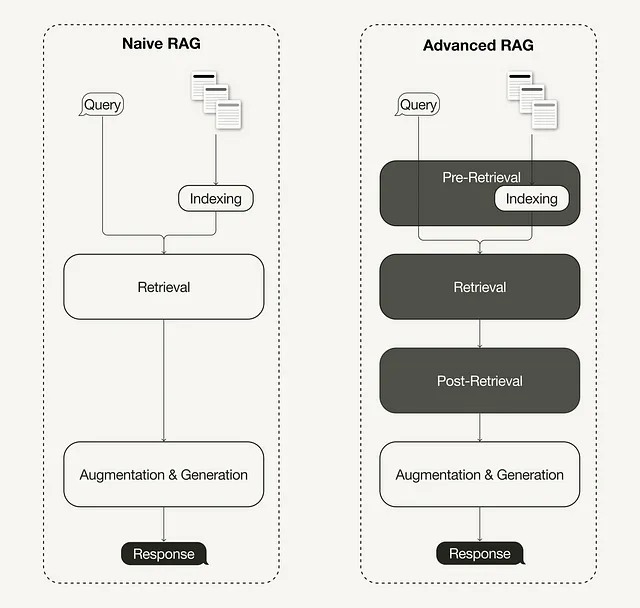
最近关于检索增强生成进行了调查,总结了三种最近发展的范式:
- Naive RAG(简单RAG)
- Advanced RAG(高级RAG)
- Modular RAG(模块化RAG)

本文首先讨论这些技术,接着分享如何使用 Python 中的 Llamaindex 实现一个简单的 RAG ,然后将其改进为一个包含以下高级 RAG 技术的高级 RAG 的全流程:
- 检索前优化:句子窗口检索
- 检索优化:混合搜索
- 检索后优化:重新排序
更多技术可以加入我们的讨论群
技术交流
前沿技术资讯、算法交流、求职内推、算法竞赛、面试交流(校招、社招、实习)等、与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度等名校名企开发者互动交流~
我们建了大模型技术交流群, 想要进交流群、获取完整源码&资料、提升技术的同学,可以直接加微信号:mlc2060。加的时候备注一下:研究方向 +学校/公司+CSDN,即可。然后就可以拉你进群了。
方式①、微信搜索公众号:机器学习社区,后台回复:技术交流
方式②、添加微信号:mlc2060,备注:技术交流
通俗易懂讲解大模型系列
-
做大模型也有1年多了,聊聊这段时间的感悟!
-
用通俗易懂的方式讲解:大模型算法工程师最全面试题汇总
-
用通俗易懂的方式讲解:不要再苦苦寻觅了!AI 大模型面试指南(含答案)的最全总结来了!
-
用通俗易懂的方式讲解:我的大模型岗位面试总结:共24家,9个offer
-
用通俗易懂的方式讲解:大模型 RAG 在 LangChain 中的应用实战
-
用通俗易懂的方式讲解:一文讲清大模型 RAG 技术全流程
-
用通俗易懂的方式讲解:如何提升大模型 Agent 的能力?
-
用通俗易懂的方式讲解:ChatGPT 开放的多模态的DALL-E 3功能,好玩到停不下来!
-
用通俗易懂的方式讲解:基于扩散模型(Diffusion),文生图 AnyText 的效果太棒了
-
用通俗易懂的方式讲解:在 CPU 服务器上部署 ChatGLM3-6B 模型
-
用通俗易懂的方式讲解:使用 LangChain 和大模型生成海报文案
-
用通俗易懂的方式讲解:ChatGLM3-6B 部署指南
-
用通俗易懂的方式讲解:使用 LangChain 封装自定义的 LLM,太棒了
-
用通俗易懂的方式讲解:基于 Langchain 和 ChatChat 部署本地知识库问答系统
-
用通俗易懂的方式讲解:在 Ubuntu 22 上安装 CUDA、Nvidia 显卡驱动、PyTorch等大模型基础环境
-
用通俗易懂的方式讲解:Llama2 部署讲解及试用方式
-
用通俗易懂的方式讲解:基于 LangChain 和 ChatGLM2 打造自有知识库问答系统
-
用通俗易懂的方式讲解:一份保姆级的 Stable Diffusion 部署教程,开启你的炼丹之路
-
用通俗易懂的方式讲解:对 embedding 模型进行微调,我的大模型召回效果提升了太多了
-
用通俗易懂的方式讲解:LlamaIndex 官方发布高清大图,纵览高级 RAG技术
-
用通俗易懂的方式讲解:为什么大模型 Advanced RAG 方法对于AI的未来至关重要?
