第2章:整体架构
目录
第2章:整体架构
2.1 单机架构
2.1.1 Mysql架构分层
2.1.2 InnoDB架构分层
2.1.3 小结
2.2 集群架构
2.2.1 主从模式
2.2.2 Cluster模式
2.2.3 主从模式和Cluste的区别
2.2.4 小结
2.3 总结
2.1 单机架构
2.1.1 Mysql架构分层
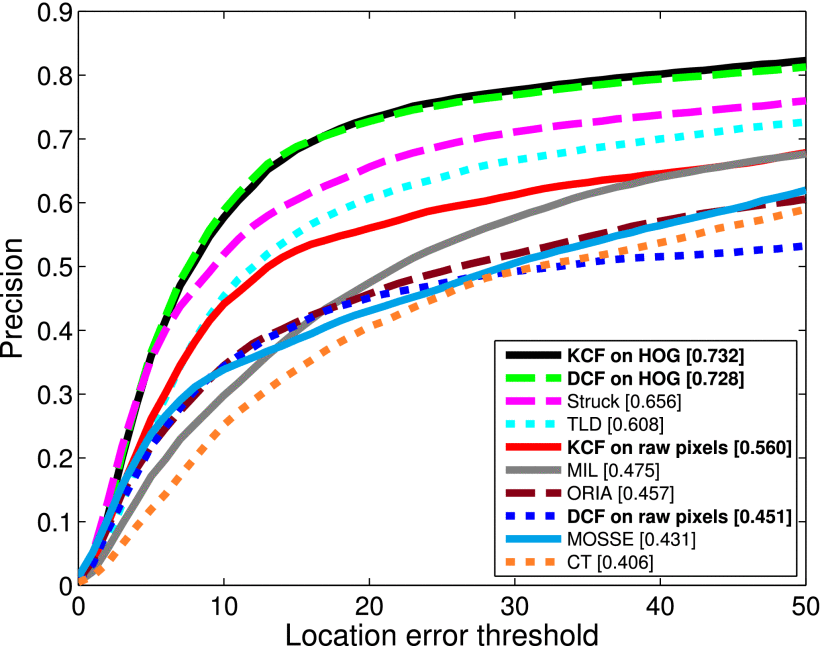
下图描述了Mysql的架构层级
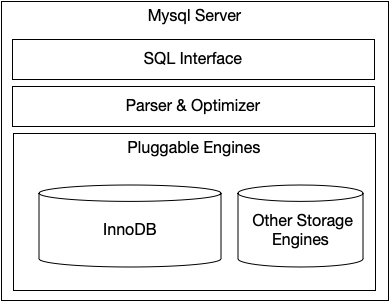
在MySQL的架构中,每个层级都有其特定的职责
SQL Interface:
- 接收请求:接收来自客户端的SQL查询请求。
- 验证权限:检查用户是否有权限执行请求的操作。
- 解析查询:将客户端提交的SQL语句分解成可理解的元素。
Parser & Optimizer:
- 解析SQL语句:将SQL语句分解成的元素组装成一棵抽象语法树(AST)。
- 优化查询计划:分析AST并优化查询执行计划,选择最有效的方式来执行查询(例如,选择合适的索引)。这是查询优化器所做的事情,这一部分是所有数据库厂商最黑的黑科技所在。
- 生成执行计划:将优化后的查询计划编译成可以被存储引擎执行的操作序列。
Pluggable Engines:
- 数据存储与检索:存储引擎负责数据的存储、检索、更新和删除操作。
- 事务处理:对于支持事务的存储引擎(如InnoDB),它们负责实现事务的ACID属性(原子性、一致性、隔离性和持久性)。
- 锁定机制:管理数据并发访问的锁定机制,保证多用户环境下数据的一致性。
- 表和索引的维护:维护表结构和索引,优化数据访问和查询性能。
具体到InnoDB存储引擎,它的职责更加具体化:
- 行级锁定:提供行级锁定,减少并发访问时的锁争用。
- MVCC支持:通过多版本并发控制(MVCC)支持更高的并发读写。
- 外键约束:支持外键约束以维护数据的引用完整性。
- 更改缓冲区:允许更改操作(如插入、删除、更新)在不直接更新主索引的情况下缓存,以实现更快的写操作。
- 自动崩溃恢复:在系统崩溃后自动恢复数据一致性。
- 缓冲池管理:维护一个内存中的缓冲池,用于缓存数据和索引页,加快读写速度。
这些层级一起构成了MySQL的架构,它们通过定义清晰的界限和职责,使得MySQL的功能强大而且灵活。在这个架构中,每个层级都是专注于其职责的专家,而存储引擎的可插拔性使得MySQL可以针对不同的工作负载和场景进行优化。
2.1.2 InnoDB架构分层
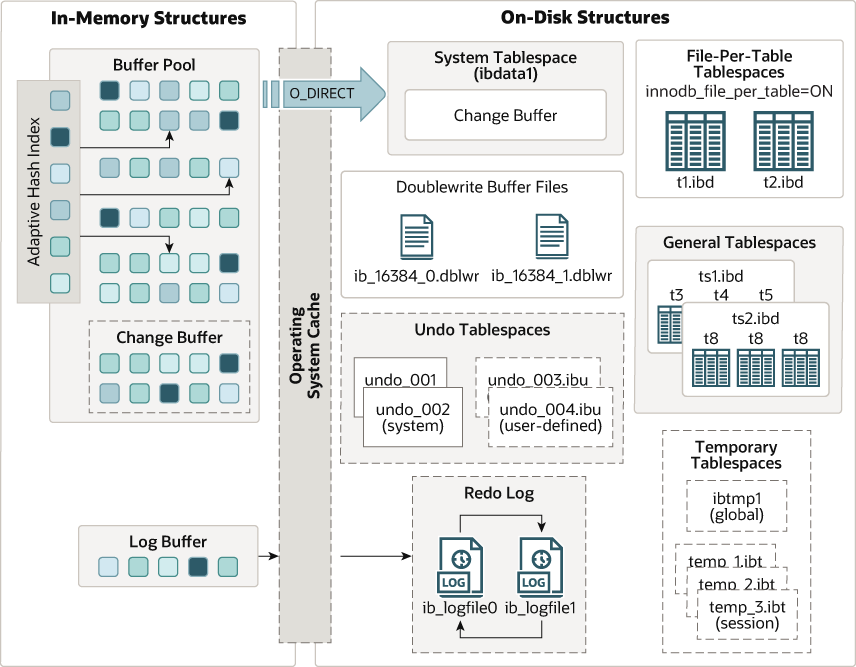
按照功能维度区分,InnoDB整体可以分为以下三个部分
缓存区:
缓存区主要是指InnoDB的缓冲池(Buffer Pool),以及与之相关的一些内存数据结构,其职责包括:
