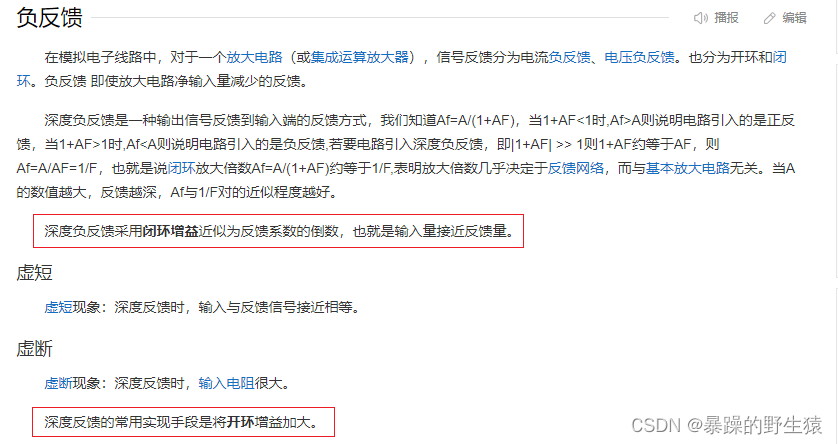
最近AI圈最火的无疑是OpenAI在2月15日发布的Sora。
Sora可以根据文本生成一分钟的高清视频,生成的视频画质、连续性、光影等都令人叹为观止,Sora无疑将视觉生成推到新的高度。
本文将重点回答三个问题:(1)Sora的原理是什么?(2)Sora到底是不是世界模型?(3)Sora会影响哪些行业?
文章目录
- 1. 背景
- 技术交流群
- 2. Sora原理解读
- 2.1 Sora要解决的任务
- 2.2 Sora原理
- 2.3 Sora 的重要性质
- 2.4 重要细节推测
- 2.5 尚未披露关键信息
- 2.6 Sora 的应用
- 2.7 Sora 的局限性
- 3. Sora到底算不算世界模型?
- 4. Sora对行业的影响
- 5. Sora成功的关键
- 用通俗易懂方式讲解系列
1. 背景
在国内外大多数AI厂商还在卷大语言模型之际,OpenAI悄无声息地发布了文生视频(text-to-video,简称t2v)模型Sora [1],仅仅几个视频demo,就让整个AI圈子从惊讶到恐惧,惊讶于Sora生成的视频已经到达工业应用级别,恐惧于现有的t2v模型与Sora的差距竟然如此之大。
先看个Sora官方博客展示的demo,当你向Sora输入:“A stylish woman walks down a Tokyo street filled with warm glowing neon and animated city signage. She wears a black leather jacket, a long red dress, and black boots, and carries a black purse. She wears sunglasses and red lipstick. She walks confidently and casually. The street is damp and reflective, creating a mirror effect of the colorful lights. Many pedestrians walk about.”,Sora则根据该文本生成了长达1分钟的高清视频。
这个demo展现了Sora至少有以下突破:(1)画质突破:视频非常高清,细节极其丰富;(2)帧率和连续性突破:视频帧率高、连续性好(无闪烁或明显的时序不一致);(3)时长突破:相比之前t2v模型仅能生成几秒的时长,Sora可以生成长达1分钟的视频,这是之前t2v模型不敢想象的;(4)物理规则理解突破:视频中物体的运动、光影等似乎都非常符合自然世界的物理规则,整个视频看上去都非常自然和逼真。
那么OpenAI到底用了什么魔法能让Sora如此惊艳?接下来我们通过OpenAI给出的Sora技术报告来解答。PS:该技术报告非常简陋,技术细节几乎没有,只给了大致的建模方法。
技术交流群
前沿技术资讯、算法交流、求职内推、算法竞赛、面试交流(校招、社招、实习)等、与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度等名校名企开发者互动交流~
我们建了SORA大模型面试与技术交流群, 想要进交流群、需要源码&资料、提升技术的同学,可以直接加微信号:mlc2060。加的时候备注一下:研究方向 +学校/公司+CSDN,即可。然后就可以拉你进群了。
方式①、微信搜索公众号:机器学习社区,后台回复:加群
方式②、添加微信号:mlc2060,备注:技术交流
2. Sora原理解读
2.1 Sora要解决的任务
Sora要解决的任务其实非常好理解,就是给定一段文本,模型需要根据该文本生成相应的视频,简单说就是text-to-video(t2v)。t2v本身并不是一个新问题,很多厂商都在研究t2v模型,只是当前的t2v模型生成的视频普遍质量较差,很难到达工业应用级别。
