每日推荐一篇专注于解决实际问题的外文,精准翻译并深入解读其要点,助力读者培养实际问题解决和代码动手的能力。
欢迎关注公众号(NLP Research),及时查看最新内容

原文标题:Improve RAG performance on custom vocabulary
原文地址:https://medium.com/datadriveninvestor/improve-rag-performance-on-custom-vocabulary-e728b7a691e0
Code: https://colab.research.google.com/drive/1pgaO_fDd5eEILVGMuNEo3m1GvF3ZBYSC?usp=sharing
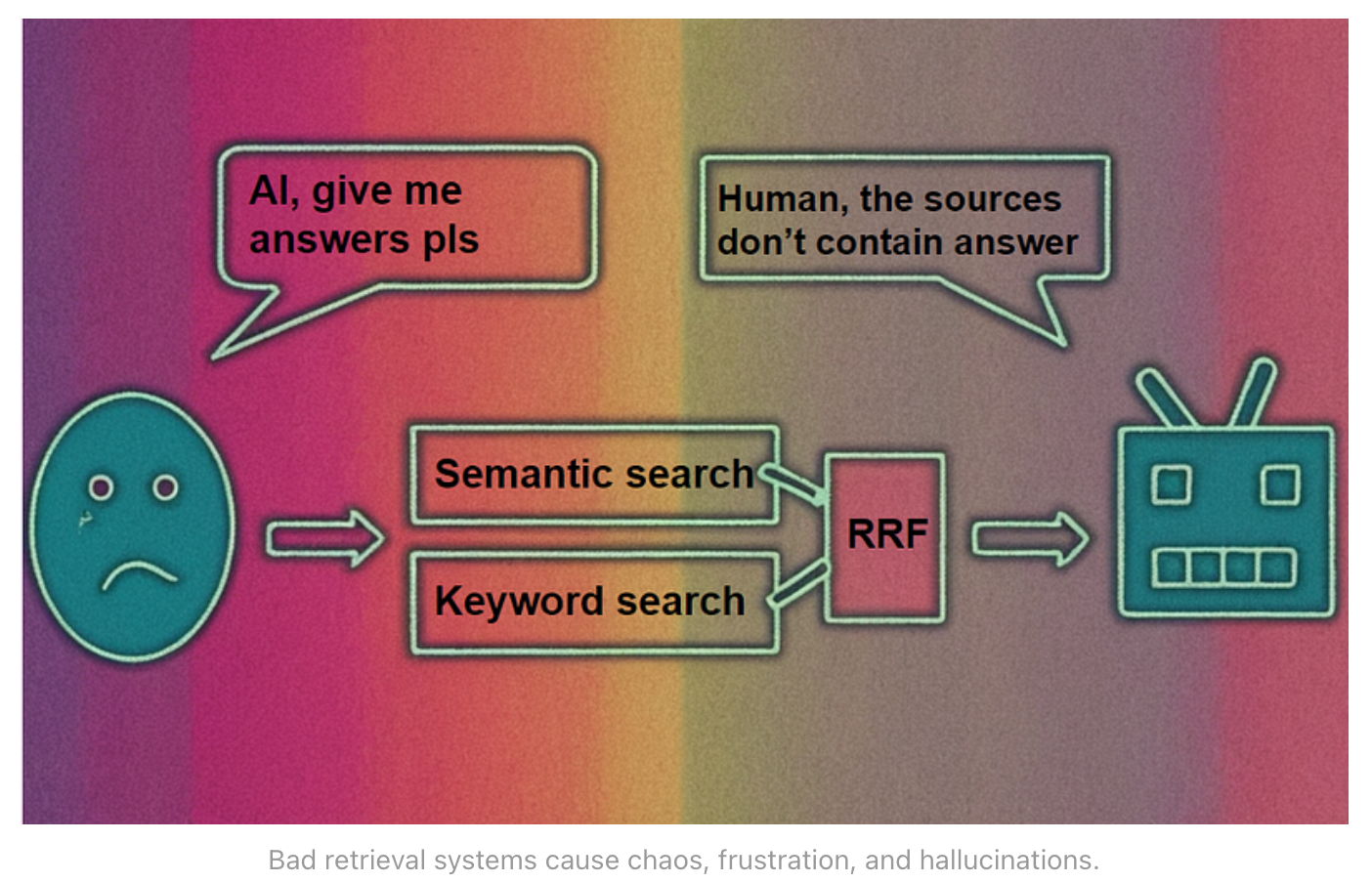
新的嵌入模型比以往更加强大。我们根据 MTEB 等基准对其进行了全面评估。但是,当我们的自定义数据包含一些网上找不到的单词(如内部产品名称和 ID)时,为什么这些模型仍然会惨遭失败呢?在本文中,我们将找出确切原因并提出多种解决方案。
简要说明
当引入自定义词汇或术语,或者使用了较差的分块策略或数据建模时,开箱即用的语义搜索模型就会失效。可以利用关键词搜索、查询扩展或使用 Reciprocal Rank Fusion(RRF)进行动态权重调整,以减少自定义词汇造成的错误。微调嵌入模型需要仔细的数据收集和设计,只有在应用了前面提到的方法后才能进行实验。
改进检索的十亿美元动力
Microsoft 365 的 Copilot 就是一个成功的 RAG 应用程序范例。Copilot 正在利用 RAG 模式,重点强调 R(etrieval)。真正的核心工作是数据建模和检索,Microsoft Graph 已经构建了8年之久。
Microsoft 365的Copilot是成功应用RAG模式的一个例子。Copilot充分利用了RAG模式,重点放在R(etrieval)上。真正的核心工作是数据建模和检索,已经构建了8年之久,即Microsoft Graph。
什么是 RAG?
检索增强生成(RAG)由检索、增强和生成三部分组成。首先,将用户问题转换为搜索查询。其次,通过应用程序接口从各种来源获取相关文本数据。第三,将相关文本数据与用户问题一起插入 LLM(大语言模型)提示。第四,LLM 根据相关文本数据生成对用户问题的回复。最后,将答案与相关数据源一起显示给用户,这样用户就可以轻松验证聊天机器人的答案。
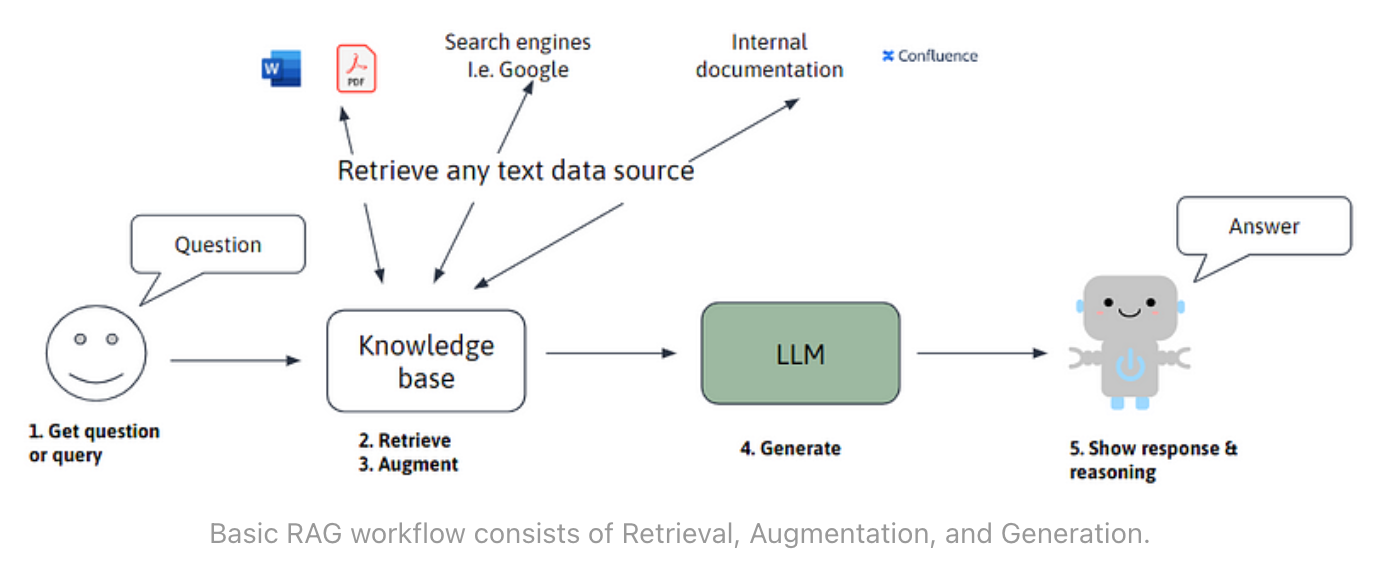
这一过程具有透明度和可扩展性。最后一步是显示聊天机器人回答问题的理由,这对于提高透明度至关重要。模块化设计允许 RAG 架构的每个组件独立扩展,因此我们可以切换 LLM、用户界面和信息检索(IR)系统或修改知识库的信息源。
机器学习或黑盒 LLM 通常不容易实现这些优势,因此基本的 RAG 模式很可能经受住时间的考验。LLM 可以换成其他算法,汇集文本数据进行回答,用户界面可以换成增强现实眼镜,IR 系统可以由成千上万个不同的 API 组成,供用户调用(可以查看 Gorilla)。在本例中,ChatGPT 是一种方便的基于文本问答的 LLM,更高级的 IR 系统可以留到以后使用。
既然我们已经就什么是 RAG 模式达成了共识,那么我们就来研究一下 IR 系统的陷阱,特别是 RAG 的陷阱。
向量搜索失败的原因及解决方法
举个例子,假设我们基于 Tesla Model 3 手册,利用语义向量搜索建立了一个 RAG 客户支持聊天机器人。为了建立矢量索引,我们将手册逐页分块。
您可以通过此 Google Colab 笔记本跟进示例。笔记本、微调模型权重、训练数据以及训练和验证损失都可以在 Google Drive 上找到。请记得将所有必要文件从 Google Drive 上传到 Google Colab 文件系统,以便在笔记本中访问。
问题陈述
一位用户进入聊天室。用户在特斯拉汽车仪表盘上遇到一个错误:APP_w304。用户向特斯拉聊天机器人发送信息。
“I see code APP_w304 on my dashboard what to do?”(“我在仪表盘上看到了代码 APP_w304,该怎么办?”)
query = "I see code app_w304 on my dashboard what to do?"
relevant_page, page_no, X = find_relevant_page_from_document(query)
answer = get_openai_rag_response(query, relevant_page)
print(answer)
我们的特斯拉聊天机器人首先根据语义相似性找到与查询最相关的页面,然后返回,并对问题做出回复。语义检索器找错了页面,结果聊天机器人产生了幻觉。

语义搜索找到了第 0 页,但问题的真正答案可以在第 217 页找到。第 1 页是封面页:
封面页几乎没有文字或其他相关信息。注意:当我们显示聊天机器人找到的索引时,我们从索引 0 开始。因此索引 0 对应第 1 页,索引 100 对应第 101 页,以此类推。
语义搜索为何失败?
我们可以将第 1 页分成若干句子,然后找出与用户查询最相似的句子。我们使用的嵌入模型要求在简短查询前加上 "Represent this sentence for searching relevant passages:"句子。该模型的训练目的是为短查询到长段落(s2p)的匹配生成高质量的嵌入。这意味着,我们为查询预置一个句子,以便模型识别我们正在用短查询查找长段落。我们使用点积来测量文本相似性。
我们通过查找换行符(\n)来提取句子。
page_texts = np.array([x for x in relevant_page.split(








![[嵌入式系统-33]:RT-Thread -18- 新手指南:三种不同的版本、三阶段学习路径](https://img-blog.csdnimg.cn/direct/8f13e2ae00a346afaf1720ea4c921455.png)