大系数,而是根据物体的实际移动方式来放大运动。这表明该技术并不是一种奇特的视觉效果,但它确实是运动的视觉显微镜。
十一、结论
实现基于相位的运动放大是一种视频处理技术,能够放大看似静态视频中难以察觉的运动。由于金字塔分解量较大,该技术的计算成本很高,但 GPU 实现能够极大地加快该过程,从使用纯 numpy 实现的 5 分钟以上到 6GB GPU 上的不到 30 秒。
结果并不完美,但处理能够清楚地放大原本看不见的运动。有一些新的基于深度学习的方法能够提供更清晰的结果。
感谢您阅读到最后!如果您发现这篇文章有用,请考虑鼓掌👏它确实可以帮助其他可能也觉得有用的人
链接:
源视频可以在这里找到:http 😕/people.csail.mit.edu/nwadhwa/phase-video/
本教程的 Github 存储库:https 😕/github.com/itberrios/phase_based
参考
[1] 哈维尔·波蒂利亚和埃罗·西蒙切利。(2000)。基于复小波系数联合统计的参数化纹理模型。国际计算机视觉杂志。40. 10.1023/A:1026553619983。
[2] Wadhwa, N.、Rubinstein, M.、Durand, F. 和 Freeman, WT (2013)。基于相位的视频运动处理。基于相位的视频运动处理。https://people.csail.mit.edu/nwadhwa/phase-video/
[3] https://rxian.github.io/phase-video/









![[AutoSar]BSW_Com03 DBC详解 (一)](https://img-blog.csdnimg.cn/direct/418aa8b67bd741d7b04ab4c22a2b5837.png)