在Sora出现前大家的普遍认知是:t2v是一个很难的任务,工业级别t2v模型(或者说能真正实用的t2v模型)短时间内应该很难实现。然而,OpenAI又又又一次打了所有人的脸,Sora的发布意味着,这一天已经来了。
2.2 Sora原理
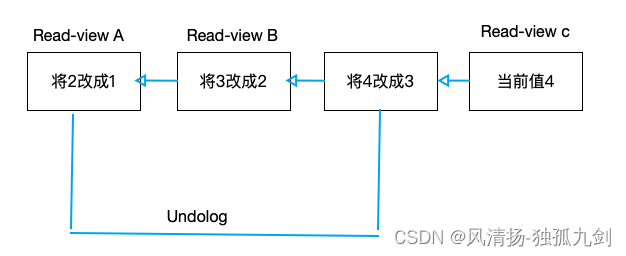
如果用一句话来描述Sora训练建模过程,可以是:将原始视频通过一个视觉编码器(visual encoder)编码到隐空间(latent space)形成隐时空块(spacetime latent patches),这些隐时空块(结合text信息)通过transformer做diffusion [2, 3, 4]的训练和生成,将生成的隐时空块再通过视觉解码器(visual decoder)解码到像素空间(pixel space)。所以整个过程就是:visual encoding -> latent diffusion with diffusion transformer (DiT) [4] -> visual decoding。
(1)Visual Encoding
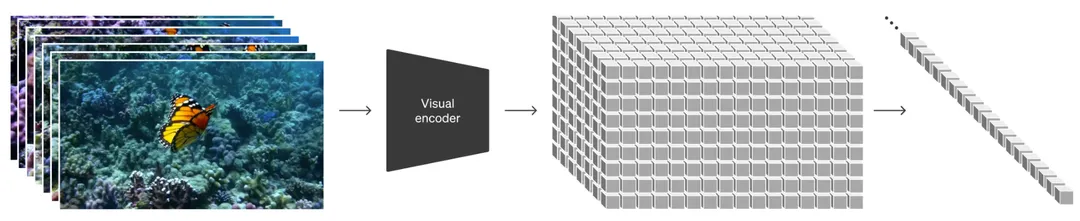
这一步其实很好理解,就是通过一个变分自编码器(VAE)[5]的encoder将高维的原始视频映射(压缩)到较为低维的隐空间(注意:不仅仅是空间上压缩了,时间上也进行了压缩),即得到该视频的低维隐空间特征(可以看成一个大的3D tensor),为了后续transformer计算方便,将这个特征切成不重叠的3D patches,再将这些patches拉平成一个token序列,这个token序列其实就是原始视频的表征了(即visual token序列)。
(2)Latent Diffusion with DiT
在得到视觉表征(上述visual token序列)后,Sora借鉴了DiT [4],使用transformer来做diffusion model的训练,使用transformer的好处在于可以输入任意长度的token序列,这样就不再限制输入视频的尺寸和时长,并且模型很容易scale up(OpenAI表示这个我熟)。同时,因为Sora想解决t2v的问题,所以Sora会将text的表征以某种形式condition到visual tokens上(Sora技术报告中未披露,但后文我会分析最可能的实现方法)来约束生成。
在diffusion transformer的训练中,给定噪声输入(e.g., 噪声patches)并conditioned on text特征,模型被训练去预测原始视频的patches(预测过程又叫denoising过程,具体可以参考DDPM [2]中的训练算法),示意图如下:

(3)Visual Decoding
第(2)步中,diffusion transformer可以生成的其实不是像素空间的视频,而是隐空间的视频表征(denoised patches),这些patches reshape成视频3D特征再经过第(1)步中的VAE的decoder,就可以映射回像素空间,得到最后生成的视频。
2.3 Sora 的重要性质
(1)Sora可以灵活地采用不同时长、分辨率和长宽比的视频
OpenAI发现之前的方法大多采用固定尺寸的视频(比如4s的256x256视频)去训练模型,和现实中任意长度、长宽比有较大gap,而采用原始尺寸的视频训练模型效果更好。得益于Sora采用的transformer结构,Sora可以输入任意多个visual patches(初始为noise patches),即可生成任意尺寸的视频。
(2)Sora有很强的语言理解能力
训练t2v模型需要大量带有文本标注的视频,OpenAI采用DALL·E 3 [6] 中的re-captioning技术来解决。首先训练一个高质量的视频标注模型(captioner model),然后它为训练集中的所有视频生成文本字幕。另外,进一步利用GPT将视频标注模型生成的简短文本扩展成更长的文本有利于还利用Sora准确遵循用户文本提示生成高质量视频。
2.4 重要细节推测
Sora的技术报告没有任何细节,仅仅告知大家大致的建模方法,但有一些细节的实现是可以推测or猜测的。
(1)visual encoder可能的结构:因为Sora在visual encoding时也压缩了时间维度,所以Sora可能采用从零开始训练的3D conv版的VAE。Sora这里没有像之前工作那样,简单地采用Stable Diffusion(SD) [3]预训练好的2D conv版的VAE。现成的SD的VAE encoder用来压缩视频最大的问题在于时间维度没有下采样,SD的VAE承担了将原本sparse的数据压缩到compact的latent domain再进行diffusion过程,从而大幅度提高training和inference的效率。然而,直接运用2D VAE缺乏了在时间维度的压缩,使得其对应的latent domain不够紧凑。实际上,这是一个历史遗留问题,大部分研究工作受算力等因素影响选择直接利用SD的预训练权重(Unet部分)、保留了2D VAE。
(2)visual encoding中视频的patches如何flatten成token序列?大概率借鉴DiT,先flatten这些patches,然后过一个linear层,将patches embed成tokens。
(3)diffusion中如何将text信息引入?大概率还是借鉴DiT和SD,在每个transformer block中,将visual tokens视为query,将text tokens作为key和value,进行cross attention,不断地conditioned on text tokens。
2.5 尚未披露关键信息
(1)模型:模型的具体结构、模型的参数量、关键参数(patch size、token数目等)如何?
(2)数据:用了哪些数据?规模如何?
(3)资源:用了多少算力?训练了多久?
(4)如何处理高帧率、时间长、高分辨率的视频?目前主流的视频生成模型都是cascade结构,也就是先生成低分辨率、低帧率的视频,再不断地在时间和空间维度上upsample。不知道Sora是否是直接一次性输出其展示的结果,如果是那样,那又会有多少token呢?
(5)如何解决motion的问题?目前的视频生成模型普遍生成的motion都不太好,最简单的例子就是“人走路”,大部分模型无法生成连贯的、长时间的、合理的人行走的过程。而Sora生成的结果在连贯性、合理性上相比之前的模型都有着断代的领先。那到底是什么促使了这样的结果呢?是模型尺寸的scale up吗?需要scale up到什么size?还是数据的收集和清洗呢?以及要做到什么程度呢?
2.6 Sora 的应用
- 视频创作:用户可以根据文本生成高质量视频;
- 扩展视频:可以在给定的视频或图片基础上,继续向前或向后延申视频;
- Video-to-video editing:例如将SDEdit [7]应用于Sora,可以很容易改变原视频的风格;
- 视频连结/过渡/转场:可以将两个视频巧妙地融合到一起,使用Sora在两个输入视频之间逐渐进行插值,从而在具有完全不同主题和场景构成的视频之间创建无缝过渡;
- 文生图:图像可以视为单帧的视频,故Sora也能实现文生图。
2.7 Sora 的局限性
原本中提到:“Sora 目前作为模拟器(simulator)表现出许多局限性。例如,它不能准确地模拟许多基本相互作用的物理过程,例如玻璃破碎。其他交互过程(例如吃食物)也不总是能正确预测。我们在登陆页面中列举了模型的其他常见故障模式,例如长时间样本中出现的不连贯性或对象的凭空出现。”
总结一下主要是:
(1)对世界的物理规则的理解还不完美;
(2)长视频生成时容易出现不连贯或者物体凭空出现的现象。
3. Sora到底算不算世界模型?
最近,围绕“Sora是不是世界模型”以及“Sora懂不懂物理世界”等相关话题引起了圈内热议。
英伟达高级研究科学家Jim Fan在X平台上称:“Sora is a learnable simulator, or “world model”.”。而图灵奖得主Yann LeCun则表示:“The generation of mostly realistic-looking videos from prompts “does not” indicate that a system understands the physical world.”。
(1)什么是世界模型(world model)[8]
“The image of the world around us, which we carry in our head, is just a model. Nobody in his head imagines all the world, government or country. He has only selected concepts, and relationships between them, and uses those to represent the real system.” --Jay Wright Forrester, the father of system dynamics
上述引自系统动力学之父Jay Wright Forrester。我的理解是人类其实无法记下整个世界的所有内容,我们的大脑仅仅是在有选择记忆一些概念和相互关系,利用这些,我们可以表征和理解这个世界。这里,我们的大脑其实在充当world model,即一个理解世界(物理)规律的模型。比如,当你看到玻璃杯从桌上掉下水泥地上,你知道接下来发生的事自然就是杯子碎了。
那么世界模型到底是啥?
我将世界模型分为广义的和狭义的进行讨论。
【广义世界模型】广义的世界模型,其实就是任何能理解世界潜在物理规律的模型,比如可以预见未来结果的模型,继续以前面那个例子为例,如果一个模型能预测玻璃杯掉下后的状态,说明该模型具备这样的能力;再比如知道世界中实体或抽象概念之间相互联系的模型,比如一个模型知道玻璃杯的硬度低于水泥地会导致玻璃破碎。这些其实在我看来都是广义上的世界模型。
【狭义世界模型】狭义的世界模型更强调理解物理世界的动力(dynamics)或者运动等物理规律的模型,了解过RL的朋友们一定特别熟悉这些。在RL中,一大分支便是model-based RL,这里的model,其实就是典型的狭义世界模型。在此模型中,给定某一时刻的状态s_t和该时刻做的动作a_t,模型可以预测出下一个时刻的状态s_t+1。所以说,狭义的世界模型其实是因果的。回到上面的例子,s_t可以是刚下落的杯子和干净的水泥地,a_t则是自由落体这个动作,s_t+1则是水泥地上碎掉的杯子这样一个状态。
(2)Sora算不算世界模型?
先给结论,我觉得Sora算广义世界模型,同时也是隐式的狭义世界模型。
Sora的diffusion过程其实是在从噪声状态在text prompts的约束下,预测可能的结果(视频)。这个过程看似跟狭义世界模型没有关系,但其实可以这么理解:
标准的狭义世界模型的状态转移过程为:s_0 -> a_0 -> s_1 -> a_1 -> s_2 -> … -> a_T-1 -> s_T。对于一个视频来说,每一帧都可以看做一个状态s,但是某一时刻动作其实很难描述,我们很难用自然语言或者其他形式来描述相邻两帧之间发生了什么。但是我们可以用自然语言描述视频在做什么,也就是s_0到s_T发生了什么,也就是将动作序列A={a_0, a_1, …, a_T-1}一起打包表示成一句话或者一段话。在Sora中,text prompts可以看做成这样的动作序列A。而Sora理解世界的过程也和一般的狭义世界模型不太一样,s_0不再是第一帧,而是“混沌”状态(噪声),于是乎diffusion的过程可以理解为:s_0(噪声) -> A -> s_1 -> … -> A -> s_T(清晰视频)。这其中,虽然Sora并没有显式建模世界的dynamics,但其实在理解自然语言和视频内容之间的关系,算是一种广义上的世界模型。
同时,回看Sora的应用可以发现,Sora其实可以拓展视频的!也就是说,换一个角度,给定一张起始图像(第一帧)和一个文本描述(描述包含生成视频内容),Sora就能生成出整个视频,那这个过程其实可以看做是在隐式的狭义世界模型建模:s_0(第一帧)-> A -> s_{1:T} (整个视频)。相当于是,给定了初始状态和接下来的所有动作A,Sora能预测出接下来的所有状态s_{1:T},所以Sora在我看来也是一个非典型的、隐式的狭义世界模型。
值得一提的是,OpenAI官方信息从未表示Sora是world model,而是强调它是world simulator,我也觉得world simulator描述比较贴切。
4. Sora对行业的影响
- 短视频内容创作可能进入新的时代:Sora可以提供丰富的视频素材;
- 视频剪辑和编辑:Sora具备相关应用能力;
- 更逼真的数字人:用户可以得到自己的“理想型”;
- 娱乐化:从图像一键生成视频;
- 游戏行业:游戏引擎受到Sora挑战;
- 图形学:未来可能不复存在。
(讨论区,欢迎大家评论添加)
5. Sora成功的关键
- 大规模训练:这点毋庸置疑。大模型、大数据量、使用大规模算力,OpenAI基本操作。
- 敢于突破常规、不屑于刷点:之前工作基本都采用SD预训练的visual encoder,也知道该encoder多少有点不合理(比如只能处理固定size的输入),但没有人真的去重新训练一个更合理的encoder(当然,更可能是算力不支持)。而OpenAI发现问题,就用算力来解决问题(大概率重新训练visual encoder)。
- 实事求是+绝对领先的sense:自回归的建模方式在LLM中大获成功,GPT系列也出自OpenAI,但这不代表“Autoregressive is everything”,Sora告诉大家,生成视频无需采用自回归,直接3D建模+transformer encoder结构就ok。
- AGI理念从上至下传播:Sam Altman绝对是一个有大格局的人物,其最终目标是实现AGI,我想整个OpenAI应该都会贯彻这样的理念,不管是ChatGPT还是Sora,都能看到AGI的影子。
用通俗易懂方式讲解系列
- 用通俗易懂的方式讲解:自然语言处理初学者指南(附1000页的PPT讲解)
- 用通俗易懂的方式讲解:1.6万字全面掌握 BERT
- 用通俗易懂的方式讲解:NLP 这样学习才是正确路线
- 用通俗易懂的方式讲解:28张图全解深度学习知识!
- 用通俗易懂的方式讲解:不用再找了,这就是 NLP 方向最全面试题库
- 用通俗易懂的方式讲解:实体关系抽取入门教程
- 用通俗易懂的方式讲解:灵魂 20 问帮你彻底搞定Transformer
- 用通俗易懂的方式讲解:图解 Transformer 架构
- 用通俗易懂的方式讲解:大模型算法面经指南(附答案)
- 用通俗易懂的方式讲解:十分钟部署清华 ChatGLM-6B,实测效果超预期
- 用通俗易懂的方式讲解:内容讲解+代码案例,轻松掌握大模型应用框架 LangChain
- 用通俗易懂的方式讲解:如何用大语言模型构建一个知识问答系统
- 用通俗易懂的方式讲解:最全的大模型 RAG 技术概览
- 用通俗易懂的方式讲解:利用 LangChain 和 Neo4j 向量索引,构建一个RAG应用程序
- 用通俗易懂的方式讲解:使用 Neo4j 和 LangChain 集成非结构化知识图增强 QA
- 用通俗易懂的方式讲解:面了 5 家知名企业的NLP算法岗(大模型方向),被考倒了。。。。。
- 用通俗易懂的方式讲解:NLP 算法实习岗,对我后续找工作太重要了!。
- 用通俗易懂的方式讲解:理想汽车大模型算法工程师面试,被问的瑟瑟发抖。。。。
- 用通俗易懂的方式讲解:基于 Langchain-Chatchat,我搭建了一个本地知识库问答系统
- 面试了字节大模型算法岗(实习),快被问哭了。。。。
【参考文献】
[1] OpenAI. “Video generation models as world simulators.” OpenAI Blog. 2024.
[2] Ho, Jonathan, Ajay Jain, and Pieter Abbeel. “Denoising diffusion probabilistic models.” Advances in neural informaion processing systems 33 (2020): 6840-6851.
[3] Rombach, Robin, et al. “High-resolution image synthesis with latent diffusion models.” Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2022.
[4] Peebles, William, and Saining Xie. “Scalable diffusion models with transformers.” Proceedings of the IEEE/CVF International Conference on Computer Vision. 2023.
[5] Kingma, Diederik P., and Max Welling. “Auto-encoding variational bayes.” arXiv preprint arXiv:1312.6114 (2013).
[6] Betker, James, et al. “Improving image generation with better captions.” Computer Science. https://cdn.openai.com/papers/dall-e-3. pdf 2.3 (2023): 8.
[7] Meng, Chenlin, et al. “Sdedit: Guided image synthesis and editing with stochastic differential equations.” arXiv preprint arXiv:2108.01073 (2021).
[8] Ha, David, and Jürgen Schmidhuber. “World models.” arXiv preprint arXiv:1803.10122 (2018).