缓冲池管理:
- 存储数据页和索引页,减少对磁盘I/O的依赖,加快数据读取速度。
- 管理脏页(已修改的数据页),定期将它们刷新回磁盘以保持数据的持久性。
更改缓冲(Change Buffer):
- 缓存非唯一索引的DML操作,提高非主键索引的更新效率。
重做日志缓冲区(Redo Log Buffer):
- 临时存储即将写入磁盘的重做日志记录,确保事务的原子性和持久性。
自适应哈希索引(Adaptive Hash Index):
- 对热点数据创建哈希索引,提高频繁访问数据的查询效率。
UNDO日志缓存:
- 缓存记录了事务修改前数据的日志,用于支持数据的回滚操作和MVCC。
磁盘区:
磁盘区涉及到InnoDB的物理存储,其职责包括:
数据文件管理:
- 存储实际的表数据、索引和表空间等信息。
日志文件管理:
- 维护重做日志文件(Redo Log Files),用于事务的回放以实现故障恢复。
UNDO表空间:
- 存储UNDO日志的物理文件,用于存储事务进行中的旧行版本。
二进制日志(Binary Log):
- 虽然是MySQL的一部分而非InnoDB专有,但它记录了所有对数据库所做的更改,用于复制和数据恢复。
调度线程:
调度线程指的是InnoDB中负责各种后台任务的线程,其职责包括:
主线程(Master Thread):
- 负责协调各种后台活动,如异步I/O请求、脏页的刷新等。
I/O线程:
- 负责处理所有的输入输出请求,例如读写数据页到磁盘或从磁盘读入。
清理线程(Purge Thread):
- 清除已完成事务留下的无用信息,如UNDO日志的清理。
页清洗线程(Page Cleaner Thread):
- 负责刷新脏页,确保缓冲池中的数据及时同步到磁盘。
锁定监控线程:
- 监测死锁的发生并进行处理,以及对锁定情况进行监控。
这三个大部分相互协作,使InnoDB能够高效地处理大量数据,同时提供事务支持、故障恢复和数据一致性等特性。
2.1.3 小结
InnoDB是MySQL数据库的核心存储引擎,其结构精心设计,将责任分配给了三个主要部分:缓存区、磁盘区和调度线程。缓存区主要由缓冲池构成,它缓存了数据和索引页,加速读取速度并有效管理脏页。更改缓冲优化了对非主键索引的修改,而重做日志缓冲区则确保事务的原子性和持久性。自适应哈希索引和UNDO日志缓存协助提高了查询效率和支持了MVCC。磁盘区涵盖了InnoDB的物理存储,管理着数据文件、日志文件和UNDO表空间,这些都是数据持久化和恢复的基础。调度线程包括了一系列后台线程,如主线程、I/O线程、清理线程,它们负责维护数据库的内部健康,如定期刷新脏页和清除无效数据,确保数据库性能的最优化。InnoDB通过这些部分的紧密协作,提供了高效的数据处理、并发控制和故障恢复,满足了高性能数据库系统的需求,使得MySQL能够胜任从小型应用到大型企业级应用的各种场景。
2.2 集群架构
InnoDB 自身并不直接提供集群架构的功能,它是一个单节点的事务存储引擎。然而,当与 MySQL 配合时,可以使用额外的组件和服务来构建集群架构。以下是几种常见的 MySQL 集群架构方案,其中都能使用 InnoDB 作为存储引擎:
2.2.1 主从模式
在这种架构中,一个主节点(master)负责处理写操作,而一个或多个从节点(slave)负责读操作。从节点可以从主节点复制数据并提供读取服务,从而提高读取性能和系统的可用性。
- 主服务器 - 该服务器负责处理所有写操作(INSERT, UPDATE, DELETE)并生成二进制日志(binary log)。这个日志记录了对数据库的所有更改,这些更改需要被复制到从服务器。
- 从服务器 - 该服务器通过其I/O线程从主服务器获取二进制日志,并将其存储在自己的中继日志(relay log)中。然后从服务器的SQL线程会读取中继日志并应用这些更改,以确保从服务器的数据与主服务器保持一致。
简单示意图如下:

这里的箭头表示数据流动的方向,从主服务器的二进制日志流向从服务器的中继日志。主从复制可以配置为同步或异步。在异步复制中,主服务器在写入二进制日志后不需要等待从服务器确认,它继续处理其他操作。而在半同步复制中,主服务器至少要等待一个从服务器接收并记录了数据更改后才会继续处理。
优点:
1. 读写分离:可以将读操作分散到从服务器上,减轻主服务器的压力。
2. 数据冗余:从服务器提供数据的备份,增加了系统的故障容忍性。
3. 可扩展性:通过添加更多的从服务器,可以提高查询的吞吐量。
4. 高可用性:在主服务器出现问题时,可以手动将从服务器提升为新的主服务器,保持服务的可用性。
5. 灵活性:从服务器可以配置为只读,也可以开启二进制日志以支持级联复制。
6. 数据迁移与备份:可以在从服务器上进行数据备份操作,避免影响主服务器的性能。
缺点:
1. 复制延迟:由于复制是异步的,从服务器上的数据可能会有延迟。
2. 复杂的故障恢复:当主服务器宕机时,需要手动进行故障恢复和角色切换。
3. 写入扩展性有限:所有写操作和事务性工作负载仍然需要在主服务器上进行,这限制了写入操作的扩展性。
4. 数据一致性:如果复制过程中遇到问题(比如网络问题或从服务器故障),可能会导致主从服务器之间的数据不一致。
5. 管理和维护:需要额外的努力来监控复制状态并管理不同服务器,特别是当复制架构变得复杂时。
6. 无自动故障转移:MySQL主从复制不提供自动的故障转移机制;需要额外的工具或手动操作来实现。
2.2.2 Cluster模式
MySQL InnoDB Cluster 提供了高可用性的解决方案。它使用了 MySQL Group Replication 技术,这是一个基于 Paxos 算法变体的一致性协议实现。它提供了一组紧密集成的 MySQL 服务器实例,它们组成了一个组复制集群。一个 InnoDB Cluster 至少包含三个 MySQL Server 实例。各个节点之间互为主节点,可以自动处理故障转移和数据一致性。
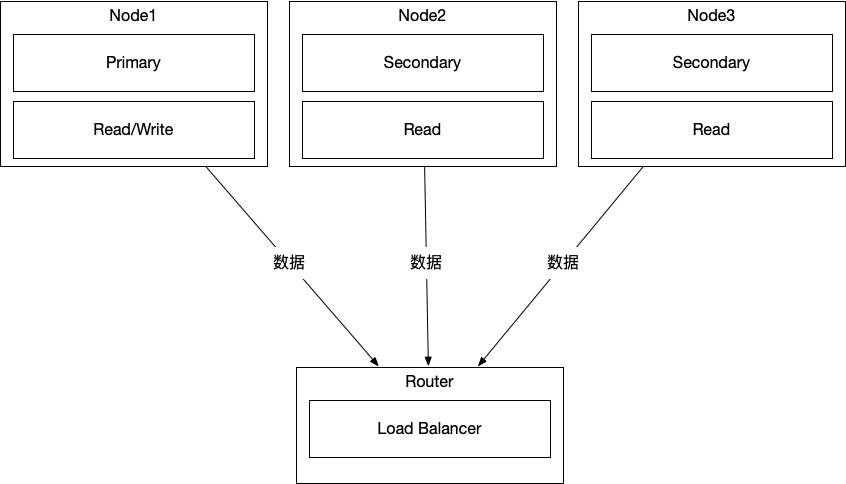
在这个图中:
- 每个 "MySQL Node" 节点都是 InnoDB Cluster 的一部分。通常,一个节点作为 "Primary"(主节点)充当读写节点,而其他节点作为 "Secondary"(从节点)通常只用于读取操作,以分担查询负载。
- "Primary" 节点负责处理所有写操作,而 "Secondary" 节点则复制 "Primary" 节点上的数据更改,确保数据的一致性。
- "MySQL Router" 是客户端和应用程序的接入点,它负责将客户端请求重定向到正确的服务器节点,并提供读写分离以及负载均衡功能。
- 所有的节点之间都是通过组复制技术相互连接的,确保数据在节点之间同步。
优点:
1. 高可用性:InnoDB Cluster 提供了自动故障转移和恢复功能,可以在节点故障时自动重新路由流量到健康节点。
2. 数据一致性:通过基于Quorum的写集一致性保证,确保数据在集群的所有节点间保持一致。
3. 易于管理:MySQL Shell 提供了管理集群的工具和接口,使得集群的配置和管理变得简单。
4. 读写扩展性:支持读写分离,可以利用从节点来分散读取负载。
5. 多主模式:支持单主模式和多主模式,后者允许所有服务器节点都可读写。
6. 无需额外中间件:直接集成在 MySQL 中,不需要额外的代理或中间件进行读写分离。
缺点:
1. 性能开销:由于复制数据需要占用网络资源和处理时间,可能会对写入操作的性能造成一定影响。
2. 配置复杂性:尽管有工具简化管理,但与单节点MySQL相比,集群的配置和管理更为复杂。
3. 资源要求:对于小型应用来说,维护一个完整的集群可能是资源密集型的,特别是在需要确保节点足够多以便提供高可用性时。
4. 网络要求:高依赖网络质量,节点之间需要稳定且低延迟的网络连接,以维持群组复制的性能。
5. 学习曲线:对于新用户来说,理解和正确配置 InnoDB Cluster 可能需要时间。
6. 节点数量限制:出于性能考虑,建议的节点数量通常有上限。例如,一个推荐配置可能只包含3到5个节点。
2.2.3 主从模式和Cluste的区别
InnoDB 主从模式和 InnoDB Cluster 是两种不同的MySQL数据复制和高可用性解决方案。以下是它们之间的一些关键区别:
复制方法
- 主从模式 使用传统的异步二进制日志复制技术。主服务器生成二进制日志(binlog),从服务器通过I/O线程读取这些日志,并通过SQL线程应用这些更改。这个过程可能导致主从之间的延迟,并且复制并不是自动同步的。