-
用通俗易懂的方式讲解:使用 LlamaIndex 和 Eleasticsearch 进行大模型 RAG 检索增强生成
-
用通俗易懂的方式讲解:基于 Langchain 框架,利用 MongoDB 矢量搜索实现大模型 RAG 高级检索方法
-
用通俗易懂的方式讲解:使用Llama-2、PgVector和LlamaIndex,构建大模型 RAG 全流程
高级 RAG
随着 RAG 领域的最新进展,高级RAG已经成为一种新范式,针对简单 RAG 范式的一些局限性进行了有针对性的增强。
正如最近一项调查[1]所总结的,高级RAG技术可以分为三类:检索前优化、检索优化和检索后优化。
检索前优化
检索前优化集中在数据索引优化和查询优化上。数据索引优化技术旨在以有助于提高检索效率的方式存储数据,例如 [1]:
- 滑动窗口使用片段之间的重叠,是最简单的技术之一。
- 提高数据粒度应用数据清洗技术,例如删除无关信息、确认事实准确性、更新过时信息等。
- 添加元数据,如日期、目的或章节,用于过滤目的。
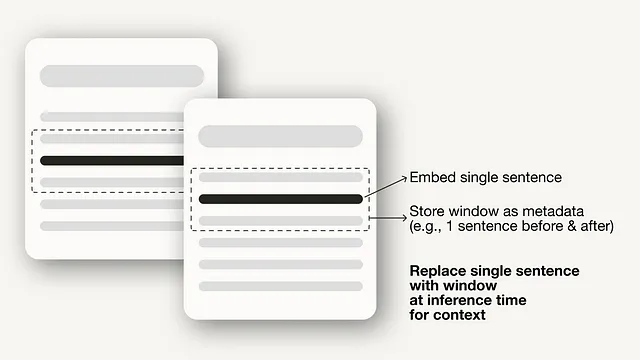
- 优化索引结构涉及不同的策略来索引数据,例如调整片段大小或使用多索引策略。本文将实现的一项技术是句子窗口检索,它将单个句子嵌入到检索中,并在推断时用更大的文本窗口替换它们。
此外,检索前技术不仅限于数据索引,还可以涉及推理时的技术,如查询路由、查询重写和查询扩展。
检索优化
检索阶段的目标是确定最相关的上下文。通常,检索基于向量搜索,它计算查询与索引数据之间的语义相似性。因此,大多数检索优化技术都围绕嵌入模型展开 [1]:
- 微调嵌入模型,将嵌入模型定制为特定领域的上下文,特别是对于术语不断演化或罕见的领域。例如,BAAI/bge-small-en是一个高性能的嵌入模型,可以进行微调(请参阅微调指南)。
- 动态嵌入根据单词的上下文进行调整,而静态嵌入则为每个单词使用单一向量。例如,OpenAI的embeddings-ada-02是一个复杂的动态嵌入模型,可以捕获上下文理解。[1]
除了向量搜索之外,还有其他检索技术,例如混合搜索,通常是指将向量搜索与基于关键字的搜索相结合的概念。如果您的检索需要精确的关键字匹配,则此检索技术非常有益。
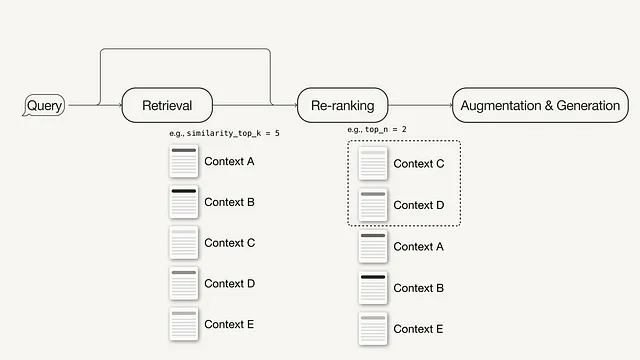
检索后优化
对检索到的上下文进行额外处理可以帮助解决一些问题,例如超出上下文窗口限制或引入噪声,从而阻碍对关键信息的关注。在RAG调查中总结的检索后优化技术包括:
- 提示压缩:通过删除无关内容并突出重要上下文,减少整体提示长度。
- 重新排序:使用机器学习模型重新计算检索到的上下文的相关性得分。
先决条件
本节讨论了在本文中跟随所需的软件包和API密钥。
所需软件包
本文将使用 Python 在 LlamaIndex 中实现一个简单的和一个高级的RAG管道。
pip install llama-index
在本文中,我们将使用LlamaIndex v0.10。如果您正在从较旧的LlamaIndex版本升级,您需要运行以下命令以正确安装和运行LlamaIndex:
pip uninstall llama-index
pip install llama-index --upgrade --no-cache-dir --force-reinstall
LlamaIndex 提供了将向量嵌入存储在JSON文件中进行持久存储的选项,这对于快速原型设计是很好的。但是,由于高级RAG技术旨在用于生产环境的应用,我们将使用向量数据库进行持久存储。
除了存储向量嵌入之外,我们还需要元数据存储和混合搜索功能。因此,我们将使用支持这些功能的开源向量数据库 Weaviate(v3.26.2)。
pip install weaviate-client llama-index-vector-stores-weaviate
API密钥
我们将使用 Weaviate 嵌入式,您可以在不注册API密钥的情况下免费使用。但是,本教程使用了来自OpenAI的嵌入模型和LLM,您将需要一个OpenAI API密钥。要获得API密钥,您需要一个OpenAI帐户,然后在API密钥下“创建新的密钥”。
接下来,在根目录中创建一个名为 .env 的本地文件,并在其中定义您的API密钥:
OPENAI_API_KEY="<YOUR_OPENAI_API_KEY>"
然后,您可以使用以下代码加载您的API密钥:
# !pip install python-dotenv
import os
from dotenv import load_dotenv,find_dotenvload_dotenv(find_dotenv())
使用 LlamaIndex 实现简单RAG
本节讨论了如何使用 LlamaIndex 实现简单的RAG管道。您可以在这个 Jupyter Notebook 中找到整个简单RAG管道。
步骤 1:定义嵌入模型和LLM
首先,您可以在全局设置对象中定义一个嵌入模型和LLM。这样做意味着您不必再次在代码中明确指定模型。
