IEPILE:基于模式的指令生成解法,提高大模型在信息抽取任务上的性能
- 提出背景
- 基于模式的指令生成解法
- 效果
提出背景
论文:https://arxiv.org/pdf/2402.14710.pdf
代码:https://github.com/zjunlp/IEPile
假设我们有一个信息抽取任务,目标是从新闻文章中抽取有关企业并购事件的信息。
包括抽取如下模式(或字段)的信息:并购方(Acquirer)、被并购方(Acquiree)、交易金额(Transaction Amount)和交易日期(Transaction Date)。
存在的问题:
-
模式查询差异: 在训练阶段,可能所有模式都被查询,但在实际评估或应用中,只查询了部分模式,例如仅查询了并购方和被并购方,没有查询交易金额和日期。这可能会导致模型在真实场景下性能下降。
-
语义混淆: “并购方”和“被并购方”的字段可能在文本中以多种方式被提及,例如,一个企业可能被称为“公司”,“企业”,或者直接用其公司名。
此外,一家公司在不同的并购事件中可能既是并购方也是被并购方,这增加了语义上的混淆和抽取的难度。
针对模式查询差异:
-
解法: 引入动态模式查询调整机制,在训练阶段不仅使用包含所有模式的指令进行训练,还要模拟实际情况,使用只包含部分模式的指令进行额外的训练。
这样可以使模型适应于在不完全信息环境下进行准确的信息抽取。
-
应用举例: 在训练数据中,我们不仅提供完整的并购事件信息(包括并购方、被并购方、交易金额和交易日期),还要创建一些只包含部分信息(如仅并购方和被并购方)的训练实例。
这样,模型学会在缺少某些字段信息的情况下也能进行有效的信息抽取。
针对语义混淆:
-
解法: 构建一个术语同义词库,将企业可能的不同称呼统一映射到一个标准化的表示上。
此外,引入上下文理解能力的训练,让模型能够根据上下文区分相同术语在不同场景下的角色(如并购方还是被并购方)。
对于“公司”、“企业”或特定公司名的提及,都映射到同一实体上,并在模型训练时加入上下文辨识的能力,如通过前后文判断一个实体在特定新闻报道中是作为并购方还是被并购方。
这样,模型能够更好地理解和抽取并购事件中的各个角色,即使在术语使用上存在多样性。
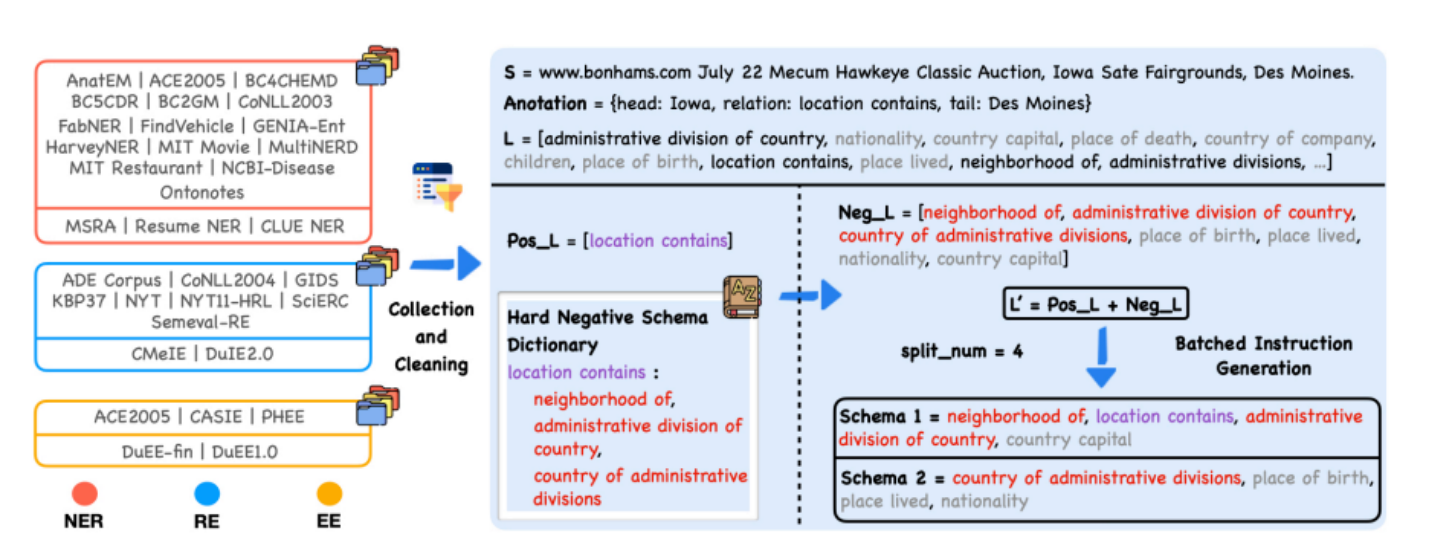
上图是 IEPILE(一个信息抽取指令数据集)构建的概览,流程分为几个部分:
-
数据收集与清理: 图表左侧列出了用于构建IEPILE的多个数据集,这些数据集被分为三类:命名实体识别(NER)、关系抽取(RE)和实体抽取(EE)。
这些数据集从网络上收集,然后经过清理以准备用于进一步处理。
-
基于模式的指令生成(Hard Negative Schema Construction): 这一部分展示了如何构建“Hard Negative Schema Dictionary”。
这是一个包含特定模式和相关负面模式(或“硬负面”模式,可能会造成混淆的模式)的词典。
例如,模式 “location contains” 与其硬负面模式,如 “neighborhood of”, “administrative division of country” 等关联。
-
批量指令生成: 在右侧,展示了如何将正面和负面的模式结合起来,以生成一批指令。
这些指令被分成多个模式(Schema),每个模式都包含一组特定的标签。例如,“Schema 1” 可能包含 “neighborhood of”, “location contains”, “administrative division of country”, “country capital” 这些标签。