- InnoDB Cluster 使用了 MySQL Group Replication 技术,它实现了更紧密的同步复制。在InnoDB Cluster中,数据几乎同时在所有节点上更新,确保了数据的一致性和高可用性。
高可用性和故障转移
- 主从模式 通常需要手动或通过第三方工具进行故障转移。如果主服务器宕机,需要人为介入来提升一个从服务器为新的主服务器。
- InnoDB Cluster 提供了自动的故障转移和恢复功能。如果主节点(或Primary节点)发生故障,集群会自动选举一个新的Primary节点,而不需要人工干预。
读写分离
- 主从模式 通常需要额外的代理软件(如MySQL Router或ProxySQL)来实现读写分离。
- InnoDB Cluster 可以直接与 MySQL Router 配合使用来实现智能的读写分离和负载均衡。
部署复杂性
- 主从模式 相对简单,可以用于不同的环境和需求。它适用于从简单的备份复制到复杂的多源复制环境。
- InnoDB Cluster 需要更复杂的设置和配置,通常是为了提供无缝的高可用性解决方案。
节点配置
- 主从模式 中,只有一个主服务器负责写操作,其他从服务器负责读操作。主服务器是单点故障的风险点。
- InnoDB Cluster 中,每个节点都可以配置为自动接管为主节点。这样即使一个节点失败,集群仍然可以继续提供服务。
一致性保证
- 主从模式 可能会遇到复制延迟,这意味着在某些情况下,从服务器可能暂时落后于主服务器。
- InnoDB Cluster 中的 Group Replication 保证了更强的数据一致性,因为它使用了 Paxos-like 协议来同步数据更改。
简而言之,InnoDB 主从模式适合于数据备份和读取扩展场景,而InnoDB Cluster为寻求自动化高可用性和数据一致性的复杂部署提供了更现代和健壮的解决方案。
2.2.4 小结
InnoDB存储引擎自身不直接提供集群功能,但可以通过MySQL的额外组件和服务实现集群架构。在InnoDB的主从模式中,主节点负责写操作,而从节点处理读操作并从主节点同步数据。这种架构的优点在于可以通过从节点的读操作缓解主节点的压力,同时提供数据冗余和较高的读取扩展性。然而,主从模式存在复制延迟,复杂的故障恢复流程,以及写入扩展性有限的缺点。相比之下,MySQL InnoDB Cluster提供了更高的可用性和数据一致性,支持自动故障转移,且易于管理。它支持多主模式,无需额外中间件,但同时这种模式可能带来写入性能开销,配置和管理上的复杂性,较高的资源需求,对网络质量的依赖,以及新用户可能面临的学习曲线。此外,InnoDB Cluster建议的节点数量通常有上限,以确保集群的高性能运行。总的来说,选择合适的集群模式需要综合考虑应用场景、资源可用性和管理复杂度等因素。