嵌入模型:用于为文档块和查询生成向量嵌入。
LLM:用于根据用户查询和相关上下文生成答案。
from llama_index.embeddings.openai import OpenAIEmbedding
from llama_index.llms.openai import OpenAI
from llama_index.core.settings import SettingsSettings.llm = OpenAI(model="gpt-3.5-turbo", temperature=0.1)
Settings.embed_model = OpenAIEmbedding()
步骤 2:加载数据
接下来,您将在根目录中创建一个名为 data 的本地目录,并从LlamaIndex GitHub存储库(MIT许可证)中下载一些示例数据。
!mkdir -p 'data'
!wget 'https://raw.githubusercontent.com/run-llama/llama_index/main/docs/examples/data/paul_graham/paul_graham_essay.txt' -O 'data/paul_graham_essay.txt'
然后,您可以加载数据以进行进一步处理:
from llama_index.core import SimpleDirectoryReader# Load data
documents = SimpleDirectoryReader(input_files=["./data/paul_graham_essay.txt"]
).load_data()
步骤 3:将文档分块成节点
由于整个文档太大,无法适应LLM的上下文窗口,因此您需要将其分割成更小的文本块,称为节点。您可以使用 SimpleNodeParser 将加载的文档解析为节点,并定义块大小为 1024。
from llama_index.core.node_parser import SimpleNodeParsernode_parser = SimpleNodeParser.from_defaults(chunk_size=1024)# Extract nodes from documents
nodes = node_parser.get_nodes_from_documents(documents)
步骤 4:构建索引
接下来,您将构建一个索引,该索引将所有外部知识存储在Weaviate中,这是一个开源的向量数据库。
首先,您需要连接到Weaviate实例。在本例中,我们使用的是Weaviate Embedded,它允许您在Notebooks中免费进行实验,而无需API密钥。对于生产就绪的解决方案,建议您自己部署Weaviate,例如通过Docker或利用托管服务。
import weaviate# Connect to your Weaviate instance
client = weaviate.Client(embedded_options=weaviate.embedded.EmbeddedOptions(),
)
接下来,您将从Weaviate客户端构建一个 VectorStoreIndex 来存储和交互您的数据。
from llama_index.core import VectorStoreIndex, StorageContext
from llama_index.vector_stores.weaviate import WeaviateVectorStoreindex_name = "MyExternalContext"# Construct vector store
vector_store = WeaviateVectorStore(weaviate_client = client, index_name = index_name
)# Set up the storage for the embeddings
storage_context = StorageContext.from_defaults(vector_store=vector_store)# Setup the index
index = VectorStoreIndex(nodes,storage_context = storage_context,
)
步骤 5:设置查询引擎
最后,您将将索引设置为查询引擎。
# The QueryEngine class is equipped with the generator
# and facilitates the retrieval and generation steps
query_engine = index.as_query_engine()
步骤 6:在您的数据上运行一个简单的 RAG 查询
现在,您可以在您的数据上运行一个简单的RAG查询,如下所示:
# Run your naive RAG query
response = query_engine.query("What happened at Interleaf?"
)
使用 LlamaIndex 实现高级RAG
本教程将涵盖以下一系列高级 RAG 技术的选择:
- 检索前优化:句子窗口检索
- 检索优化:混合搜索
- 检索后优化:重新排序
索引优化示例:句子窗口检索
对于句子窗口检索技术,您需要进行两个调整:首先,您必须调整如何存储和后处理您的数据。我们将使用 SentenceWindowNodeParser,而不是 SimpleNodeParser。
from llama_index.core.node_parser import SentenceWindowNodeParsernode_parser = SentenceWindowNodeParser.from_defaults(window_size=3,window_metadata_key="window",original_text_metadata_key="original_text",
)
SentenceWindowNodeParser 做了两件事情:
- 它将文档分成单个句子,这些句子将被嵌入。
- 对于每个句子,它创建一个上下文窗口。如果您指定 window_size = 3,则生成的窗口将为三个句子长,从嵌入句子的前一个句子开始,并跨越后一个句子。窗口将存储为元数据。
在检索过程中,返回与查询最接近的句子。检索后,您需要通过定义 MetadataReplacementPostProcessor 并在节点后处理器列表中使用它来用元数据替换句子。
from llama_index.core.postprocessor import MetadataReplacementPostProcessor# The target key defaults to `window` to match the node_parser's default
postproc = MetadataReplacementPostProcessor(target_metadata_key="window"
)
...
query_engine = index.as_query_engine( node_postprocessors = [postproc],
)
检索优化示例:混合搜索
在LlamaIndex中实现混合搜索与两个参数更改相同,如果底层向量数据库支持混合搜索查询的话。alpha 参数指定向量搜索和基于关键字的搜索之间的加权,其中 alpha = 0
表示基于关键字的搜索,alpha = 1 表示纯向量搜索。
query_engine = index.as_query_engine(...,vector_store_query_mode="hybrid", alpha=0.5,...
)
检索后优化示例:重新排序
将 reranker 添加到您的高级RAG管道中只需要三个简单的步骤:
首先,定义一个重新排序模型。在这里,我们使用来自Hugging Face的 BAAI/bge-reranker-base。
在查询引擎中,将重新排序模型添加到节点后处理器列表中。
在查询引擎中增加 similarity_top_k 以检索更多的上下文段落,在重新排序后可以将其减少到 top_n。
# !pip install torch sentence-transformers
from llama_index.core.postprocessor import SentenceTransformerRerank# Define reranker model
rerank = SentenceTransformerRerank(top_n = 2, model = "BAAI/bge-reranker-base"
)
...
# Add reranker to query engine
query_engine = index.as_query_engine(similarity_top_k = 6,...,node_postprocessors = [rerank],...,
)
高级RAG范式中还有许多不同的技术。如果您对进一步的实现感兴趣,可以加入我们讨论群。
参考
[1] Gao, Y., Xiong, Y., Gao, X., Jia, K., Pan, J., Bi, Y., … & Wang, H. (2023). Retrieval-augmented generation for large language models: A survey. arXiv preprint arXiv:2312.10997.
[2] https://towardsdatascience.com/advanced-retrieval-augmented-generation-from-theory-to-llamaindex-implementation-4de1464a9930

![[SpringDataMongodb开发游戏服务器实战]](https://img-blog.csdnimg.cn/direct/16f74fa4de8044cea54c4cceff13e856.png)