这个过程中考虑了一个名为
split_num的变量,这个变量定义了在每批指令生成中会用到的模式数量。这有助于确保训练数据中的模式与评估或应用阶段中可能出现的模式数量一致。
这张图是对一个复杂数据处理过程的视觉概述,说明了如何从现有数据集中提取和清洗数据,构建模式字典,并基于这些模式生成训练数据,以便在信息抽取任务中训练机器学习模型。
基于模式的指令生成解法
针对信息抽取(IE)任务的改进解法可以被称为“基于模式的指令生成解法”,主要包括两个关键特征:硬负模式构建(Hard Negative Schema Construction)和批量指令生成(Batched Instruction Generation)。
这个解法旨在提高大型语言模型在信息抽取任务中的性能,尤其是在面对模式数量不一致和模式间的语义混淆时。
-
硬负模式构建(特征1):
- 目标是减少模型在信息抽取任务中的语义混淆。
- 方法是创建一个字典,其中包含每个正面模式和一系列与其语义上接近的负面模式。
- 这允许模型学习更准确地区分那些在语义上可能引起混淆的模式。
-
批量指令生成(特征2):
- 目标是处理训练与评估时查询模式数量不一致的问题。
- 方法是动态限制每个指令中查询的模式数量,并将这些模式分批查询。
- 这样即使在评估阶段查询的模式数量与训练不同时,也能保持模型的泛化能力。
硬负模式构建的例子(特征1):
假设我们正在开发一个模型,其任务是从新闻文章中抽取与企业并购相关的事件。其中一个正面模式可能是“公司A收购公司B”。
- 目标: 减少模型在抽取并购事件时的语义混淆。
- 方法: 我们创建一个硬负模式字典,其中“合作”或“伙伴关系”等术语可能与“收购”相混淆,但实际上并不表示并购事件。
- 应用: 当模型在训练中遇到“公司A与公司B建立合作关系”这样的句子时,由于“合作”被标识为硬负模式,模型将学会这并不是一个并购事件,进而在实际应用中更准确地识别真正的并购事件。
批量指令生成的例子(特征2):
继续以上的并购信息抽取任务,假设我们有一组指令,每个指令要求抽取不同数量的模式信息。
- 目标: 确保模型能在训练和评估时处理不同数量的模式查询。
- 方法: 我们将指令集分成批次,每批次包含固定数量(比如5个)的模式。每批次的模式可以包括“收购方”、“被收购方”、“交易金额”、“交易日期”等。
- 应用: 在训练期间,模型通过这种批量处理学会了同时处理多个模式的查询。在评估阶段,即使指令中的模式数量减少到3个或增加到7个,模型也能够适应,因为它已经学会了如何处理不同批次大小的模式集。
通过这两个特征的结合使用,模型在面对实际数据时能够更准确地执行信息抽取任务,同时减少了训练和实际应用之间的性能差距。
完整步骤:
-
数据收集和清理:
- 从多个数据源收集涉及命名实体识别(NER)、关系抽取(RE)和事件抽取(EE)的双语数据。
- 对数据进行标准化处理,包括格式统一、实例去重和低质量数据排除。
-
构建硬负模式字典:
- 从标准化后的数据集中识别正面模式集合。
- 定义每个正面模式的硬负模式集合,即语义上接近但并不正确的模式。
-
批量指令生成:
- 将正面模式和一小部分硬负模式组合,形成最终的查询模式集合。
- 根据预设的
split_num将模式集合分批,每批包含固定数量的模式。
-
模型训练:
- 使用生成的批量指令对信息抽取模型进行训练。
- 确保模型能够适应在数量不一致的模式查询中进行准确的信息抽取。
-
模型评估与微调:
- 在实际的IE任务中评估模型性能。
- 根据评估结果对模型进行微调,以提高其在实际应用中的准确性和鲁棒性。
效果

IEPILE 使用后: